Händelseanalys och visualisering med Azure Monitor-loggar
Azure Monitor-loggar samlar in och analyserar telemetri från program och tjänster som finns i molnet och tillhandahåller analysverktyg som hjälper dig att maximera deras tillgänglighet och prestanda. Den här artikeln beskriver hur du kör frågor i Azure Monitor-loggar för att få insikter och felsöka vad som händer i klustret. Följande vanliga frågor tas upp:
- Hur felsöker jag hälsohändelser?
- Hur vet jag när en nod slutar fungera?
- Hur vet jag om programmets tjänster har startats eller stoppats?
Kommentar
Den här artikeln uppdaterades nyligen för att använda termen Azure Monitor-loggar i stället för Log Analytics. Loggdata lagras fortfarande på en Log Analytics-arbetsyta och samlas fortfarande in och analyseras av samma Log Analytics-tjänst. Vi uppdaterar terminologin för att bättre återspegla loggarnas roll i Azure Monitor. Mer information finns i Terminologiändringar i Azure Monitor.
Översikt över Log Analytics-arbetsytan
Kommentar
Även om diagnostiklagring är aktiverat som standard när klustret skapas måste du fortfarande konfigurera Log Analytics-arbetsytan för att läsa från diagnostiklagringen.
Azure Monitor-loggar samlar in data från hanterade resurser, inklusive en Azure-lagringstabell eller en agent, och underhåller dem på en central lagringsplats. Data kan sedan användas för analys, aviseringar och visualisering eller ytterligare export. Azure Monitor-loggar