Not
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Med lakedatabasen i Azure Synapse Analytics kan kunderna samla databasdesign, metainformation om de data som lagras och en möjlighet att beskriva hur och var data ska lagras. Lake-databasen hanterar utmaningen med dagens datasjöar där det är svårt att förstå hur data är strukturerade.
**
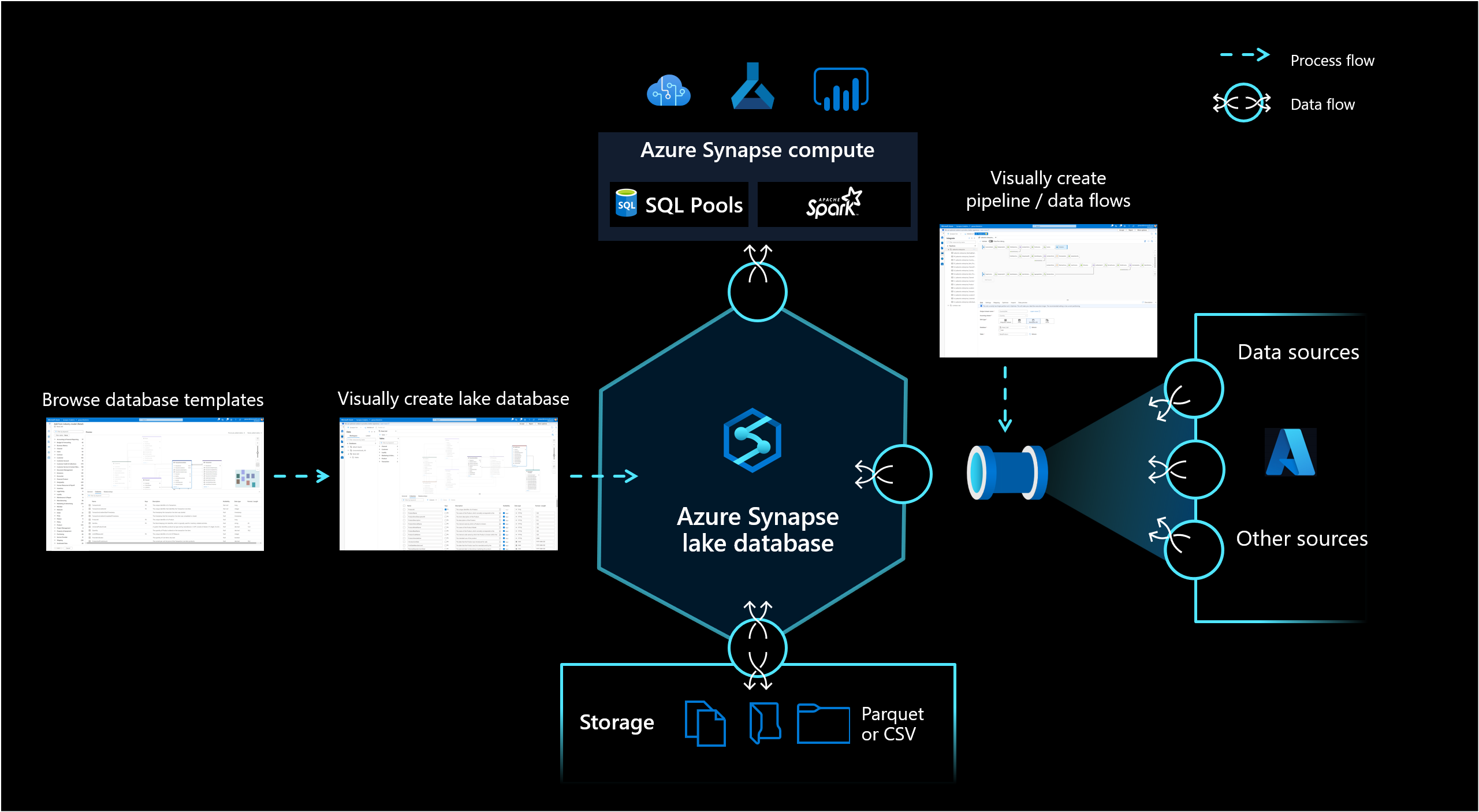
Databasformgivare
Den nya databasdesignern i Synapse Studio ger dig möjlighet att skapa en datamodell för din lake-databas och lägga till ytterligare information i den. Varje entitet och attribut kan beskrivas för att ge mer information om modellen, som inte bara innehåller entiteter utan även relationer. I synnerhet har oförmågan att modellera relationer varit en utmaning för interaktionen på datasjön. Den här utmaningen hanteras nu med en integrerad designer som ger möjligheter som har varit tillgängliga i databaser men inte på sjön. Även möjligheten att lägga till beskrivningar och möjliga demovärden i modellen gör det möjligt för personer som interagerar med den i framtiden att ha information där de behöver den för att få en bättre förståelse för data.
Kommentar
Den maximala storleken på metadata i en sjödatabas är 10 GB. Försök att publicera eller uppdatera en modell som överskrider 10 GB i storlek misslyckas. Lös problemet genom att minska modellstorleken genom att ta bort tabeller och kolumner. Överväg att dela upp stora modeller i flera sjödatabaser för att undvika den här gränsen.
Datalagring
Lake-databaser använder en datasjö på Azure Storage-kontot för att lagra databasens data. Data kan lagras i Parquet-, Delta- eller CSV-format och olika inställningar kan användas för att optimera lagringen. Varje lake-databas använder en länkad tjänst för att definiera platsen för rotdatamappen. För varje entitet skapas separata mappar som standard i den här databasmappen på datasjön. Som standard använder alla tabeller i en lake-databas samma format, men dataformaten och platsen kan ändras per entitet om det begärs.
Kommentar
Publicering av en lake-databas skapar inte någon av de underliggande strukturer eller scheman som behövs för att köra frågor mot data i Spark eller SQL. När du har publicerat läser du in data i din lake-databas med hjälp av pipelines för att börja köra frågor mot den.
Stöd för Delta-format för lake-databaser stöds för närvarande inte i Synapse Studio.
Synkroniseringen av lakedatabasobjekt mellan lagring och Synapse är enkelriktad. Se till att utföra alla skapande- eller schemaändringar av lake-databasobjekt med hjälp av databasdesignern i Synapse Studio. Om du i stället gör sådana ändringar från Spark eller direkt i lagringen blir definitionerna av dina lakedatabaser osynkroniserade. Om detta händer kan du se gamla lake-databasdefinitioner i databasdesignern. Du måste replikera och publicera sådana ändringar i databasdesignern för att kunna synkronisera dina lake-databaser igen.
Databasberäkning
Lake-databasen exponeras i Synapse SQL-serverlös SQL-pool och Apache Spark ger användarna möjlighet att frikoppla lagring från beräkning. Metadata som är associerade med lake-databasen gör det enkelt för olika beräkningsmotorer att inte bara tillhandahålla en integrerad upplevelse utan även använda ytterligare information (till exempel relationer) som inte ursprungligen stöddes på datasjön.
Relaterat innehåll
Fortsätt att utforska funktionerna i databasdesignern med hjälp av länkarna nedan.