Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Azure Stream Analytics kan mata ut data i JSON-format till Azure Cosmos DB. Det möjliggör dataarkivering och frågor med låg svarstid på ostrukturerade JSON-data. Den här artikeln beskriver några metodtips för att implementera den här konfigurationen (Stream Analytics till Cosmos DB). Om du inte är bekant med Azure Cosmos DB kan du läsa dokumentationen för Azure Cosmos DB för att komma igång.
Kommentar
- För närvarande stöder Stream Analytics endast anslutning till Azure Cosmos DB via SQL-API:et. Andra Azure Cosmos DB-API:er stöds ännu inte. Om du pekar Stream Analytics på Azure Cosmos DB-konton som skapats med andra API:er kanske data inte lagras korrekt.
- Vi rekommenderar att du ställer in jobbet på kompatibilitetsnivå 1.2 när du använder Azure Cosmos DB som utdata.
Grunderna i Azure Cosmos DB som mål för utdata
Med Azure Cosmos DB-utdata i Stream Analytics kan du skriva dina dataströmbearbetningsresultat som JSON-utdata till dina Azure Cosmos DB-containrar. Stream Analytics skapar inte containrar i databasen. I stället måste du skapa dem i förväg. Du kan sedan styra faktureringskostnaderna för Azure Cosmos DB-containrar. Du kan också justera prestanda, konsekvens och kapacitet för dina containrar direkt med hjälp av Azure Cosmos DB-API:erna. I följande avsnitt beskrivs några av containeralternativen för Azure Cosmos DB.
Optimera konsekvens, tillgänglighet och svarstid
För att matcha dina programkrav kan du med Azure Cosmos DB finjustera databasen och containrarna och göra kompromisser mellan konsekvens, tillgänglighet, svarstid och dataflöde.
Beroende på vilka nivåer av läskonsekvens ditt scenario behöver med hänsyn till läs- och skrivfördröjning kan du välja en konsekvensnivå för ditt databaskonto. Du kan förbättra dataflödet genom att skala upp enheter för programbegäran (RU: er) på containern. Som standard möjliggör Azure Cosmos DB också synkron indexering på varje CRUD-åtgärd till din container. Det här alternativet är ett annat användbart alternativ för att styra skriv-/läsprestanda i Azure Cosmos DB. Mer information finns i artikeln Ändra databas- och frågekonsekvensnivåer .
Upserts från Stream Analytics
Med Stream Analytics-integrering med Azure Cosmos DB kan du infoga eller uppdatera poster i containern baserat på en viss dokument-ID-kolumn . Den här åtgärden kallas även för en upsert. Stream Analytics använder en optimistisk upsert-metod. Uppdateringar sker bara när en infogning misslyckas med en dokument-ID-konflikt.
Med kompatibilitetsnivå 1.0 utför Stream Analytics den här uppdateringen som en PATCH-åtgärd, så det möjliggör partiella uppdateringar av dokumentet. Stream Analytics lägger till nya egenskaper eller ersätter en befintlig egenskap stegvis. Men ändringar i värdena för matrisegenskaper i JSON-dokumentet resulterar i att hela matrisen skrivs över. Matrisen är alltså inte sammanfogad.
Med 1.2 ändras upsert-beteendet för att infoga eller ersätta dokumentet. I det senare avsnittet om kompatibilitetsnivå 1.2 beskrivs det här beteendet ytterligare.
Om det inkommande JSON-dokumentet har ett befintligt ID-fält används fältet automatiskt som dokument-ID-kolumn i Azure Cosmos DB. Efterföljande skrivningar hanteras som sådana, vilket leder till någon av följande situationer:
- Unika ID:er leder till infogning.
- Duplicerade ID:er och dokument-ID som är inställda på ID leder till upsert.
- Dubbla ID:n och document-ID som inte setts leder till fel efter det första dokumentet.
Om du vill spara alla dokument, inklusive de som har ett duplicerat ID, byter du namn på ID-fältet i din fråga (med hjälp av nyckelordet AS ). Låt Azure Cosmos DB skapa ID-fältet eller ersätt ID:t med en annan kolumns värde (med hjälp av AS-nyckelordet eller med hjälp av inställningen Dokument-ID).
Datapartitionering i Azure Cosmos DB
Azure Cosmos DB skalar automatiskt partitioner baserat på din arbetsbelastning. Därför rekommenderar vi att du använder obegränsade containrar för partitionering av dina data. När Stream Analytics skriver till obegränsade containrar använder den lika många parallella skrivare som föregående frågesteg eller indatapartitioneringsschema.
Kommentar
Azure Stream Analytics stöder endast obegränsade containrar med partitionsnycklar på den översta nivån. Till exempel /region stöds. Kapslade partitionsnycklar (till exempel /region/name) stöds inte.
Beroende på val av partitionsnyckel kan du få den här varningen:
CosmosDB Output contains multiple rows and just one row per partition key. If the output latency is higher than expected, consider choosing a partition key that contains at least several hundred records per partition key.
