Samla in data från Event Hubs i Parquet-format
Den här artikeln beskriver hur du använder kodredigeraren utan kod för att automatiskt samla in strömmande data i Event Hubs i ett Azure Data Lake Storage Gen2 konto i Parquet-format.
Förutsättningar
Ett Azure Event Hubs namnområde med en händelsehubb och ett Azure Data Lake Storage Gen2-konto med en container för att lagra insamlade data. Dessa resurser måste vara offentligt tillgängliga och får inte finnas bakom en brandvägg eller skyddas i ett virtuellt Azure-nätverk.
Om du inte har en händelsehubb skapar du en genom att följa anvisningarna i Snabbstart: Skapa en händelsehubb.
Om du inte har ett Data Lake Storage Gen2 konto skapar du ett genom att följa anvisningarna från Skapa ett lagringskonto
Data i dina Event Hubs måste serialiseras i antingen JSON-, CSV- eller Avro-format. I testsyfte väljer du Generera data (förhandsversion) på den vänstra menyn, väljer Lagerdata för datauppsättning och väljer sedan Skicka.


Konfigurera ett jobb för att samla in data
Använd följande steg för att konfigurera ett Stream Analytics-jobb för att samla in data i Azure Data Lake Storage Gen2.
I Azure Portal navigerar du till din händelsehubb.
På den vänstra menyn väljer du Bearbeta data under Funktioner. Välj sedan Starta på kortet Avbilda data till ADLS Gen2 i Parquet-format .

Ange ett namn för Stream Analytics-jobbet och välj sedan Skapa.
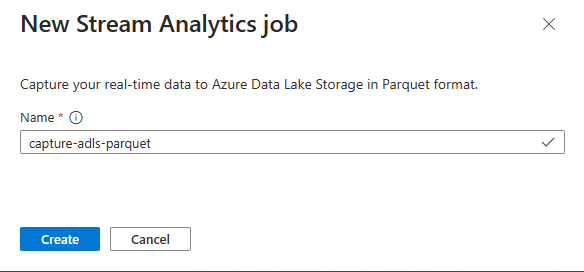
Ange serialiseringstypen för dina data i Event Hubs och den autentiseringsmetod som jobbet använder för att ansluta till Event Hubs. Välj Anslut.

När anslutningen har upprättats visas:
Fält som finns i indata. Du kan välja Lägg till fält eller välja symbolen med tre punkter bredvid ett fält om du vill ta bort, byta namn på eller ändra dess namn.
Ett live-exempel på inkommande data i tabellen Dataförhandsgranskning under diagramvyn. Den uppdateras regelbundet. Du kan välja Pausa förhandsversionen av direktuppspelning för att visa en statisk vy över exempelindata.

