Not
Åtkomst till denna sida kräver auktorisation. Du kan prova att logga in eller byta katalog.
Åtkomst till denna sida kräver auktorisation. Du kan prova att byta katalog.
I den här självstudien får du lära dig hur du enkelt kan utöka dina data i Azure Synapse Analytics med Azure AI-tjänster. Du kommer att använda Azure AI Avvikelseidentifiering för att hitta avvikelser. En användare i Azure Synapse kan helt enkelt välja en tabell för att utöka identifieringen av avvikelser.
Den här självstudiekursen omfattar:
- Steg för att hämta en Spark-tabelldatauppsättning som innehåller tidsseriedata.
- Användning av en guidad upplevelse i Azure Synapse för att förbättra data med hjälp av Anomaly Detector.
Om du inte har någon Azure-prenumeration skapar du ett kostnadsfritt konto innan du börjar.
Förutsättningar
- Azure Synapse Analytics-arbetsyta med ett Azure Data Lake Storage Gen2-lagringskonto konfigurerat som standardlagring. Du måste vara Storage Blob Data Contributor för det Data Lake Storage Gen2-filsystem som du arbetar med.
- Spark-pool på din Azure Synapse Analytics-arbetsyta. Mer information finns i Skapa en Spark-pool i Azure Synapse.
- Slutförande av förkonfigurationsstegen i självstudien Konfigurera Azure AI-tjänster i Azure Synapse .
Logga in på Azure-portalen
Logga in på Azure-portalen.
Skapa en Spark-tabell
Du behöver en Spark-tabell för den här handledningen.
Skapa en PySpark-anteckningsbok och kör följande kod.
from pyspark.sql.functions import lit
df = spark.createDataFrame([
("1972-01-01T00:00:00Z", 826.0),
("1972-02-01T00:00:00Z", 799.0),
("1972-03-01T00:00:00Z", 890.0),
("1972-04-01T00:00:00Z", 900.0),
("1972-05-01T00:00:00Z", 766.0),
("1972-06-01T00:00:00Z", 805.0),
("1972-07-01T00:00:00Z", 821.0),
("1972-08-01T00:00:00Z", 20000.0),
("1972-09-01T00:00:00Z", 883.0),
("1972-10-01T00:00:00Z", 898.0),
("1972-11-01T00:00:00Z", 957.0),
("1972-12-01T00:00:00Z", 924.0),
("1973-01-01T00:00:00Z", 881.0),
("1973-02-01T00:00:00Z", 837.0),
("1973-03-01T00:00:00Z", 9000.0)
], ["timestamp", "value"]).withColumn("group", lit("series1"))
df.write.mode("overwrite").saveAsTable("anomaly_detector_testing_data")
En Spark-tabell med namnet anomaly_detector_testing_data bör nu visas i standarddatabasen för Spark.
Öppna azure AI-tjänstguiden
Högerklicka på den Spark-tabell som skapades i föregående steg. Välj Machine Learning Predict with a model (Förutsäga maskininlärning>med en modell) för att öppna guiden.
