Självstudie: Skapa Apache Spark-jobbdefinition i Synapse Studio
Den här självstudien visar hur du använder Synapse Studio för att skapa Apache Spark-jobbdefinitioner och sedan skicka dem till en serverlös Apache Spark-pool.
Den här självstudien omfattar följande uppgifter:
- Skapa en Apache Spark-jobbdefinition för PySpark (Python)
- Skapa en Apache Spark-jobbdefinition för Spark (Scala)
- Skapa en Apache Spark-jobbdefinition för .NET Spark (C#/F#)
- Skapa jobbdefinition genom att importera en JSON-fil
- Exportera en Apache Spark-jobbdefinitionsfil till lokal
- Skicka en Apache Spark-jobbdefinition som ett batchjobb
- Lägga till en Apache Spark-jobbdefinition i pipeline
Förutsättningar
Innan du börjar med den här självstudien måste du uppfylla följande krav:
- En Azure Synapse Analytics-arbetsyta. Anvisningar finns i Skapa en Azure Synapse Analytics-arbetsyta.
- En serverlös Apache Spark-pool.
- Ett ADLS Gen2-lagringskonto. Du måste vara Storage Blob Data-deltagare för det ADLS Gen2-filsystem som du vill arbeta med. Om du inte gör det måste du lägga till behörigheten manuellt.
- Om du inte vill använda standardlagringen för arbetsytan länkar du det nödvändiga ADLS Gen2-lagringskontot i Synapse Studio.
Skapa en Apache Spark-jobbdefinition för PySpark (Python)
I det här avsnittet skapar du en Apache Spark-jobbdefinition för PySpark (Python).
Öppna Synapse Studio.
Du kan gå till Exempelfiler för att skapa Apache Spark-jobbdefinitioner för att ladda ned exempelfiler för python.zip, sedan packa upp det komprimerade paketet och extrahera wordcount.py - och shakespeare.txt-filerna .
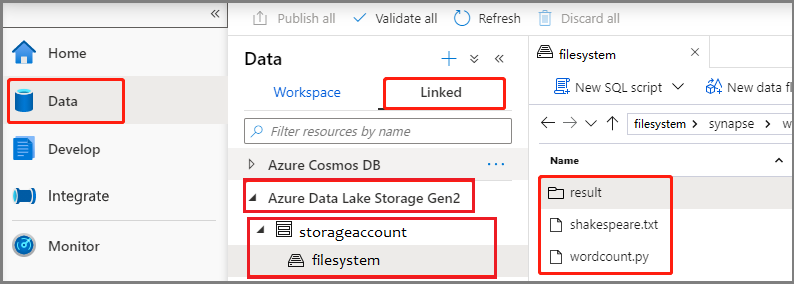
Välj Data ->Linked ->Azure Data Lake Storage Gen2 och ladda upp wordcount.py och shakespeare.txt till ditt ADLS Gen2-filsystem.
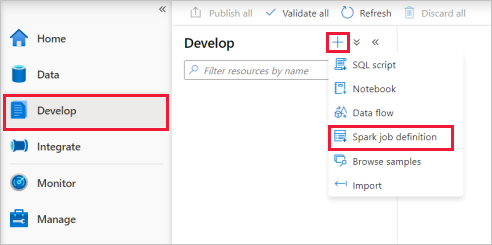
Välj Utveckla hubb, välj ikonen +och välj Spark-jobbdefinition för att skapa en ny Spark-jobbdefinition.
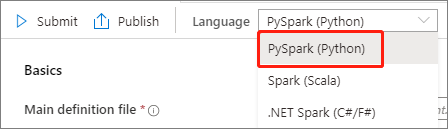
Välj PySpark (Python) i listrutan Språk i huvudfönstret för Apache Spark-jobbdefinitionen.
Fyll i information för Apache Spark-jobbdefinition.
Property beskrivning Namn på jobbdefinition Ange ett namn för apache Spark-jobbdefinitionen. Det här namnet kan uppdateras när som helst tills det publiceras.
Exempel:job definition sampleHuvuddefinitionsfil Huvudfilen som används för jobbet. Välj en PY-fil från lagringen. Du kan välja Ladda upp fil för att ladda upp filen till ett lagringskonto.
Exempel:abfss://…/path/to/wordcount.pyKommandoradsargument Valfria argument för jobbet.
