Hantera paket med sessionsomfång
Förutom paket på poolnivå kan du även ange bibliotek med sessionsomfång i början av en notebook-session. Med bibliotek med sessionsomfång kan du ange och använda Python-, jar- och R-paket i en notebook-session.
När du använder bibliotek med sessionsomfång är det viktigt att ha följande i åtanke:
- När du installerar bibliotek med sessionsomfång har endast den aktuella notebook-filen åtkomst till de angivna biblioteken.
- De här biblioteken påverkar inte andra sessioner eller jobb som använder samma Spark-pool.
- De här biblioteken installeras ovanpå baskörnings- och poolnivåbiblioteken och har högsta prioritet.
- Bibliotek med sessionsomfång bevaras inte mellan sessioner.
Python-paket med sessionsomfång
Hantera Python-paket med sessionsomfång via filen environment.yml
Så här anger du Python-paket med sessionsomfattning:
- Gå till den valda Spark-poolen och kontrollera att du har aktiverat bibliotek på sessionsnivå. Du kan aktivera den här inställningen genom att gå till fliken Hantera>Apache Spark-poolpaket>.

- När inställningen gäller kan du öppna en notebook-fil och välja Konfigurera sessionspaket>.

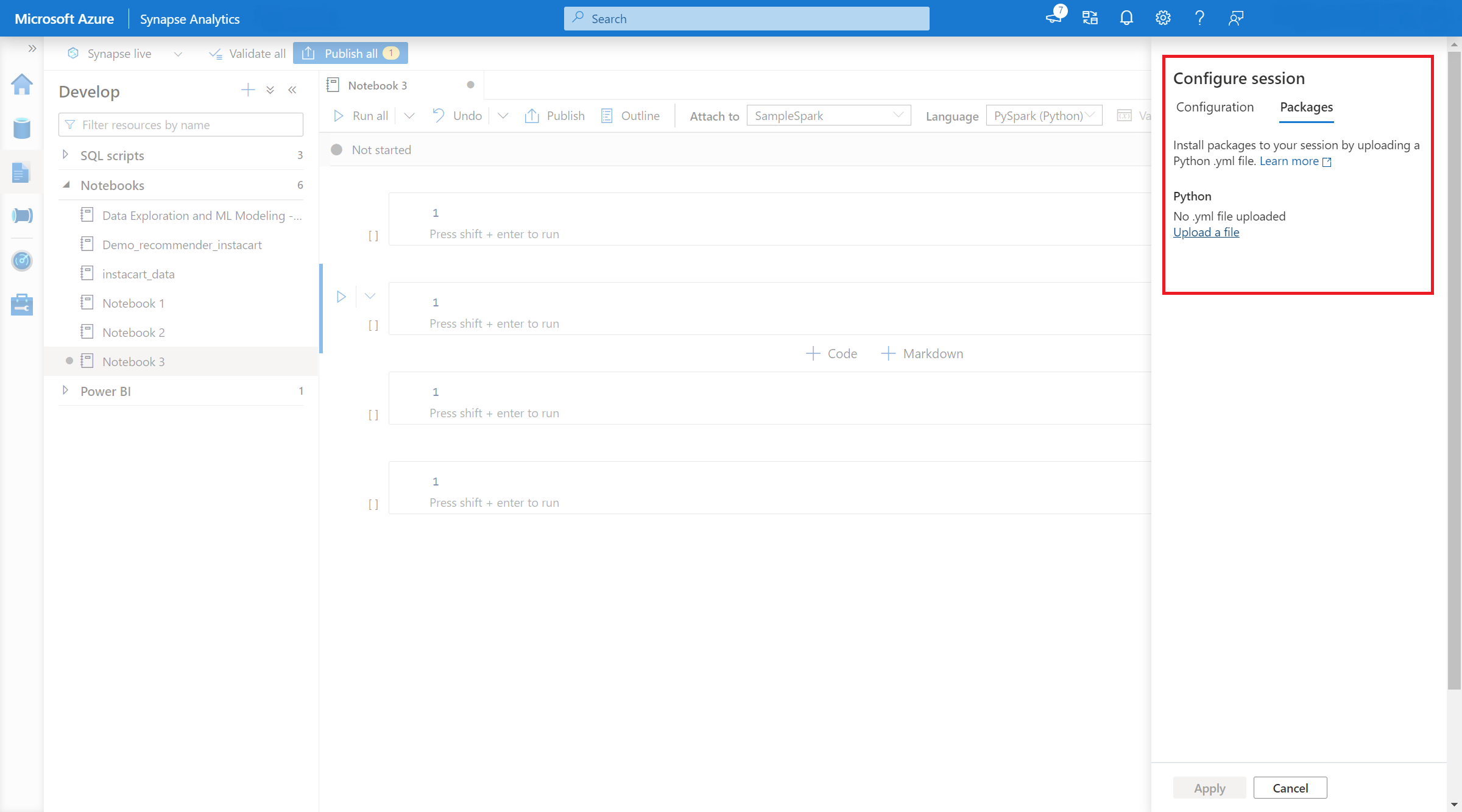
- Här kan du ladda upp en Conda environment.yml-fil för att installera eller uppgradera paket inom en session. De angivna biblioteken finns när sessionen startar. De här biblioteken kommer inte längre att vara tillgängliga när sessionen är slut.

