Designvägledning för att använda replikerade tabeller i Synapse SQL-pool
Den här artikeln ger rekommendationer för att utforma replikerade tabeller i ditt Synapse SQL-poolschema. Använd dessa rekommendationer för att förbättra frågeprestanda genom att minska dataförflyttning och frågekomplexitet.
Förutsättningar
Den här artikeln förutsätter att du är bekant med begreppen datadistribution och dataflytt i SQL-poolen. Mer information finns i artikeln om arkitektur .
Som en del av tabelldesignen kan du förstå så mycket som möjligt om dina data och hur data efterfrågas. Tänk till exempel på följande frågor:
- Hur stor är tabellen?
- Hur ofta uppdateras tabellen?
- Har jag fakta- och dimensionstabeller i en SQL-pool?
Vad är en replikerad tabell?
En replikerad tabell har en fullständig kopia av tabellen som är tillgänglig på varje beräkningsnod. När du replikerar en tabell behöver du inte överföra data till beräkningsnoder innan en koppling eller aggregering. Eftersom tabellen har flera kopior fungerar replikerade tabeller bäst när tabellstorleken är mindre än 2 GB komprimerad. 2 GB är inte en hård gräns. Om data är statiska och inte ändras kan du replikera större tabeller.
Följande diagram visar en replikerad tabell som är tillgänglig på varje beräkningsnod. I SQL-poolen kopieras den replikerade tabellen helt till en distributionsdatabas på varje beräkningsnod.

Replikerade tabeller fungerar bra för dimensionstabeller i ett stjärnschema. Dimensionstabeller är vanligtvis kopplade till faktatabeller, som distribueras på ett annat sätt än dimensionstabellen. Dimensioner är vanligtvis av en storlek som gör det möjligt att lagra och underhålla flera kopior. Dimensioner lagrar beskrivande data som ändras långsamt, till exempel kundnamn och adress samt produktinformation. Datans långsamt föränderliga karaktär leder till mindre underhåll av den replikerade tabellen.
Överväg att använda en replikerad tabell när:
- Tabellstorleken på disken är mindre än 2 GB, oavsett antalet rader. Om du vill hitta storleken på en tabell kan du använda kommandot DBCC PDW_SHOWSPACEUSED :
DBCC PDW_SHOWSPACEUSED('ReplTableCandidate'). - Tabellen används i kopplingar som annars skulle kräva dataflytt. När du ansluter tabeller som inte är distribuerade i samma kolumn, till exempel en hash-distribuerad tabell till en resursallokeringstabell, krävs dataflytt för att slutföra frågan. Om en av tabellerna är liten bör du överväga en replikerad tabell. Vi rekommenderar att du använder replikerade tabeller i stället för resursallokeringstabeller i de flesta fall. Om du vill visa dataförflyttningsåtgärder i frågeplaner använder du sys.dm_pdw_request_steps. BroadcastMoveOperation är den typiska dataförflyttningsåtgärden som kan elimineras med hjälp av en replikerad tabell.
Replikerade tabeller kanske inte ger bästa frågeprestanda när:
- Tabellen har frekventa åtgärder för att infoga, uppdatera och ta bort. Åtgärderna för datamanipuleringsspråk (DML) kräver att den replikerade tabellen återskapas. Återskapande ofta kan orsaka långsammare prestanda.
- SQL-poolen skalas ofta. Om du skalar en SQL-pool ändras antalet beräkningsnoder, vilket medför att den replikerade tabellen återskapas.
- Tabellen har ett stort antal kolumner, men dataåtgärder har vanligtvis bara åtkomst till ett litet antal kolumner. I det här scenariot kan det vara effektivare att distribuera tabellen i stället för att replikera hela tabellen och sedan skapa ett index för de kolumner som används ofta. När en fråga kräver dataförflyttning flyttar SQL-poolen endast data för de begärda kolumnerna.
Dricks
Mer information om indexering och replikerade tabeller finns i Cheat-bladet för dedikerad SQL-pool (tidigare SQL DW) i Azure Synapse Analytics.
Använda replikerade tabeller med enkla frågepredikat
Innan du väljer att distribuera eller replikera en tabell bör du tänka på vilka typer av frågor du planerar att köra mot tabellen. När det är möjligt
- Använd replikerade tabeller för frågor med enkla frågepredikat, till exempel likhet eller ojämlikhet.
- Använd distribuerade tabeller för frågor med komplexa frågepredikat, till exempel LIKE eller NOT LIKE.
CPU-intensiva frågor fungerar bäst när arbetet distribueras över alla beräkningsnoder. Till exempel presterar frågor som kör beräkningar på varje rad i en tabell bättre på distribuerade tabeller än replikerade tabeller. Eftersom en replikerad tabell lagras i sin helhet på varje beräkningsnod körs en CPU-intensiv fråga mot en replikerad tabell mot hela tabellen på varje beräkningsnod. Den extra beräkningen kan göra frågeprestanda långsammare.
