Not
Åtkomst till denna sida kräver auktorisation. Du kan prova att logga in eller byta katalog.
Åtkomst till denna sida kräver auktorisation. Du kan prova att byta katalog.
Viktigt!
Azure Synapse Analytics Data Explorer (förhandsversion) dras tillbaka den 7 oktober 2025. Efter det här datumet tas arbetsbelastningar som körs i Synapse Data Explorer bort och associerade programdata går förlorade. Vi rekommenderar starkt att du migrerar till Eventhouse i Microsoft Fabric.
Microsoft Cloud Migration Factory-programmet (CMF) är utformat för att hjälpa kunder att migrera till Fabric. Programmet erbjuder praktiska tangentbordsresurser utan kostnad för kunden. Dessa resurser tilldelas för en period på 6–8 veckor, med ett fördefinierat och överenskommet omfång. Kundnomineringar accepteras från Microsoft-kontoteamet eller direkt genom att skicka en begäran om hjälp till CMF-teamet.
Azure Synapse Data Explorer är en snabb, fullständigt hanterad dataanalystjänst för realtidsanalys på stora mängder dataströmning från program, webbplatser, IoT-enheter med mera. Om du vill använda Datautforskaren skapar du först en Data Explorer-pool.
Den här snabbstarten beskriver stegen för att skapa en Data Explorer-pool på en Synapse-arbetsyta med hjälp av Synapse Studio.
Viktigt!
Faktureringen för Data Explorer-instanser beräknas proportionellt per minut, oavsett om du använder dem eller inte. Se till att stänga av Data Explorer-instansen när du har använt den eller ange en kort tidsgräns. För mer information, se Rensa resurser.
Om du inte har någon Azure-prenumeration skapar du ett kostnadsfritt konto innan du börjar.
Förutsättningar
- Du behöver en Azure-prenumeration. Skapa ett kostnadsfritt Azure-konto om det behövs
- Synapse-arbetsyta
Logga in på Azure-portalen
Logga in på Azure-portalen
Navigera till Synapse-arbetsytan
Gå till Synapse-arbetsytan där datautforskarens pool skapas genom att skriva tjänstnamnet (eller resursnamnet direkt) i sökfältet.
I listan över arbetsytor skriver du namnet (eller en del av namnet) på arbetsytan som ska öppnas. I det här exemplet använder vi en arbetsyta med namnet contosoanalytics.
Starta Synapse Studio
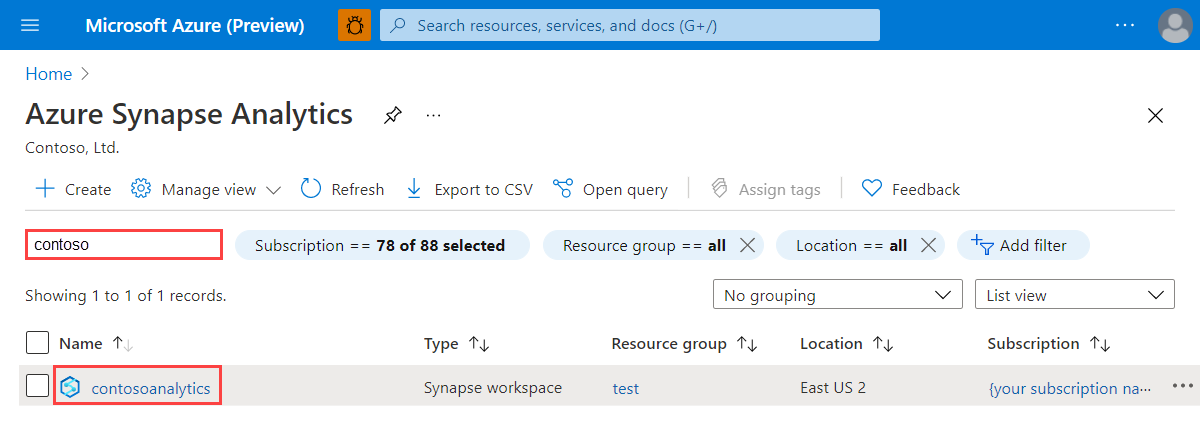
I översikten över arbetsytan väljer du webb-URL:en för arbetsytan för att öppna Synapse Studio.
