Mönster för tabelldesign
I den här artikeln beskrivs några mönster som är lämpliga för användning med Table Service-lösningar. Dessutom ser du hur du praktiskt taget kan hantera några av de problem och kompromisser som beskrivs i andra artiklar om tabelllagringsdesign. I följande diagram sammanfattas relationerna mellan de olika mönstren:
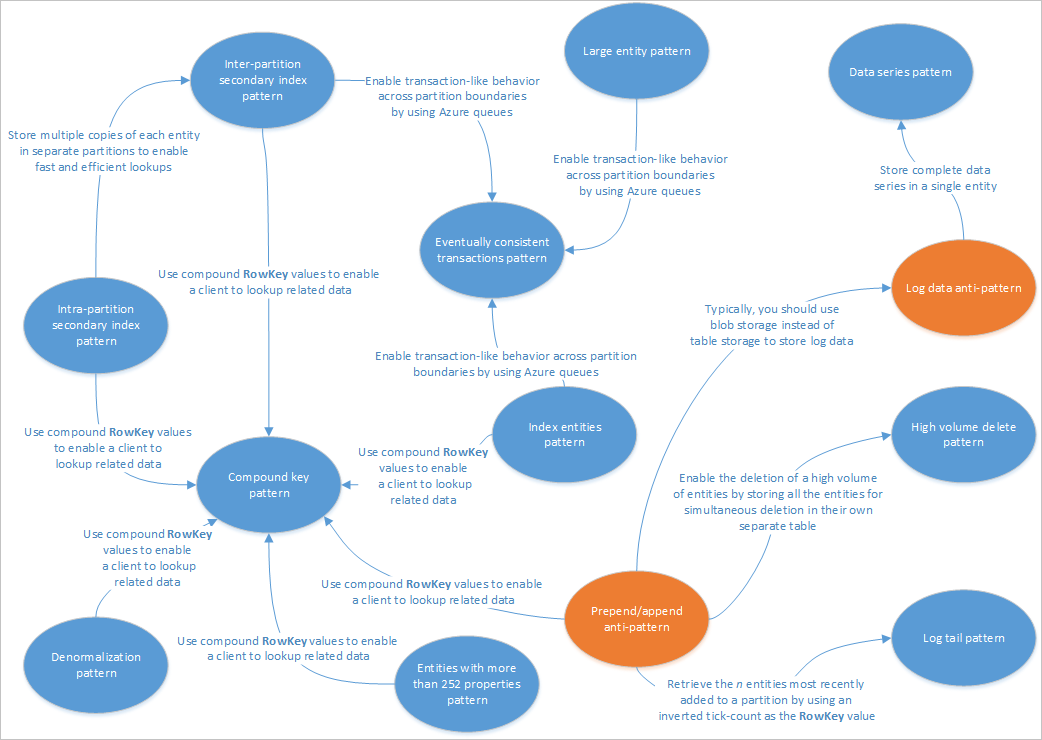
Mönsterkartan ovan visar några relationer mellan mönster (blå) och antimönster (orange) som dokumenteras i den här guiden. Det finns många andra mönster som är värda att överväga. Ett av de viktigaste scenarierna för Table Service är till exempel att använda det materialiserade vymönstret från CQRS-mönstret (Command Query Responsibility Segregation).
Mönster för sekundärt index mellan partitioner
Lagra flera kopior av varje entitet med olika RowKey-värden (i samma partition) för att aktivera snabba och effektiva sökningar och alternativa sorteringsordningar med hjälp av olika RowKey-värden . Uppdateringar mellan kopior kan hållas konsekvent med hjälp av entitetsgrupptransaktioner (EGT).
Kontext och problem
Tabelltjänsten indexerar automatiskt entiteter med värdena PartitionKey och RowKey . Detta gör att ett klientprogram kan hämta en entitet effektivt med hjälp av dessa värden. Om du till exempel använder tabellstrukturen som visas nedan kan ett klientprogram använda en punktfråga för att hämta en enskild medarbetaretitet med hjälp av avdelningsnamnet och medarbetar-ID :t ( värdena PartitionKey och RowKey ). En klient kan också hämta entiteter sorterade efter medarbetar-ID inom varje avdelning.
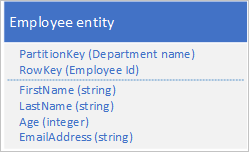
Om du också vill kunna hitta en medarbetaretitet baserat på värdet för en annan egenskap, till exempel e-postadress, måste du använda en mindre effektiv partitionsgenomsökning för att hitta en matchning. Det beror på att tabelltjänsten inte tillhandahåller sekundära index. Dessutom finns det inget alternativ för att begära en lista över anställda sorterade i en annan ordning än RowKey-ordningen .
Lösning
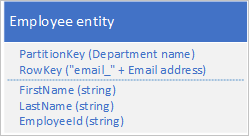
Om du vill undvika bristen på sekundära index kan du lagra flera kopior av varje entitet med varje kopia med ett annat RowKey-värde . Om du lagrar en entitet med de strukturer som visas nedan kan du effektivt hämta anställdatiteter baserat på e-postadress eller medarbetar-ID. Med prefixvärdena för RowKey, "empid_" och "email_" kan du fråga efter en enskild anställd eller ett antal anställda med hjälp av ett intervall med e-postadresser eller medarbetar-ID:t.

Följande två filtervillkor (ett som söker efter medarbetar-ID och ett som söker efter e-postadress) anger båda punktfrågor:
- $filter=(PartitionKey eq 'Sales') och (RowKey eq 'empid_000223')
- $filter=(PartitionKey eq 'Sales') och (RowKey eq 'email_jonesj@contoso.com')
Om du frågar efter ett intervall med medarbetarentiteter kan du ange ett intervall sorterat i ID-ordning för anställda eller ett intervall sorterat i e-postadressordning genom att fråga efter entiteter med rätt prefix i RowKey.
Om du vill hitta alla anställda på försäljningsavdelningen med ett medarbetar-ID i intervallet 000100 till 000199 använder du: $filter=(PartitionKey eq 'Sales') och (RowKey ge 'empid_000100') och (RowKey le 'empid_000199')
Om du vill hitta alla anställda på försäljningsavdelningen med en e-postadress som börjar med bokstaven "a" använder du: $filter=(PartitionKey eq 'Sales') och (RowKey ge 'email_a') och (RowKey lt 'email_b')
Filtersyntaxen som används i exemplen ovan kommer från REST-API:et för tabelltjänsten. Mer information finns i Fråga entiteter.
Problem och överväganden
Tänk på följande när du bestämmer hur du ska implementera mönstret:
Tabelllagring är relativt billigt att använda, så kostnaden för att lagra duplicerade data bör inte vara ett stort problem. Du bör dock alltid utvärdera kostnaden för din design baserat på dina förväntade lagringskrav och endast lägga till duplicerade entiteter som stöd för de frågor som klientprogrammet ska köra.
Eftersom de sekundära indexentiteterna lagras i samma partition som de ursprungliga entiteterna bör du se till att du inte överskrider skalbarhetsmålen för en enskild partition.
Du kan hålla dina duplicerade entiteter konsekventa med varandra genom att använda EGT för att uppdatera de två kopiorna av entiteten atomiskt. Detta innebär att du bör lagra alla kopior av en entitet i samma partition. Mer information finns i avsnittet Använda entitetsgrupptransaktioner.
Värdet som används för RowKey måste vara unikt för varje entitet. Överväg att använda sammansatta nyckelvärden.
Utfyllnad av numeriska värden i RowKey (till exempel medarbetar-ID:t 000223) möjliggör korrekt sortering och filtrering baserat på övre och nedre gränser.
Du behöver inte nödvändigtvis duplicera alla egenskaper för din entitet. Om till exempel de frågor som söker efter entiteterna med hjälp av e-postadressen i RowKey aldrig behöver medarbetarens ålder kan dessa entiteter ha följande struktur:
Det är vanligtvis bättre att lagra duplicerade data och se till att du kan hämta alla data som du behöver med en enda fråga, än att använda en fråga för att hitta en entitet och en annan för att söka efter nödvändiga data.
När du ska använda det här mönstret
Använd det här mönstret när klientprogrammet behöver hämta entiteter med en mängd olika nycklar, när klienten behöver hämta entiteter i olika sorteringsordningar och där du kan identifiera varje entitet med en mängd olika unika värden. Du bör dock vara säker på att du inte överskrider partitionens skalbarhetsgränser när du utför entitetssökningar med hjälp av de olika RowKey-värdena .
Relaterade mönster och vägledningar
Följande mönster och riktlinjer kan också vara relevanta när du implementerar det här mönstret:
- Sekundärt indexmönster mellan partitioner
- Mönster för sammansatt nyckel
- Entitetsgrupptransaktioner
- Arbeta med heterogena entitetstyper
Sekundärt indexmönster mellan partitioner
Lagra flera kopior av varje entitet med olika RowKey-värden i separata partitioner eller i separata tabeller för att aktivera snabba och effektiva sökningar och alternativa sorteringsordningar med hjälp av olika RowKey-värden .
