Not
Åtkomst till denna sida kräver auktorisation. Du kan prova att logga in eller byta katalog.
Åtkomst till denna sida kräver auktorisation. Du kan prova att byta katalog.
Med Azure Synapse Analytics kan du använda Apache Spark för att köra notebooks, jobb och andra typer av program på dina Apache Spark-pooler i din workspace.
Den här artikeln beskriver hur du övervakar dina Apache Spark-program så att du kan hålla ett öga på den senaste statusen, problemen och förloppet.
Visa Apache Spark-applikationer
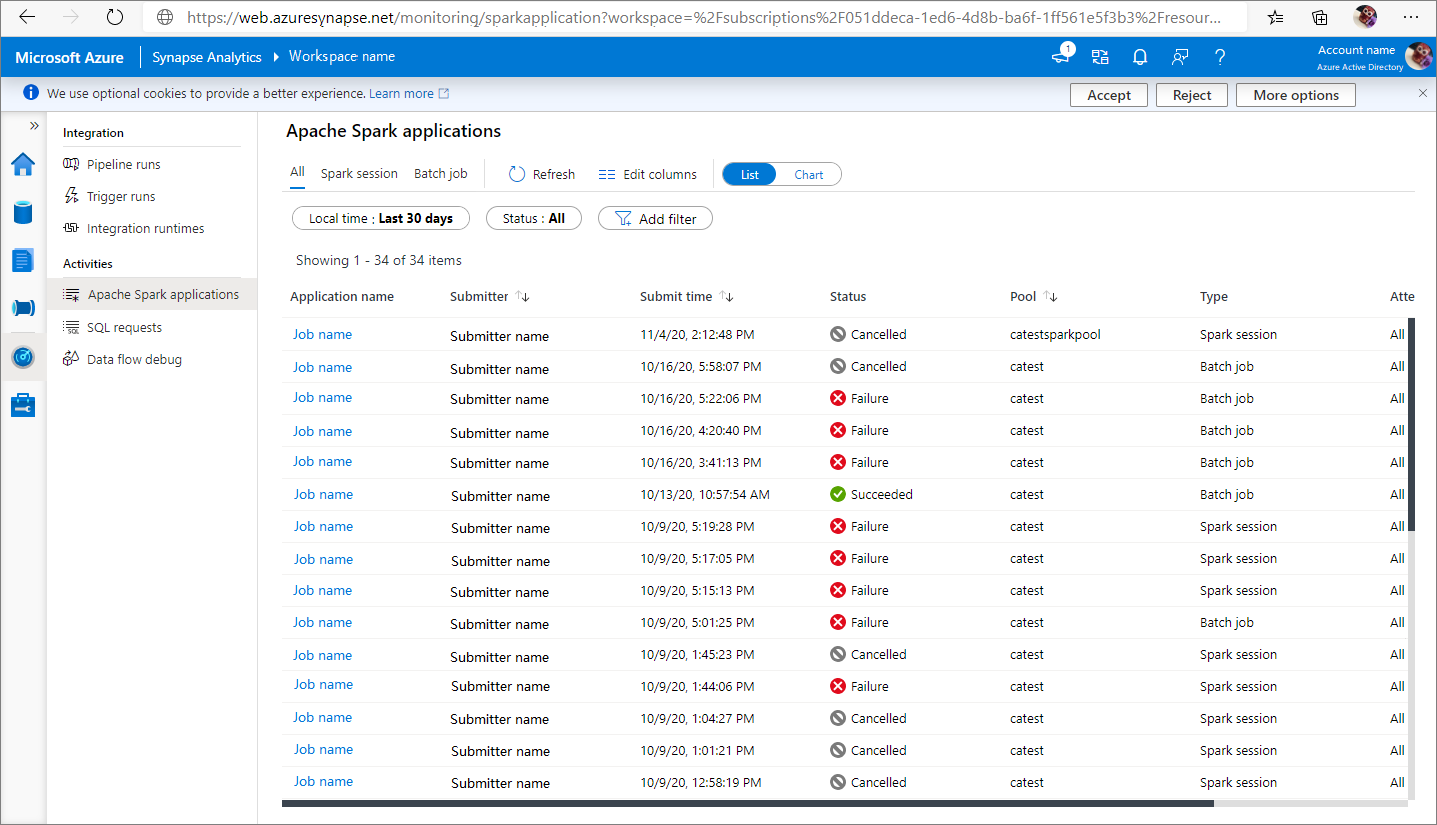
Du kan visa alla Apache Spark-program från Monitor -Apache Spark-program>.
