Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Tip
Microsoft Fabric Data Warehouse är ett relationslager i företagsskala på en datasjögrund med en framtidsklar arkitektur, inbyggd AI och nya funktioner. Om du är nybörjare på datalager börjar du med Fabric Data Warehouse. Befintliga dedicerade SQL-poolarbetsbelastningar kan uppgraderas till Fabric för att få åtkomst till nya funktioner inom datavetenskap, realtidsanalys och rapportering.
Azure Synapse Analytics är en analystjänst som samlar företagsdatalager och stordataanalys. Det ger dig friheten att fråga efter data på dina villkor.
Kommentar
Mer information om Azure Synapse Analytics finns i den här videon som förklarar förbättringar av dataflytt.
Komponenter i Synapse SQL-arkitektur
Dedikerad SQL-pool (tidigare SQL DW) använder en utskalningsarkitektur för att distribuera beräkningsbearbetning av data över flera noder. Skalningsenheten är en abstraktion av beräkningskraften som kallas för en informationslagerenhet. Beräkningen är separat från lagringen, vilket gör att du kan skala beräkningarna oberoende av dina data i systemet.
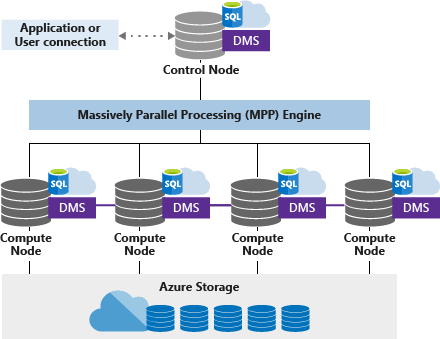
En dedikerad SQL-pool (tidigare SQL DW) använder en nodbaserad arkitektur. Program ansluter och utfärdar T-SQL-kommandon till en kontrollnod. Kontrollnoden är värd för den distribuerade frågemotorn, som optimerar frågor för parallell bearbetning och sedan skickar åtgärder till Beräkningsnoder för att utföra sitt arbete parallellt.
Beräkningsnoderna lagrar alla användardata i Azure Storage och kör de parallella frågorna. Data Movement Service (DMS) är en intern tjänst på systemnivå som flyttar data mellan noder efter behov för att köra frågor parallellt och returnera korrekta resultat.
Med frikopplad lagring och beräkning kan man när man använder en dedikerad SQL-pool (tidigare SQL DW):
- Storleksanpassa beräkningskraften oberoende av lagringsbehoven.
- Öka eller minska beräkningskraften i en dedikerad SQL-pool (tidigare SQL DW) utan att flytta data.
- Pausa beräkningskapaciteten och lämna data intakta, så att du bara betalar för lagring.
- Återuppta beräkningskapacitet under driftstimmar.
Azure Storage
Dedikerad SQL-pool SQL (tidigare SQL DW) använder Azure Storage för att skydda dina användardata. Eftersom dina data lagras och hanteras av Azure Storage finns det en separat avgift för din lagringsförbrukning. Data delas in i distributioner för att optimera systemets prestanda. Du kan välja vilket mönster för horisontell partitionering som ska användas för att distribuera data när du definierar tabellen. Dessa shardingmönster stöds:
- Hashfunktion
- Rundtur
- Duplicera
Kontrollnoden
Kontrollnoden är hjärnan i arkitekturen. Det är frontänden som interagerar med alla program och anslutningar. Den distribuerade frågemotorn körs på kontrollnoden för att optimera och samordna parallella frågor. När du skickar en T-SQL-fråga omvandlar kontrollnoden den till frågor som körs parallellt mot varje distribution.
Beräkningsnoder
Beräkningsnoderna utgör själva beräkningskraften. Distributioner mappas till beräkningsnoder för bearbetning. När du betalar för fler beräkningsresurser mappas distributionerna om till tillgängliga beräkningsnoder. Antalet beräkningsnoder varierar från 1 till 60 och bestäms av tjänstnivån för Synapse SQL.
