Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Azure Synapse Analytics erbjuder olika analysmotorer som hjälper dig att mata in, transformera, modellera och analysera dina data. En dedikerad SQL-pool erbjuder T-SQL-baserade beräknings- och lagringsfunktioner. När du har skapat en dedikerad SQL-pool på din Synapse-arbetsyta kan data läsas in, modelleras, bearbetas och levereras för snabbare analysinsikt.
I den här snabbstarten lär du dig att läsa in data från Azure SQL Database till Azure Synapse Analytics. Du kan följa liknande steg för att kopiera data från andra typer av datalager. Det här liknande flödet gäller även för datakopiering för andra källor och mottagare.
Förutsättningar
- Azure-prenumeration: Om du inte har en Azure-prenumeration skapar du ett kostnadsfritt Azure-konto innan du börjar.
- Azure Synapse-arbetsyta: Skapa en Synapse-arbetsyta med hjälp av Azure-portalen enligt anvisningarna i Snabbstart: Skapa en Synapse-arbetsyta.
- Azure SQL Database: Den här självstudien kopierar data från Adventure Works LT-exempeldatauppsättningen i Azure SQL Database. Du kan skapa den här exempeldatabasen i SQL Database genom att följa anvisningarna i Skapa en exempeldatabas i Azure SQL Database. Du kan också använda andra datalager genom att följa liknande steg.
- Azure Storage-konto: Azure Storage används som mellanlagringsområde i kopieringsåtgärden. Om du inte har något Azure-lagringskonto kan du läsa anvisningarna i Skapa ett lagringskonto.
- Azure Synapse Analytics: Du använder en dedikerad SQL-pool som måldatalager. Om du inte har någon Azure Synapse Analytics-instans kan du läsa Skapa en dedikerad SQL-pool för steg för att skapa en.
Navigera till Synapse Studio
När din Synapse-arbetsyta har skapats kan du öppna Synapse Studio på två sätt:
- Öppna Synapse-arbetsytan i Azure-portalen. Välj Öppna på Komma igång-sidan under Synapse Studio.
- Öppna Azure Synapse Analytics och logga in på din arbetsyta.
I den här snabbstarten använder vi arbetsytan med namnet "adftest2020" som exempel. Den navigerar automatiskt till Synapse Studio-startsidan.
Skapa länkade tjänster
I Azure Synapse Analytics är en länkad tjänst där du definierar din anslutningsinformation till andra tjänster. I det här avsnittet skapar du följande två typer av länkade tjänster: länkade tjänster i Azure SQL Database och Azure Data Lake Storage Gen2 (ADLS Gen2).
På synapse Studio-startsidan väljer du fliken Hantera i det vänstra navigeringsfältet.
Under Externa anslutningar väljer du Länkade tjänster.
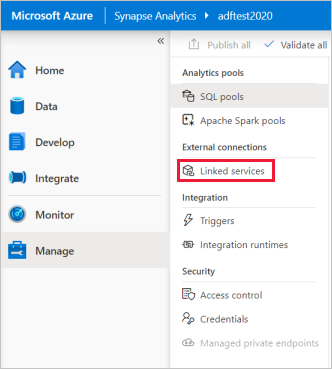
Om du vill lägga till en länkad tjänst väljer du Ny.
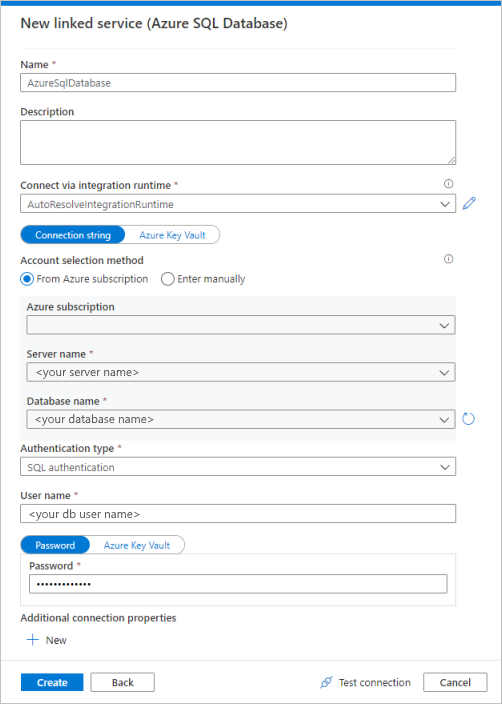
Välj Azure SQL Database i galleriet och välj sedan Fortsätt. Du kan skriva "sql" i sökrutan för att filtrera anslutningarna.