Kontext och problem
Tabelltjänsten indexerar automatiskt entiteter med värdena PartitionKey och RowKey . Detta gör att ett klientprogram kan hämta en entitet effektivt med hjälp av dessa värden. Om du till exempel använder tabellstrukturen som visas nedan kan ett klientprogram använda en punktfråga för att hämta en enskild medarbetaretitet med hjälp av avdelningsnamnet och medarbetar-ID :t ( värdena PartitionKey och RowKey ). En klient kan också hämta entiteter sorterade efter medarbetar-ID inom varje avdelning.
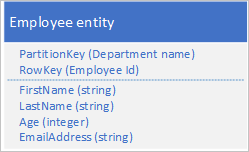
Om du också vill kunna hitta en medarbetaretitet baserat på värdet för en annan egenskap, till exempel e-postadress, måste du använda en mindre effektiv partitionsgenomsökning för att hitta en matchning. Det beror på att tabelltjänsten inte tillhandahåller sekundära index. Dessutom finns det inget alternativ för att begära en lista över anställda sorterade i en annan ordning än RowKey-ordningen .
Du förväntar dig en stor mängd transaktioner mot dessa entiteter och vill minimera risken för att Table Service begränsar klienten.
Lösning
För att undvika bristen på sekundära index kan du lagra flera kopior av varje entitet med varje kopia med olika PartitionKey - och RowKey-värden . Om du lagrar en entitet med de strukturer som visas nedan kan du effektivt hämta anställdatiteter baserat på e-postadress eller medarbetar-ID. Med prefixvärdena för PartitionKey, "empid_" och "email_" kan du identifiera vilket index du vill använda för en fråga.

Följande två filtervillkor (ett som söker efter medarbetar-ID och ett som söker efter e-postadress) anger båda punktfrågor:
- $filter=(PartitionKey eq 'empid_Sales') och (RowKey eq '000223')
- $filter=(PartitionKey eq 'email_Sales') och (RowKey eq 'jonesj@contoso.com')
Om du frågar efter ett intervall med medarbetarentiteter kan du ange ett intervall sorterat i ID-ordning för anställda eller ett intervall sorterat i e-postadressordning genom att fråga efter entiteter med rätt prefix i RowKey.
- Om du vill hitta alla anställda på försäljningsavdelningen med ett medarbetar-ID i intervallet 000100 till 000199 sorterade i orderanvändningen för anställda: $filter=(PartitionKey eq "empid_Sales") och (RowKey ge '000100') och (RowKey le '000199')
- Om du vill hitta alla anställda på försäljningsavdelningen med en e-postadress som börjar med "a" sorterad i e-postadressordning använder du: $filter=(PartitionKey eq 'email_Sales') och (RowKey ge 'a') och (RowKey lt 'b')
Filtersyntaxen som används i exemplen ovan kommer från REST-API:et för tabelltjänsten. Mer information finns i Fråga entiteter.
Problem och överväganden
Tänk på följande när du bestämmer hur du ska implementera mönstret:
Du kan hålla dina duplicerade entiteter så småningom konsekventa med varandra genom att använda mönstret Så småningom konsekventa transaktioner för att underhålla de primära och sekundära indexentiteterna.
Tabelllagring är relativt billigt att använda, så kostnaden för att lagra duplicerade data bör inte vara ett stort problem. Du bör dock alltid utvärdera kostnaden för din design baserat på dina förväntade lagringskrav och endast lägga till duplicerade entiteter som stöd för de frågor som klientprogrammet ska köra.
Värdet som används för RowKey måste vara unikt för varje entitet. Överväg att använda sammansatta nyckelvärden.
Utfyllnad av numeriska värden i RowKey (till exempel medarbetar-ID:t 000223) möjliggör korrekt sortering och filtrering baserat på övre och nedre gränser.
Du behöver inte nödvändigtvis duplicera alla egenskaper för din entitet. Om till exempel de frågor som söker efter entiteterna med hjälp av e-postadressen i RowKey aldrig behöver medarbetarens ålder kan dessa entiteter ha följande struktur:
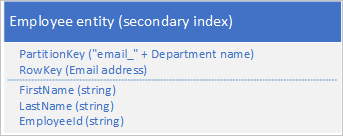
Det är vanligtvis bättre att lagra duplicerade data och se till att du kan hämta alla data som du behöver med en enda fråga än att använda en fråga för att hitta en entitet med hjälp av det sekundära indexet och en annan för att leta upp nödvändiga data i det primära indexet.
När du ska använda det här mönstret
Använd det här mönstret när klientprogrammet behöver hämta entiteter med en mängd olika nycklar, när klienten behöver hämta entiteter i olika sorteringsordningar och där du kan identifiera varje entitet med en mängd olika unika värden. Använd det här mönstret när du vill undvika att överskrida partitionens skalbarhetsgränser när du utför entitetssökningar med hjälp av de olika RowKey-värdena .
Relaterade mönster och vägledningar
Följande mönster och riktlinjer kan också vara relevanta när du implementerar det här mönstret:
- Så småningom konsekventa transaktionsmönster
- Mönster för sekundärt index mellan partitioner
- Mönster för sammansatt nyckel
- Entitetsgrupptransaktioner
- Arbeta med heterogena entitetstyper
Så småningom konsekventa transaktionsmönster
Aktivera så småningom konsekvent beteende över partitionsgränser eller lagringssystemgränser med hjälp av Azure-köer.
Kontext och problem
EGT möjliggör atomiska transaktioner mellan flera entiteter som delar samma partitionsnyckel. Av prestanda- och skalbarhetsskäl kan du välja att lagra entiteter som har konsekvenskrav i separata partitioner eller i ett separat lagringssystem: i ett sådant scenario kan du inte använda EGT för att upprätthålla konsekvens. Du kan till exempel ha ett krav på att upprätthålla eventuell konsekvens mellan:
- Entiteter som lagras i två olika partitioner i samma tabell, i olika tabeller eller i olika lagringskonton.
- En entitet som lagras i tabelltjänsten och en blob som lagras i Blob-tjänsten.
- En entitet som lagras i tabelltjänsten och en fil i ett filsystem.
- En entitet som lagras i tabelltjänsten men som ännu har indexerats med hjälp av Azure Cognitive tjänsten Search.
Lösning
Genom att använda Azure-köer kan du implementera en lösning som ger slutlig konsekvens mellan två eller flera partitioner eller lagringssystem. Anta att du har ett krav på att kunna arkivera gamla medarbetarentiteter för att illustrera den här metoden. Gamla medarbetarentiteter efterfrågas sällan och bör undantas från aktiviteter som hanterar nuvarande anställda. För att implementera det här kravet lagrar du aktiva anställda i tabellen Aktuell och gamla anställda i tabellen Arkiv . När du arkiverar en anställd måste du ta bort entiteten från tabellen Aktuell och lägga till entiteten i arkivtabellen, men du kan inte använda en EGT för att utföra dessa två åtgärder. För att undvika risken för att ett fel gör att en entitet visas i båda eller ingen av tabellerna måste arkivåtgärden så småningom vara konsekvent. Följande sekvensdiagram beskriver stegen i den här åtgärden. Mer information finns för undantagssökvägar i följande text.
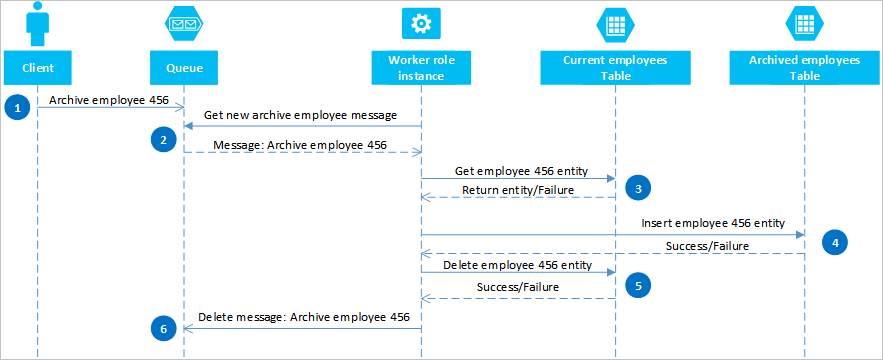
En klient initierar arkivåtgärden genom att placera ett meddelande i en Azure-kö, i det här exemplet för att arkivera medarbetaren #456. En arbetsroll avsöker kön efter nya meddelanden. när den hittar en läser den meddelandet och lämnar en dold kopia i kön. Arbetsrollen hämtar sedan en kopia av entiteten från tabellen Aktuell, infogar en kopia i arkivtabellenoch tar sedan bort originalet från tabellen Aktuell. Om det inte fanns några fel från föregående steg tar arbetsrollen slutligen bort det dolda meddelandet från kön.