stöder händelser, prestandadata eller andra anpassade data. Kolla in steg för att konfigurera diagnostiktillägget för att aggregera händelser och steg för att skapa en Log Analytics-arbetsyta som ska läsas från händelserna i lagringen för att se till att data flödar in i Azure Monitor-loggar.
När data har tagits emot av Azure Monitor-loggar har Azure flera övervakningslösningar som är förpaketerade lösningar eller operativa instrumentpaneler för att övervaka inkommande data, anpassade till flera scenarier. Dessa inkluderar en Service Fabric Analytics-lösning och en containerlösning , som är de två mest relevanta för diagnostik och övervakning när du använder Service Fabric-kluster. Den här artikeln beskriver hur du använder Service Fabric Analytics-lösningen, som skapas med arbetsytan.
Få åtkomst till Service Fabric Analytics-lösningen
I Azure-portalen går du till resursgruppen där du skapade Service Fabric Analytics-lösningen.
Välj resursen ServiceFabric<nameOfOMSWorkspace>.
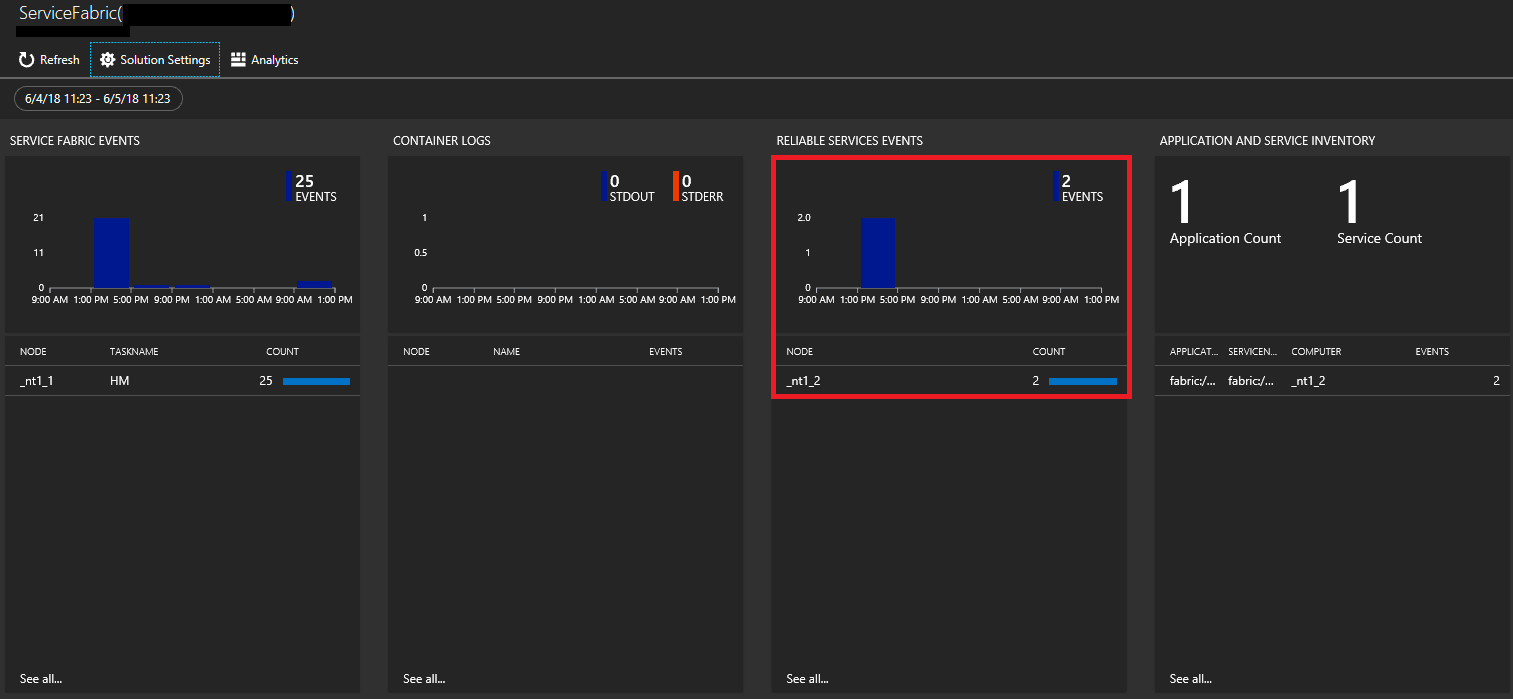
I Summaryvisas paneler i form av ett diagram för var och en av de aktiverade lösningarna, inklusive en för Service Fabric. Klicka på Service Fabric-grafen för att fortsätta till Service Fabric Analytics-lösningen.
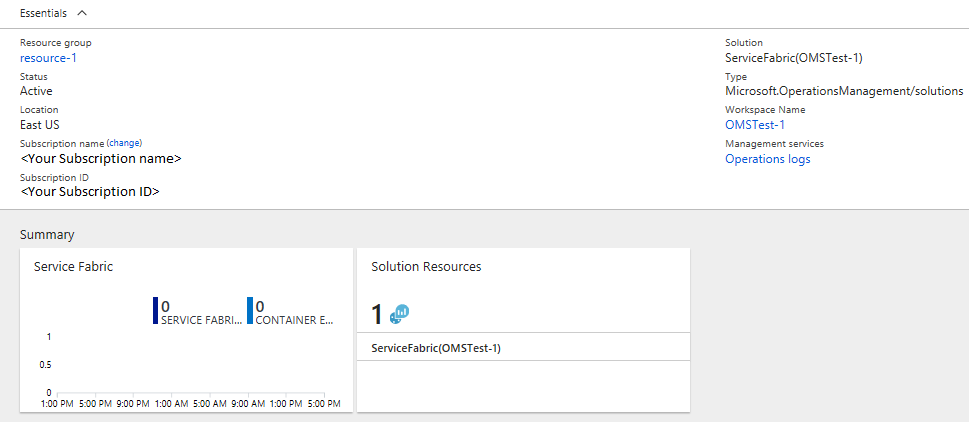
Följande bild visar startsidan för Service Fabric Analytics-lösningen. Den här startsidan innehåller en ögonblicksbild av vad som händer i klustret.