Prov:abfss://…/path/to/shakespeare.txtabfss://…/path/to/result
Obs! Två argument för exempeljobbdefinitionen avgränsas med ett blanksteg.Referensfiler Ytterligare filer som används som referens i huvuddefinitionsfilen. Du kan välja Ladda upp fil för att ladda upp filen till ett lagringskonto. Spark-pool Jobbet skickas till den valda Apache Spark-poolen. Spark-version Version av Apache Spark som Apache Spark-poolen kör. Exekverare Antal utförare som ska anges i den angivna Apache Spark-poolen för jobbet. Storlek på köre Antal kärnor och minne som ska användas för utförare som anges i den angivna Apache Spark-poolen för jobbet. Drivrutinsstorlek Antal kärnor och minne som ska användas för drivrutinen som anges i den angivna Apache Spark-poolen för jobbet. Apache Spark-konfiguration Anpassa konfigurationer genom att lägga till egenskaper nedan. Om du inte lägger till en egenskap använder Azure Synapse standardvärdet när det är tillämpligt. 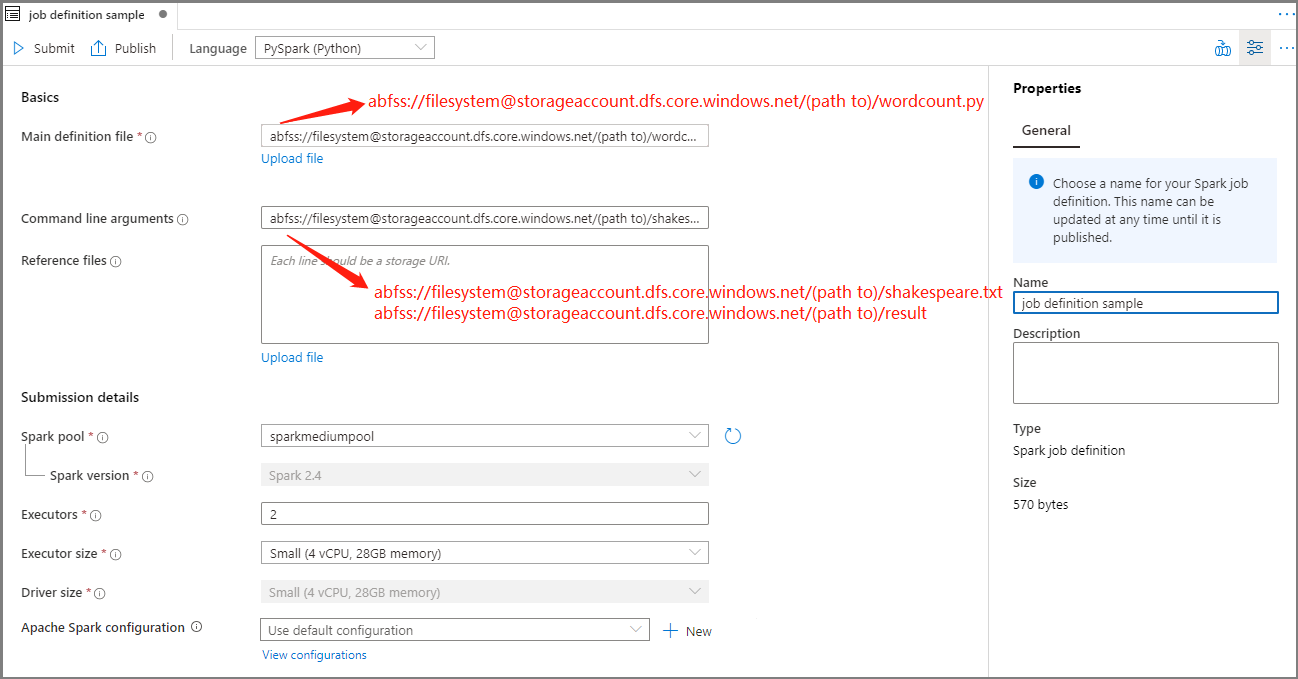
Välj Publicera för att spara Apache Spark-jobbdefinitionen.

Skapa en Apache Spark-jobbdefinition för Apache Spark (Scala)
I det här avsnittet skapar du en Apache Spark-jobbdefinition för Apache Spark (Scala).
Öppna Azure Synapse Studio.
Du kan gå till Exempelfiler för att skapa Apache Spark-jobbdefinitioner för att ladda ned exempelfiler för scala.zip, sedan packa upp det komprimerade paketet och extrahera wordcount.jar - och shakespeare.txt-filerna .
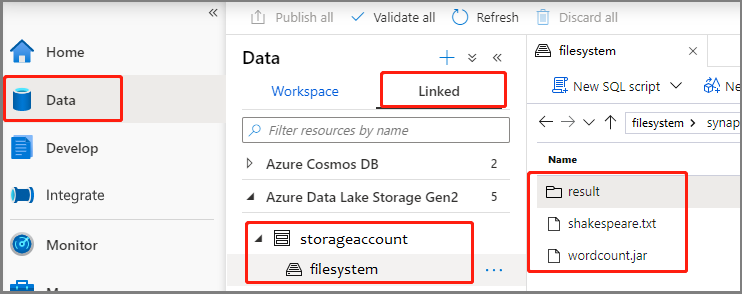
Välj Data ->Linked ->Azure Data Lake Storage Gen2 och ladda upp wordcount.jar och shakespeare.txt till ditt ADLS Gen2-filsystem.
Välj Utveckla hubb, välj ikonen +och välj Spark-jobbdefinition för att skapa en ny Spark-jobbdefinition. (Exempelbilden är samma som steg 4 i Skapa en Apache Spark-jobbdefinition (Python) för PySpark.)
Välj Spark(Scala) i listrutan Språk i huvudfönstret för Apache Spark-jobbdefinitionen.
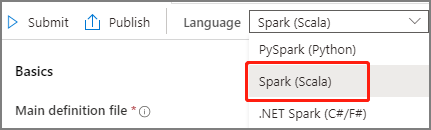
Fyll i information för Apache Spark-jobbdefinition. Du kan kopiera exempelinformationen.
Property beskrivning Namn på jobbdefinition Ange ett namn för apache Spark-jobbdefinitionen. Det här namnet kan uppdateras när som helst tills det publiceras.
Exempel:scalaHuvuddefinitionsfil Huvudfilen som används för jobbet. Välj en JAR-fil från lagringen. Du kan välja Ladda upp fil för att ladda upp filen till ett lagringskonto.
Exempel:abfss://…/path/to/wordcount.jarHuvudklassnamn Den fullständigt kvalificerade identifieraren eller huvudklassen som finns i huvuddefinitionsfilen.
Exempel:WordCountKommandoradsargument Valfria argument för jobbet.
