Diagnostisera vanliga scenarier med Service Fabric
Den här artikeln illustrerar vanliga scenarier som användare har stött på när det gäller övervakning och diagnostik med Service Fabric. De scenarier som presenteras omfattar alla tre skikten av serviceinfrastruktur: Program, kluster och infrastruktur. Varje lösning använder Application Insights- och Azure Monitor-loggar, Azure-övervakningsverktyg, för att slutföra varje scenario. Stegen i varje lösning ger användarna en introduktion till hur de använder Application Insights- och Azure Monitor-loggar i samband med Service Fabric.
Kommentar
Den här artikeln uppdaterades nyligen för att använda termen Azure Monitor-loggar i stället för Log Analytics. Loggdata lagras fortfarande på en Log Analytics-arbetsyta och samlas fortfarande in och analyseras av samma Log Analytics-tjänst. Vi uppdaterar terminologin för att bättre återspegla loggarnas roll i Azure Monitor. Mer information finns i Terminologiändringar i Azure Monitor.
Krav och rekommendationer
Lösningarna i den här artikeln använder följande verktyg. Vi rekommenderar att du har konfigurerat följande:
- Application Insights med Service Fabric
- Aktivera Azure Diagnostics i klustret
- Konfigurera en Log Analytics-arbetsyta
- Log Analytics-agent för att spåra prestandaräknare
Hur kan jag se ohanterade undantag i mitt program?
Gå till din Application Insights-resurs som ditt program har konfigurerats med.
Klicka på Sök längst upp till vänster. Klicka sedan på filter på nästa panel.
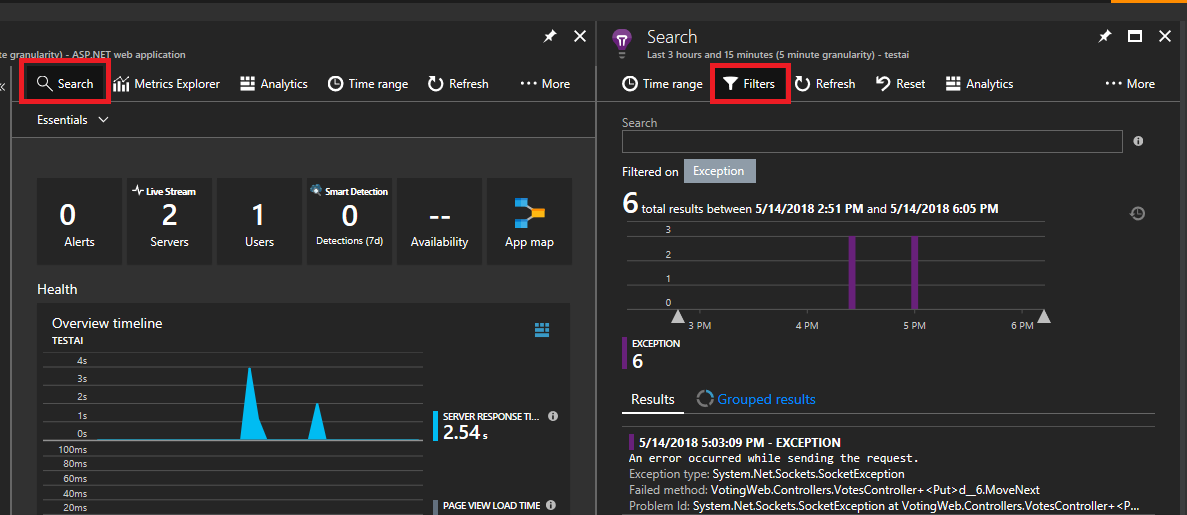
Du ser många typer av händelser (spårningar, begäranden, anpassade händelser). Välj "Undantag" som filter.