På sidan Ny länkad tjänst väljer du ditt servernamn och db-namn i listrutan och anger användarnamn och lösenord. Klicka på Testa anslutning för att verifiera inställningarna och välj sedan Skapa.
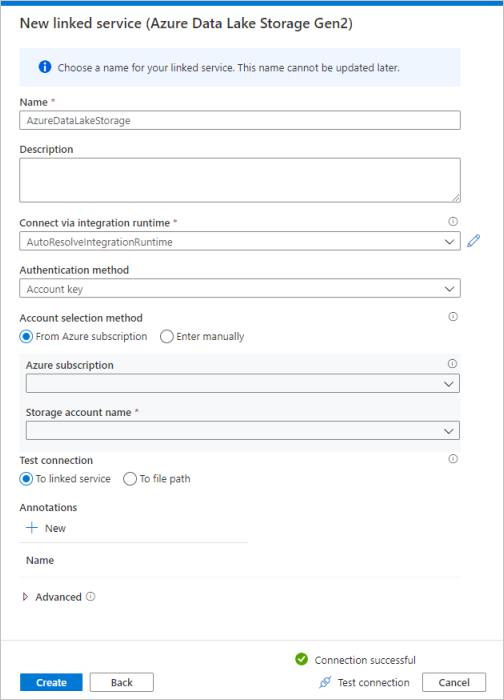
Upprepa steg 3–4, men välj Azure Data Lake Storage Gen2 i stället från galleriet. På sidan Ny länkad tjänst väljer du ditt lagringskontonamn i listrutan. Klicka på Testa anslutning för att verifiera inställningarna och välj sedan Skapa.
Skapa en processkedja
En pipeline innehåller det logiska flödet för en körning av en uppsättning aktiviteter. I det här avsnittet skapar du en pipeline som innehåller en kopieringsaktivitet som matar in data från Azure SQL Database till en dedikerad SQL-pool.
Gå till fliken Integrera . Välj plusikonen bredvid pipelinehuvudet och välj Pipeline.
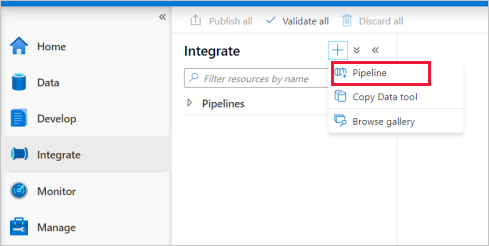
Under Flytta och transformera i fönstret Aktiviteter drar du Kopiera data till pipelinearbetsytan.
Välj på kopieringsaktiviteten och gå till fliken Källa. Välj Ny för att skapa en ny källdatauppsättning.
Välj Azure SQL Database som datalager och välj Fortsätt.
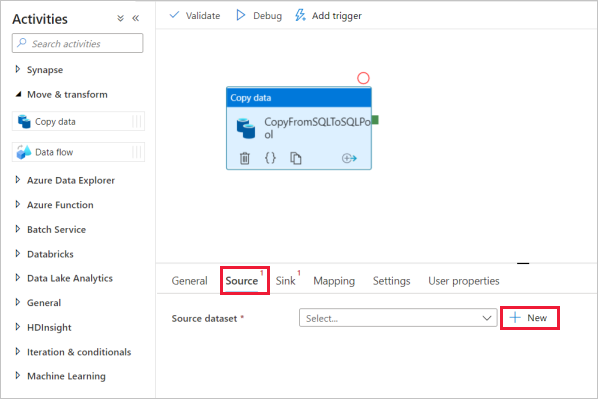
I fönstret Ange egenskaper väljer du den länkade Azure SQL Database-tjänst som du skapade i tidigare steg.