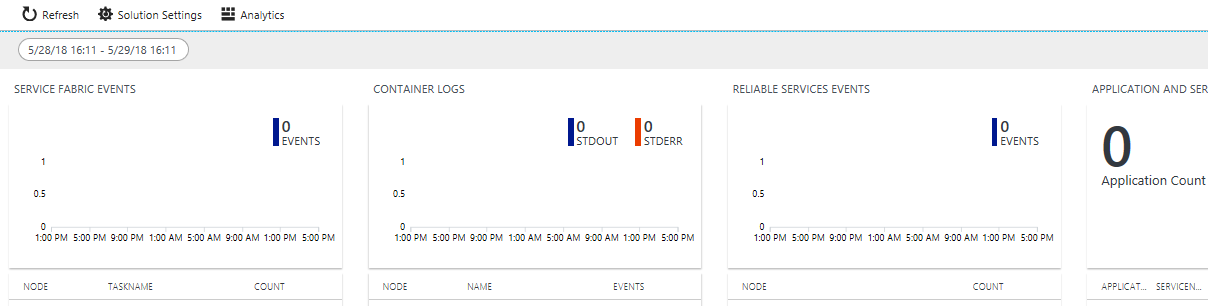
Om du aktiverade diagnostik när klustret skapades kan du se händelser för
- Service Fabric-klusterhändelser
- Reliable Actors programmeringsmodellhändelser
- Reliable Services-programmeringsmodellhändelser
Kommentar
Utöver Service Fabric-händelserna kan du samla in mer detaljerade systemhändelser genom att uppdatera konfigurationen för diagnostiktillägget.
Visa Service Fabric-händelser, inklusive åtgärder på noder
På sidan Service Fabric Analytics klickar du på diagrammet för Service Fabric-händelser.
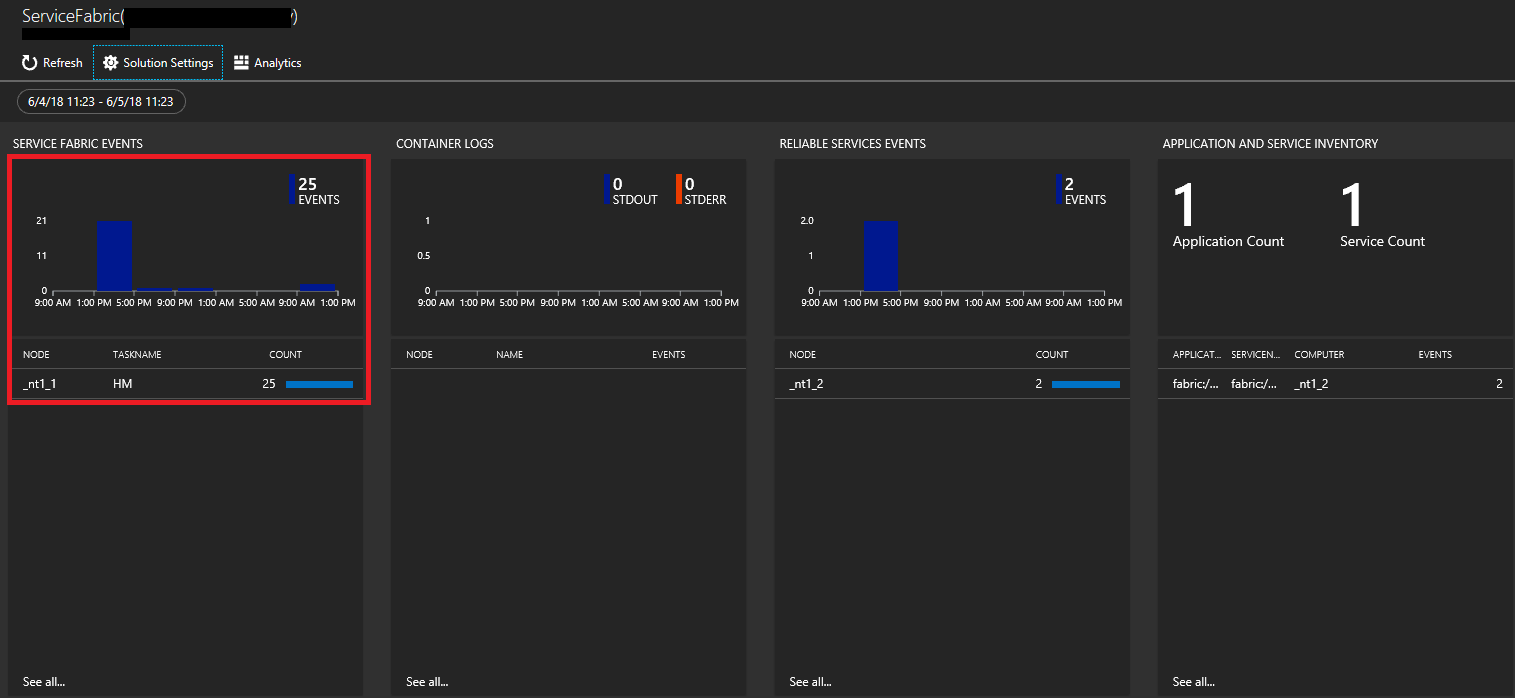
Klicka på Lista för att visa händelserna i en lista. Här visas alla systemhändelser som har samlats in. Som referens kommer