Prov:abfss://…/path/to/shakespeare.txtabfss://…/path/to/result
Obs! Två argument för exempeljobbdefinitionen avgränsas med ett blanksteg.Referensfiler Ytterligare filer som används som referens i huvuddefinitionsfilen. Du kan välja Ladda upp fil för att ladda upp filen till ett lagringskonto. Spark-pool Jobbet skickas till den valda Apache Spark-poolen. Spark-version Version av Apache Spark som Apache Spark-poolen kör. Exekverare Antal utförare som ska anges i den angivna Apache Spark-poolen för jobbet. Storlek på köre Antal kärnor och minne som ska användas för utförare som anges i den angivna Apache Spark-poolen för jobbet. Drivrutinsstorlek Antal kärnor och minne som ska användas för drivrutinen som anges i den angivna Apache Spark-poolen för jobbet. Apache Spark-konfiguration Anpassa konfigurationer genom att lägga till egenskaper nedan. Om du inte lägger till en egenskap använder Azure Synapse standardvärdet när det är tillämpligt. 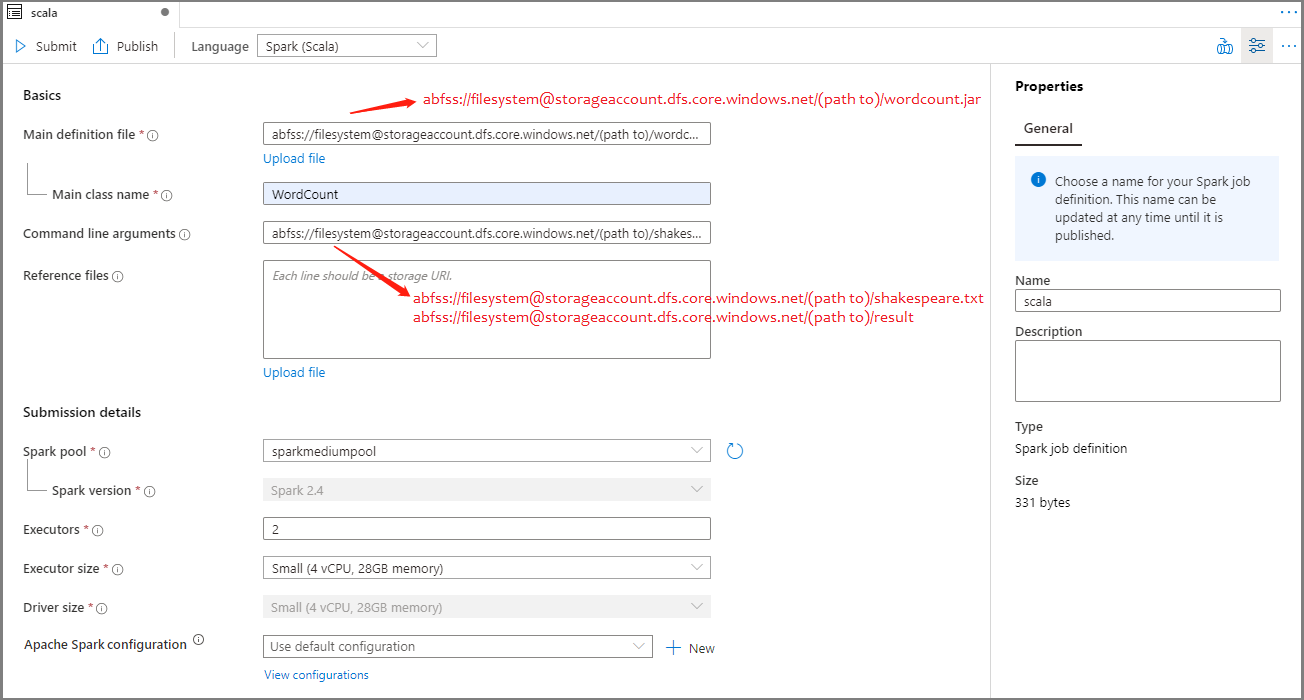
Välj Publicera för att spara Apache Spark-jobbdefinitionen.

Skapa en Apache Spark-jobbdefinition för .NET Spark(C#/F#)
I det här avsnittet skapar du en Apache Spark-jobbdefinition för .NET Spark(C#/F#).
Öppna Azure Synapse Studio.
Du kan gå till Exempelfiler för att skapa Apache Spark-jobbdefinitioner för att ladda ned exempelfiler för dotnet.zip, sedan packa upp det komprimerade paketet och extrahera wordcount.zip - och shakespeare.txt-filerna .
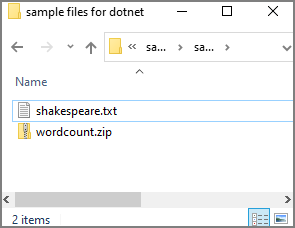
Välj Data ->Linked ->Azure Data Lake Storage Gen2 och ladda upp wordcount.zip och shakespeare.txt till ditt ADLS Gen2-filsystem.
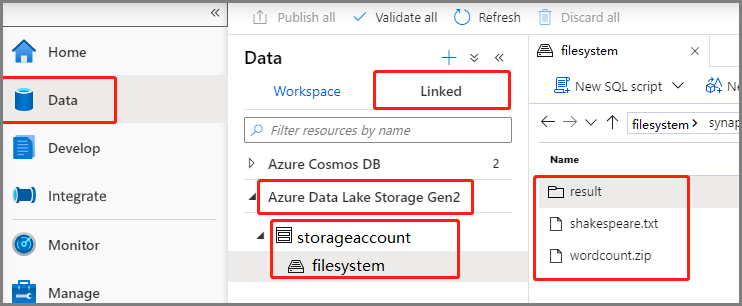
Välj Utveckla hubb, välj ikonen +och välj Spark-jobbdefinition för att skapa en ny Spark-jobbdefinition. (Exempelbilden är samma som steg 4 i Skapa en Apache Spark-jobbdefinition (Python) för PySpark.)