I det här exemplet infogar steg 4 medarbetaren i tabellen Arkiv . Den kan lägga till medarbetaren i en blob i Blob-tjänsten eller en fil i ett filsystem.
Återställa från fel
Det är viktigt att åtgärderna i steg 4 och 5 måste vara idempotent om arbetsrollen behöver starta om arkivåtgärden. Om du använder tabelltjänsten bör du för steg 4 använda en "infoga eller ersätt"-åtgärd. För steg 5 bör du använda åtgärden "ta bort om det finns" i det klientbibliotek som du använder. Om du använder ett annat lagringssystem måste du använda en lämplig idempotent-åtgärd.
Om arbetsrollen aldrig slutför steg 6 visas meddelandet igen i kön som är redo för arbetsrollen för att försöka bearbeta det igen efter en tidsgräns. Arbetsrollen kan kontrollera hur många gånger ett meddelande i kön har lästs och om det behövs flaggar du att det är ett "gift"-meddelande för undersökning genom att skicka det till en separat kö. Mer information om hur du läser kömeddelanden och kontrollerar antalet köer finns i Hämta meddelanden.
Vissa fel från tabell- och kötjänsterna är tillfälliga fel och klientprogrammet bör innehålla lämplig logik för omprövning för att hantera dem.
Problem och överväganden
Tänk på följande när du bestämmer hur du ska implementera mönstret:
- Den här lösningen tillhandahåller inte transaktionsisolering. En klient kan till exempel läsa tabellerna Aktuell och Arkiv när arbetsrollen var mellan steg 4 och 5 och se en inkonsekvent vy över data. Data blir konsekventa så småningom.
- Du måste vara säker på att steg 4 och 5 är idempotent för att säkerställa eventuell konsekvens.
- Du kan skala lösningen med hjälp av flera köer och arbetsrollinstanser.
När du ska använda det här mönstret
Använd det här mönstret när du vill garantera eventuell konsekvens mellan entiteter som finns i olika partitioner eller tabeller. Du kan utöka det här mönstret för att säkerställa eventuell konsekvens för åtgärder i tabelltjänsten och Blob-tjänsten och andra datakällor som inte är Azure Storage, till exempel databas eller filsystem.
Relaterade mönster och vägledningar
Följande mönster och riktlinjer kan också vara relevanta när du implementerar det här mönstret:
- Entitetsgrupptransaktioner
- Sammanfoga eller ersätt
Kommentar
Om transaktionsisolering är viktigt för din lösning bör du överväga att utforma om tabellerna så att du kan använda EGT.
Mönster för indexentiteter
Underhåll indexentiteter för att möjliggöra effektiva sökningar som returnerar listor över entiteter.
Kontext och problem
Tabelltjänsten indexerar automatiskt entiteter med värdena PartitionKey och RowKey . Detta gör att ett klientprogram kan hämta en entitet effektivt med hjälp av en punktfråga. Med hjälp av tabellstrukturen nedan kan ett klientprogram till exempel effektivt hämta en enskild medarbetaretitet med hjälp av avdelningsnamnet och medarbetar-ID :t ( PartitionKey och RowKey).

Om du också vill kunna hämta en lista över medarbetarentiteter baserat på värdet för en annan icke-unik egenskap, till exempel deras efternamn, måste du använda en mindre effektiv partitionssökning för att hitta matchningar i stället för att använda ett index för att leta upp dem direkt. Det beror på att tabelltjänsten inte tillhandahåller sekundära index.
Lösning
Om du vill aktivera uppslag efter efternamn med entitetsstrukturen som visas ovan måste du underhålla listor över medarbetar-ID:n. Om du vill hämta de anställdas entiteter med ett visst efternamn, till exempel Jones, måste du först hitta listan över medarbetar-ID:n för anställda med Jones som efternamn och sedan hämta de anställdas entiteter. Det finns tre huvudsakliga alternativ för att lagra listorna över medarbetar-ID:t:
- Använd bloblagring.
- Skapa indexentiteter i samma partition som medarbetarnas entiteter.
- Skapa indexentiteter i en separat partition eller tabell.
Alternativ 1: Använd bloblagring
För det första alternativet skapar du en blob för varje unikt efternamn, och i varje blob lagrar du en lista över värdena PartitionKey (avdelning) och RowKey (anställds-ID) för anställda som har det efternamnet. När du lägger till eller tar bort en medarbetare bör du se till att innehållet i den relevanta blobben så småningom överensstämmer med de anställdas entiteter.
Alternativ 2: Skapa indexentiteter i samma partition
För det andra alternativet använder du indexentiteter som lagrar följande data:
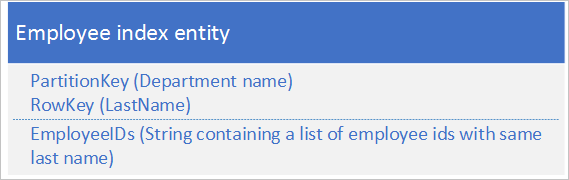
Egenskapen EmployeeIDs innehåller en lista över medarbetar-ID:t för anställda med det efternamn som lagras i RowKey.
Följande steg beskriver den process som du bör följa när du lägger till en ny anställd om du använder det andra alternativet. I det här exemplet lägger vi till en anställd med ID 000152 och ett efternamn Jones på försäljningsavdelningen:
- Hämta indexentiteten med partitionsnyckelvärdet "Sales" och RowKey-värdet "Jones". Spara ETag för den här entiteten som ska användas i steg 2.
- Skapa en entitetsgrupptransaktion (dvs. en batchåtgärd) som infogar den nya medarbetarentiteten (PartitionKey-värdet "Försäljning" och RowKey-värdet "000152") och uppdaterar indexentiteten (PartitionKey-värdet "Försäljning" och RowKey-värdet "Jones") genom att lägga till det nya medarbetar-ID:t i listan i fältet EmployeeIDs. Mer information om entitetsgrupptransaktioner finns i Entitetsgrupptransaktioner.
- Om entitetsgruppens transaktion misslyckas på grund av ett optimistiskt samtidighetsfel (någon annan har just ändrat indexentiteten) måste du börja om i steg 1 igen.
Du kan använda en liknande metod för att ta bort en anställd om du använder det andra alternativet. Att ändra en medarbetares efternamn är något mer komplext eftersom du måste köra en entitetsgrupptransaktion som uppdaterar tre entiteter: den anställdas entitet, indexentiteten för det gamla efternamnet och indexentiteten för det nya efternamnet. Du måste hämta varje entitet innan du gör några ändringar för att hämta de ETag-värden som du sedan kan använda för att utföra uppdateringarna med optimistisk samtidighet.
Följande steg beskriver den process som du bör följa när du behöver leta upp alla anställda med ett visst efternamn på en avdelning om du använder det andra alternativet. I det här exemplet letar vi upp alla anställda med efternamnet Jones på försäljningsavdelningen:
- Hämta indexentiteten med partitionsnyckelvärdet "Sales" och RowKey-värdet "Jones".
- Parsa listan över medarbetar-ID:t i fältet EmployeeIDs.
- Om du behöver ytterligare information om var och en av dessa anställda (till exempel deras e-postadresser) hämtar du var och en av de anställdas entiteter med partitionsnyckelvärdet "Försäljning" och RowKey-värden från listan över anställda som du fick i steg 2.
Alternativ 3: Skapa indexentiteter i en separat partition eller tabell
För det tredje alternativet använder du indexentiteter som lagrar följande data:

Egenskapen EmployeeDetails innehåller en lista över anställnings-ID:t och avdelningsnamnparen för anställda med det efternamn som lagras i RowKey.
Med det tredje alternativet kan du inte använda EGT för att upprätthålla konsekvens eftersom indexentiteterna finns i en separat partition från de anställdas entiteter. Se till att indexentiteterna så småningom är konsekventa med de anställdas entiteter.
Problem och överväganden
Tänk på följande när du bestämmer hur du ska implementera mönstret:
- Den här lösningen kräver minst två frågor för att hämta matchande entiteter: en för att fråga indexentiteterna för att hämta listan med RowKey-värden och sedan frågor för att hämta varje entitet i listan.
- Med tanke på att en enskild entitet har en maximal storlek på 1 MB förutsätter alternativet #2 och alternativ 3 i lösningen att listan över medarbetar-ID:n för ett angivet efternamn aldrig är större än 1 MB. Om listan över medarbetar-ID:t sannolikt är större än 1 MB använder du alternativ 1 och lagrar indexdata i bloblagring.