dessa från WADServiceFabricSystemEventsTable i Azure Storage-kontot, och på samma sätt kommer de tillförlitliga tjänste- och aktörshändelser som du ser härnäst från respektive tabeller.
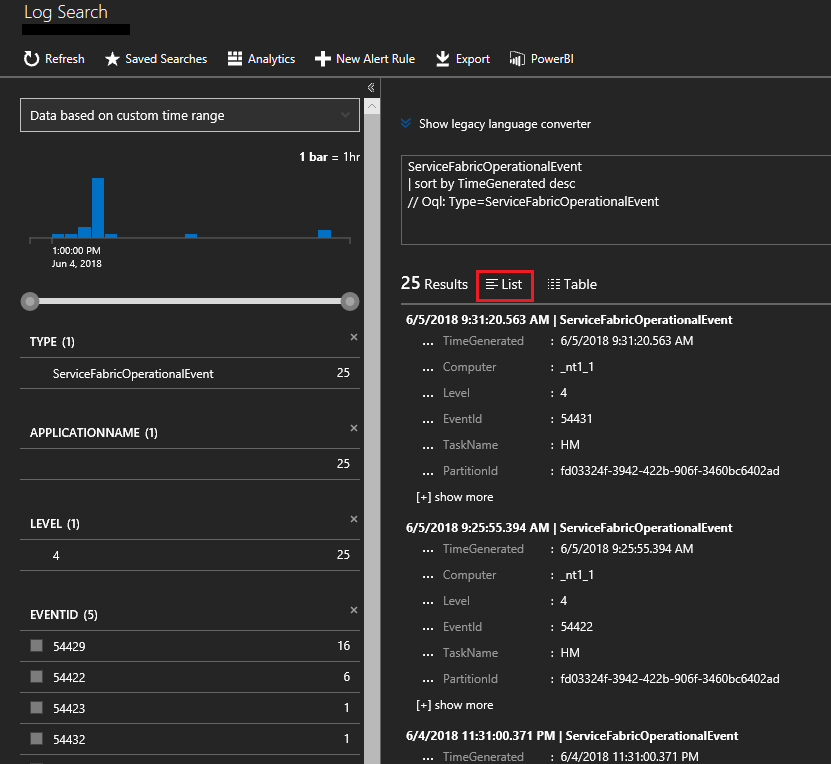
Du kan också klicka på förstoringsglaset till vänster och använda Kusto-frågespråket för att hitta det du letar efter. Om du till exempel vill hitta alla åtgärder som vidtas på noder i klustret kan du använda följande fråga. Händelse-ID:t som används nedan finns i händelsereferensen för den operativa kanalen.
ServiceFabricOperationalEvent
| where EventId < 25627 and EventId > 25619
Du kan fråga i många fler fält, till exempel de specifika noderna (dator) systemtjänsten (TaskName).