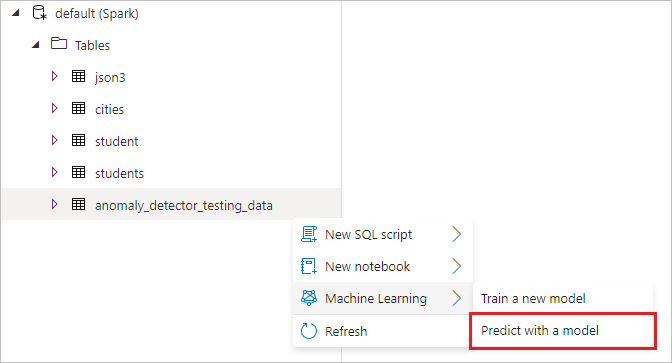
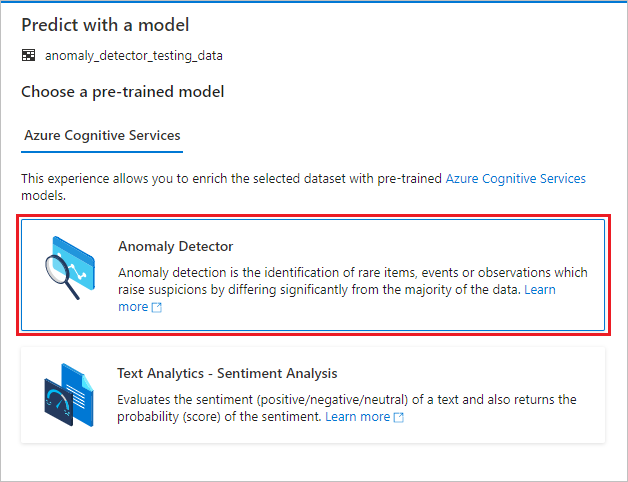
En konfigurationspanel visas, och du uppmanas att välja en förtränad modell. Välj Avvikelseidentifiering.
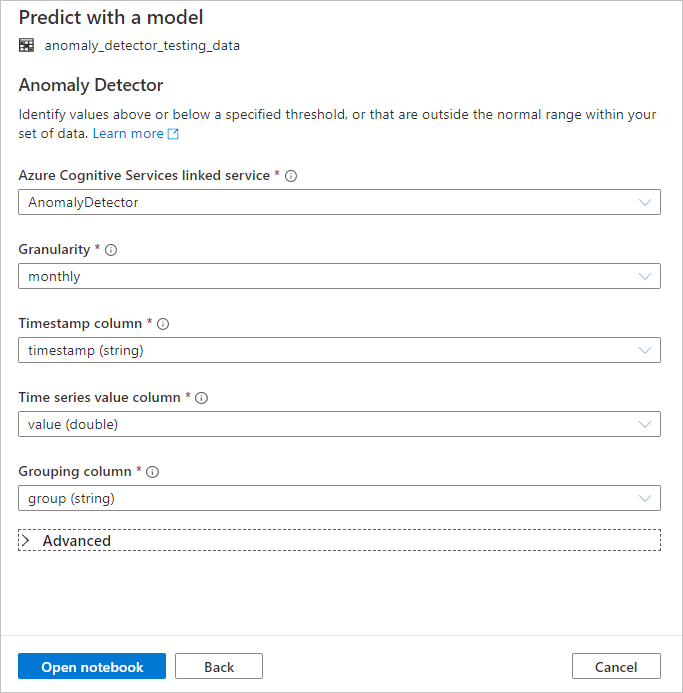
Konfigurera Anomalidetektor
Ange följande information för att konfigurera Avvikelseidentifiering:
Länkad Azure Cognitive Services-tjänst: Som en del av de nödvändiga stegen skapade du en länkad tjänst till din Azure AI-tjänst. Välj den här.
Kornighet: Den hastighet med vilken dina data samplas. Välj varje månad.
Tidsstämpelkolumn: Kolumnen som representerar tiden för serien. Välj tidsstämpel (sträng).
Kolumn för tidsserievärde: Den kolumn som representerar värdet för serien vid den tidpunkt som anges av kolumnen Tidsstämpel. Välj värde (dubbelt).
Grupperingskolumn: Kolumnen som grupperar serien. Alla rader som har samma värde i den här kolumnen bör alltså bilda en tidsserie. Välj grupp (sträng).
När du är klar väljer du Öppna anteckningsbok. Detta genererar en notebook-fil åt dig med PySpark-kod som använder Azure AI-tjänster för att identifiera avvikelser.
