Självstudie: Samla in Event Hubs-data i parquet-format och analysera med Azure Synapse Analytics
Den här självstudien visar hur du använder Stream Analytics utan kodredigerare för att skapa ett jobb som samlar in Event Hubs-data i för att Azure Data Lake Storage Gen2 i parquet-format.
I den här guiden får du lära dig att:
- Distribuera en händelsegenerator som skickar exempelhändelser till en händelsehubb
- Skapa ett Stream Analytics-jobb med redigeringsprogrammet utan kod
- Granska indata och schema
- Konfigurera Azure Data Lake Storage Gen2 till vilken händelsehubbdata som ska samlas in
- Köra Stream Analytics-jobbet
- Använd Azure Synapse Analytics för att köra frågor mot parkettfilerna
Förutsättningar
Kontrollera att du har slutfört följande steg innan du börjar:
- Om du inte har någon Azure-prenumeration kan du skapa ett kostnadsfritt konto.
- Distribuera händelsegeneratorappen TollApp till Azure. Ange parametern "intervall" till 1 och använd en ny resursgrupp för det här steget.
- Skapa en Azure Synapse Analytics-arbetsyta med ett Data Lake Storage Gen2-konto.
Använd ingen kodredigerare för att skapa ett Stream Analytics-jobb
Leta upp resursgruppen där TollApp-händelsegeneratorn distribuerades.
Välj Azure Event Hubs namnområde.
På sidan Event Hubs-namnområde väljer du Händelsehubbar under Entiteter på den vänstra menyn.
Välj
entrystreaminstans.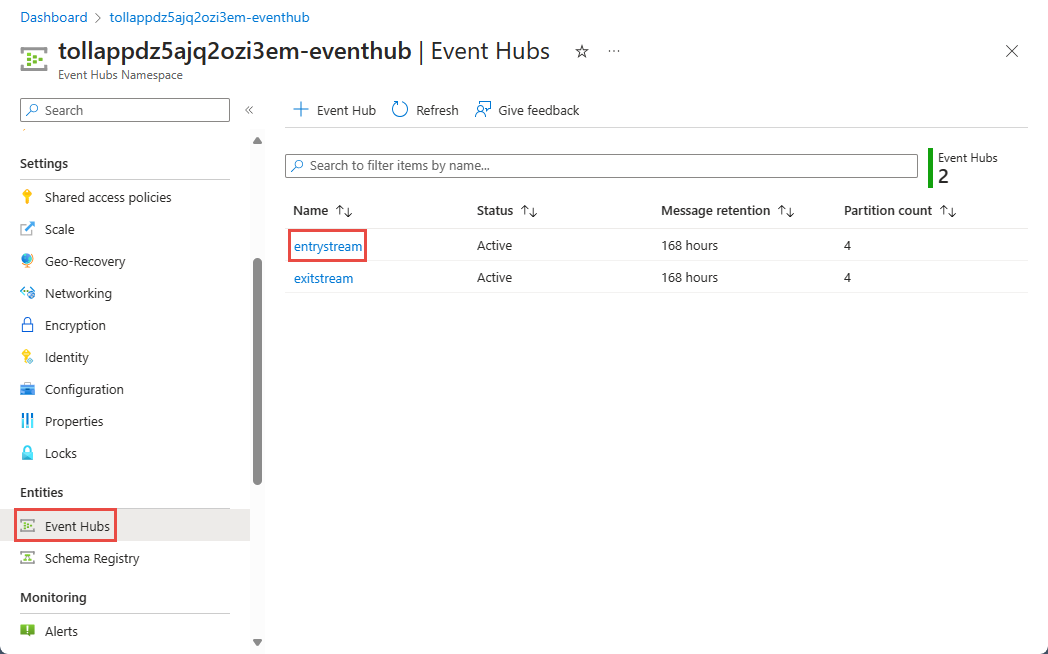
På sidan Event Hubs-instans väljer du Bearbeta data i avsnittet Funktioner på den vänstra menyn.