Skapa en ny Data Explorer-pool
På synapse Studio-startsidan går du till hanteringshubben i det vänstra navigeringsfältet genom att välja ikonen Hantera .
I hanteringshubben går du till avsnittet Datautforskarens pooler för att se den aktuella listan över datautforskarens pooler som är tillgängliga på arbetsytan.
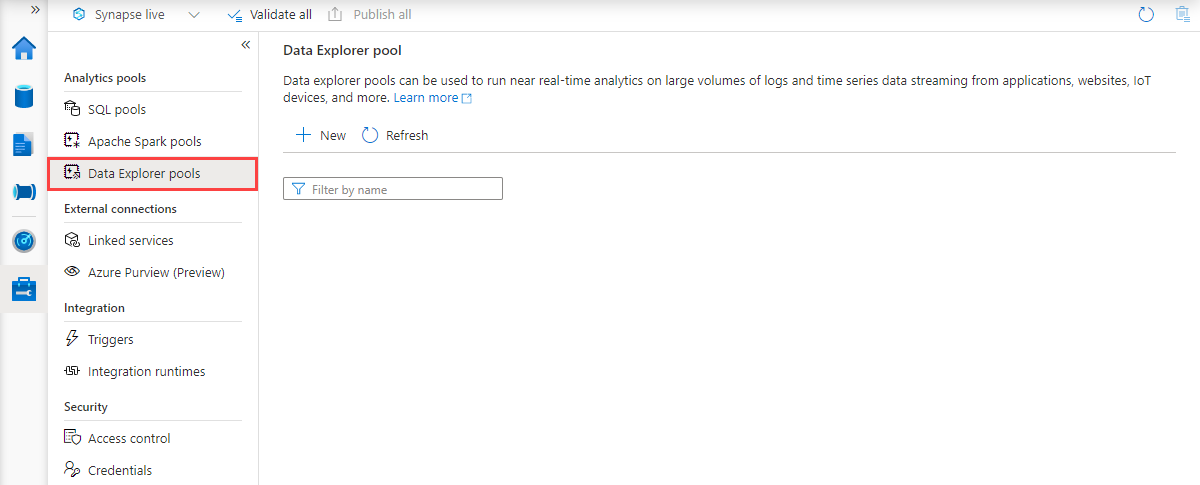
Välj + Ny. Guiden för att skapa en pool i Datautforskaren visas.
Ange följande information på fliken Grundläggande :
Inställning Föreslaget värde Description Namn på Data Explorer-pool contosodataexplorer Det här är namnet som datautforskarens pool kommer att ha. Arbetsbörda Optimerad för beräkning Den här arbetsbelastningen ger ett högre cpu-till-SSD-lagringsförhållande. Nodstorlek Små (4 kärnor) Ange den minsta storleken för att minska kostnaderna för den här snabbstarten 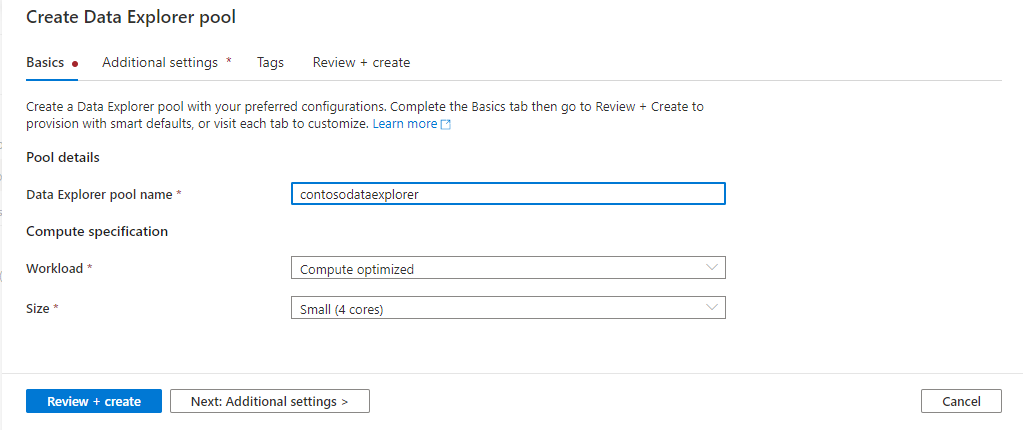
Viktigt!