Under Tabellnamn väljer du en exempeltabell som ska användas i följande kopieringsaktivitet. I den här snabbstarten använder vi tabellen SalesLT.Customer som exempel.
Välj OK när du är klar.
Välj kopieringsaktiviteten och gå till fliken Sink. Välj Ny för att skapa en ny sink-datauppsättning.
Välj Azure Synapse-dedikerad SQL-pool som datalager och välj Fortsätt.
I fönstret Ange egenskaper väljer du den SQL Analytics-pool som du skapade i tidigare steg. Om du skriver till en befintlig tabell under Tabellnamn väljer du den i listrutan. Annars markerar du Redigera och anger det nya tabellnamnet. Välj OK när du är klar.
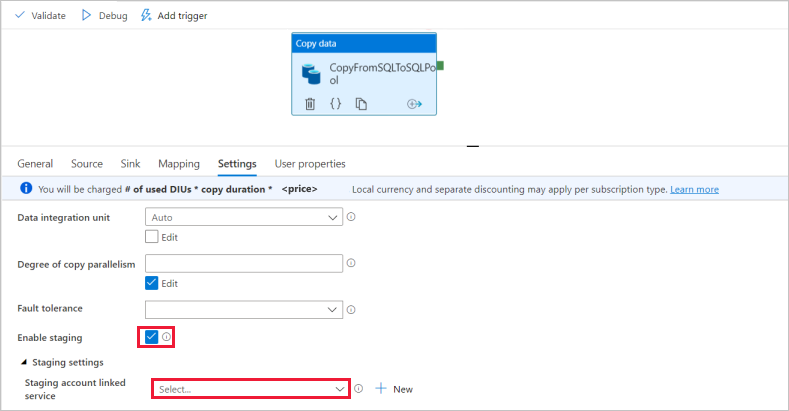
För inställningar för datauppsättning för datasänk, aktiverar du Skapa tabell automatiskt i fältet Tabellalternativ.
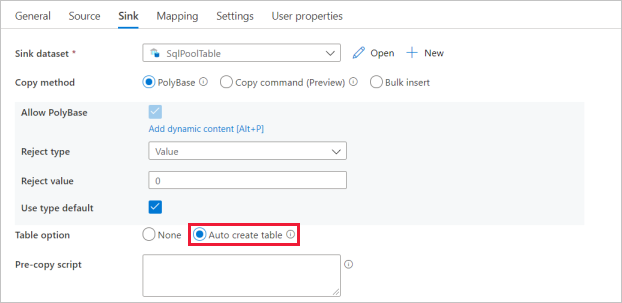
På sidan Inställningar markerar du kryssrutan för Aktivera mellanlagring. Det här alternativet gäller om dina källdata inte är kompatibla med PolyBase. I avsnittet Mellanlagringsinställningar väljer du den länkade Azure Data Lake Storage Gen2-tjänst som du skapade i tidigare steg som mellanlagring.
Lagringen används för att mellanlagring av data innan de läses in i Azure Synapse Analytics med hjälp av PolyBase. När kopian är klar rensas interimsdata i Azure Data Lake Storage Gen2 automatiskt.
Om du vill verifiera pipelinen väljer du Verifiera i verktygsfältet. Du ser resultatet av pipelinevalideringsutdata till höger på sidan.
Felsöka och publicera en pipeline
När du har konfigurerat pipelinen kan du köra en felsökningskörning innan du publicerar artefakterna för att kontrollera att allt är korrekt.
Välj Felsöka i verktygsfält för att felsöka pipelinen. Du ser status för pipelinekörningen på fliken Utdata längst ned i fönstret.