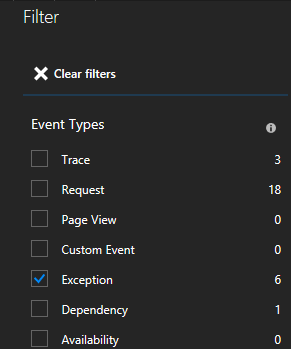
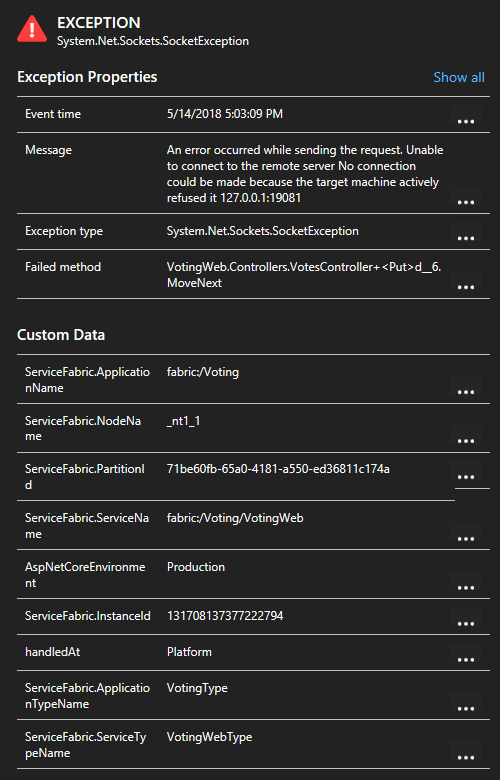
Genom att klicka på ett undantag i listan kan du titta på mer information, inklusive tjänstkontexten om du använder Service Fabric Application Insights SDK.
Hur visar jag vilka HTTP-anrop som används i mina tjänster?
I samma Application Insights-resurs kan du filtrera på "begäranden" i stället för undantag och visa alla begäranden som görs
Om du använder Service Fabric Application Insights SDK kan du se en visuell representation av dina tjänster som är anslutna till varandra och antalet lyckade och misslyckade begäranden. Till vänster klickar du på "Programkarta"
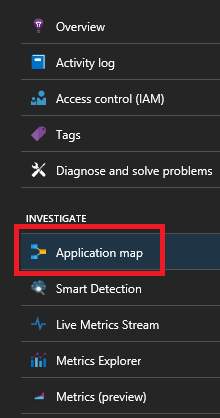
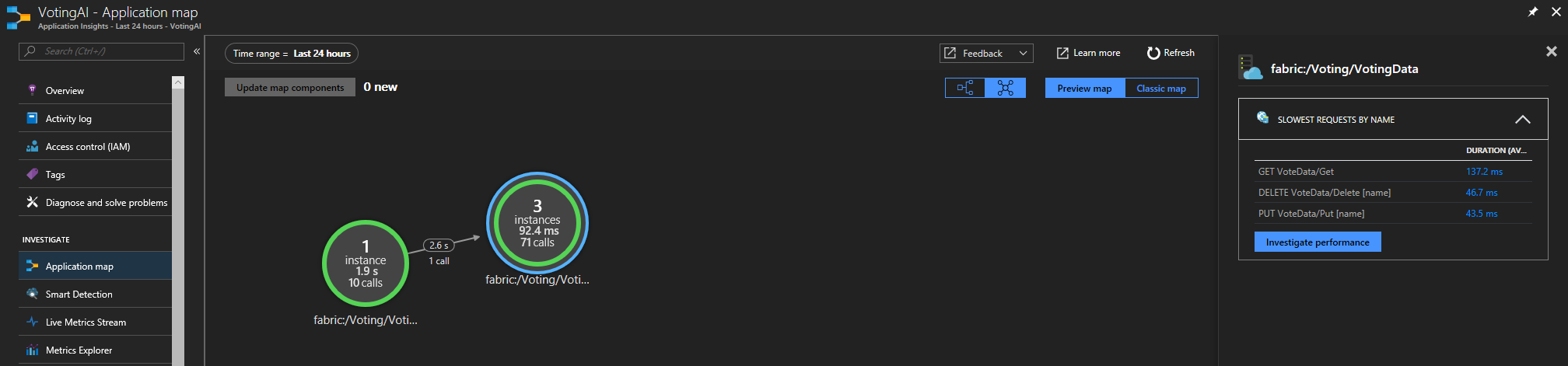
Mer information om programkartan finns i dokumentationen för Programkarta
Hur skapar jag en avisering när en nod slutar fungera
Nodhändelser spåras av service fabric-klustret. Gå till Service Fabric Analytics-lösningsresursen med namnet ServiceFabric(NameofResourceGroup)