Observera att det finns specifika begränsningar för de namn som Data Explorer-pooler kan använda. Namn får endast innehålla gemener och siffror, måste vara mellan 4 och 15 tecken och måste börja med en bokstav.
Välj Nästa: Ytterligare inställningar. Använd följande inställningar och lämna standardinställningarna för de återstående inställningarna.
Inställning Föreslaget värde Description Autoscale Disabled Vi kommer inte att behöva autoskala i den här snabbstarten Antal instanser 2 Ange den minsta storleken för att minska kostnaderna för den här snabbstarten 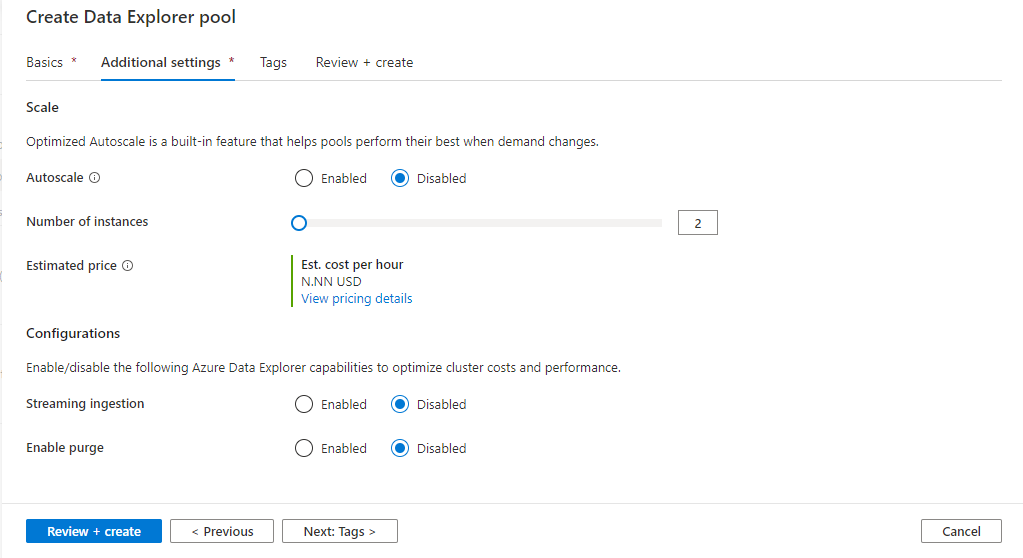
Välj Nästa: taggar. Lägg inte till några taggar.
Välj Förhandsgranska + skapa.
Granska informationen och kontrollera att de är korrekta och välj sedan Skapa.
Datautforskarpoolen kommer att starta provisioneringsprocessen.