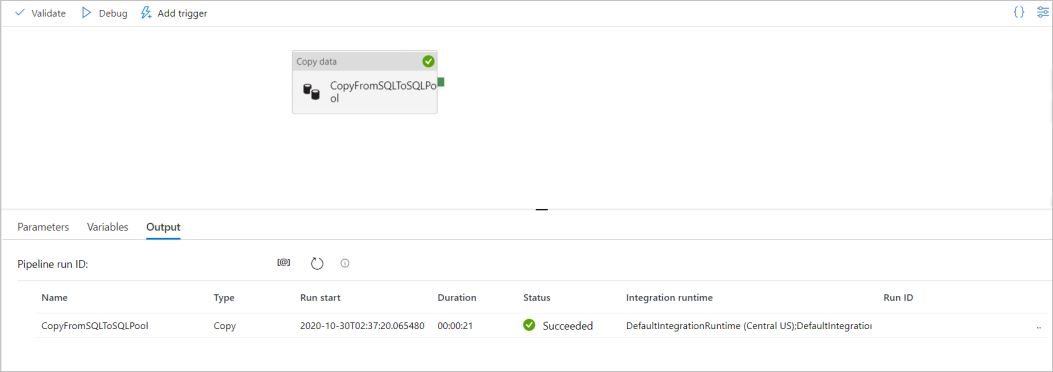
När pipelinekörningen är klar väljer du Publicera alla i det översta verktygsfältet. Den här åtgärden publicerar entiteter (datauppsättningar och pipelines) som du har skapat till Synapse Analytics-tjänsten.
Vänta tills du ser meddelandet Framgångsrikt publicerat. Om du vill se meddelanden väljer du klockknappen längst upp till höger.
Utlösa och övervaka pipelinen
I det här avsnittet utlöser du manuellt pipelinen som publicerades i föregående steg.
Välj Lägg till utlösare i verktygsfältet och välj sedan Utlösa nu. På sidan PipelineKörning väljer du OK.
Gå till fliken Övervaka i det vänstra sidofältet. Du ser en pipelinekörning som är utlöst av en manuell utlösare.
När pipelinekörningen har slutförts väljer du länken under kolumnen Pipelinenamn för att visa aktivitetskörningsinformation eller för att köra pipelinen igen. I det här exemplet finns det bara en aktivitet, så du ser bara en post i listan.
Om du vill ha mer information om kopieringsåtgärden väljer du länken Information (glasögonikonen) under kolumnen Aktivitetsnamn . Du kan övervaka information som mängden data som kopieras från källan till mottagaren, dataflödet, körningsstegen med motsvarande varaktighet och använda konfigurationer.
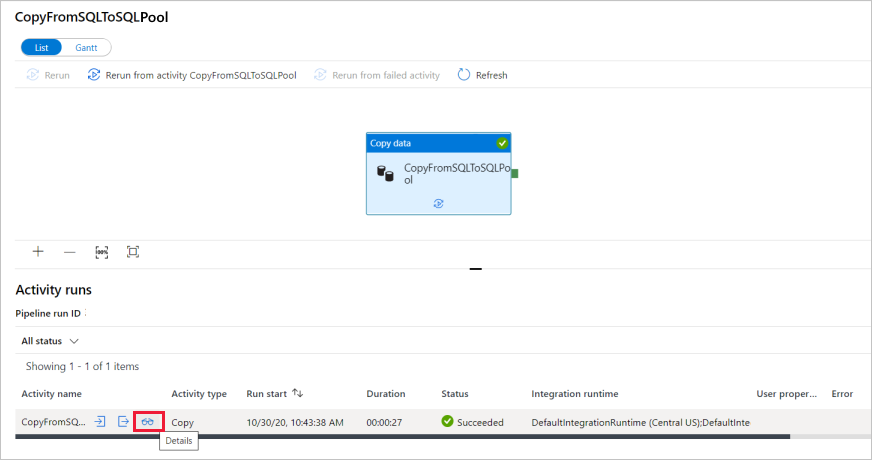
Om du vill växla tillbaka till pipelinekörningsvyn väljer du länken Alla pipelinekörningar längst upp. Välj Uppdatera för att uppdatera listan.
Kontrollera att dina data är korrekt skrivna i den dedikerade SQL-poolen.
Nästa steg
Gå vidare till följande artikel för att lära dig mer om Azure Synapse Analytics-stöd: