Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Azure Synapse Analytics erbjuder olika analysmotorer som hjälper dig att mata in, transformera, modellera, analysera och hantera dina data. Apache Spark-poolen erbjuder funktioner för stordatabearbetning med öppen källkod. När du har skapat en Apache Spark-pool på din Synapse-arbetsyta kan data läsas in, modelleras, bearbetas och hanteras för att få insikter.
Den här snabbstarten beskriver stegen för att skapa en Apache Spark-pool på en Synapse-arbetsyta med hjälp av Synapse Studio.
Viktigt!
Faktureringen för Spark-instanser beräknas per minut, oavsett om du använder dem eller inte. Se till att stänga av Spark-instansen när du har använt den eller ange en kort tidsgräns. Mer information finns i avsnittet Rensa resurser i den här artikeln.
Kommentar
Synapse Studio fortsätter att stödja terraform- eller bicep-baserade konfigurationsfiler.
Om du inte har någon Azure-prenumeration skapar du ett kostnadsfritt konto innan du börjar.
Förutsättningar
- Du behöver en Azure-prenumeration. Skapa ett kostnadsfritt Azure-konto om det behövs
- Du kommer att använda Synapse-arbetsytan.
Logga in på Azure-portalen
Logga in på Azure-portalen
Navigera till Synapse-arbetsytan
Gå till Synapse-arbetsytan där Apache Spark-poolen skapas genom att skriva tjänstnamnet (eller resursnamnet direkt) i sökfältet.
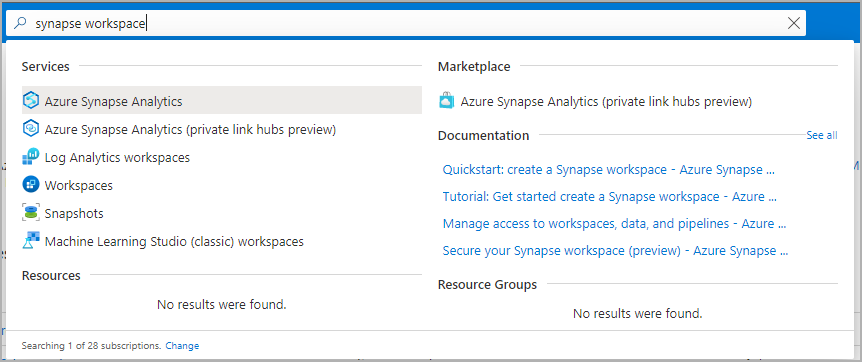
I listan över arbetsytor skriver du namnet (eller en del av namnet) på arbetsytan som ska öppnas. I det här exemplet använder vi en arbetsyta med namnet contosoanalytics.


Starta Synapse Studio
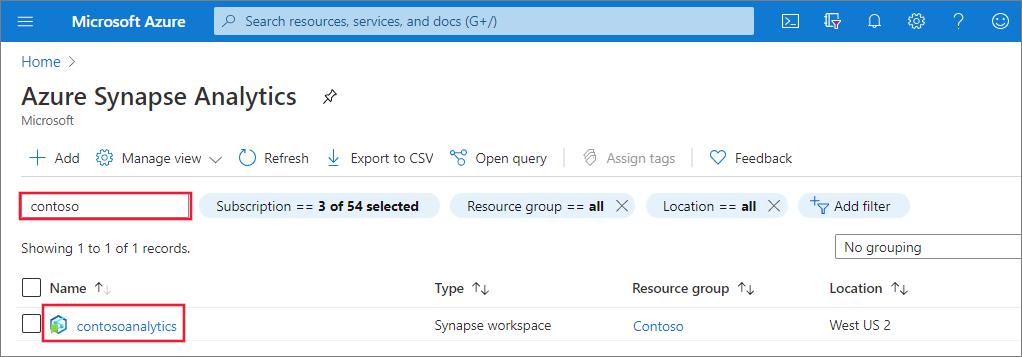
I översikten över arbetsytan väljer du webb-URL:en för arbetsytan för att öppna Synapse Studio.