Visa slutförda Apache Spark-program
Öppna Övervaka och välj sedan Apache Spark-program. Om du vill visa information om de slutförda Apache Spark-programmen väljer du Apache Spark-programmet.

Kontrollera varaktigheten Slutförda aktiviteter, Status och Total.
Uppdatera jobbet.
Klicka på Jämför program för att använda jämförelsefunktionen. Mer information om den här funktionen finns i Jämför Apache Spark-program.
Klicka på Spark-historikservern för att öppna sidan Historikserver.
Kontrollera sammanfattningsinformationen .
Kontrollera diagnostiken på fliken Diagnostik .
Kontrollera loggarna. Du kan visa fullständig logg över Livy-, Prelaunch- och Driver-loggar genom att välja olika alternativ i listrutan. Och du kan hämta nödvändig logginformation direkt genom att söka efter nyckelord. Klicka på Ladda ned logg för att ladda ned logginformationen till den lokala filen och markera kryssrutan Filtrera fel och varningar för att filtrera de fel och varningar du behöver.
Du kan se en översikt över ditt jobb i det genererade jobbdiagrammet. Som standard visar diagrammet alla jobb. Du kan filtrera den här vyn efter jobb-ID.
Som standard är förloppsvisningen markerad. Du kan kontrollera dataflödet genom att välja Förlopp/Läst/Skrivet/Varaktighet i listrutan Visa.
Om du vill spela upp jobbet klickar du på knappen Uppspelning . Du kan när som helst klicka på knappen Stoppa för att stoppa.
Använd rullningslisten för att zooma in och zooma ut jobbdiagrammet. Du kan också välja Zooma till Anpassa för att få den att passa skärmen.

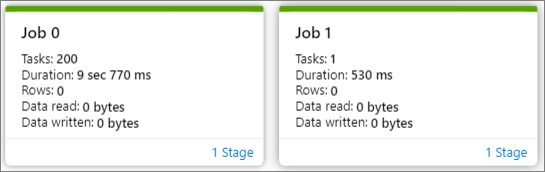
Jobbdiagramnoden visar följande information för varje steg:
Jobb-ID
Aktivitetsnummer
Varaktighetstid
Antal rader
Läsdata: summan av indatastorleken och shuffle-lässtorleken
Skrivna data: summan av utdatastorleken och shuffle-skrivstorleken
Stegnummer
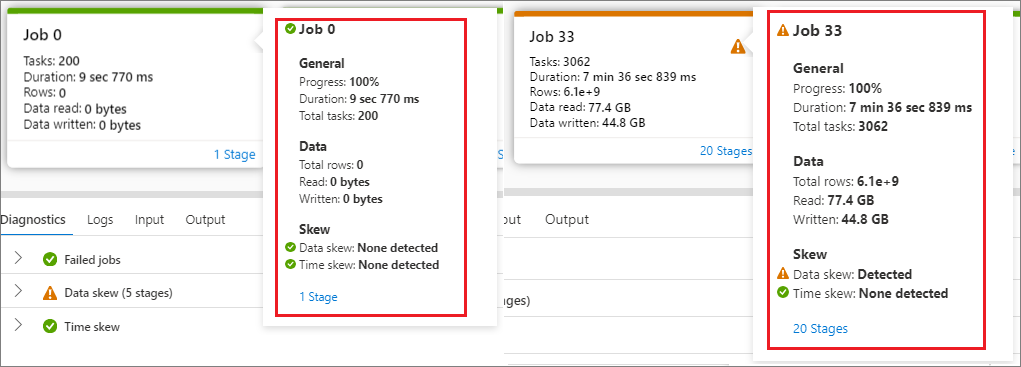
Hovra musen över ett jobb så visas jobbinformationen i knappbeskrivningen:
Ikon för jobbstatus: Om jobbet är lyckat visas det som en grön "√"; om jobbet upptäcker något problem visas det som ett gult "!"