- Om du använder alternativ 2 (med egt för att hantera tillägg och borttagning av anställda och ändring av en medarbetares efternamn) måste du utvärdera om transaktionsvolymen närmar sig skalbarhetsgränserna i en viss partition. Om så är fallet bör du överväga en så småningom konsekvent lösning (alternativ 1 eller alternativ 3) som använder köer för att hantera uppdateringsbegäranden och gör att du kan lagra dina indexentiteter i en separat partition från de anställdas entiteter.
- Alternativ 2 i den här lösningen förutsätter att du vill söka efter efternamn inom en avdelning: du vill till exempel hämta en lista över anställda med ett efternamn Jones på försäljningsavdelningen. Om du vill kunna slå upp alla anställda med ett efternamn jones i hela organisationen använder du antingen alternativ nr 1 eller alternativ 3.
- Du kan implementera en köbaserad lösning som ger slutlig konsekvens (se mönster för så småningom konsekventa transaktioner för mer information).
När du ska använda det här mönstret
Använd det här mönstret när du vill leta upp en uppsättning entiteter som alla delar ett gemensamt egenskapsvärde, till exempel alla anställda med efternamnet Jones.
Relaterade mönster och vägledningar
Följande mönster och riktlinjer kan också vara relevanta när du implementerar det här mönstret:
- Mönster för sammansatt nyckel
- Så småningom konsekventa transaktionsmönster
- Entitetsgrupptransaktioner
- Arbeta med heterogena entitetstyper
Avormaliseringsmönster
Kombinera relaterade data i en enda entitet så att du kan hämta alla data du behöver med en enskild punktfråga.
Kontext och problem
I en relationsdatabas normaliserar du vanligtvis data för att ta bort duplicering, vilket resulterar i frågor som hämtar data från flera tabeller. Om du normaliserar dina data i Azure-tabeller måste du göra flera turer från klienten till servern för att hämta dina relaterade data. Med tabellstrukturen nedan behöver du till exempel två turer för att hämta information för en avdelning: en för att hämta den avdelningsentitet som innehåller chefens ID och sedan en annan begäran om att hämta chefens information i en medarbetaretitet.

Lösning
I stället för att lagra data i två separata entiteter avnormaliserar du data och behåller en kopia av chefens information i avdelningsentiteten. Till exempel:
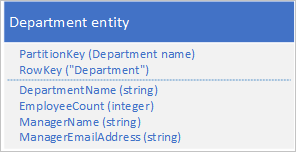
Med avdelningsentiteter som lagras med dessa egenskaper kan du nu hämta all information du behöver om en avdelning med hjälp av en punktfråga.
Problem och överväganden
Tänk på följande när du bestämmer hur du ska implementera mönstret:
- Det finns vissa kostnader för att lagra vissa data två gånger. Prestandafördelarna (till följd av färre begäranden till lagringstjänsten) uppväger vanligtvis den marginella ökningen av lagringskostnaderna (och den här kostnaden kompenseras delvis av en minskning av antalet transaktioner som du behöver för att hämta information om en avdelning).
- Du måste upprätthålla konsekvensen för de två entiteter som lagrar information om chefer. Du kan hantera konsekvensproblemet genom att använda EGT för att uppdatera flera entiteter i en enda atomisk transaktion: i det här fallet lagras avdelningsentiteten och den anställdatiteten för avdelningschefen i samma partition.
När du ska använda det här mönstret
Använd det här mönstret när du ofta behöver söka efter relaterad information. Det här mönstret minskar antalet frågor som klienten måste göra för att hämta de data som krävs.
Relaterade mönster och vägledningar
Följande mönster och riktlinjer kan också vara relevanta när du implementerar det här mönstret:
- Mönster för sammansatt nyckel
- Entitetsgrupptransaktioner
- Arbeta med heterogena entitetstyper
Mönster för sammansatt nyckel
Använd sammansatta RowKey-värden för att göra det möjligt för en klient att söka efter relaterade data med en enskild punktfråga.
Kontext och problem
I en relationsdatabas är det naturligt att använda kopplingar i frågor för att returnera relaterade data till klienten i en enda fråga. Du kan till exempel använda medarbetar-ID:t för att leta upp en lista över relaterade entiteter som innehåller prestanda och granska data för den medarbetaren.
Anta att du lagrar medarbetarentiteter i tabelltjänsten med hjälp av följande struktur:
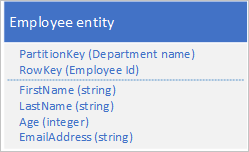
Du måste också lagra historiska data som rör granskningar och prestanda för varje år som medarbetaren har arbetat för din organisation och du måste kunna komma åt den här informationen per år. Ett alternativ är att skapa en annan tabell som lagrar entiteter med följande struktur:
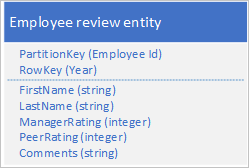
Observera att med den här metoden kan du välja att duplicera viss information (till exempel förnamn och efternamn) i den nya entiteten så att du kan hämta dina data med en enda begäran. Du kan dock inte upprätthålla stark konsekvens eftersom du inte kan använda en EGT för att uppdatera de två entiteterna atomiskt.
Lösning
Lagra en ny entitetstyp i den ursprungliga tabellen med hjälp av entiteter med följande struktur:
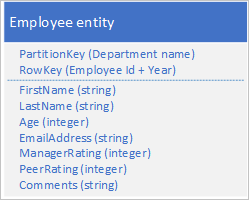
Observera hur RowKey nu är en sammansatt nyckel som består av medarbetar-ID:t och året för granskningsdata som gör att du kan hämta medarbetarens prestanda och granska data med en enda begäran för en enda entitet.
I följande exempel beskrivs hur du kan hämta alla granskningsdata för en viss anställd (till exempel medarbetare 000123 på försäljningsavdelningen):
$filter=(PartitionKey eq 'Sales') och (RowKey ge 'empid_000123') och (RowKey lt '000123_2012')&$select=RowKey,Manager Rating,Peer Rating,Comments
Problem och överväganden
Tänk på följande när du bestämmer hur du ska implementera mönstret:
- Du bör använda ett lämpligt avgränsartecken som gör det enkelt att parsa RowKey-värdet : till exempel 000123_2012.
- Du lagrar även den här entiteten i samma partition som andra entiteter som innehåller relaterade data för samma medarbetare, vilket innebär att du kan använda EGT för att upprätthålla stark konsekvens.
- Du bör fundera på hur ofta du ska köra frågor mot data för att avgöra om det här mönstret är lämpligt. Om du till exempel kommer åt granskningsdata sällan och de viktigaste anställdas data ofta bör du behålla dem som separata entiteter.
När du ska använda det här mönstret
Använd det här mönstret när du behöver lagra en eller flera relaterade entiteter som du frågar ofta.
Relaterade mönster och vägledningar
Följande mönster och riktlinjer kan också vara relevanta när du implementerar det här mönstret:
- Entitetsgrupptransaktioner
- Arbeta med heterogena entitetstyper
- Så småningom konsekventa transaktionsmönster
Loggsvansmönster
Hämta de n entiteter som senast har lagts till i en partition med hjälp av ett RowKey-värde som sorterar i omvänd datum- och tidsordning.
Kontext och problem
Ett vanligt krav är att kunna hämta de senast skapade entiteterna, till exempel de 10 senaste utgiftsanspråken som skickats av en anställd. Tabellfrågor stöder en $top frågeåtgärd för att returnera de första n entiteterna från en uppsättning: det finns ingen motsvarande frågeåtgärd för att returnera de sista n entiteterna i en uppsättning.
Lösning
Lagra entiteterna med hjälp av en RowKey som naturligt sorterar i omvänd datum-/tidsordning med så att den senaste posten alltid är den första i tabellen.
Om du till exempel vill kunna hämta de 10 senaste utgiftsanspråken som skickats av en anställd kan du använda ett omvänt tickvärde som härletts från aktuellt datum/tid. Följande C#-kodexempel visar ett sätt att skapa ett lämpligt värde för "inverterade fästingar" för en RowKey som sorterar från den senaste till den äldsta:
string invertedTicks = string.Format("{0:D19}", DateTime.MaxValue.Ticks - DateTime.UtcNow.Ticks);
Du kan gå tillbaka till datumtidsvärdet med hjälp av följande kod:
DateTime dt = new DateTime(DateTime.MaxValue.Ticks - Int64.Parse(invertedTicks));
Tabellfrågan ser ut så här:
https://myaccount.table.core.windows.net/EmployeeExpense(PartitionKey='empid')?$top=10
Problem och överväganden
Tänk på följande när du bestämmer hur du ska implementera mönstret:
- Du måste fylla det omvända tickvärdet med inledande nollor för att säkerställa att strängvärdet sorteras som förväntat.
- Du måste vara medveten om skalbarhetsmålen på partitionsnivå. Var försiktig så att du inte skapar partitioner med frekventa platser.