Hantera Python-paket med sessionsomfång via kommandona %pip och %conda
Du kan använda de populära kommandona %pip och %conda för att installera ytterligare bibliotek från tredje part eller dina anpassade bibliotek under apache Spark-notebook-sessionen. I det här avsnittet använder vi %pip-kommandon för att demonstrera flera vanliga scenarier.
Anteckning
- Vi rekommenderar att du placerar kommandona %pip och %conda i den första cellen i anteckningsboken om du vill installera nya bibliotek. Python-tolken startas om efter att biblioteket på sessionsnivå har hanterats för att ändringarna ska börja gälla.
- Dessa kommandon för att hantera Python-bibliotek inaktiveras när du kör pipelinejobb. Om du vill installera ett paket i en pipeline måste du använda bibliotekshanteringsfunktionerna på poolnivå.
- Python-bibliotek med sessionsomfattning installeras automatiskt över både drivrutins- och arbetsnoderna.
- Följande %conda-kommandon stöds inte: skapa, rensa, jämföra, aktivera, inaktivera, köra, paketera.
- Du kan referera till %pip-kommandon och %conda-kommandon för den fullständiga listan över kommandon.
Installera ett paket från tredje part
Du kan enkelt installera ett Python-bibliotek från PyPI.
# Install vega_datasets
%pip install altair vega_datasets
Om du vill verifiera installationsresultatet kan du köra följande kod för att visualisera vega_datasets
# Create a scatter plot
# Plot Miles per gallon against the horsepower across different region
import altair as alt
from vega_datasets import data
cars = data.cars()
alt.Chart(cars).mark_point().encode(
x='Horsepower',
y='Miles_per_Gallon',
color='Origin',
).interactive()
Installera ett hjulpaket från lagringskontot
För att kunna installera biblioteket från lagringen måste du montera till ditt lagringskonto genom att köra följande kommandon.
from notebookutils import mssparkutils
mssparkutils.fs.mount(
"abfss://<<file system>>@<<storage account>.dfs.core.windows.net",
"/<<path to wheel file>>",
{"linkedService":"<<storage name>>"}
)
Sedan kan du använda installationskommandot %pip för att installera det nödvändiga hjulpaketet
%pip install /<<path to wheel file>>/<<wheel package name>>.whl
Installera en annan version av det inbyggda biblioteket
Du kan använda följande kommando för att se vad som är den inbyggda versionen av vissa paket. Vi använder Pandas som exempel
%pip show pandas
Resultatet är som följande logg:
Name: pandas
Version: **1.2.3**
Summary: Powerful data structures for data analysis, time series, and statistics
Home-page: https://pandas.pydata.org
... ...
Du kan använda följande kommando för att växla Pandas till en annan version, låt oss säga 1.2.4
%pip install pandas==1.2.4
Avinstallera ett bibliotek med sessionsomfattning
Om du vill avinstallera ett paket som är installerat på den här notebook-sessionen kan du läsa följande kommandon. Du kan dock inte avinstallera de inbyggda paketen.
%pip uninstall altair vega_datasets --yes
Använda kommandot %pip för att installera bibliotek från en requirement.txt fil
%pip install -r /<<path to requirement file>>/requirements.txt
Java- eller Scala-paket med sessionsomfång
Om du vill ange Java- eller Scala-paket med sessionsomfång kan du använda alternativet %%configure :
%%configure -f
{
"conf": {
"spark.jars": "abfss://<<file system>>@<<storage account>.dfs.core.windows.net/<<path to JAR file>>",
}
}
Anteckning
- Vi rekommenderar att du kör %%configure i början av anteckningsboken. I det här dokumentet finns en fullständig lista över giltiga parametrar.