Visa händelser för Service Fabric Reliable Service och Actor
På sidan Service Fabric Analytics klickar du på diagrammet för Reliable Services.
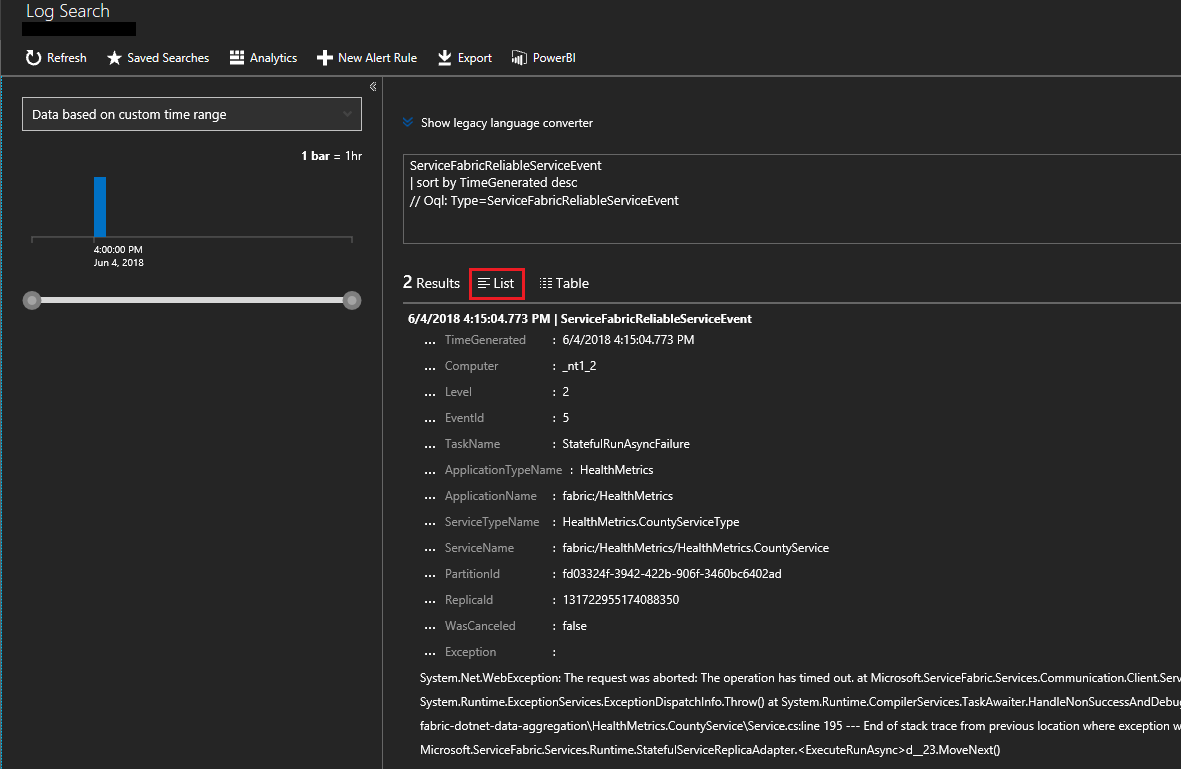
Klicka på Lista för att visa händelserna i en lista. Här kan du se händelser från tillförlitliga tjänster. Du kan se olika händelser för när tjänstens runasync startas och slutförs, vilket vanligtvis sker vid distributioner och uppgraderingar.
Tillförlitliga aktörshändelser kan visas på ett liknande sätt. Om du vill konfigurera mer detaljerade händelser för tillförlitliga aktörer måste du ändra scheduledTransferKeywordFilter i konfigurationen för diagnostiktillägget (visas nedan). Information om värdena för dessa finns i referensen för tillförlitliga aktörers händelser.