När du ska använda det här mönstret
Använd det här mönstret när du behöver komma åt entiteter i omvänd datum-/tidsordning eller när du behöver komma åt de senast tillagda entiteterna.
Relaterade mönster och vägledningar
Följande mönster och riktlinjer kan också vara relevanta när du implementerar det här mönstret:
Mönster för borttagning av stora volymer
Aktivera borttagning av en stor mängd entiteter genom att lagra alla entiteter för samtidig borttagning i sin egen separata tabell. du tar bort entiteterna genom att ta bort tabellen.
Kontext och problem
Många program tar bort gamla data som inte längre behöver vara tillgängliga för ett klientprogram eller som programmet har arkiverat till ett annat lagringsmedium. Du identifierar vanligtvis sådana data efter ett datum: till exempel måste du ta bort poster för alla inloggningsbegäranden som är mer än 60 dagar gamla.
En möjlig design är att använda datum och tid för inloggningsbegäran i RowKey:
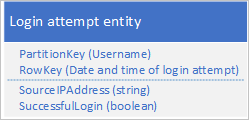
Den här metoden undviker partitions hotspots eftersom programmet kan infoga och ta bort inloggningsentiteter för varje användare i en separat partition. Den här metoden kan dock vara kostsam och tidskrävande om du har ett stort antal entiteter eftersom du först måste utföra en tabellgenomsökning för att identifiera alla entiteter som ska tas bort, och sedan måste du ta bort varje gammal entitet. Du kan minska antalet tur- och returresor till servern som krävs för att ta bort de gamla entiteterna genom att batcha flera borttagningsbegäranden i EGT.
Lösning
Använd en separat tabell för varje dag med inloggningsförsök. Du kan använda entitetsdesignen ovan för att undvika hotspots när du infogar entiteter, och att ta bort gamla entiteter handlar nu bara om att ta bort en tabell varje dag (en enda lagringsåtgärd) i stället för att hitta och ta bort hundratals och tusentals enskilda inloggningsentiteter varje dag.
Problem och överväganden
Tänk på följande när du bestämmer hur du ska implementera mönstret:
- Har din design stöd för andra sätt som ditt program kommer att använda data som att leta upp specifika entiteter, länka med andra data eller generera sammanställd information?
- Undviker din design hot spots när du infogar nya entiteter?
- Förvänta dig en fördröjning om du vill återanvända samma tabellnamn när du har raderat det. Det är bättre att alltid använda unika tabellnamn.
- Förvänta dig vissa begränsningar när du först använder en ny tabell medan tabelltjänsten lär sig åtkomstmönstren och distribuerar partitionerna mellan noder. Du bör tänka på hur ofta du behöver skapa nya tabeller.
När du ska använda det här mönstret
Använd det här mönstret när du har en stor mängd entiteter som du måste ta bort samtidigt.
Relaterade mönster och vägledningar
Följande mönster och riktlinjer kan också vara relevanta när du implementerar det här mönstret:
- Entitetsgrupptransaktioner
- Ändra entiteter
Mönster för dataserier
Lagra fullständiga dataserier i en enda entitet för att minimera antalet begäranden som du gör.
Kontext och problem
Ett vanligt scenario är att ett program lagrar en serie data som vanligtvis måste hämtas samtidigt. Ditt program kan till exempel registrera hur många snabbmeddelanden varje anställd skickar varje timme och sedan använda den här informationen för att rita hur många meddelanden varje användare har skickat under de senaste 24 timmarna. En design kan vara att lagra 24 entiteter för varje anställd:
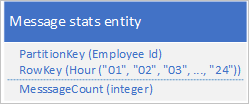
Med den här designen kan du enkelt hitta och uppdatera entiteten så att den uppdateras för varje anställd när programmet behöver uppdatera värdet för antal meddelanden. Men för att hämta informationen för att rita ett diagram över aktiviteten under de senaste 24 timmarna måste du hämta 24 entiteter.
Lösning
Använd följande design med en separat egenskap för att lagra antalet meddelanden för varje timme:
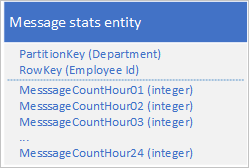
Med den här designen kan du använda en sammanslagningsåtgärd för att uppdatera antalet meddelanden för en anställd under en viss timme. Nu kan du hämta all information som du behöver för att rita diagrammet med hjälp av en begäran om en enda entitet.
Problem och överväganden
Tänk på följande när du bestämmer hur du ska implementera mönstret:
- Om din fullständiga dataserie inte passar in i en enda entitet (en entitet kan ha upp till 252 egenskaper) använder du ett alternativt datalager, till exempel en blob.
- Om du har flera klienter som uppdaterar en entitet samtidigt måste du använda ETag för att implementera optimistisk samtidighet. Om du har många klienter kan det uppstå hög konkurrens.
När du ska använda det här mönstret
Använd det här mönstret när du behöver uppdatera och hämta en dataserie som är associerad med en enskild entitet.
Relaterade mönster och vägledningar
Följande mönster och riktlinjer kan också vara relevanta när du implementerar det här mönstret:
- Mönster för stora entiteter
- Sammanfoga eller ersätt
- Så småningom konsekventa transaktionsmönster (om du lagrar dataserien i en blob)
Mönster för breda entiteter
Använd flera fysiska entiteter för att lagra logiska entiteter med fler än 252 egenskaper.
Kontext och problem
En enskild entitet får inte ha fler än 252 egenskaper (exklusive de obligatoriska systemegenskaperna) och kan inte lagra mer än 1 MB data totalt. I en relationsdatabas skulle du vanligtvis kringgå alla gränser för storleken på en rad genom att lägga till en ny tabell och framtvinga en 1-till-1-relation mellan dem.
Lösning
Med tabelltjänsten kan du lagra flera entiteter för att representera ett enda stort affärsobjekt med fler än 252 egenskaper. Om du till exempel vill lagra antalet snabbmeddelanden som skickats av varje anställd under de senaste 365 dagarna kan du använda följande design som använder två entiteter med olika scheman:
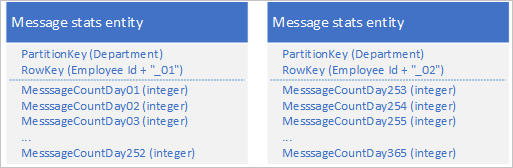
Om du behöver göra en ändring som kräver att båda entiteterna uppdateras för att hålla dem synkroniserade med varandra kan du använda en EGT. Annars kan du använda en enda sammanslagningsåtgärd för att uppdatera antalet meddelanden för en viss dag. Om du vill hämta alla data för en enskild anställd måste du hämta båda entiteterna, vilket du kan göra med två effektiva begäranden som använder både en PartitionKey och ett RowKey-värde .
Problem och överväganden
Tänk på följande när du bestämmer hur du ska implementera mönstret:
- När du hämtar en fullständig logisk entitet ingår minst två lagringstransaktioner: en för att hämta varje fysisk entitet.
När du ska använda det här mönstret
Använd det här mönstret när du behöver lagra entiteter vars storlek eller antal egenskaper överskrider gränserna för en enskild entitet i tabelltjänsten.
Relaterade mönster och vägledningar
Följande mönster och riktlinjer kan också vara relevanta när du implementerar det här mönstret:
- Entitetsgrupptransaktioner
- Sammanfoga eller ersätt
Mönster för stora entiteter
Använd bloblagring för att lagra stora egenskapsvärden.
Kontext och problem
En enskild entitet kan inte lagra mer än 1 MB data totalt. Om en eller flera av dina egenskaper lagrar värden som gör att den totala storleken på entiteten överskrider det här värdet kan du inte lagra hela entiteten i tabelltjänsten.
Lösning
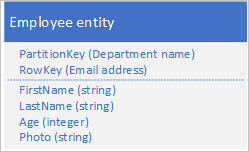
Om entiteten överskrider 1 MB eftersom en eller flera egenskaper innehåller en stor mängd data kan du lagra data i Blob-tjänsten och sedan lagra blobens adress i en egenskap i entiteten. Du kan till exempel lagra fotot av en anställd i Blob Storage och lagra en länk till fotot i egenskapen Foto för din medarbetaretitet:
Problem och överväganden
Tänk på följande när du bestämmer hur du ska implementera mönstret:
- Om du vill upprätthålla slutlig konsekvens mellan entiteten i tabelltjänsten och data i blobtjänsten använder du mönstret Så småningom konsekventa transaktioner för att underhålla dina entiteter.
- Att hämta en fullständig entitet omfattar minst två lagringstransaktioner: en för att hämta entiteten och en för att hämta blobdata.
När du ska använda det här mönstret
Använd det här mönstret när du behöver lagra entiteter vars storlek överskrider gränserna för en enskild entitet i tabelltjänsten.