Det är viktigt att välja en partitionsnyckelegenskap som har många distinkta värden och som gör att du kan distribuera arbetsbelastningen jämnt över dessa värden. Som en naturlig artefakt för partitionering begränsas begäranden som omfattar samma partitionsnyckel av det maximala dataflödet för en enda partition.
Lagringsstorleken för dokument som tillhör samma partitionsnyckelvärde är begränsad till 20 GB (den fysiska partitionsstorleksgränsen är 50 GB). En idealisk partitionsnyckel är den som ofta visas som ett filter i dina frågor och har tillräcklig kardinalitet för att säkerställa att lösningen är skalbar.
Partitionsnycklar som används för Stream Analytics-frågor och Azure Cosmos DB behöver inte vara identiska. Fullt parallella topologier rekommenderar att du använder Indatapartitionsnyckel, PartitionId, som partitionsnyckel för Stream Analytics-frågan, men det kanske inte är den rekommenderade partitionsnyckeln för en container i Azure Cosmos DB.
En partitionsnyckel är också gränsen för transaktioner i lagrade procedurer och utlösare för Azure Cosmos DB. Du bör välja partitionsnyckeln så att dokument som sker tillsammans i transaktioner delar samma partitionsnyckelvärde. Artikeln Partitionering i Azure Cosmos DB innehåller mer information om hur du väljer en partitionsnyckel.
För fasta Azure Cosmos DB-containrar tillåter Stream Analytics inget sätt att skala upp eller ut när de är fulla. De har en övre gräns på 10 GB och 10 000 RU/s dataflöde. Om du vill migrera data från en fast container till en obegränsad container (till exempel en med minst 1 000 RU/s och en partitionsnyckel) använder du datamigreringsverktyget eller biblioteket för ändringsflöde.
Möjligheten att skriva till flera förutbestämda containrar håller på att fasas ut. Vi rekommenderar det inte för att skala ut ditt Stream Analytics-jobb.
Förbättrat dataflöde med kompatibilitetsnivå 1.2
Med kompatibilitetsnivå 1.2 har Stream Analytics stöd för intern integrering för massskrivning till Azure Cosmos DB. Den här integreringen gör det möjligt att skriva effektivt till Azure Cosmos DB samtidigt som dataflödet maximeras och begränsningsbegäranden hanteras effektivt.
Den förbättrade skrivmekanismen är tillgänglig under en ny kompatibilitetsnivå på grund av skillnader i hur upsert-beteendet fungerar. Med nivåer före 1.2 är upsert-beteendet att infoga eller sammanfoga dokumentet. Med 1.2 ändras upsert-beteendet för att infoga eller ersätta dokumentet.
Med nivåer före 1.2 använder Stream Analytics en anpassad lagrad procedur för att massuppdatera dokument per partitionsnyckel i Azure Cosmos DB. Där skrivs en batch som en transaktion. Även när en enskild post drabbas av ett tillfälligt fel (strömbegränsning), måste hela gruppen/batchen försöka igen. Det här beteendet gör scenarier även med rimlig hastighetsbegränsning relativt långsamma.
I följande exempel visas två identiska Stream Analytics-jobb som läser från samma Azure Event Hubs-indata. Båda Stream Analytics-jobben är helt partitionerade med en genomströmningsfråga och skriver till identiska Azure Cosmos DB-containrar. Måtten till vänster härstammar från den uppgift som konfigurerats med kompatibilitetsnivå 1.0. Mått till höger konfigureras med 1.2. En Azure Cosmos DB-containers partitionsnyckel är ett unikt GUID som hämtas från indatahändelsen.
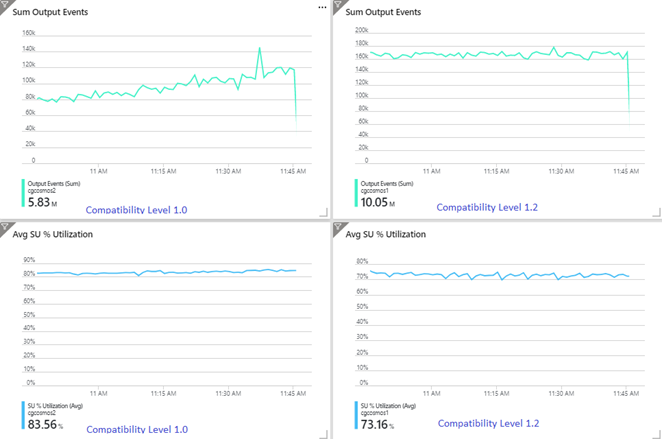
Den inkommande händelsefrekvensen i Event Hubs är dubbelt så hög som vad Azure Cosmos DB-containrar (20 000 RUs) är konfigurerade för att hantera, så begränsning förväntas i Azure Cosmos DB. Jobbet med 1.2 skrivs dock konsekvent vid ett högre dataflöde (utdatahändelser per minut) och med en lägre genomsnittlig SU%-användning. I din miljö beror den här skillnaden på några fler faktorer. Dessa faktorer inkluderar val av händelseformat, indatahändelse/meddelandestorlek, partitionsnycklar och fråga.