Välj Starta på panelen Avbilda data till ADLS Gen2 i Parquet-format .

Ge jobbet ett
parquetcapturenamn och välj Skapa.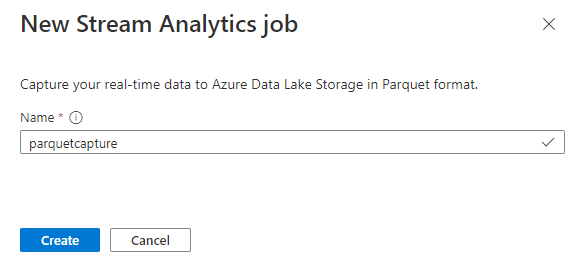
På konfigurationssidan för händelsehubben bekräftar du följande inställningar och väljer sedan Anslut.
Konsumentgrupp: Standard
Serialiseringstyp för dina indata: JSON
Autentiseringsläge som jobbet ska använda för att ansluta till din händelsehubb: Anslutningssträng.

Inom några sekunder visas exempel på indata och schemat. Du kan välja att släppa fält, byta namn på fält eller ändra datatyp.

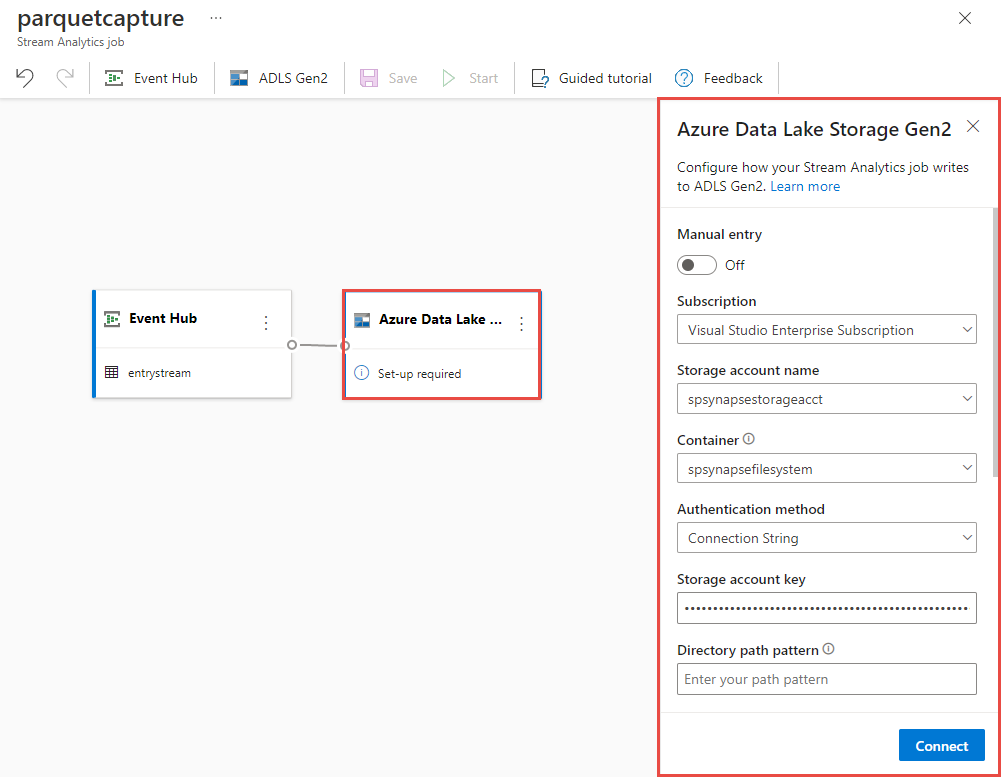
Välj Azure Data Lake Storage Gen2-panelen på arbetsytan och konfigurera den genom att ange
- Prenumeration där ditt Azure Data Lake Gen2-konto finns i
- Lagringskontots namn, som ska vara samma ADLS Gen2-konto som används med din Azure Synapse Analytics-arbetsyta i avsnittet Krav.