Välj .NET Spark(C#/F#) i listrutan Språk i huvudfönstret För Apache Spark-jobbdefinition.
Fyll i information för Apache Spark-jobbdefinition. Du kan kopiera exempelinformationen.
Property beskrivning Namn på jobbdefinition Ange ett namn för apache Spark-jobbdefinitionen. Det här namnet kan uppdateras när som helst tills det publiceras.
Exempel:dotnetHuvuddefinitionsfil Huvudfilen som används för jobbet. Välj en ZIP-fil som innehåller ditt .NET för Apache Spark-program (dvs. den körbara huvudfilen, DLL:er som innehåller användardefinierade funktioner och andra nödvändiga filer) från lagringen. Du kan välja Ladda upp fil för att ladda upp filen till ett lagringskonto.
Exempel:abfss://…/path/to/wordcount.zipHuvudfil som kan köras Den huvudsakliga körbara filen i ZIP-huvuddefinitionsfilen.
Exempel:WordCountKommandoradsargument Valfria argument för jobbet.
Prov:abfss://…/path/to/shakespeare.txtabfss://…/path/to/result
Obs! Två argument för exempeljobbdefinitionen avgränsas med ett blanksteg.Referensfiler Ytterligare filer som behövs av arbetsnoderna för att köra .NET för Apache Spark-programmet som inte ingår i ZIP-huvuddefinitionsfilen (det vill: beroende jar-filer, ytterligare användardefinierade funktions-DLL:er och andra konfigurationsfiler). Du kan välja Ladda upp fil för att ladda upp filen till ett lagringskonto. Spark-pool Jobbet skickas till den valda Apache Spark-poolen. Spark-version Version av Apache Spark som Apache Spark-poolen kör. Exekverare Antal utförare som ska anges i den angivna Apache Spark-poolen för jobbet. Storlek på köre Antal kärnor och minne som ska användas för utförare som anges i den angivna Apache Spark-poolen för jobbet. Drivrutinsstorlek Antal kärnor och minne som ska användas för drivrutinen som anges i den angivna Apache Spark-poolen för jobbet. Apache Spark-konfiguration Anpassa konfigurationer genom att lägga till egenskaper nedan. Om du inte lägger till en egenskap använder Azure Synapse standardvärdet när det är tillämpligt. 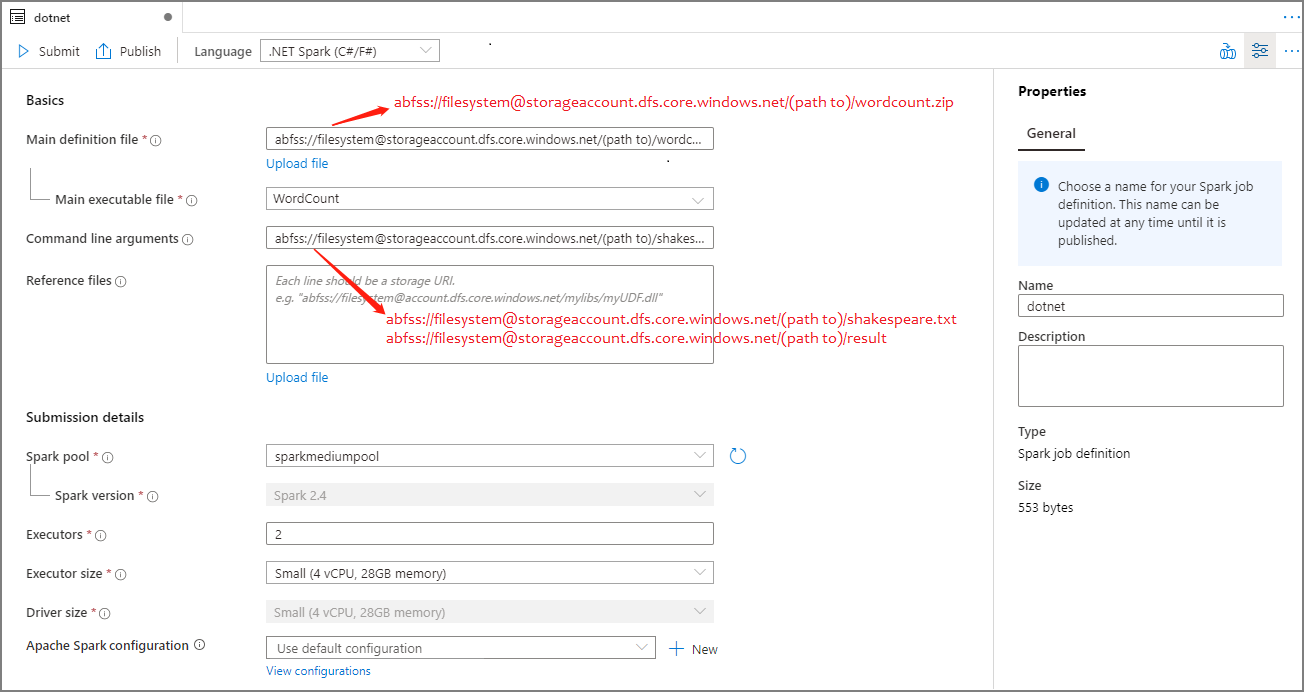
Välj Publicera för att spara Apache Spark-jobbdefinitionen.

Kommentar
Om Apache Spark-konfigurationen av Apache Spark-jobbdefinitionen inte gör något speciellt för Apache Spark-konfigurationen används standardkonfigurationen när jobbet körs.