"EtwEventSourceProviderConfiguration": [
{
"provider": "Microsoft-ServiceFabric-Actors",
"scheduledTransferKeywordFilter": "1",
"scheduledTransferPeriod": "PT5M",
"DefaultEvents": {
"eventDestination": "ServiceFabricReliableActorEventTable"
}
},
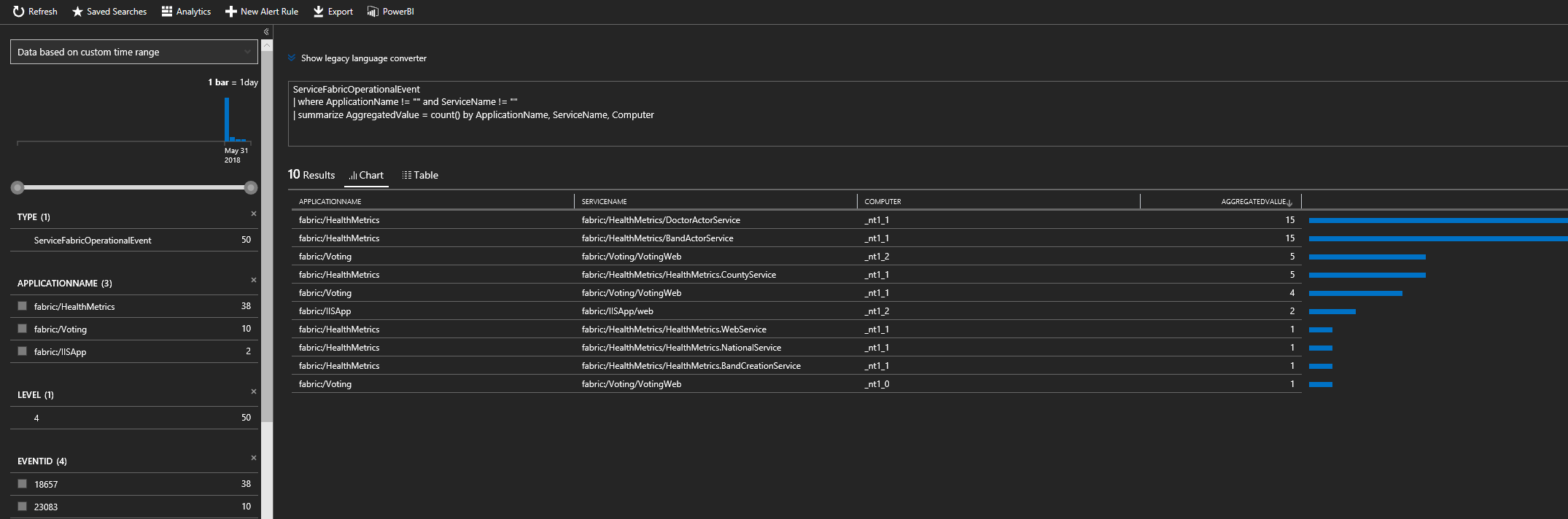
Kusto-frågespråket är kraftfullt. En annan värdefull fråga som du kan köra är att ta reda på vilka noder som genererar flest händelser. Frågan i skärmbilden nedan visar service fabric-drifthändelser aggregerade med den specifika tjänsten och noden.
Nästa steg
- Om du vill aktivera infrastrukturövervakning, dvs. prestandaräknare, går du över till att lägga till Log Analytics-agenten. Agenten samlar in prestandaräknare och lägger till dem i din befintliga arbetsyta.
- För lokala kluster erbjuder Azure Monitor-loggar en gateway (HTTP Forward Proxy) som kan användas för att skicka data till Azure Monitor-loggar. Läs mer om det i Ansluta datorer utan Internetåtkomst till Azure Monitor-loggar med hjälp av Log Analytics-gatewayen.
- Konfigurera automatisk avisering för att underlätta identifiering och diagnostik.
- Bekanta dig med loggsöknings - och frågefunktionerna som erbjuds som en del av Azure Monitor-loggarna.
- Få en mer detaljerad översikt över Azure Monitor-loggar och vad den erbjuder, läs Vad är Azure Monitor-loggar?.
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för