- Container där Parquet-filerna skapas.
- Sökvägsmönster inställt på {date}/{time}
- Datum- och tidsmönster som standard-yyyy-mm-dd och HH.
- Välj Anslut
Välj Spara i det övre menyfliksområdet för att spara jobbet och välj sedan Starta för att köra jobbet. När jobbet har startats väljer du X i det högra hörnet för att stänga Stream Analytics-jobbsidan .
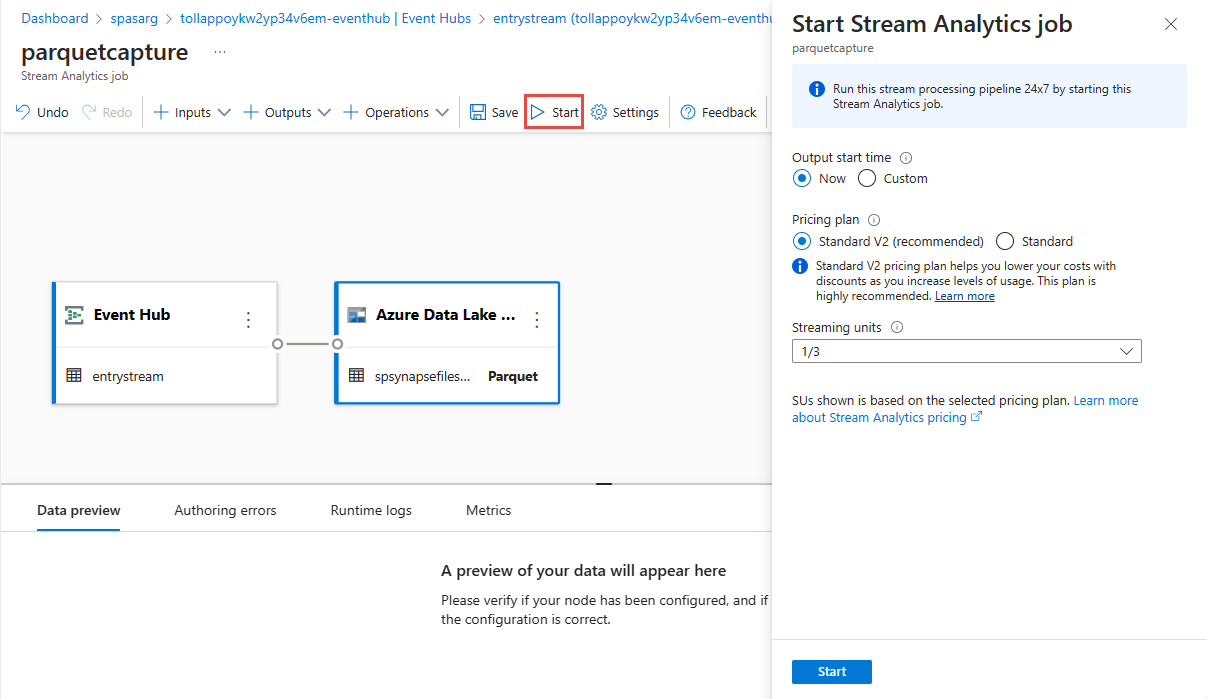
Sedan visas en lista över alla Stream Analytics-jobb som skapats med hjälp av redigeringsprogrammet utan kod. Och inom två minuter går jobbet till ett körtillstånd . Välj knappen Uppdatera på sidan för att se statusen ändras från Skapad –> Startar –> Körs.









Visa utdata i ditt Azure Data Lake Storage Gen 2-konto
Leta upp det Azure Data Lake Storage Gen2 konto som du använde i föregående steg.
Välj den container som du använde i föregående steg. Du ser parquet-filer som skapats baserat på sökvägsmönstret {date}/{time} som användes i föregående steg.