Skapa Apache Spark-jobbdefinition genom att importera en JSON-fil
Du kan importera en befintlig lokal JSON-fil till Azure Synapse-arbetsytan från menyn Åtgärder (...) i Apache Spark-jobbdefinitionsutforskaren för att skapa en ny Apache Spark-jobbdefinition.
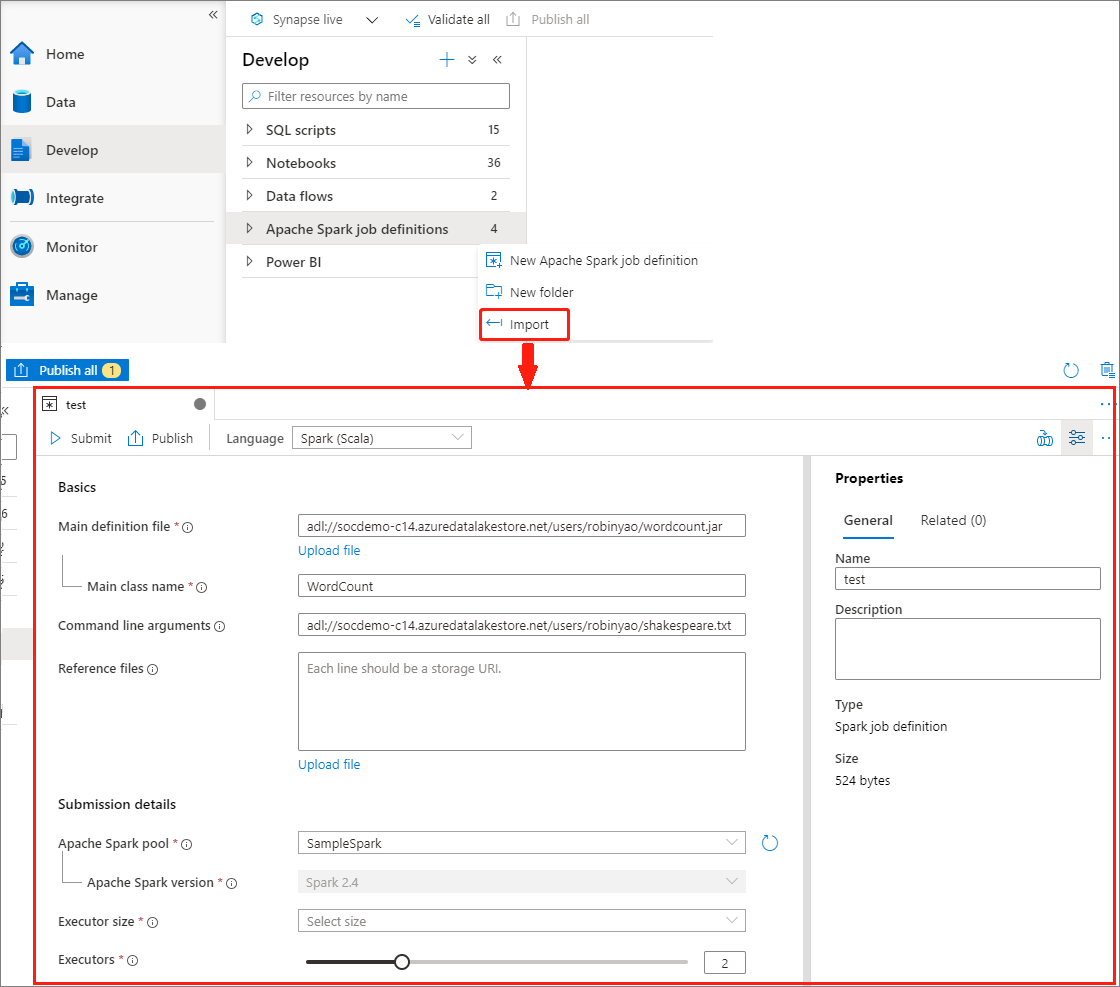
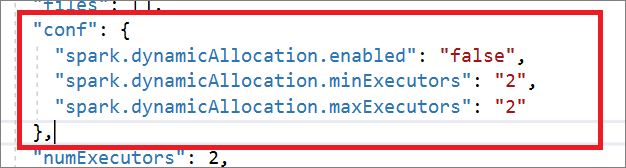
Spark-jobbdefinitionen är helt kompatibel med Livy API. Du kan lägga till ytterligare parametrar för andra Livy-egenskaper (Livy Docs – REST API (apache.org) i den lokala JSON-filen. Du kan också ange de Spark-konfigurationsrelaterade parametrarna i konfigurationsegenskapen enligt nedan. Sedan kan du importera tillbaka JSON-filen för att skapa en ny Apache Spark-jobbdefinition för batchjobbet. Exempel på JSON för spark-definitionsimport:
{
"targetBigDataPool": {
"referenceName": "socdemolarge",
"type": "BigDataPoolReference"
},
"requiredSparkVersion": "2.3",
"language": "scala",
"jobProperties": {
"name": "robinSparkDefinitiontest",
"file": "adl://socdemo-c14.azuredatalakestore.net/users/robinyao/wordcount.jar",
"className": "WordCount",
"args": [
"adl://socdemo-c14.azuredatalakestore.net/users/robinyao/shakespeare.txt"
],
"jars": [],
"files": [],
"conf": {
"spark.dynamicAllocation.enabled": "false",
"spark.dynamicAllocation.minExecutors": "2",
"spark.dynamicAllocation.maxExecutors": "2"
},
"numExecutors": 2,
"executorCores": 8,