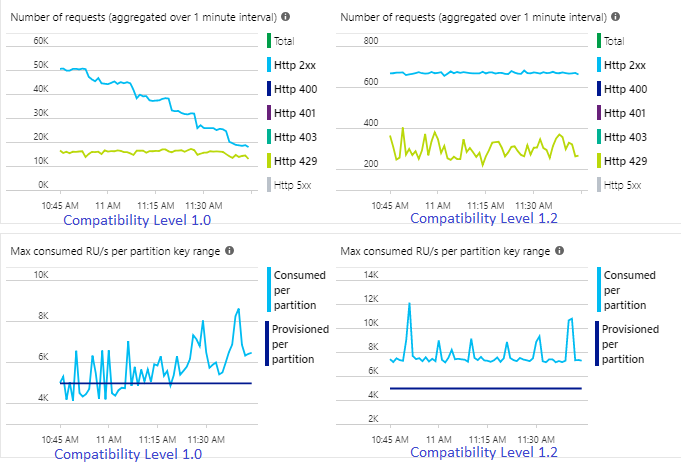
Med version 1.2 är Stream Analytics mer intelligent i att använda 100 procent av den tillgängliga ankomsttakten i Azure Cosmos DB med få ominskickningar på grund av strypning eller hastighetsbegränsningar. Det här beteendet skapar en bättre upplevelse för andra arbetsbelastningar, såsom databaskörningar som körs på containern samtidigt. Om du vill se hur Stream Analytics skalar ut med Azure Cosmos DB som mottagare för 1 000 till 10 000 meddelanden per sekund kan du prova det här Azure-exempelprojektet.
Dataflödet för Azure Cosmos DB-utdata är identiskt med 1.0 och 1.1. Vi rekommenderar starkt att du använder kompatibilitetsnivå 1.2 i Stream Analytics med Azure Cosmos DB.
Azure Cosmos DB-inställningar för JSON-utdata
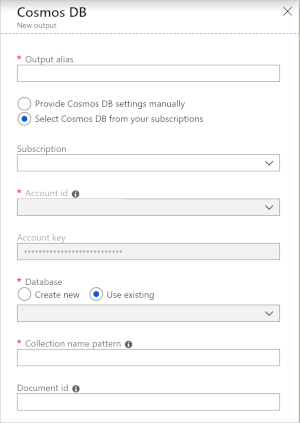
Om du använder Azure Cosmos DB som utdata i Stream Analytics genereras följande fråga efter information.
| Fält | beskrivning |
|---|---|
| Utdataalias | Ett alias som refererar till dessa utdata i Stream Analytics-frågan. |
| Prenumeration | Azure-prenumerationen. |
| Konto-ID | Namnet eller slutpunkts-URI:n för Azure Cosmos DB-kontot. |
| Kontonyckel | Den delade åtkomstnyckeln för Azure Cosmos DB-kontot. |
| Databas | Azure Cosmos DB-databasnamnet. |
| Containerns namn | Containernamnet, till exempel MyContainer. En container med namnet MyContainer måste finnas. |
| Dokument-ID | Valfritt. Kolumnnamnet i utdatahändelser används som den unika nyckeln, på vilken införings- eller uppdateringsåtgärder måste baseras. Om du lämnar den tom infogas alla händelser utan uppdateringsalternativ. |
När du har konfigurerat Azure Cosmos DB-utdata kan du använda det i frågan som mål för en INTO-instruktion. När du använder ett Azure Cosmos DB-utdata på det sättet måste en partitionsnyckel anges explicit.
Utdataposten måste innehålla en skiftlägeskänslig kolumn som är döpt efter partitionsnyckeln i Azure Cosmos DB. För att uppnå större parallellisering kan instruktionen kräva en PARTITION BY-sats som använder samma kolumn.
Här är en exempelfråga:
SELECT TollBoothId, PartitionId
INTO CosmosDBOutput
FROM Input1 PARTITION BY PartitionId
Felhantering och återförsök
Om ett tillfälligt fel, tjänstens otillgänglighet eller begränsning inträffar när Stream Analytics skickar händelser till Azure Cosmos DB, försöker Stream Analytics på obestämd tid för att slutföra åtgärden. Men det gör inga nya försök för följande fel:
- Obehörig (HTTP-felkod 401)
- NotFound (HTTP-felkod 404)
- Förbjudet (HTTP-felkod 403)
- BadRequest (HTTP-felkod 400)
Vanliga problem
En unik indexbegränsning läggs till i samlingen och utdata från Stream Analytics bryter mot den här begränsningen. Se till att utdata från Stream Analytics inte bryter mot unika begränsningar eller tar bort begränsningar. Mer information finns i Begränsningar för unik nyckel i Azure Cosmos DB.
Kolumnen
PartitionKeyfinns inte.Kolumnen
Idfinns inte.