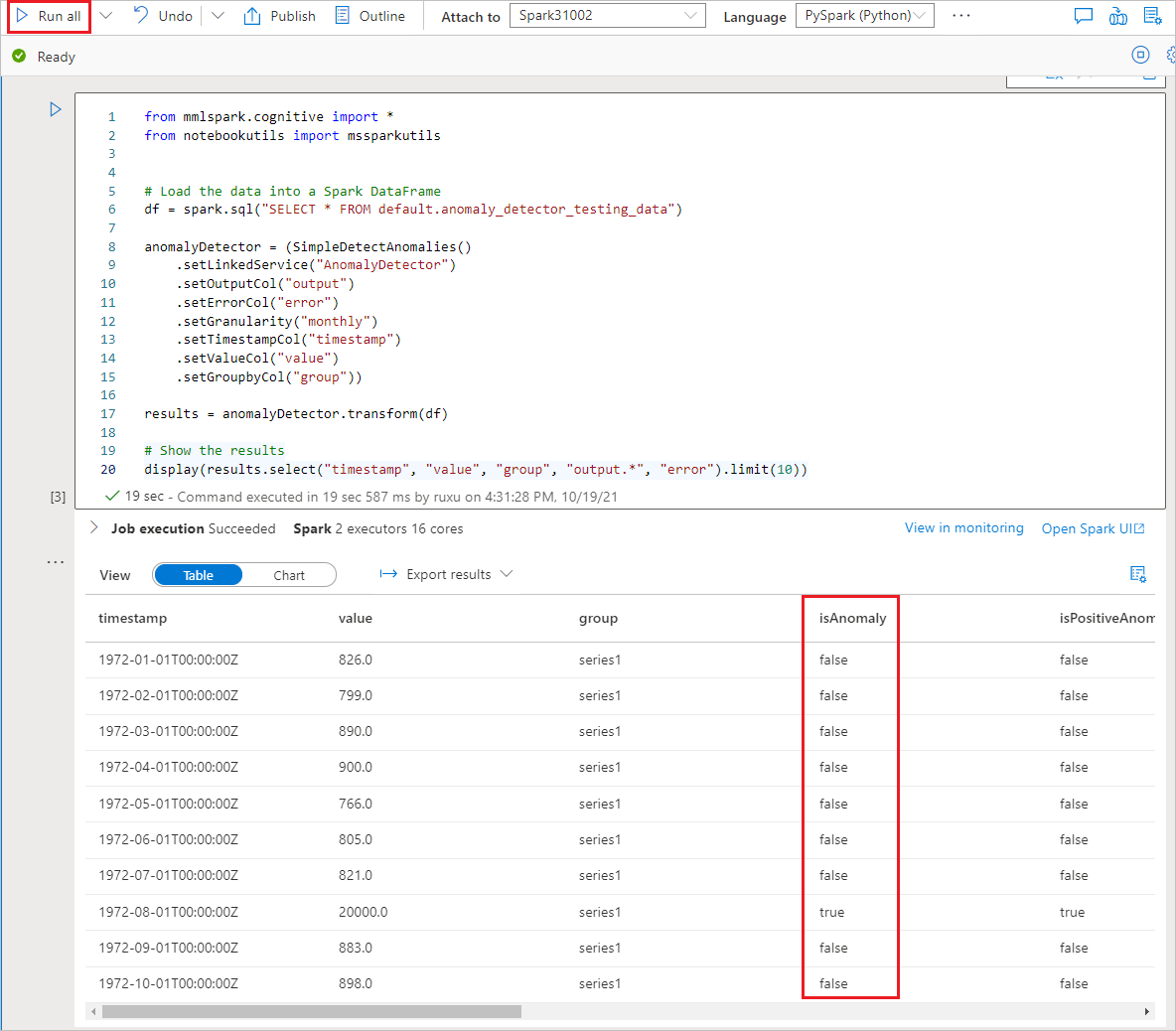
Kör anteckningsboken
Anteckningsboken som du precis öppnade använder SynapseML-biblioteket för att ansluta till Azure AI-tjänster. Med den länkade Azure AI-tjänst som du tillhandahöll kan du på ett säkert sätt referera till din Azure AI-tjänst från den här upplevelsen utan att avslöja några hemligheter.
Nu kan du köra alla celler för att utföra avvikelseidentifiering. Välj Kör alla. Läs mer om Avvikelseidentifiering i Azure AI-tjänster.