"executorMemory": "24g",
"driverCores": 8,
"driverMemory": "24g"
}
}
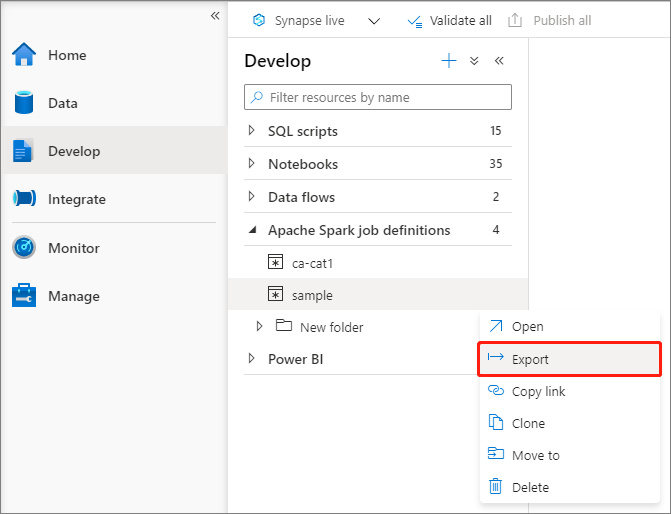
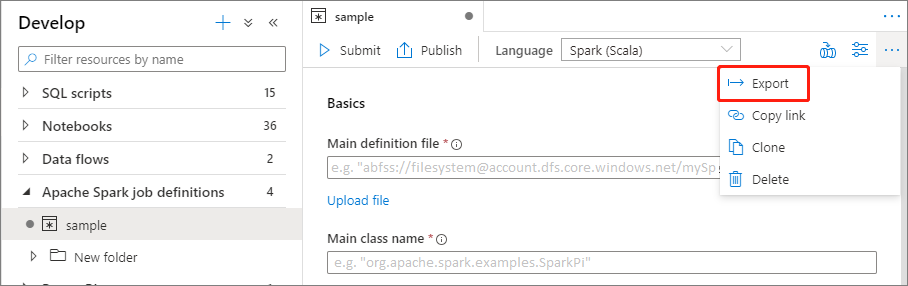
Exportera en befintlig Apache Spark-jobbdefinitionsfil
Du kan exportera befintliga Apache Spark-jobbdefinitionsfiler till lokala från åtgärdsmenyn (...) i Istraživač datoteka. Du kan uppdatera JSON-filen ytterligare för ytterligare Livy-egenskaper och importera tillbaka den för att skapa en ny jobbdefinition om det behövs.
Skicka en Apache Spark-jobbdefinition som ett batchjobb
När du har skapat en Apache Spark-jobbdefinition kan du skicka den till en Apache Spark-pool. Kontrollera att du är lagringsblobdatadeltagare för det ADLS Gen2-filsystem som du vill arbeta med. Om du inte gör det måste du lägga till behörigheten manuellt.
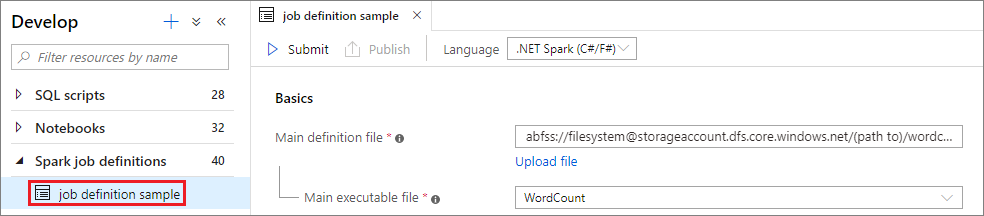
Scenario 1: Skicka Apache Spark-jobbdefinition
Öppna ett Apache Spark-jobbdefinitionsfönster genom att välja det.
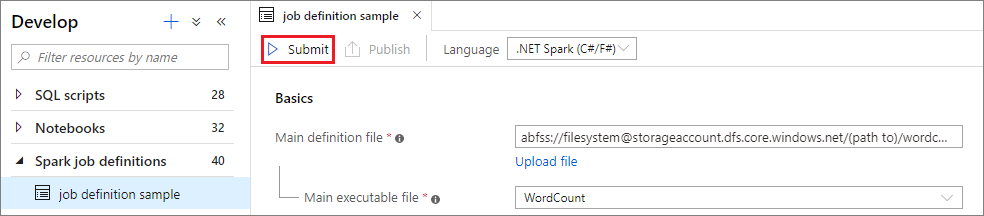
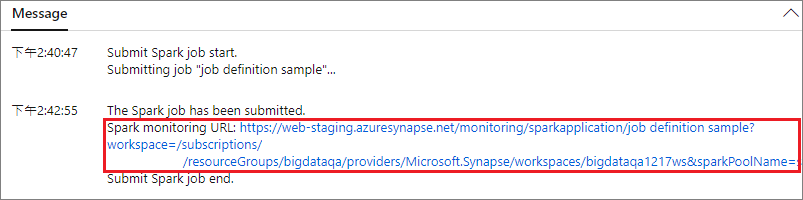
Välj knappen Skicka för att skicka projektet till den valda Apache Spark-poolen. Du kan välja fliken Spark-övervaknings-URL för att se LogQuery för Apache Spark-programmet.
Scenario 2: Visa förloppet för Apache Spark-jobb som kör
Välj Övervaka och välj sedan alternativet Apache Spark-program . Du hittar det skickade Apache Spark-programmet.