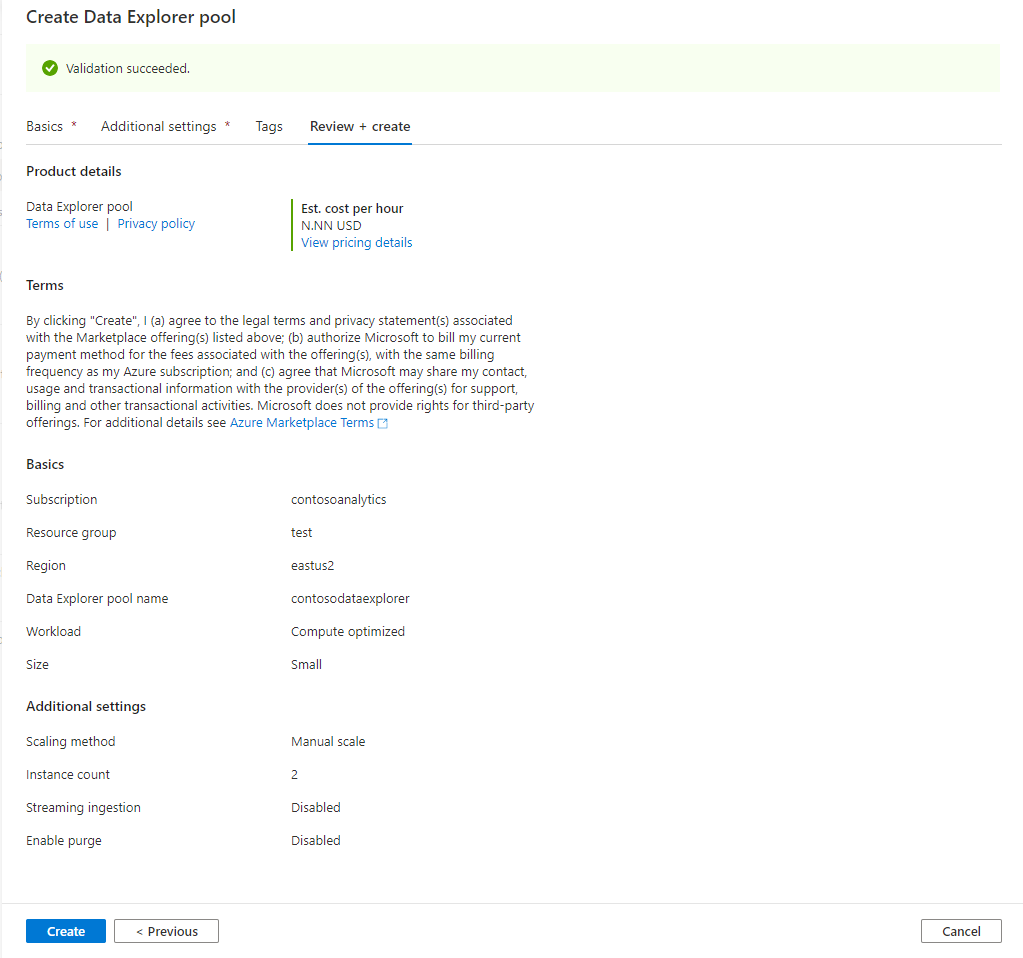
När etableringen är klar går du tillbaka till arbetsområdet och kontrollerar att den nya Data Explorer-poolen visas i listan.
Rensa Data Explorer-poolresurser med Hjälp av Synapse Studio
Använd följande steg för att ta bort datautforskarens pool från arbetsytan med hjälp av Synapse Studio.
Varning
Att ta bort en datautforskarpool kommer att ta bort analysmotorn från arbetsytan. Det går inte längre att ansluta till poolen och alla frågor, pipelines och notebook-filer som använder den borttagna poolen fungerar inte längre.
Ta bort datautforskarens pool
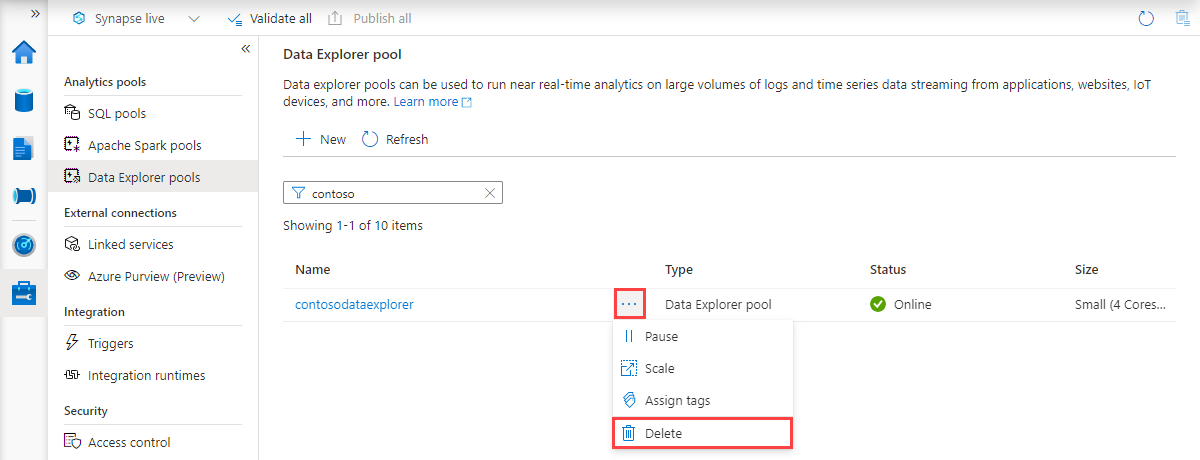
Gå till Data Explorer-poolerna på arbetsytan.