Klicka på diagrammet längst ned på bladet med rubriken "Sammanfattning"
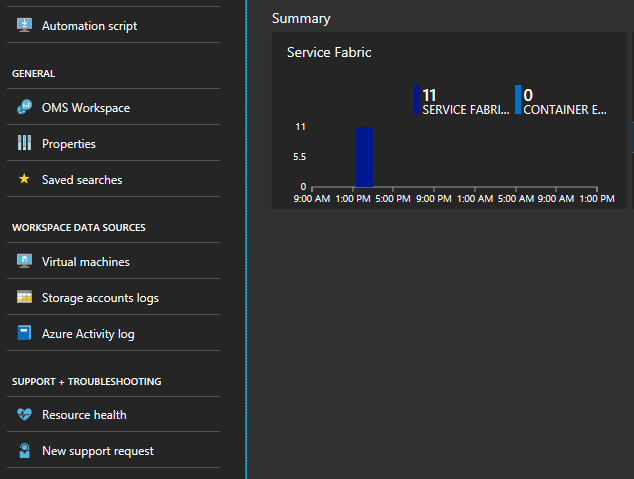
Här finns många grafer och paneler som visar olika mått. Klicka på ett av diagrammet så tar det dig till loggsökningen. Här kan du fråga efter eventuella klusterhändelser eller prestandaräknare.
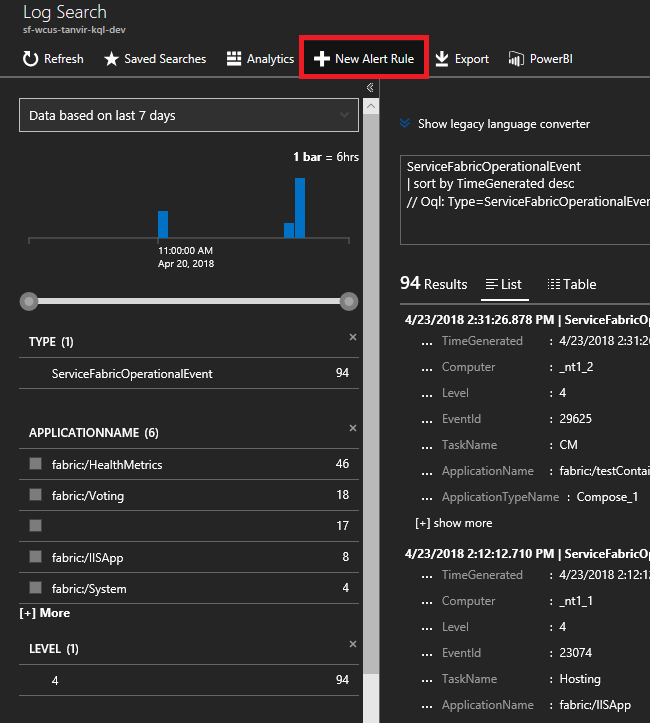
Ange följande fråga. Dessa händelse-ID:er finns i referensen för Node-händelser
ServiceFabricOperationalEvent | where EventID >= 25622 and EventID <= 25626Klicka på "Ny aviseringsregel" högst upp och när en händelse kommer baserat på den här frågan får du en avisering i den valda kommunikationsmetoden.
Hur kan jag få aviseringar om återställningar av programuppgradering?
I samma loggsökningsfönster som innan anger du följande fråga för uppgraderingsåterställning. Dessa händelse-ID:er finns under Referens för programhändelser
ServiceFabricOperationalEvent | where EventID == 29623 or EventID == 29624Klicka på "Ny aviseringsregel" högst upp och när en händelse kommer baserat på den här frågan får du en avisering.