Jobb-ID
Allmän del:
- Framsteg
- Varaktighetstid
- Totalt antal uppgifter
Datadel:
- Totalt antal rader
- Lässtorlek
- Textstorlek
Skev del:
- Dataskev
- Tidsförskjutning
Etappnummer
Klicka på Stegnummer för att expandera alla faser som ingår i jobbet. Klicka på Dölj bredvid jobb-ID:t för att dölja alla faser i jobbet.
Klicka på Visa information i ett stegdiagram. Informationen för en fas visas.


Övervaka Förloppet för Apache Spark-programmet
Öppna Övervaka och välj sedan Apache Spark-program. Om du vill visa information om de Apache Spark-program som körs väljer du det skickade Apache Spark-programmet. Om Apache Spark-programmet fortfarande körs kan du övervaka förloppet.

Kontrollera varaktigheten Slutförda aktiviteter, Status och Total.
Avbryt Apache Spark-programmet.
Uppdatera jobbet.
Klicka på knappen Spark-användargränssnitt för att gå till sidan Spark-jobb.
För jobbdiagram, sammanfattning, diagnostik, loggar. Du kan se en översikt över ditt jobb i det genererade jobbdiagrammet. Se steg 5–15 i Visa slutförda Apache Spark-program.

Visa avbrutna Apache Spark-program
Öppna Övervaka och välj sedan Apache Spark-program. Om du vill visa information om de avbrutna Apache Spark-programmen väljer du Apache Spark-programmet.

Kontrollera varaktigheten Slutförda aktiviteter, Status och Total.
Återställ jobbet.
Klicka på Jämför program för att använda jämförelsefunktionen. Mer information om den här funktionen finns i Jämför Apache Spark-program.
Öppna länken för Apache-historikservern genom att klicka på Spark-historikservern.
Visa diagrammet. Du kan se en översikt över ditt jobb i det genererade jobbdiagrammet. Se steg 5–15 i Visa slutförda Apache Spark-program.

Felsöka ett Apache Spark-program som misslyckades
Öppna Övervaka och välj sedan Apache Spark-program. Om du vill visa information om de misslyckade Apache Spark-programmen väljer du Apache Spark-programmet.

Kontrollera varaktigheten Slutförda aktiviteter, Status och Total.
Uppdatera jobbet.
Klicka på Jämför program för att använda jämförelsefunktionen. Mer information om den här funktionen finns i Jämför Apache Spark-program.
Öppna länken för Apache-historikservern genom att klicka på Spark-historikservern.
Visa diagrammet. Du kan se en översikt över ditt jobb i det genererade jobbdiagrammet. Se steg 5–15 i Visa slutförda Apache Spark-program.

Visa indatainformation/utdatainformation
Välj ett Apache Spark-program och klicka på fliken Indata/Utdata för att visa datum för indata och utdata för Apache Spark-programmet. Den här funktionen kan hjälpa dig att felsöka Spark-jobbet. Och datakällan stöder tre lagringsmetoder: gen1, gen2 och blob.
Fliken Indata
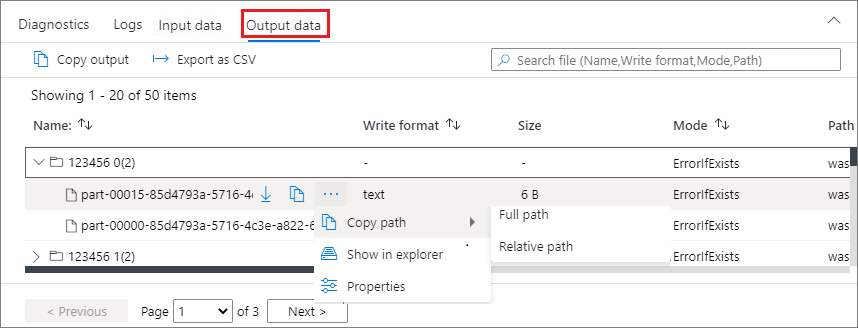
Klicka på knappen Kopiera indata för att klistra in indatafilen till den lokala filen.