Relaterade mönster och vägledningar
Följande mönster och riktlinjer kan också vara relevanta när du implementerar det här mönstret:
Prepend/lägg till antimönster
Öka skalbarheten när du har en hög mängd infogningar genom att sprida infogningarna över flera partitioner.
Kontext och problem
Att lägga till eller lägga till entiteter till dina lagrade entiteter resulterar vanligtvis i att programmet lägger till nya entiteter till den första eller sista partitionen i en sekvens med partitioner. I det här fallet sker alla infogningar vid en viss tidpunkt i samma partition, vilket skapar en hotspot som hindrar tabelltjänsten från att belastningsutjämninga infogningar över flera noder, vilket kan leda till att programmet når skalbarhetsmålen för partitionen. Om du till exempel har ett program som loggar nätverks- och resursåtkomst av anställda kan en entitetsstruktur som visas nedan leda till att den aktuella timmens partition blir en hotspot om transaktionsvolymen når skalbarhetsmålet för en enskild partition:

Lösning
Följande alternativa entitetsstruktur undviker en hotspot på en viss partition när programmet loggar händelser:
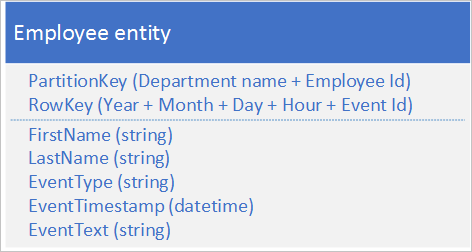
Observera i det här exemplet hur både PartitionKey och RowKey är sammansatta nycklar. PartitionKey använder både avdelnings- och medarbetar-ID:t för att distribuera loggningen över flera partitioner.
Problem och överväganden
Tänk på följande när du bestämmer hur du ska implementera mönstret:
- Stöder den alternativa nyckelstrukturen som undviker att skapa frekventa partitioner på infogningar effektivt de frågor som klientprogrammet gör?
- Innebär din förväntade transaktionsvolym att du sannolikt kommer att nå skalbarhetsmålen för en enskild partition och begränsas av lagringstjänsten?
När du ska använda det här mönstret
Undvik antimönstret prepend/append när din transaktionsvolym sannolikt kommer att leda till begränsning av lagringstjänsten när du kommer åt en frekvent partition.
Relaterade mönster och vägledningar
Följande mönster och riktlinjer kan också vara relevanta när du implementerar det här mönstret:
Logga dataskyddsmönster
Vanligtvis bör du använda blobtjänsten i stället för tabelltjänsten för att lagra loggdata.
Kontext och problem
Ett vanligt användningsfall för loggdata är att hämta ett urval av loggposter för ett visst datum-/tidsintervall: du vill till exempel hitta alla fel och kritiska meddelanden som programmet loggade mellan 15:04 och 15:06 på ett visst datum. Du vill inte använda datum och tid för loggmeddelandet för att fastställa vilken partition du sparar loggentiteter till: det resulterar i en frekvent partition eftersom alla loggentiteter vid en viss tidpunkt delar samma PartitionKey-värde (se avsnittet Prepend/append anti-pattern). Följande entitetsschema för ett loggmeddelande resulterar till exempel i en frekvent partition eftersom programmet skriver alla loggmeddelanden till partitionen för aktuellt datum och timme:
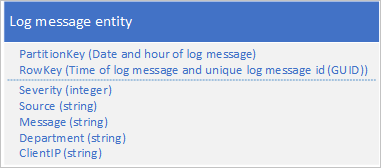
I det här exemplet innehåller RowKey datum och tid för loggmeddelandet för att säkerställa att loggmeddelanden lagras sorterade i datum-/tidsordning och innehåller ett meddelande-ID om flera loggmeddelanden delar samma datum och tid.
En annan metod är att använda en PartitionKey som säkerställer att programmet skriver meddelanden över ett antal partitioner. Om källan till loggmeddelandet till exempel ger ett sätt att distribuera meddelanden över många partitioner kan du använda följande entitetsschema:
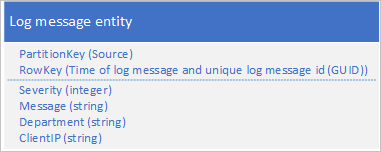
Problemet med det här schemat är dock att om du vill hämta alla loggmeddelanden under ett visst tidsintervall måste du söka i varje partition i tabellen.
Lösning
I föregående avsnitt lyftes problemet med att försöka använda tabelltjänsten för att lagra loggposter och föreslog två, otillfredsställande, designer. En lösning ledde till en frekvent partition med risk för dålig prestanda när loggmeddelanden skrevs. den andra lösningen resulterade i dåliga frågeprestanda på grund av kravet på att genomsöka varje partition i tabellen för att hämta loggmeddelanden under ett visst tidsintervall. Blob Storage erbjuder en bättre lösning för den här typen av scenario och det är så Azure Lagringsanalys lagrar loggdata som samlas in.
I det här avsnittet beskrivs hur Lagringsanalys lagrar loggdata i Blob Storage som en illustration av den här metoden för att lagra data som du vanligtvis frågar efter intervall.
Lagringsanalys lagrar loggmeddelanden i ett avgränsat format i flera blobar. Det avgränsade formatet gör det enkelt för ett klientprogram att parsa data i loggmeddelandet.
Lagringsanalys använder en namngivningskonvention för blobar som gör att du kan hitta bloben (eller blobarna) som innehåller de loggmeddelanden som du söker efter. Till exempel innehåller en blob med namnet "queue/2014/07/31/1800/000001.log" loggmeddelanden som relaterar till kötjänsten för timmen som börjar kl. 18:00 den 31 juli 2014. "000001" anger att det här är den första loggfilen för den här perioden. Lagringsanalys registrerar också tidsstämplarna för de första och sista loggmeddelanden som lagras i filen som en del av blobens metadata. Med API:et för bloblagring kan du hitta blobar i en container baserat på ett namnprefix: om du vill hitta alla blobar som innehåller köloggdata för timmen med början kl. 18:00 kan du använda prefixet "queue/2014/07/31/1800".
Lagringsanalys buffrar loggmeddelanden internt och uppdaterar sedan regelbundet lämplig blob eller skapar en ny med den senaste batchen med loggposter. Detta minskar antalet skrivningar som måste utföras till blobtjänsten.
Om du implementerar en liknande lösning i ditt eget program måste du överväga hur du ska hantera kompromissen mellan tillförlitlighet (skriva varje loggpost till bloblagring när det händer) och kostnad och skalbarhet (buffring av uppdateringar i ditt program och skriva dem till bloblagring i batchar).
Problem och överväganden
Tänk på följande när du bestämmer hur loggdata ska lagras:
- Om du skapar en tabelldesign som undviker potentiella frekventa partitioner kan du upptäcka att du inte kan komma åt dina loggdata effektivt.
- För att bearbeta loggdata behöver en klient ofta läsa in många poster.
- Även om loggdata ofta är strukturerade kan bloblagring vara en bättre lösning.
Implementeringöverväganden
I det här avsnittet beskrivs några av de överväganden som du bör tänka på när du implementerar de mönster som beskrivs i föregående avsnitt. De flesta av det här avsnittet använder exempel skrivna i C# som använder Storage-klientbiblioteket (version 4.3.0 i skrivande stund).
Hämtar entiteter
Som beskrivs i avsnittet Design för frågor är den mest effektiva frågan en punktfråga. I vissa scenarier kan du dock behöva hämta flera entiteter. I det här avsnittet beskrivs några vanliga metoder för att hämta entiteter med hjälp av Storage-klientbiblioteket.
Köra en punktfråga med hjälp av Storage-klientbiblioteket
Det enklaste sättet att köra en punktfråga är att använda metoden GetEntityAsync enligt följande C#-kodfragment som hämtar en entitet med partitionsnyckeln "Sales" och rowkey-värdet "212":
EmployeeEntity employee = await employeeTable.GetEntityAsync<EmployeeEntity>("Sales", "212");
Observera hur det här exemplet förväntar sig att entiteten den hämtar ska vara av typen EmployeeEntity.
Hämtar flera entiteter med LINQ
Du kan använda LINQ för att hämta flera entiteter från tabelltjänsten när du arbetar med Microsoft Azure Cosmos DB Table Standard Library.
dotnet add package Azure.Data.Tables
Om du vill att exemplen nedan ska fungera måste du inkludera namnområden:
using System.Linq;
using Azure.Data.Tables
Du kan hämta flera entiteter genom att ange en fråga med en filtersats . För att undvika en tabellgenomsökning bör du alltid inkludera Värdet PartitionKey i filtersatsen och om möjligt RowKey-värdet för att undvika tabell- och partitionsgenomsökningar. Tabelltjänsten har stöd för en begränsad uppsättning jämförelseoperatorer (större än, större än eller lika med, mindre än, mindre än eller lika, lika med och inte lika med) som ska användas i filtersatsen.