Varje beräkningsnod har ett nod-ID som visas i systemvyer. Du kan se beräkningsnod-ID:t genom att leta efter kolumnen node_id i systemvyer vars namn börjar med sys.pdw_nodes. En lista över dessa systemvyer finns i Synapse SQL-systemvyer.
Tjänst för datarörelse
Data Movement Service (DMS) är datatransporttekniken som samordnar dataflytten mellan beräkningsnoderna. Vissa frågor kräver dataflytt för att säkerställa att parallella frågor returnerar korrekta resultat. När dataflytt krävs ser DMS till att rätt data kommer till rätt plats.
Distributioner
En distribution är den grundläggande lagringsenheten för parallella frågor som körs på distribuerade data. När Synapse SQL kör en fråga delas arbetet upp i 60 mindre frågor som körs parallellt.
Var och en av de 60 mindre frågorna körs på en av datadistributionerna. Varje beräkningsnod hanterar en eller flera av de 60 distributionerna. En dedikerad SQL-pool (tidigare SQL DW) med maximala beräkningsresurser har en distribution per beräkningsnod. En dedikerad SQL-pool (tidigare SQL DW) med minsta möjliga beräkningsresurser har alla distributioner på en beräkningsnod.
Kommentar
Rekommendationer om den bästa tabelldistributionsstrategin som ska användas baserat på dina arbetsbelastningar finns i Azure Synapse SQL Distribution Advisor.
Hash-distribuerade tabeller
En hash-distribuerad tabell kan leverera högsta frågeprestanda för kopplingar och aggregeringar för stora tabeller.
För att fragmentera data till en hash-distribuerad tabell används en hash-funktion för att deterministiskt tilldela varje rad till en distribution. I tabelldefinitionen utses en av kolumnerna till distributionskolumnen. Hash-funktionen använder värdena i distributionskolumnen för att tilldela varje rad till en distribution.
Följande diagram visar hur en fullständig (icke-distribuerad tabell) lagras som en hash-distribuerad tabell.

- Varje rad tillhör en distribution.
- En deterministisk hash-algoritm tilldelar varje rad till en distribution.
- Antalet tabellrader per distribution varierar beroende på tabellernas olika storlekar.
Det finns prestandaöverväganden för valet av en distributionskolumn, till exempel distinkthet, datasnedvridning och de typer av frågor som körs i systemet.
Round-robin-distribuerade tabeller
En resursallokeringstabell är den enklaste tabellen för att skapa och leverera snabba prestanda när den används som mellanlagringstabell för belastningar.
En round-robin-distribuerad tabell fördelar data jämnt över tabellen men utan någon ytterligare optimering. En fördelning väljs först slumpmässigt och sedan tilldelas buffertar av rader till distributioner sekventiellt. Det går snabbt att läsa in data i en resursallokeringstabell men frågeprestanda kan ofta vara bättre med hash-distribuerade tabeller. Kopplingar på rundgångstabeller kräver omfördelning av data, vilket tar ytterligare tid.
Replikerade tabeller
En replikerad tabell ger snabbaste frågeprestanda för små tabeller.
En tabell som replikeras cachelagrar en fullständig kopia av tabellen på varje beräkningsnod. Därför behöver du, när du replikerar en tabell, inte överföra data till beräkningsnoder innan en koppling eller aggregering. Replikerade tabeller används bäst med små tabeller. Extra lagringsutrymme krävs och det finns ytterligare kostnader som uppstår vid skrivning av data, vilket gör stora tabeller opraktiska.
Diagrammet nedan visar en replikerad tabell som cachelagras på den första distributionen på varje beräkningsnod.

Relaterat innehåll
Nu när du vet lite om Azure Synapse lär du dig hur du snabbt skapar en dedikerad SQL-pool (tidigare SQL DW) och läser in exempeldata. Om du är nybörjare på Azure kanske du tycker att de grundläggande Begreppen i Azure är användbara när du stöter på ny terminologi. Eller titta på några av dessa andra Azure Synapse-resurser.
- Kundernas framgångsberättelser
- Bloggar
- Önskemål om funktioner
- Videor
- Skapa ett supportärende
Microsoft Q&A-frågesida - Stack Overflow-forum
- X