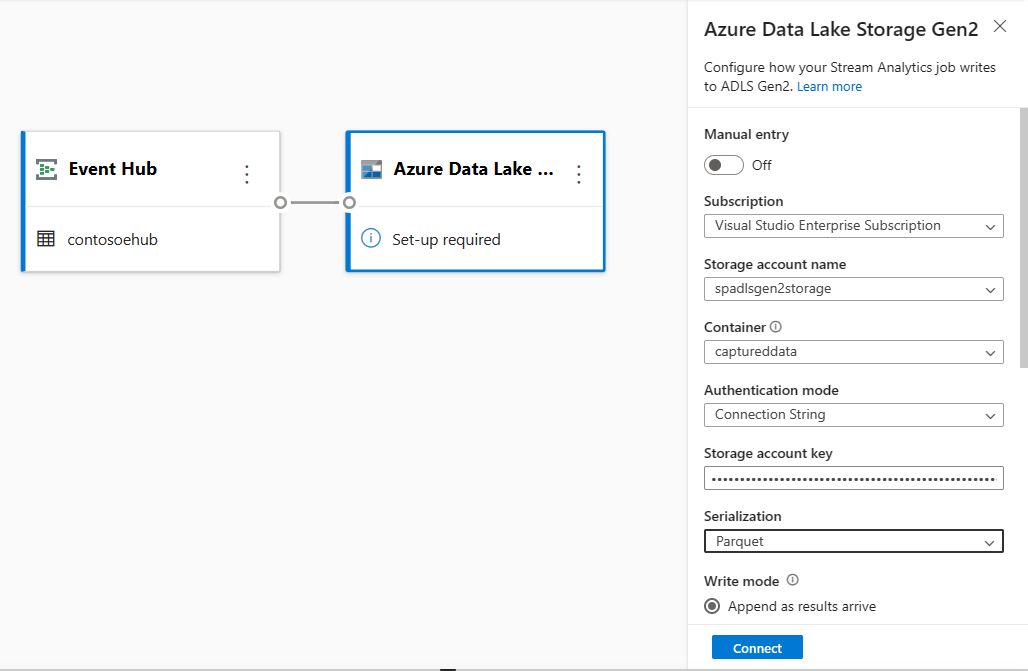
Välj Azure Data Lake Storage Gen2-panelen för att redigera konfigurationen.
Följ dessa steg på Azure Data Lake Storage Gen2 konfigurationssidan:
Välj prenumeration, lagringskontonamn och container på den nedrullningsbara menyn.
När prenumerationen har valts ska autentiseringsmetoden och lagringskontonyckeln fyllas i automatiskt.
Välj Parquet som serialiseringsformat .
För strömmande blobar förväntas katalogsökvägsmönstret vara ett dynamiskt värde. Det krävs för att datumet ska vara en del av filsökvägen för blobben – som refereras till som
{date}. Mer information om anpassade sökvägsmönster finns i Anpassad partitionering av blobutdata i Azure Stream Analytics.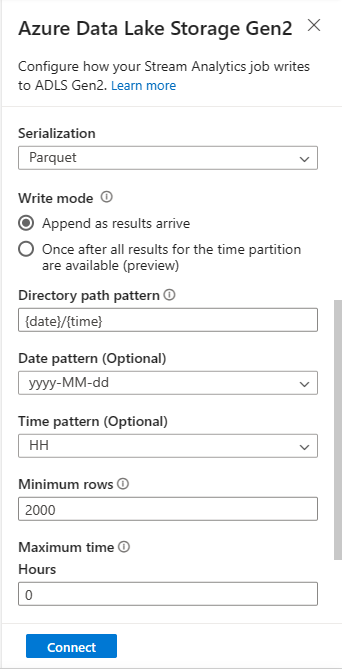
Välj Anslut
När anslutningen upprättas visas fält som finns i utdata.
Välj Spara i kommandofältet för att spara konfigurationen.
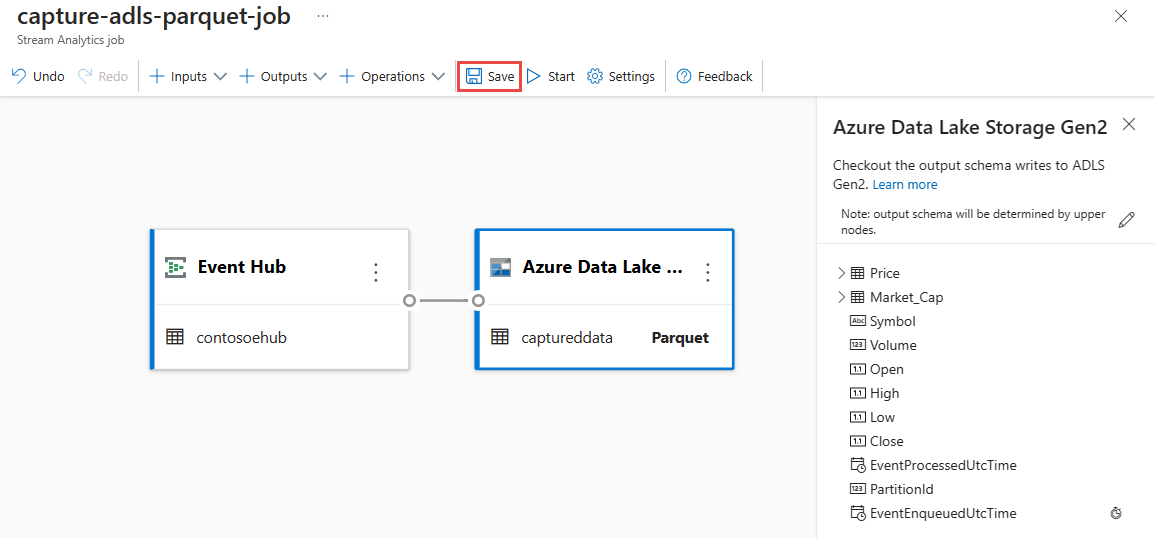
Välj Starta i kommandofältet för att starta direktuppspelningsflödet för att samla in data. I fönstret Starta Stream Analytics-jobb:
Välj starttid för utdata.
Välj prisplanen.
Välj antalet strömningsenheter (SU) som jobbet körs med. SU representerar de databehandlingsresurser som allokeras för att köra ett Stream Analytics-jobb. Mer information finns i Strömmande enheter i Azure Stream Analytics.