Om du vill ta bort Data Explorer-poolen (i det här fallet contosodataexplorer) väljer du Mer [...]>Ta bort.
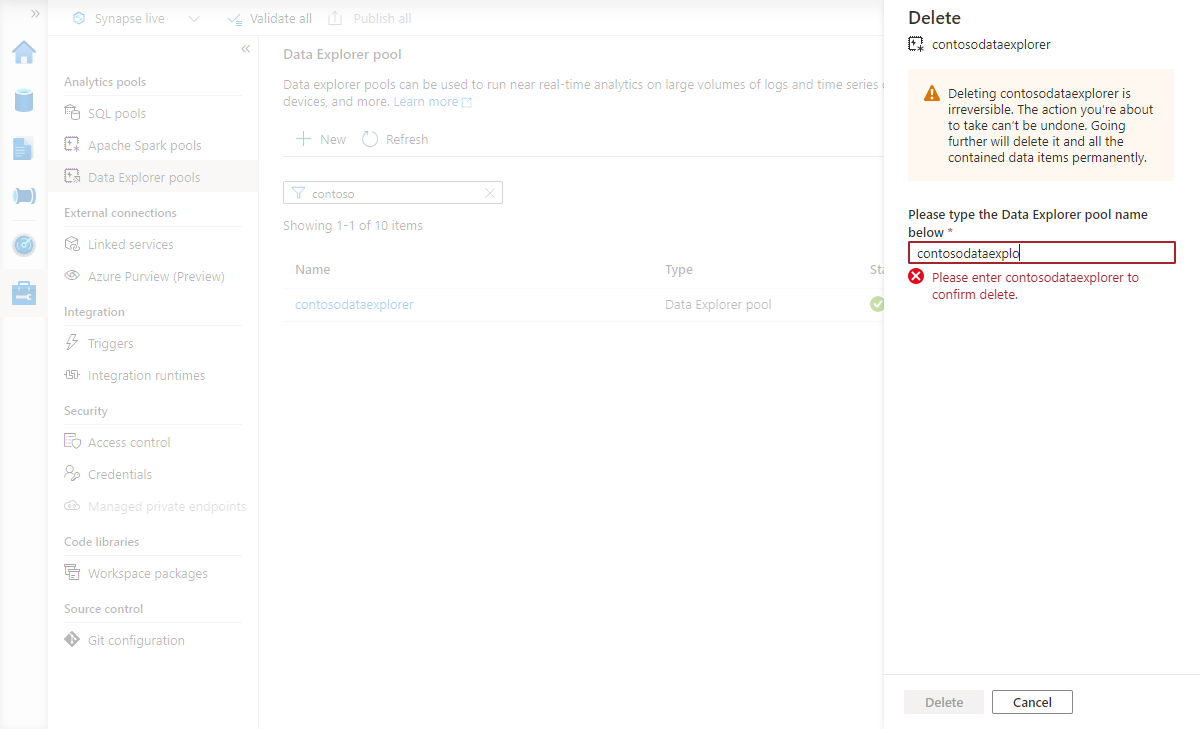
Bekräfta borttagningen genom att ange namnet på poolen som tas bort och sedan välja Ta bort.
När processen har slutförts kontrollerar du att poolen inte längre visas i listan.