Den här frågan har till exempel ett komplext predikat. Den körs snabbare när data finns i en distribuerad tabell i stället för en replikerad tabell. I det här exemplet kan data distribueras med resursallokering.
SELECT EnglishProductName
FROM DimProduct
WHERE EnglishDescription LIKE '%frame%comfortable%';
Konvertera befintliga resursallokeringstabeller till replikerade tabeller
Om du redan har resursallokeringstabeller rekommenderar vi att du konverterar dem till replikerade tabeller om de uppfyller kriterierna som beskrivs i den här artikeln. Replikerade tabeller förbättrar prestandan för resursallokeringstabeller eftersom de eliminerar behovet av dataflytt. En resursallokeringstabell kräver alltid dataflytt för kopplingar.
I det här exemplet används CTAS för att ändra DimSalesTerritory tabellen till en replikerad tabell. Det här exemplet fungerar oavsett om DimSalesTerritory det är hash-distribuerat eller resursallokerat.
CREATE TABLE [dbo].[DimSalesTerritory_REPLICATE]
WITH
(
HEAP,
DISTRIBUTION = REPLICATE
)
AS SELECT * FROM [dbo].[DimSalesTerritory]
OPTION (LABEL = 'CTAS : DimSalesTerritory_REPLICATE')
-- Switch table names
RENAME OBJECT [dbo].[DimSalesTerritory] to [DimSalesTerritory_old];
RENAME OBJECT [dbo].[DimSalesTerritory_REPLICATE] TO [DimSalesTerritory];
DROP TABLE [dbo].[DimSalesTerritory_old];
Exempel på frågeprestanda för resursallokering jämfört med replikerad
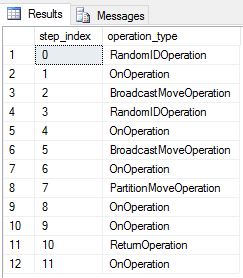
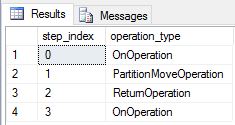
En replikerad tabell kräver ingen dataflytt för kopplingar eftersom hela tabellen redan finns på varje beräkningsnod. Om dimensionstabellerna är resursallokerade kopierar en koppling dimensionstabellen i sin helhet till varje beräkningsnod. Om du vill flytta data innehåller frågeplanen en åtgärd som kallas BroadcastMoveOperation. Den här typen av dataflytt gör frågeprestanda långsammare och elimineras med hjälp av replikerade tabeller. Om du vill visa frågeplanssteg använder du vyn sys.dm_pdw_request_steps systemkatalog.
I följande fråga mot AdventureWorks schemat är tabellen FactInternetSales till exempel hash-distribuerad. Tabellerna DimDate och DimSalesTerritory är mindre dimensionstabeller. Den här frågan returnerar den totala försäljningen i Nordamerika för räkenskapsåret 2004:
SELECT [TotalSalesAmount] = SUM(SalesAmount)
FROM dbo.FactInternetSales s
INNER JOIN dbo.DimDate d
ON d.DateKey = s.OrderDateKey
INNER JOIN dbo.DimSalesTerritory t
ON t.SalesTerritoryKey = s.SalesTerritoryKey
WHERE d.FiscalYear = 2004
AND t.SalesTerritoryGroup = 'North America'
Vi återskapade DimDate och DimSalesTerritory som resursallokeringstabeller. Därför visade frågan följande frågeplan, som har flera sändningsflyttningsåtgärder:
Vi återskapade DimDate och DimSalesTerritory som replikerade tabeller och körde frågan igen. Den resulterande frågeplanen är mycket kortare och har inga sändningssteg.
Prestandaöverväganden för att ändra replikerade tabeller
SQL-poolen implementerar en replikerad tabell genom att underhålla en huvudversion av tabellen. Den kopierar huvudversionen till den första distributionsdatabasen på varje beräkningsnod. När det sker en ändring uppdateras huvudversionen först och sedan återskapas tabellerna på varje beräkningsnod. En återskapande av en replikerad tabell omfattar att kopiera tabellen till varje beräkningsnod och sedan skapa indexen. En replikerad tabell på en DW2000c har till exempel fem kopior av data. En huvudkopia och en fullständig kopia på varje beräkningsnod. Alla data lagras i distributionsdatabaser. SQL-poolen använder den här modellen för att stödja snabbare instruktioner för datamodifiering och flexibla skalningsåtgärder.