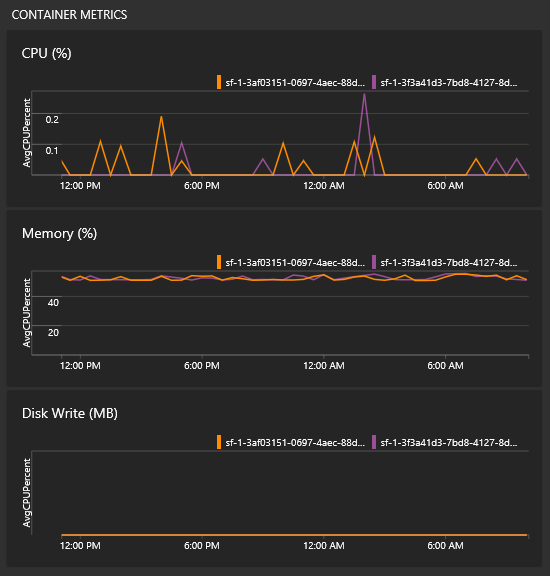
Hur ser jag containermått?
I samma vy som alla diagram visas några paneler för prestanda för dina containrar. Du behöver Log Analytics-agenten och containerövervakningslösningen för att dessa paneler ska fyllas i.
Kommentar
Om du vill instrumentera telemetri inifrån containern måste du lägga till Nuget-paketet Application Insights för containrar.
Hur kan jag övervaka prestandaräknare?
När du har lagt till Log Analytics-agenten i klustret måste du lägga till de specifika prestandaräknare som du vill spåra. Gå till Log Analytics-arbetsytans sida i portalen – från lösningssidan finns arbetsytefliken på den vänstra menyn.
När du är på arbetsytans sida klickar du på "Avancerade inställningar" på samma vänstra meny.
Klicka på Data > Windows-prestandaräknare (Data > Linux-prestandaräknare för Linux-datorer) för att börja samla in specifika räknare från dina noder via Log Analytics-agenten. Här är exempel på formatet för räknare som ska läggas till
.NET CLR Memory(<ProcessNameHere>)\\# Total committed BytesProcessor(_Total)\\% Processor TimeI snabbstarten är VotingData och VotingWeb de processnamn som används, så att spåra dessa räknare skulle se ut som
.NET CLR Memory(VotingData)\\# Total committed Bytes.NET CLR Memory(VotingWeb)\\# Total committed Bytes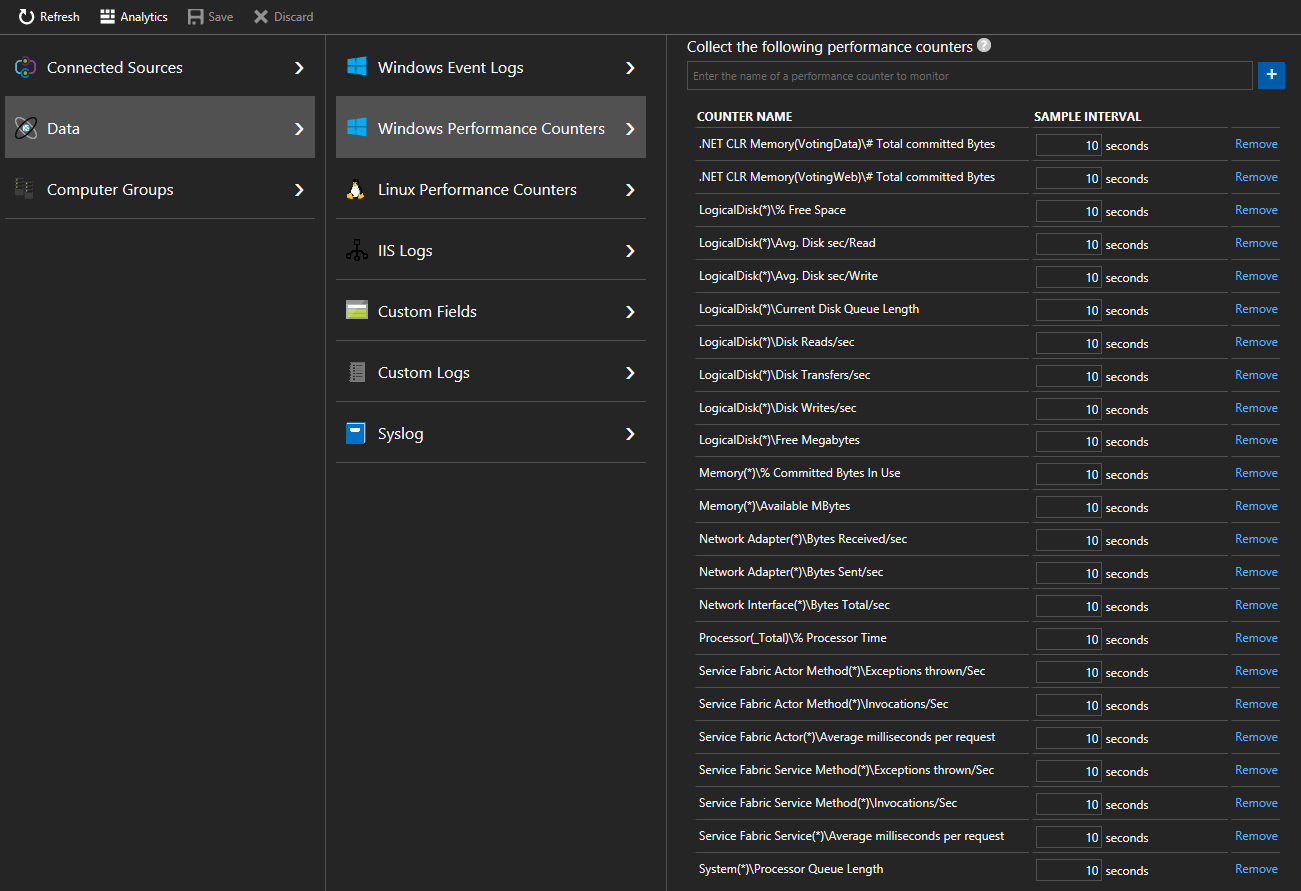
På så sätt kan du se hur infrastrukturen hanterar dina arbetsbelastningar och ange relevanta aviseringar baserat på resursanvändning. Du kanske till exempel vill ange en avisering om den totala processoranvändningen överskrider 90 % eller under 5 %. Räknarnamnet som du använder för detta är %-processortid. Du kan göra detta genom att skapa en aviseringsregel för följande fråga:
Perf | where CounterName == "% Processor Time" and InstanceName == "_Total" | where CounterValue >= 90 or CounterValue <= 5.