Klicka på knappen Exportera till CSV för att exportera indatafilen i CSV-format.
Du kan söka efter filer med indatanyckelord i sökrutan (nyckelord inkluderar filnamn, läsformat och sökväg).
Du kan sortera indatafilerna genom att klicka på Namn, Läs format och sökväg.
Använd musen för att hovra över en indatafil. Ikonen för knappen Ladda ned/kopiera sökväg/Mer visas.
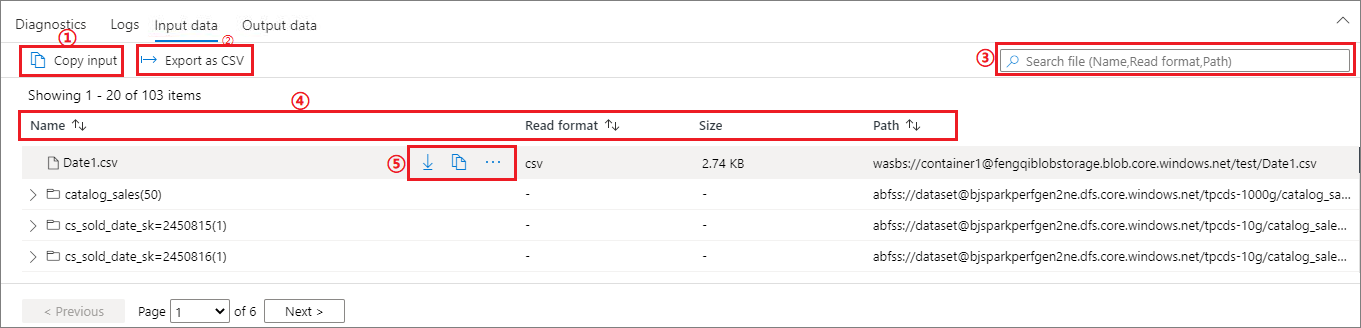
Klicka på knappen Mer . Kopiera sökväg/Visa i Utforskaren/Egenskaper visas i snabbmenyn.
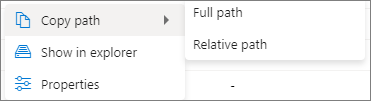
Kopieringssökväg: kan kopiera fullständig sökväg och relativ sökväg.
"Visa i 'Utforskaren': kan hoppa till det länkade lagringskontot (Data->Linked)."
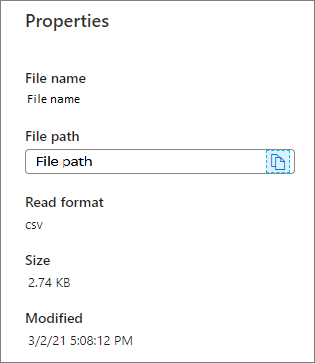
Egenskaper: visa de grundläggande egenskaperna för filen (Filnamn/Filsökväg/Läsformat/Storlek/Ändrad).
Utdatafliken
Visar samma funktioner som indatafliken.