R-paket med sessionsomfång (förhandsversion)
Azure Synapse Analytics-pooler innehåller många populära R-bibliotek direkt. Du kan också installera extra bibliotek från tredje part under apache Spark-notebook-sessionen.
Anteckning
- Dessa kommandon för att hantera R-bibliotek inaktiveras när du kör pipelinejobb. Om du vill installera ett paket i en pipeline måste du använda bibliotekshanteringsfunktionerna på poolnivå.
- R-bibliotek med sessionsomfång installeras automatiskt över både drivrutins- och arbetsnoderna.
Installera ett paket
Du kan enkelt installera ett R-bibliotek från CRAN.
# Install a package from CRAN
install.packages(c("nycflights13", "Lahman"))
Du kan också använda CRAN-ögonblicksbilder som lagringsplats för att ladda ned samma paketversion varje gång.
install.packages("highcharter", repos = "https://cran.microsoft.com/snapshot/2021-07-16/")
Använda devtools för att installera paket
Biblioteket devtools förenklar paketutvecklingen för att påskynda vanliga uppgifter. Det här biblioteket installeras i standardkörningen Azure Synapse Analytics.
Du kan använda devtools för att ange en specifik version av ett bibliotek som ska installeras. Dessa bibliotek installeras på alla noder i klustret.
# Install a specific version.
install_version("caesar", version = "1.0.0")
På samma sätt kan du installera ett bibliotek direkt från GitHub.
# Install a GitHub library.
install_github("jtilly/matchingR")
För närvarande stöds följande devtools funktioner i Azure Synapse Analytics:
| Kommando | Beskrivning |
|---|---|
| install_github() | Installerar ett R-paket från GitHub |
| install_gitlab() | Installerar ett R-paket från GitLab |
| install_bitbucket() | Installerar ett R-paket från BitBucket |
| install_url() | Installerar ett R-paket från en godtycklig URL |
| install_git() | Installerar från en godtycklig git-lagringsplats |
| install_local() | Installerar från en lokal fil på disk |
| install_version() | Installerar från en specifik version på CRAN |
Visa installerade bibliotek
Du kan köra frågor mot alla bibliotek som är installerade i sessionen med hjälp av library kommandot .
library()
Du kan använda packageVersion funktionen för att kontrollera versionen av biblioteket:
packageVersion("caesar")
Ta bort ett R-paket från en session
Du kan använda funktionen detach för att ta bort ett bibliotek från namnområdet. De här biblioteken finns kvar på disken tills de läses in igen.
# detach a library
detach("package: caesar")
Om du vill ta bort ett paket med sessionsomfång från en notebook-fil använder du remove.packages() kommandot . Den här biblioteksändringen påverkar inte andra sessioner i samma kluster. Användare kan inte avinstallera eller ta bort inbyggda bibliotek för standardkörningen Azure Synapse Analytics.
remove.packages("caesar")
Anteckning
Du kan inte ta bort kärnpaket som SparkR, SparklyR eller R.
R-bibliotek med sessionsomfång och SparkR
Bibliotek med notebook-omfång är tillgängliga på SparkR-arbetare.
install.packages("stringr")
library(SparkR)
str_length_function <- function(x) {
library(stringr)
str_length(x)
}
docs <- c("Wow, I really like the new light sabers!",
"That book was excellent.",
"R is a fantastic language.",
"The service in this restaurant was miserable.",
"This is neither positive or negative.")
spark.lapply(docs, str_length_function)
R-bibliotek med sessionsomfång och SparklyR
Med spark_apply() i SparklyR kan du använda valfritt R-paket i Spark. I sparklyr::spark_apply() anges som standard argumentet packages till FALSE. Detta kopierar bibliotek i aktuella libPaths till arbetarna, så att du kan importera och använda dem på arbetare. Du kan till exempel köra följande för att generera ett caesarkrypterat meddelande med sparklyr::spark_apply():
install.packages("caesar", repos = "https://cran.microsoft.com/snapshot/2021-07-16/")
spark_version <- "3.2"
config <- spark_config()
sc <- spark_connect(master = "yarn", version = spark_version, spark_home = "/opt/spark", config = config)
apply_cases <- function(x) {
library(caesar)
caesar("hello world")
}
sdf_len(sc, 5) %>%
spark_apply(apply_cases, packages=FALSE)
Nästa steg
- Visa standardbiblioteken: Stöd för Apache Spark-version
- Hantera paketen utanför Synapse Studio-portalen: Hantera paket via Az-kommandon och REST-API:er