Hur spårar jag prestanda för mina Reliable Services och Actors?
Om du vill spåra prestanda för Reliable Services eller Actors i dina program bör du även samla in räknarna Service Fabric Actor, Actor Method, Service och Service Method. Här är exempel på tillförlitliga prestandaräknare för tjänster och aktörer att samla in
Kommentar
Prestandaräknare för Service Fabric kan för närvarande inte samlas in av Log Analytics-agenten, men kan samlas in av andra diagnostiklösningar
Service Fabric Service(*)\\Average milliseconds per requestService Fabric Service Method(*)\\Invocations/SecService Fabric Actor(*)\\Average milliseconds per requestService Fabric Actor Method(*)\\Invocations/Sec
Kontrollera dessa länkar för den fullständiga listan över prestandaräknare på Reliable Services och Actors
Nästa steg
- Slå upp vanliga fel vid aktivering av kodpaket
- Konfigurera aviseringar i AI som ska meddelas om ändringar i prestanda eller användning
- Smart identifiering i Application Insights utför en proaktiv analys av telemetrin som skickas till AI för att varna dig om potentiella prestandaproblem
- Läs mer om aviseringar om Azure Monitor-loggar för att underlätta identifiering och diagnostik.
- För lokala kluster erbjuder Azure Monitor-loggar en gateway (HTTP Forward Proxy) som kan användas för att skicka data till Azure Monitor-loggar. Läs mer om det i Ansluta datorer utan Internetåtkomst till Azure Monitor-loggar med hjälp av Log Analytics-gatewayen
- Bekanta dig med loggsöknings - och frågefunktionerna som erbjuds som en del av Azure Monitor-loggar
- Få en mer detaljerad översikt över Azure Monitor-loggar och vad den erbjuder, läs Vad är Azure Monitor-loggar?
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för