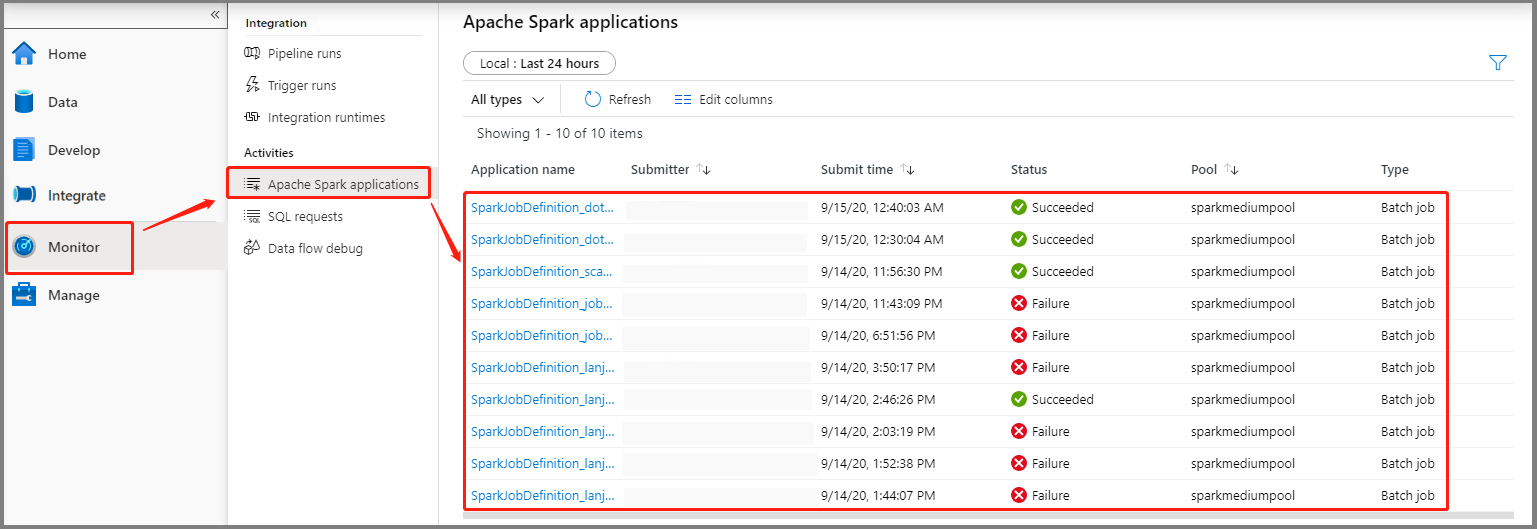
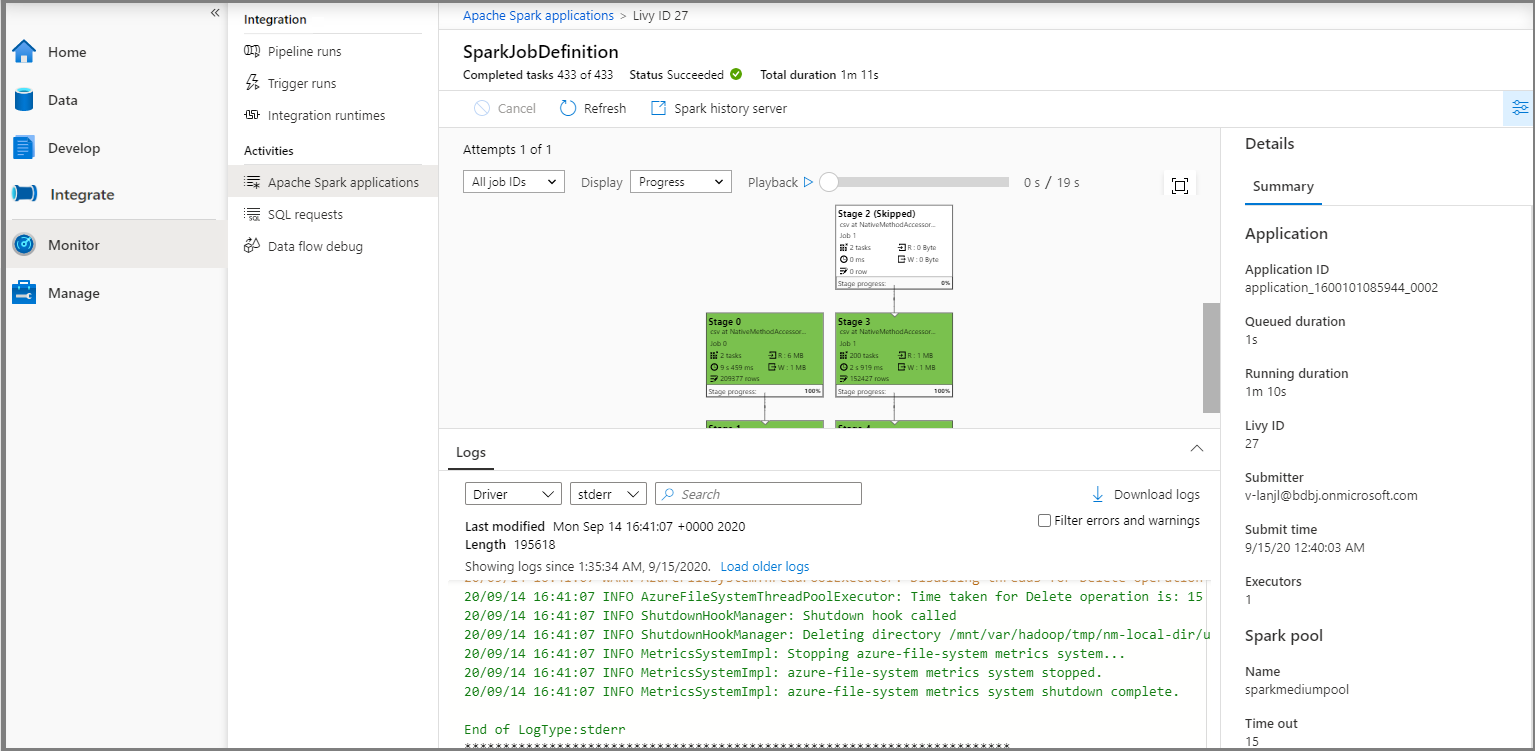
Välj sedan ett Apache Spark-program. Fönstret SparkJobDefinition-jobb visas. Du kan visa jobbkörningens förlopp härifrån.
