Ansluta till Azure Data Explorer med Apache Spark för Azure Synapse Analytics
Den här artikeln beskriver hur du får åtkomst till en Azure Data Explorer-databas från Synapse Studio med Apache Spark för Azure Synapse Analytics.
Förutsättningar
- Skapa ett Azure Data Explorer-kluster och en databas.
- Ha en befintlig Azure Synapse Analytics-arbetsyta eller skapa en ny arbetsyta genom att följa stegen i Snabbstart: Skapa en Azure Synapse-arbetsyta.
- Ha en befintlig Apache Spark-pool eller skapa en ny pool genom att följa stegen i Snabbstart: Skapa en Apache Spark-pool med hjälp av Azure-portalen.
- Skapa en Microsoft Entra-app genom att etablera ett Microsoft Entra-program.
- Ge din Microsoft Entra-app åtkomst till databasen genom att följa stegen i Hantera Azure Data Explorer-databasbehörigheter.
Gå till Synapse Studio
Från en Azure Synapse-arbetsyta väljer du Starta Synapse Studio. På synapse Studio-startsidan väljer du Data för att gå till Dataobjektutforskaren.
Anslut en Azure Data Explorer-databas till en Azure Synapse-arbetsyta
Anslut en Azure Data Explorer-databas till en arbetsyta görs via en länkad tjänst. Med en länkad Azure Data Explorer-tjänst kan du bläddra bland och utforska data, läsa och skriva från Apache Spark för Azure Synapse. Du kan också köra integrationsjobb i en pipeline.
Från Data Object Explorer följer du dessa steg för att ansluta ett Azure Data Explorer-kluster direkt:
+ Välj ikonen nära Data.
Välj Anslut för att ansluta till externa data.
Välj Azure Data Explorer (Kusto).
Välj Fortsätt.
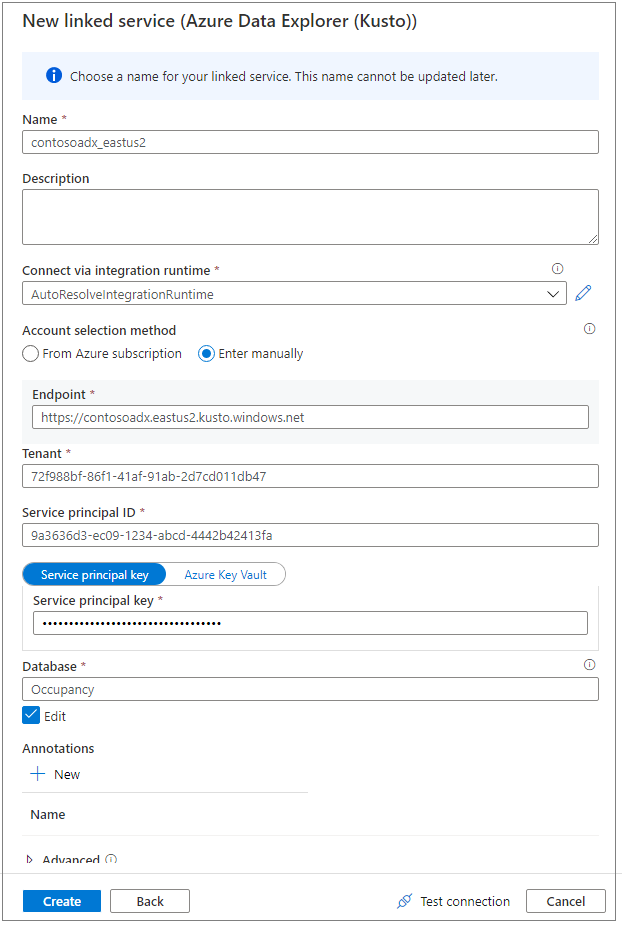
Använd ett eget namn för att namnge den länkade tjänsten. Namnet visas i Data Object Explorer och används av Azure Synapse-körningar för att ansluta till databasen.
Välj Azure Data Explorer-klustret från din prenumeration eller ange URI:n.
Ange tjänstens huvudnamns-ID och tjänstens huvudnamnsnyckel. Se till att tjänstens huvudnamn har visningsåtkomst till databasen för läsåtgärd och ingestor-åtkomst för inmatning av data.
Ange databasnamnet för Azure Data Explorer.
Välj Testa anslutning för att se till att du har rätt behörigheter.
Välj Skapa.
Kommentar
(Valfritt) Testanslutningen validerar inte skrivåtkomst. Kontrollera att tjänstens huvudnamns-ID har skrivåtkomst till Azure Data Explorer-databasen.
Azure Data Explorer-kluster och -databaser visas på fliken Länkad under avsnittet Azure Data Explorer .
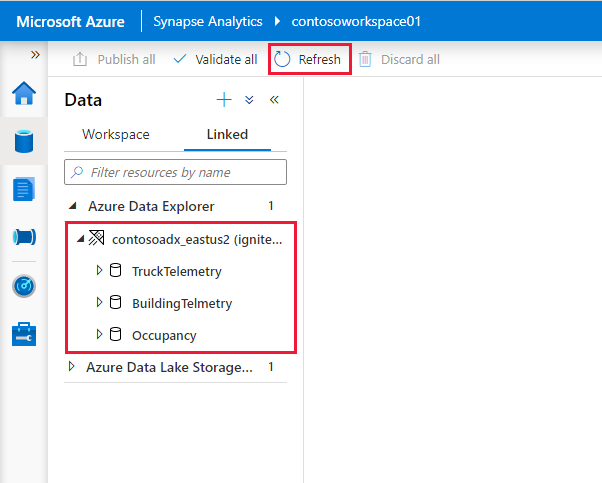
Innan du kan interagera med den länkade tjänsten från en notebook-fil måste den publiceras till arbetsytan. Klicka på Publicera i verktygsfältet, granska de väntande ändringarna och klicka på OK.
Kommentar
I den aktuella versionen fylls databasobjekten i baserat på dina Microsoft Entra-kontobehörigheter i Azure Data Explorer-databaserna. När du kör Apache Spark-notebook-filer eller integrationsjobb används autentiseringsuppgifterna i länktjänsten (till exempel tjänstens huvudnamn).
Interagera snabbt med kodgenererade åtgärder
När du högerklickar på en databas eller tabell visas en lista med Spark-exempelanteckningsböcker. Välj ett alternativ för att läsa, skriva eller strömma data till Azure Data Explorer.

Här är ett exempel på att läsa data. Koppla notebook-filen till Spark-poolen och kör cellen.

Kommentar
Det kan ta mer än tre minuter att starta Spark-sessionen första gången. Efterföljande körningar kommer att gå betydligt snabbare.
Begränsningar
Azure Data Explorer-anslutningsappen stöds för närvarande inte med Azure Synapse-hanterade virtuella nätverk.