Asynkrona återskapanden utlöses av den första frågan mot den replikerade tabellen efter:
- Data läses in eller ändras
- Synapse SQL-instansen skalas till en annan nivå
- Tabelldefinitionen uppdateras
Återskapanden krävs inte efter:
- Pausa åtgärden
- Återuppta åtgärden
Återskapande sker inte omedelbart efter att data har ändrats. I stället utlöses återskapande första gången en fråga väljs från tabellen. Frågan som utlöste återskapande läser direkt från huvudversionen av tabellen medan data kopieras asynkront till varje beräkningsnod. Tills datakopian är klar fortsätter efterföljande frågor att använda huvudversionen av tabellen. Om någon aktivitet sker mot den replikerade tabellen som tvingar fram en ny återskapande, ogiltigförklaras datakopian och nästa select-instruktion utlöser att data kopieras igen.
Använd index konservativt
Standardmetoder för indexering gäller för replikerade tabeller. SQL-poolen återskapar varje replikerat tabellindex som en del av återskapande. Använd endast index när prestandavinsten uppväger kostnaden för att återskapa indexen.
Batch-datainläsning
När du läser in data i replikerade tabeller kan du försöka minimera återskapanden genom att batchinläsningar tillsammans. Utför alla batchinläsningar innan du kör select-instruktioner.
Det här belastningsmönstret läser till exempel in data från fyra källor och anropar fyra återskapanden.
- Läs in från källa 1.
- Select-instruktionsutlösare återskapar 1.
- Läs in från källa 2.
- Select-instruktionsutlösare återskapar 2.
- Läs in från källa 3.
- Select-instruktionsutlösare återskapar 3.
- Läs in från källa 4.
- Select-instruktionsutlösare återskapar 4.
Det här belastningsmönstret läser till exempel in data från fyra källor, men anropar bara en återskapning.
- Läs in från källa 1.
- Läs in från källa 2.
- Läs in från källa 3.
- Läs in från källa 4.
- Select-instruktionsutlösare återskapas.
Återskapa en replikerad tabell efter en batchbelastning
För att säkerställa konsekventa frågekörningstider bör du överväga att tvinga fram genereringen av de replikerade tabellerna efter en batchinläsning. Annars använder den första frågan fortfarande dataflytt för att slutföra frågan.
Åtgärden "Skapa replikerad tabellcache" kan köra upp till två åtgärder samtidigt. Om du till exempel försöker återskapa cachen för fem tabeller använder systemet en staticrc20 (som inte kan ändras) för att samtidigt skapa två tabeller samtidigt. Därför rekommenderar vi att du undviker att använda stora replikerade tabeller som överstiger 2 GB, eftersom detta kan göra cacheminnet långsammare för noderna och öka den totala tiden.
Den här frågan använder sys.pdw_replicated_table_cache_state DMV för att lista de replikerade tabeller som har ändrats, men inte återskapats.
SELECT SchemaName = SCHEMA_NAME(t.schema_id)
, [ReplicatedTable] = t.[name]
, [RebuildStatement] = 'SELECT TOP 1 * FROM ' + '[' + SCHEMA_NAME(t.schema_id) + '].[' + t.[name] +']'
FROM sys.tables t
JOIN sys.pdw_replicated_table_cache_state c
ON c.object_id = t.object_id
JOIN sys.pdw_table_distribution_properties p
ON p.object_id = t.object_id
WHERE c.[state] = 'NotReady'
AND p.[distribution_policy_desc] = 'REPLICATE'
Om du vill utlösa en ombyggnad kör du följande instruktion i varje tabell i föregående utdata.
SELECT TOP 1 * FROM [ReplicatedTable]
Kommentar
Om du planerar att återskapa statistiken för den icke-replikerade tabellen måste du uppdatera statistiken innan du utlöser cachen. Om du uppdaterar statistik ogiltigförklaras cacheminnet, så sekvensen är viktig.
Exempel: Börja med UPDATE STATISTICSoch utlöser sedan återskapande av cacheminnet. I följande exempel uppdaterar rätt exempel statistiken och utlöser sedan återskapande av cacheminnet.
-- Incorrect sequence. Ensure that the rebuild operation is the last statement within the batch.
BEGIN
SELECT TOP 1 * FROM [ReplicatedTable]
UPDATE STATISTICS [ReplicatedTable]
END
-- Correct sequence. Ensure that the rebuild operation is the last statement within the batch.
BEGIN
UPDATE STATISTICS [ReplicatedTable]
SELECT TOP 1 * FROM [ReplicatedTable]
END
Om du vill övervaka återskapandeprocessen kan du använda sys.dm_pdw_exec_requests, där command kommer att börja med "BuildReplicatedTableCache". Till exempel:
-- Monitor Build Replicated Cache
SELECT *
FROM sys.dm_pdw_exec_requests
WHERE command like 'BuildReplicatedTableCache%'
Dricks
Frågor om tabellstorlek kan användas för att verifiera vilka tabeller som har en replikerad distributionsprincip och som är större än 2 GB.
Nästa steg
Om du vill skapa en replikerad tabell använder du någon av följande instruktioner:
En översikt över distribuerade tabeller finns i distribuerade tabeller.