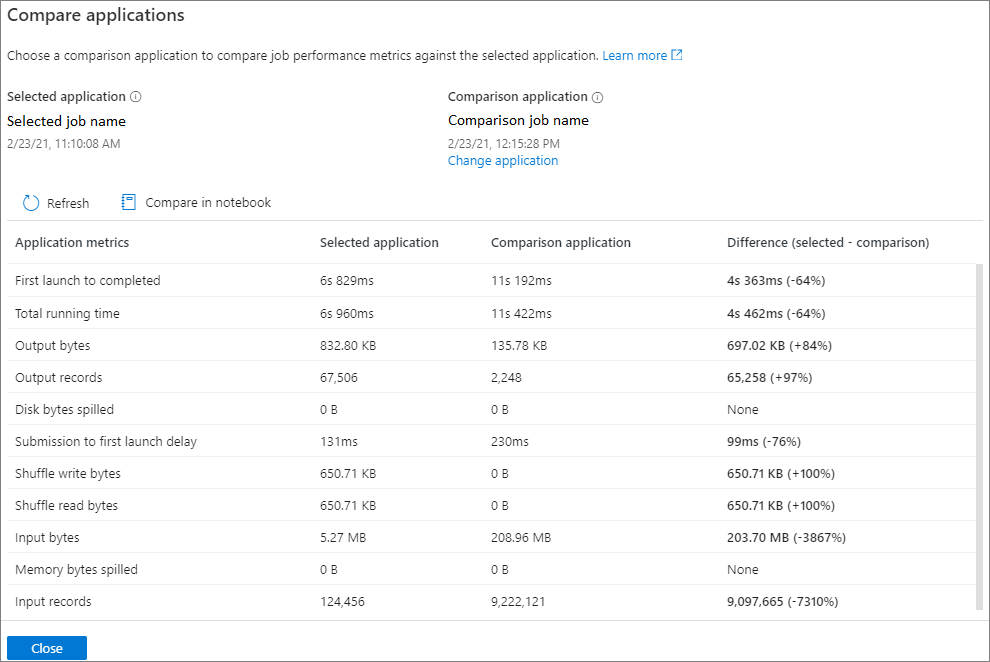
Jämföra Apache Spark-program
Det finns två sätt att jämföra program. Du kan jämföra genom att välja Jämför program eller klicka på knappen Jämför i anteckningsbok för att visa det i notebook-filen.
Jämför efter program
Klicka på knappen Jämför program och välj ett program för att jämföra prestanda. Du kan se skillnaden mellan de två programmen.

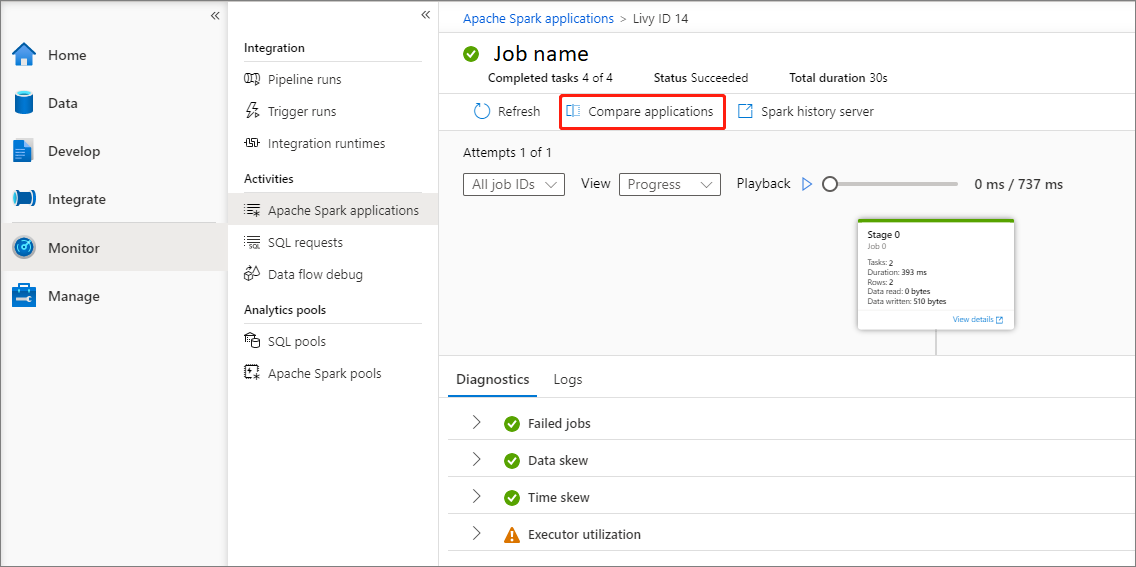
Använd musen för att hovra över ett program och sedan visas ikonen Jämför program .
Klicka på ikonen Jämför program så visas sidan Jämför program.
Klicka på knappen Välj program för att öppna sidan Välj jämförelseprogram .
När du väljer jämförelseprogrammet måste du antingen ange programmets URL eller välja från den återkommande listan. Klicka sedan på OK-knappen .