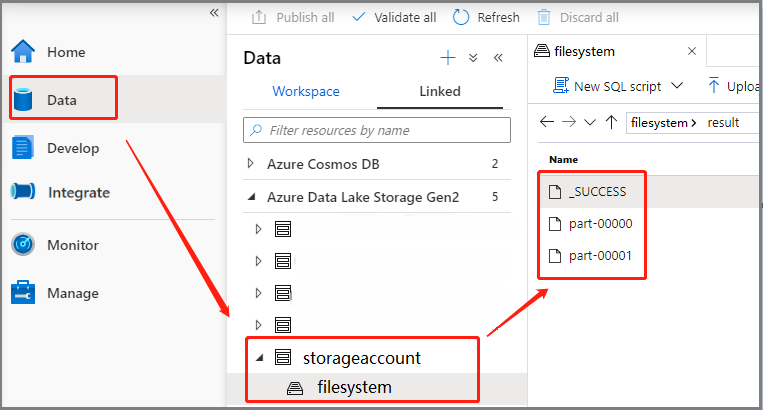
Scenario 3: Kontrollera utdatafilen
Välj Data ->Linked ->Azure Data Lake Storage Gen2 (hozhaobdbj), öppna resultatmappen som skapades tidigare. Du kan gå till resultatmappen och kontrollera om utdata genereras.
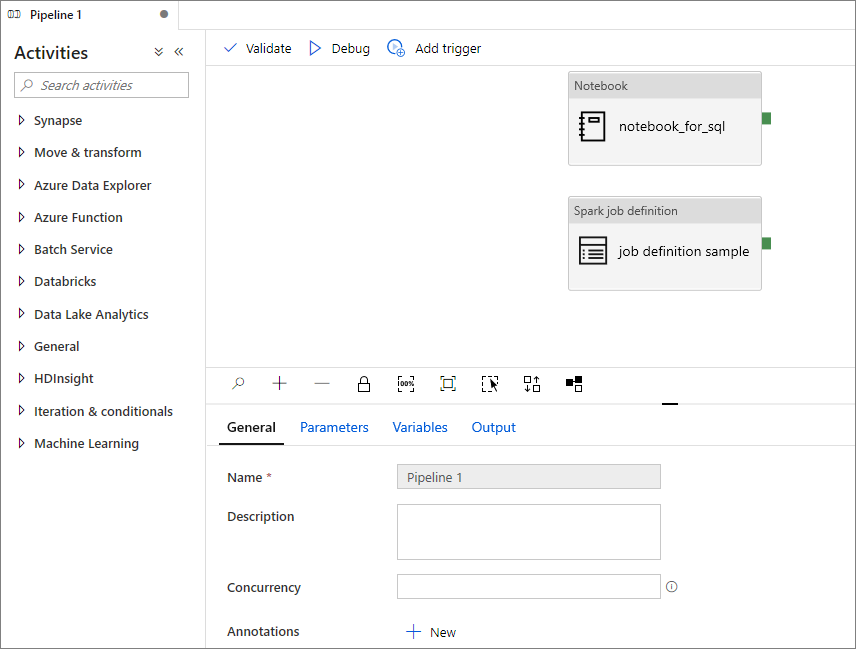
Lägga till en Apache Spark-jobbdefinition i pipeline
I det här avsnittet lägger du till en Apache Spark-jobbdefinition i pipelinen.
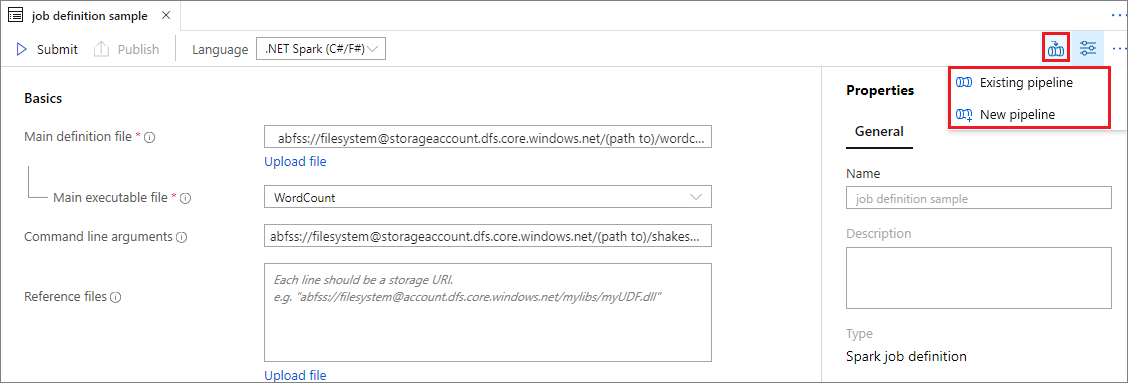
Öppna en befintlig Apache Spark-jobbdefinition.
Välj ikonen längst upp till höger i Apache Spark-jobbdefinitionen, välj Befintlig pipeline eller Ny pipeline. Mer information finns på sidan Pipeline.
Nästa steg
Sedan kan du använda Azure Synapse Studio för att skapa Power BI-datamängder och hantera Power BI-data. Gå vidare till artikeln Länka en Power BI-arbetsyta till en Synapse-arbetsyta om du vill veta mer.