Skapa Apache Spark-poolen i Synapse Studio
Viktigt!
Azure Synapse Runtime för Apache Spark 2.4 har blivit inaktuell och stöds officiellt inte sedan september 2023. Med tanke på att Spark 3.1 och Spark 3.2 också har upphört med supporten rekommenderar vi att kunderna migrerar till Spark 3.3.
På synapse Studio-startsidan går du till hanteringshubben i det vänstra navigeringsfältet genom att välja ikonen Hantera .
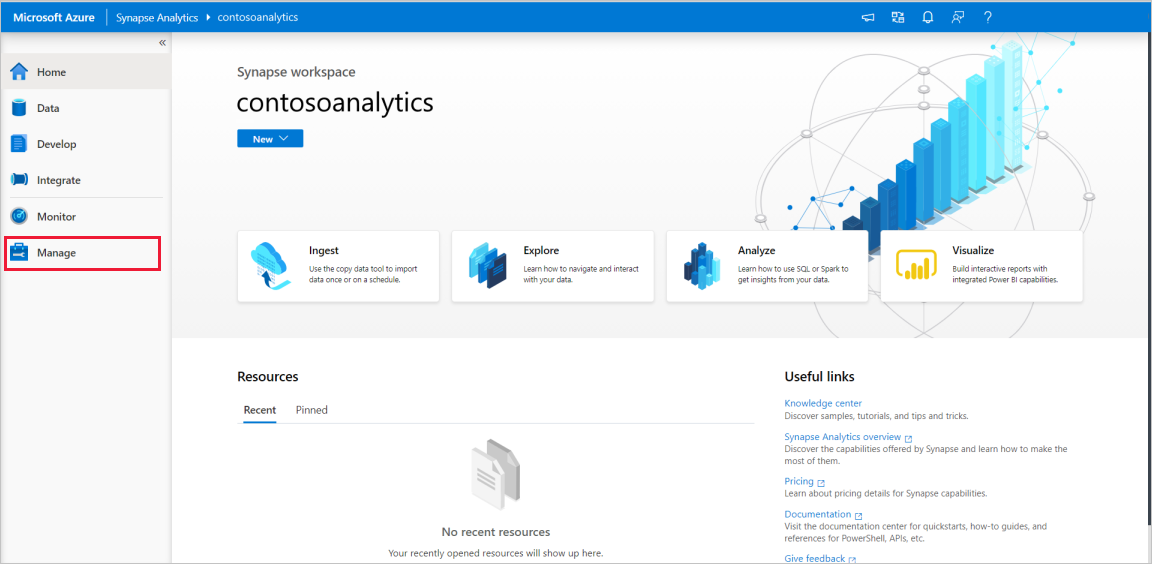
I hanteringshubben går du till avsnittet Apache Spark-pooler för att se den aktuella listan över Apache Spark-pooler som är tillgängliga på arbetsytan.

Välj + Ny så visas den nya guiden skapa Apache Spark-pool.
Ange följande information på fliken Grundläggande :
Inställning Föreslaget värde Beskrivning Namn på Apache Spark-pool Ett giltigt poolnamn, till exempel contososparkDet här är namnet som Apache Spark-poolen kommer att ha. Nodstorlek Liten (4 vCPU/32 GB) Ange den minsta storleken för att minska kostnaderna för den här snabbstarten Automatisk skalning Avaktiverad Vi kommer inte att behöva autoskala i den här snabbstarten Antal noder 8 Använd en liten storlek för att begränsa kostnaderna i den här snabbstarten Dynamisk allokering av exekverare Avaktiverad Den här inställningen mappar till den dynamiska allokeringsegenskapen i Spark-konfigurationen för Spark Application Executors-allokering. Vi kommer inte att behöva autoskalning i den här snabbstarten. 
Viktigt!
Det finns specifika begränsningar för de namn som Apache Spark-pooler kan använda. Namn får endast innehålla bokstäver eller siffror, måste innehålla högst 15 tecken, måste börja med en bokstav, inte innehålla reserverade ord och vara unika på arbetsytan.
På nästa flik, Ytterligare inställningar, lämnar du alla inställningar som standard.
Välj Taggar. Överväg att använda Azure-taggar. Till exempel taggen "Ägare" eller "CreatedBy" för att identifiera vem som skapade resursen och taggen "Miljö" för att identifiera om den här resursen finns i Produktion, Utveckling osv. Mer information finns i Utveckla din namngivnings- och taggningsstrategi för Azure-resurser. När du är klar väljer du Granska + skapa.
På fliken Granska + skapa kontrollerar du att informationen ser korrekt ut baserat på vad som angavs tidigare och trycker på Skapa.

Apache Spark-klustret kommer att starta etableringsprocessen.
När etableringen är klar visas den nya Apache Spark-poolen i listan.






Rensa Apache Spark-poolresurser med Synapse Studio
Följande steg tar bort den Apache Spark-poolen från arbetsytan med hjälp av Synapse Studio.
Varning
Om du tar bort en Spark-pool tas analysmotorn bort från arbetsytan. Det går inte längre att ansluta till poolen, och alla frågor, pipelines och notebook-filer som använder den här Spark-poolen fungerar inte längre.
Om du vill ta bort Apache Spark-poolen gör du följande:
Gå till Apache Spark-poolerna i hanteringshubben i Synapse Studio.
Välj ellipsen bredvid Apache-poolen som ska tas bort (i det här fallet contosospark) för att visa kommandona för Apache Spark-poolen.

Välj Ta bort.
Bekräfta borttagningen och tryck på knappen Ta bort .
När processen är klar visas inte längre Apache Spark-poolen i arbetsytans resurser.