I följande exempel employeeTable är ett TableClient-objekt . Det här exemplet hittar alla anställda vars efternamn börjar med "B" (förutsatt att RowKey lagrar efternamn) på försäljningsavdelningen (förutsatt att PartitionKey lagrar avdelningsnamnet):
var employees = employeeTable.Query<EmployeeEntity>(e => (e.PartitionKey == "Sales" && e.RowKey.CompareTo("B") >= 0 && e.RowKey.CompareTo("C") < 0));
Observera hur frågan anger både en RowKey och en PartitionKey för att säkerställa bättre prestanda.
Följande kodexempel visar motsvarande funktioner utan att använda LINQ-syntax:
var employees = employeeTable.Query<EmployeeEntity>(filter: $"PartitionKey eq 'Sales' and RowKey ge 'B' and RowKey lt 'C'");
Kommentar
Exempel på frågemetoder innehåller de tre filtervillkoren.
Hämtar ett stort antal entiteter från en fråga
En optimal fråga returnerar en enskild entitet baserat på ett PartitionKey-värde och ett RowKey-värde . I vissa scenarier kan du dock ha ett krav på att returnera många entiteter från samma partition eller till och med från många partitioner.
Du bör alltid testa programmets prestanda fullt ut i sådana scenarier.
En fråga mot tabelltjänsten kan returnera högst 1 000 entiteter samtidigt och kan köras i högst fem sekunder. Om resultatuppsättningen innehåller fler än 1 000 entiteter, om frågan inte slutfördes inom fem sekunder, eller om frågan korsar partitionsgränsen, returnerar Tabelltjänsten en fortsättningstoken för att klientprogrammet ska kunna begära nästa uppsättning entiteter. Mer information om hur fortsättningstoken fungerar finns i Timeout och sidnumrering för frågor.
Om du använder Azure Tables-klientbiblioteket kan det automatiskt hantera fortsättningstoken åt dig eftersom det returnerar entiteter från tabelltjänsten. Följande C#-kodexempel med klientbiblioteket hanterar automatiskt fortsättningstoken om tabelltjänsten returnerar dem i ett svar:
var employees = employeeTable.Query<EmployeeEntity>("PartitionKey eq 'Sales'")
foreach (var emp in employees)
{
// ...
}
Du kan också ange det maximala antalet entiteter som returneras per sida. I följande exempel visas hur du frågar entiteter med maxPerPage:
var employees = employeeTable.Query<EmployeeEntity>(maxPerPage: 10);
// Iterate the Pageable object by page
foreach (var page in employees.AsPages())
{
// Iterate the entities returned for this page
foreach (var emp in page.Values)
{
// ...
}
}
I mer avancerade scenarier kanske du vill lagra fortsättningstoken som returneras från tjänsten så att koden styr exakt när nästa sidor hämtas. I följande exempel visas ett grundläggande scenario med hur token kan hämtas och tillämpas på sidnumrerade resultat:
string continuationToken = null;
bool moreResultsAvailable = true;
while (moreResultsAvailable)
{
var page = employeeTable
.Query<EmployeeEntity>()
.AsPages(continuationToken, pageSizeHint: 10)
.FirstOrDefault(); // pageSizeHint limits the number of results in a single page, so we only enumerate the first page
if (page == null)
break;
// Get the continuation token from the page
// Note: This value can be stored so that the next page query can be executed later
continuationToken = page.ContinuationToken;
var pageResults = page.Values;
moreResultsAvailable = pageResults.Any() && continuationToken != null;
// Iterate the results for this page
foreach (var result in pageResults)
{
// ...
}
}
Genom att uttryckligen använda fortsättningstoken kan du styra när ditt program hämtar nästa datasegment. Om ditt klientprogram till exempel gör det möjligt för användare att bläddra igenom de entiteter som lagras i en tabell kan en användare besluta att inte bläddra igenom alla entiteter som hämtas av frågan så att programmet endast använder en fortsättningstoken för att hämta nästa segment när användaren hade slutfört växlingen genom alla entiteter i det aktuella segmentet. Den här metoden har flera fördelar:
- Det gör att du kan begränsa mängden data som ska hämtas från tabelltjänsten och att du flyttar över nätverket.
- Det gör att du kan utföra asynkron I/O i .NET.
- Det gör att du kan serialisera fortsättningstoken till beständig lagring så att du kan fortsätta i händelse av en programkrasch.
Kommentar
En fortsättningstoken returnerar vanligtvis ett segment som innehåller 1 000 entiteter, även om det kan vara färre. Detta är också fallet om du begränsar antalet poster som en fråga returnerar med hjälp av Take för att returnera de första n entiteterna som matchar dina uppslagsvillkor: tabelltjänsten kan returnera ett segment som innehåller färre än n entiteter tillsammans med en fortsättningstoken så att du kan hämta de återstående entiteterna.
Projektion på serversidan
En enskild entitet kan ha upp till 255 egenskaper och vara upp till 1 MB stor. När du frågar tabellen och hämtar entiteter behöver du kanske inte alla egenskaper och kan undvika att överföra data i onödan (för att minska svarstiden och kostnaden). Du kan använda projektion på serversidan för att överföra bara de egenskaper du behöver. I följande exempel hämtas bara egenskapen E-post (tillsammans med PartitionKey, RowKey, Timestamp och ETag) från de entiteter som valts av frågan.
var subsetResults = query{
for employee in employeeTable.Query<EmployeeEntity>("PartitionKey eq 'Sales'") do
select employee.Email
}
foreach (var e in subsetResults)
{
Console.WriteLine("RowKey: {0}, EmployeeEmail: {1}", e.RowKey, e.Email);
}
Observera hur RowKey-värdet är tillgängligt även om det inte ingick i listan med egenskaper som ska hämtas.
Ändra entiteter
Med storage-klientbiblioteket kan du ändra dina entiteter som lagras i tabelltjänsten genom att infoga, ta bort och uppdatera entiteter. Du kan använda EGT för att batcha flera infogningar, uppdatera och ta bort åtgärder tillsammans för att minska antalet tur- och returresor som krävs och förbättra lösningens prestanda.
Undantag som utlöses när Storage-klientbiblioteket kör en EGT inkluderar vanligtvis indexet för entiteten som gjorde att batchen misslyckades. Det här är användbart när du felsöker kod som använder EGT.
Du bör också överväga hur din design påverkar hur klientprogrammet hanterar samtidighets- och uppdateringsåtgärder.
Hantera samtidighet
Som standard implementerar tabelltjänsten optimistiska samtidighetskontroller på nivån för enskilda entiteter för åtgärderna Insert, Merge och Delete , även om det är möjligt för en klient att tvinga tabelltjänsten att kringgå dessa kontroller. Mer information om hur tabelltjänsten hanterar samtidighet finns i Hantera samtidighet i Microsoft Azure Storage.
Sammanfoga eller ersätt
Metoden Ersätt för klassen TableOperation ersätter alltid den fullständiga entiteten i tabelltjänsten. Om du inte inkluderar en egenskap i begäran när den egenskapen finns i den lagrade entiteten, tar begäran bort den egenskapen från den lagrade entiteten. Om du inte uttryckligen vill ta bort en egenskap från en lagrad entitet måste du inkludera varje egenskap i begäran.
Du kan använda metoden Merge i klassen TableOperation för att minska mängden data som du skickar till table-tjänsten när du vill uppdatera en entitet. Metoden Merge ersätter alla egenskaper i den lagrade entiteten med egenskapsvärden från entiteten som ingår i begäran, men lämnar alla egenskaper intakta i den lagrade entiteten som inte ingår i begäran. Detta är användbart om du har stora entiteter och bara behöver uppdatera ett litet antal egenskaper i en begäran.
Kommentar
Metoderna Ersätt och sammanfoga misslyckas om entiteten inte finns. Alternativt kan du använda metoderna InsertOrReplace och InsertOrMerge som skapar en ny entitet om den inte finns.
Arbeta med heterogena entitetstyper
Tabelltjänsten är ett schemalöst tabelllager som innebär att en enskild tabell kan lagra entiteter av flera typer, vilket ger stor flexibilitet i din design. I följande exempel visas en tabell som lagrar både anställda och avdelningsentiteter:
| PartitionKey | RowKey | Tidsstämpel | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| |||||||||||
| |||||||||||
|
|||||||||||
|
Varje entitet måste fortfarande ha värden för PartitionKey, RowKey och Timestamp , men kan ha valfri uppsättning egenskaper. Dessutom finns det inget som anger typen av en entitet om du inte väljer att lagra den informationen någonstans. Det finns två alternativ för att identifiera entitetstypen:
- Förbered entitetstypen till RowKey (eller eventuellt PartitionKey). Till exempel EMPLOYEE_000123 eller DEPARTMENT_SALES som RowKey-värden .