Jämförelseresultatet visas på sidan jämför program.
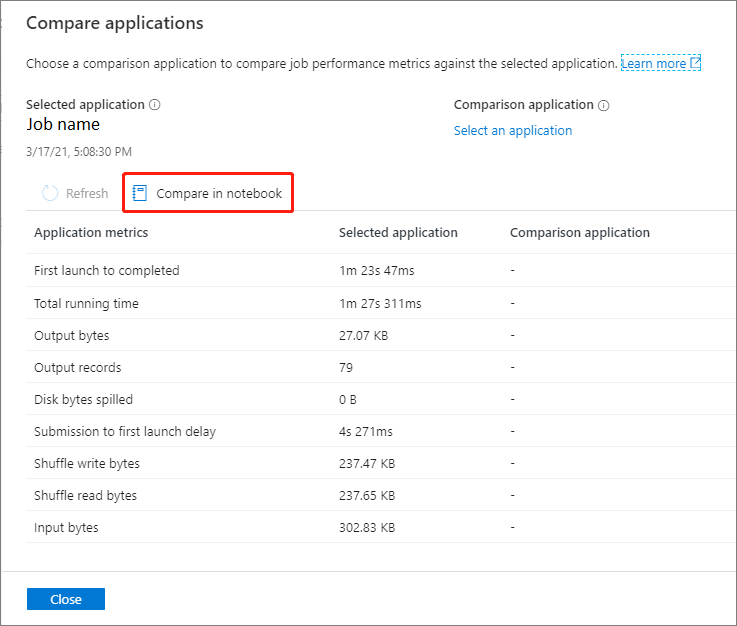
Jämför i notebook
Klicka på knappen Jämför i anteckningsbok på sidan Jämför program för att öppna anteckningsboken. Standardnamnet för .ipynb-filen är Recurrent Application Analytics.
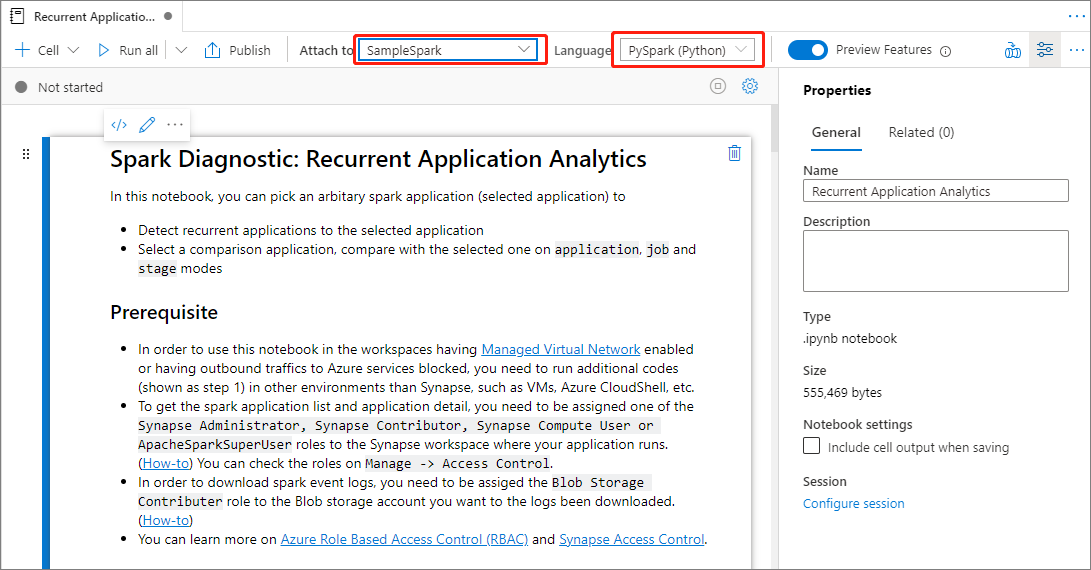
I filen Notebook: Recurrent Application Analytics kan du köra den direkt när du har angett Spark-poolen och språket.
Nästa steg
Mer information om hur du övervakar pipelinekörningar finns i artikeln Övervaka pipelinekörningar med Synapse Studio .