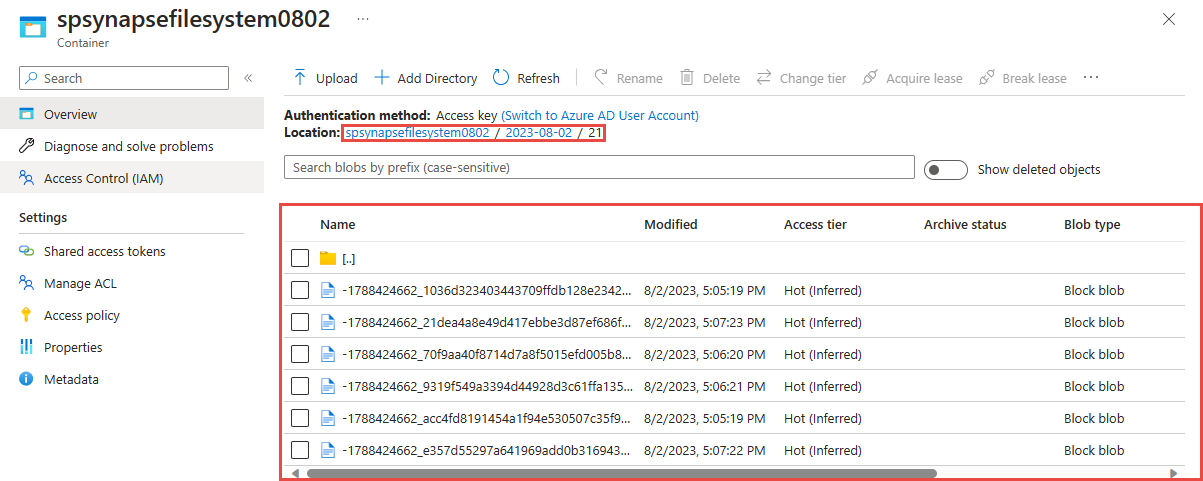
Fråga insamlade data i Parquet-format med Azure Synapse Analytics
Fråga med Azure Synapse Spark
Leta upp din Azure Synapse Analytics-arbetsyta och öppna Synapse Studio.
Skapa en serverlös Apache Spark-pool på din arbetsyta om det inte redan finns någon.
I Synapse Studio går du till utveckla hubben och skapar en ny notebook-fil.
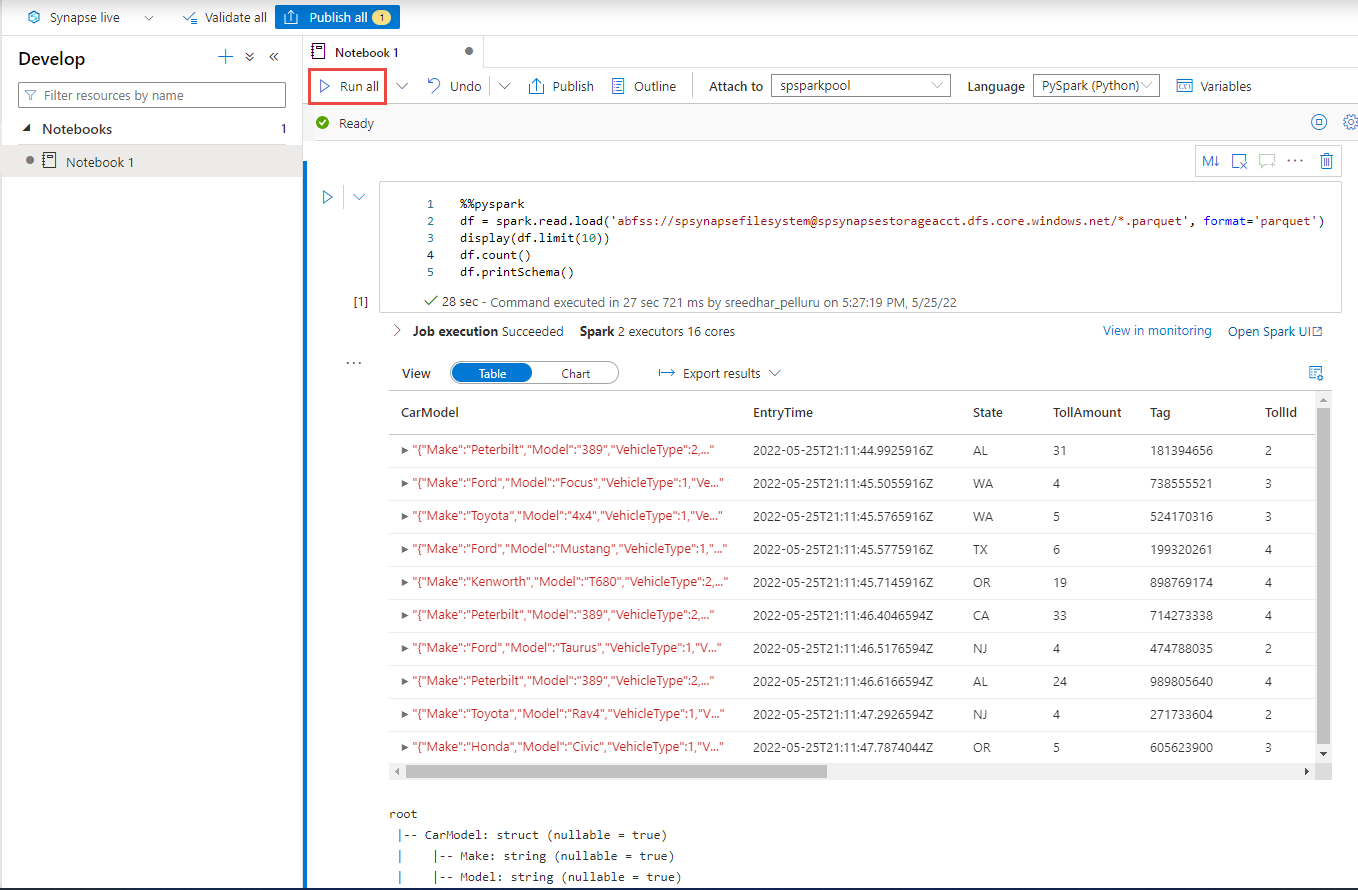
Skapa en ny kodcell och klistra in följande kod i cellen. Ersätt container och adlsname med namnet på containern och ADLS Gen2-kontot som användes i föregående steg.
%%pyspark df = spark.read.load('abfss://container@adlsname.dfs.core.windows.net/*/*/*.parquet', format='parquet') display(df.limit(10)) df.count() df.printSchema()För Anslut till i verktygsfältet väljer du din Spark-pool i listrutan.
Välj Kör alla för att se resultatet

Fråga med Azure Synapse serverlös SQL
I utveckla hubben skapar du ett nytt SQL-skript.
Klistra in följande skript och kör det med hjälp av den inbyggda serverlösa SQL-slutpunkten . Ersätt container och adlsname med namnet på containern och ADLS Gen2-kontot som användes i föregående steg.
SELECT TOP 100 * FROM OPENROWSET( BULK 'https://adlsname.dfs.core.windows.net/container/*/*/*.parquet', FORMAT='PARQUET' ) AS [result]

Rensa resurser
- Leta upp din Event Hubs-instans och se listan över Stream Analytics-jobb under avsnittet Processdata . Stoppa alla jobb som körs.
- Gå till den resursgrupp som du använde när du distribuerade TollApp-händelsegeneratorn.
- Välj Ta bort resursgrupp. Ange namnet på resursgruppen för att bekräfta borttagningen.
Nästa steg
I den här självstudien har du lärt dig hur du skapar ett Stream Analytics-jobb med hjälp av kodredigeraren utan kod för att samla in Event Hubs-dataströmmar i Parquet-format. Sedan använde du Azure Synapse Analytics för att köra frågor mot parkettfilerna med både Synapse Spark och Synapse SQL.
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för