- Använd en separat egenskap för att registrera entitetstypen enligt tabellen nedan.
| PartitionKey | RowKey | Tidsstämpel | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| |||||||||||||
| |||||||||||||
|
|||||||||||||
|
Det första alternativet, som väntar på entitetstypen till RowKey, är användbart om det finns en möjlighet att två entiteter av olika typer kan ha samma nyckelvärde. Den grupperar också entiteter av samma typ tillsammans i partitionen.
De tekniker som beskrivs i det här avsnittet är särskilt relevanta för diskussionen Arvsrelationer tidigare i den här guiden i artikeln Modelleringsrelationer.
Kommentar
Du bör överväga att inkludera ett versionsnummer i värdet för entitetstypen för att göra det möjligt för klientprogram att utveckla POCO-objekt och arbeta med olika versioner.
Resten av det här avsnittet beskriver några av funktionerna i Storage-klientbiblioteket som underlättar arbete med flera entitetstyper i samma tabell.
Hämtar heterogena entitetstyper
Om du använder tabellklientbiblioteket har du tre alternativ för att arbeta med flera entitetstyper.
Om du känner till typen av entitet som lagrats med ett specifikt RowKey- och PartitionKey-värden kan du ange entitetstypen när du hämtar entiteten enligt föregående två exempel som hämtar entiteter av typen EmployeeEntity: Kör en punktfråga med hjälp av Storage-klientbiblioteket och Hämtar flera entiteter med LINQ.
Det andra alternativet är att använda typen TableEntity (en egenskapsväska) i stället för en konkret POCO-entitetstyp (det här alternativet kan också förbättra prestanda eftersom det inte finns något behov av att serialisera och deserialisera entiteten till .NET-typer). Följande C#-kod hämtar potentiellt flera entiteter av olika typer från tabellen, men returnerar alla entiteter som TableEntity-instanser . Den använder sedan egenskapen EntityType för att fastställa typen av varje entitet:
Pageable<TableEntity> entities = employeeTable.Query<TableEntity>(x =>
x.PartitionKey == "Sales" && x.RowKey.CompareTo("B") >= 0 && x.RowKey.CompareTo("F") <= 0)
foreach (var entity in entities)
{
if (entity.GetString("EntityType") == "Employee")
{
// use entityTypeProperty, RowKey, PartitionKey, Etag, and Timestamp
}
}
Om du vill hämta andra egenskaper måste du använda metoden GetString på entiteten för klassen TableEntity .
Ändra heterogena entitetstyper
Du behöver inte känna till typen av en entitet för att ta bort den och du känner alltid till typen av en entitet när du infogar den. Du kan dock använda TableEntity-typen för att uppdatera en entitet utan att känna till dess typ och utan att använda en POCO-entitetsklass. Följande kodexempel hämtar en enskild entitet och kontrollerar att egenskapen EmployeeCount finns innan den uppdateras.
var result = employeeTable.GetEntity<TableEntity>(partitionKey, rowKey);
TableEntity department = result.Value;
if (department.GetInt32("EmployeeCount") == null)
{
throw new InvalidOperationException("Invalid entity, EmployeeCount property not found.");
}
employeeTable.UpdateEntity(department, ETag.All, TableUpdateMode.Merge);
Kontrollera åtkomst med signaturer för delad åtkomst
Du kan använda SAS-token (Signatur för delad åtkomst) för att göra det möjligt för klientprogram att ändra (och fråga) tabellentiteter utan att behöva inkludera din lagringskontonyckel i koden. Det finns vanligtvis tre huvudsakliga fördelar med att använda SAS i ditt program:
- Du behöver inte distribuera lagringskontonyckeln till en osäker plattform (till exempel en mobil enhet) för att tillåta att enheten får åtkomst till och ändra entiteter i tabelltjänsten.
- Du kan avlasta en del av det arbete som webb- och arbetsroller utför i hanteringen av dina entiteter till klientenheter som slutanvändare och mobila enheter.
- Du kan tilldela en begränsad och tidsbegränsad uppsättning behörigheter till en klient (till exempel att tillåta skrivskyddad åtkomst till specifika resurser).
Mer information om hur du använder SAS-token med tabelltjänsten finns i Använda signaturer för delad åtkomst (SAS).
Du måste dock fortfarande generera SAS-token som beviljar ett klientprogram till entiteterna i tabelltjänsten: du bör göra detta i en miljö som har säker åtkomst till dina lagringskontonycklar. Vanligtvis använder du en webb- eller arbetsroll för att generera SAS-token och leverera dem till de klientprogram som behöver åtkomst till dina entiteter. Eftersom det fortfarande finns ett arbete med att generera och leverera SAS-token till klienter bör du överväga hur du bäst kan minska den här kostnaden, särskilt i scenarier med stora volymer.
Det är möjligt att generera en SAS-token som ger åtkomst till en delmängd av entiteterna i en tabell. Som standard skapar du en SAS-token för en hel tabell, men det går också att ange att SAS-token beviljar åtkomst till antingen ett intervall med PartitionKey-värden eller ett intervall med PartitionKey - och RowKey-värden . Du kan välja att generera SAS-token för enskilda användare i systemet så att varje användares SAS-token endast ger dem åtkomst till sina egna entiteter i tabelltjänsten.
Asynkrona och parallella åtgärder
Förutsatt att du sprider dina begäranden över flera partitioner kan du förbättra dataflödet och klientens svarstider med hjälp av asynkrona eller parallella frågor. Du kan till exempel ha två eller flera arbetsrollsinstanser som har åtkomst till dina tabeller parallellt. Du kan ha enskilda arbetsroller som ansvarar för vissa uppsättningar partitioner, eller helt enkelt ha flera arbetsrollinstanser, var och en kan komma åt alla partitioner i en tabell.
I en klientinstans kan du förbättra dataflödet genom att köra lagringsåtgärder asynkront. Med Storage-klientbiblioteket är det enkelt att skriva asynkrona frågor och ändringar. Du kan till exempel börja med den synkrona metoden som hämtar alla entiteter i en partition enligt följande C#-kod:
private static void ManyEntitiesQuery(TableClient employeeTable, string department)
{
TableContinuationToken continuationToken = null;
do
{
var employees = employeeTable.Query<EmployeeEntity>($"PartitionKey eq {department}");
foreach (var emp in employees.AsPages())
{
// ...
continuationToken = emp.ContinuationToken;
}
} while (continuationToken != null);
}
Du kan enkelt ändra den här koden så att frågan körs asynkront enligt följande:
private static async Task ManyEntitiesQueryAsync(TableClient employeeTable, string department)
{
TableContinuationToken continuationToken = null;
do
{
var employees = await employeeTable.QueryAsync<EmployeeEntity>($"PartitionKey eq {department}");
foreach (var emp in employees.AsPages())
{
// ...
continuationToken = emp.ContinuationToken;
}
} while (continuationToken != null);
}
I det här asynkrona exemplet kan du se följande ändringar från den synkrona versionen:
- Metodsignaturen innehåller nu asynkron modifierare och returnerar en aktivitetsinstans.
- I stället för att anropa query-metoden för att hämta resultat anropar metoden nu Metoden QueryAsync och använder await-modifieraren för att hämta resultat asynkront.
Klientprogrammet kan anropa den här metoden flera gånger (med olika värden för avdelningsparametern) och varje fråga körs i en separat tråd.
Du kan också infoga, uppdatera och ta bort entiteter asynkront. I följande C#-exempel visas en enkel, synkron metod för att infoga eller ersätta en medarbetaretitet:
private static void SimpleEmployeeUpsert(
TableClient employeeTable,
EmployeeEntity employee)
{
var result = employeeTable.UpdateEntity(employee, Azure.ETag.All, TableUpdateMode.Replace);
Console.WriteLine("HTTP Status: {0}", result.Status);
}
Du kan enkelt ändra den här koden så att uppdateringen körs asynkront enligt följande:
private static async Task SimpleEmployeeUpsertAsync(
TableClient employeeTable,
EmployeeEntity employee)
{
var result = await employeeTable.UpdateEntityAsync(employee, Azure.ETag.All, TableUpdateMode.Replace);
Console.WriteLine("HTTP Status: {0}", result.Result.Status);
}
I det här asynkrona exemplet kan du se följande ändringar från den synkrona versionen:
- Metodsignaturen innehåller nu asynkron modifierare och returnerar en aktivitetsinstans.
- I stället för att anropa metoden Execute för att uppdatera entiteten anropar metoden nu metoden ExecuteAsync och använder inväntningsmodifieraren för att hämta resultat asynkront.
Klientprogrammet kan anropa flera asynkrona metoder som den här, och varje metodanrop körs på en separat tråd.