Du bör se streamanalysjobbet på fliken Stream Analytics-jobb på sidan Bearbeta data för din händelsehubb.
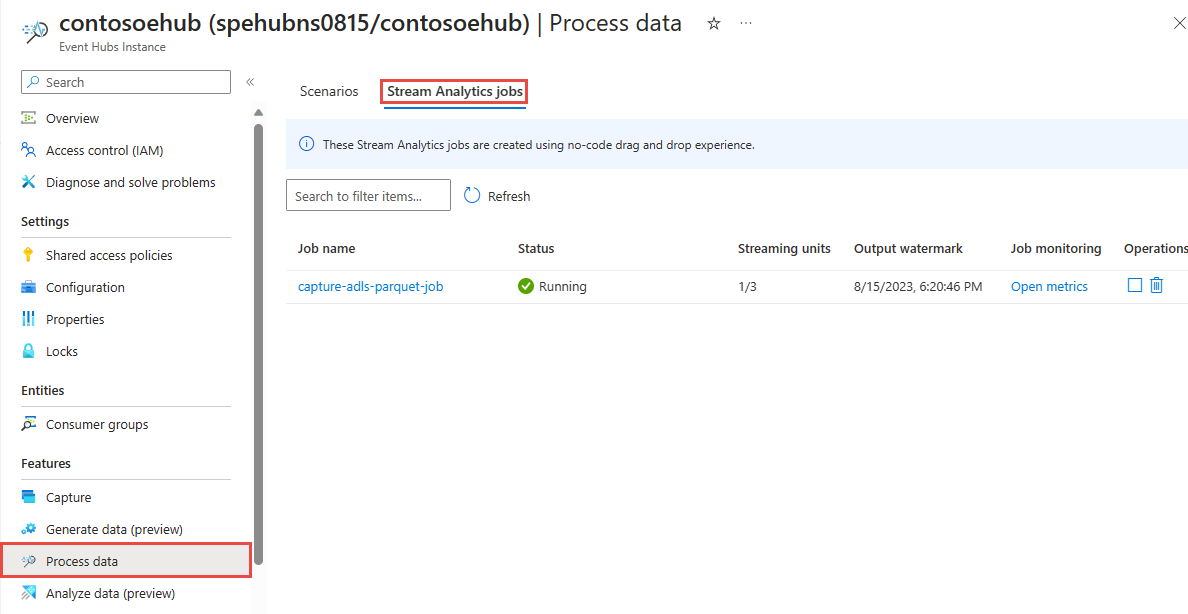







Verifiera utdata
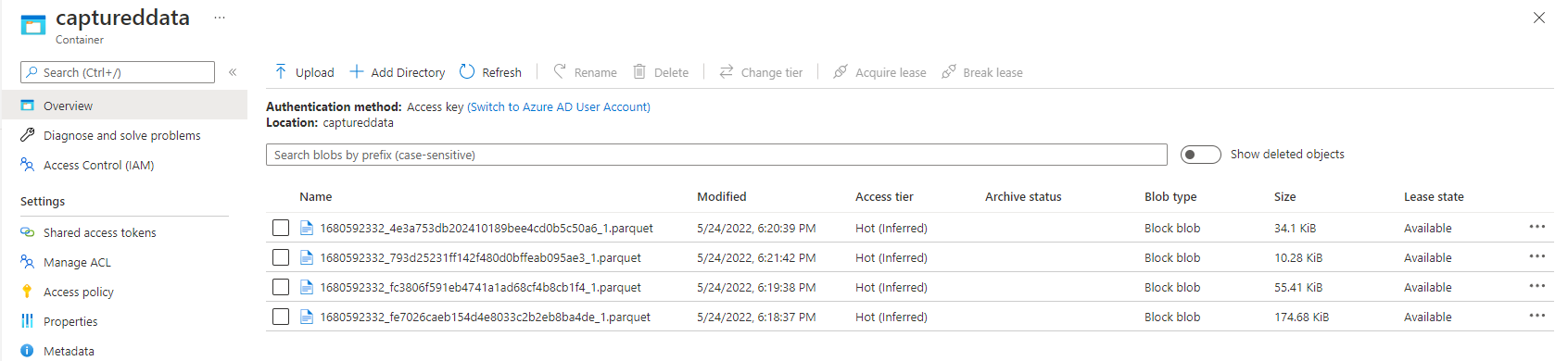
På sidan Event Hubs-instans för din händelsehubb väljer du Generera data, väljer Lagerdata för datauppsättning och väljer sedan Skicka för att skicka exempeldata till händelsehubben.
Kontrollera att Parquet-filerna genereras i containern Azure Data Lake Storage.
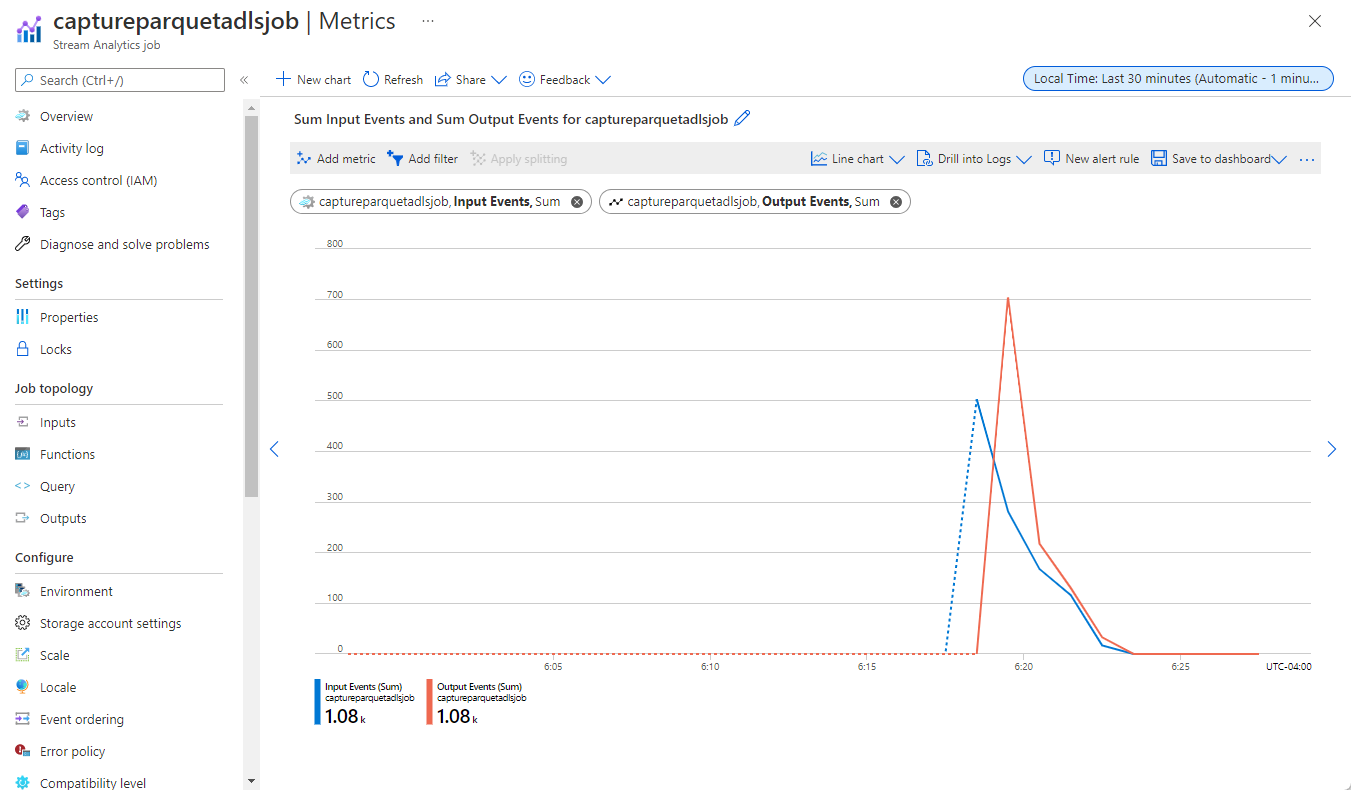
Välj Bearbeta data på den vänstra menyn. Växla till fliken Stream Analytics-jobb . Välj Öppna mått för att övervaka det.

Här är ett exempel på en skärmbild av mått som visar indata- och utdatahändelser.



Nästa steg
Nu vet du hur du använder Stream Analytics utan kodredigerare för att skapa ett jobb som samlar in Event Hubs-data till att Azure Data Lake Storage Gen2 i Parquet-format. Därefter kan du lära dig mer om Azure Stream Analytics och hur du övervakar jobbet som du skapade.