Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Tip
Microsoft Fabric Data Warehouse är ett relationslager i företagsskala på en datasjögrund med en framtidsklar arkitektur, inbyggd AI och nya funktioner. Om du är nybörjare på datalager börjar du med Fabric Data Warehouse. Befintliga dedicerade SQL-poolarbetsbelastningar kan uppgraderas till Fabric för att få åtkomst till nya funktioner inom datavetenskap, realtidsanalys och rapportering.
Den här artikeln beskriver hur du kan beräkna och hantera kostnader för serverlös SQL-pool i Azure Synapse Analytics:
- Beräkna mängden data som bearbetas innan du skickar en fråga
- Använd funktionen kostnadskontroll för att ange budgeten
Förstå att kostnaderna för serverlös SQL-pool i Azure Synapse Analytics bara är en del av de månatliga kostnaderna i din Azure-faktura. Om du använder andra Azure-tjänster debiteras du för alla Azure-tjänster och resurser som används i din Azure-prenumeration, inklusive tjänsterna från tredje part. Den här artikeln beskriver hur du planerar för och hanterar kostnader för serverlös SQL-pool i Azure Synapse Analytics.
Data som bearbetas
Data som bearbetas är mängden data som systemet tillfälligt lagrar när en fråga körs. Data som bearbetas består av följande kvantiteter:
- Mängden data som lästs från lagringen. Det här beloppet omfattar:
- Data läses under dataläsning.
- Data lästes när man läste metadata (för filformat som innehåller metadata, till exempel Parquet).
- Mängden data i mellanliggande resultat. Dessa data överförs mellan noder medan frågan körs. Den innehåller dataöverföringen till slutpunkten i ett okomprimerat format.
- Mängd data som skrivits till lagring. Om du använder CETAS för att exportera resultatuppsättningen till lagring läggs mängden utskrivna data till i mängden data som bearbetas för SELECT-delen av CETAS.
Läsning av filer från lagring är mycket optimerad. Processen använder:
- Prefetching, vilket kan lägga till en viss belastning på mängden data som läses. Om en fråga läser en hel fil finns det inga omkostnader. Om en fil läses delvis, till exempel i TOP N-frågor, läses lite mer data med hjälp av prefetching.
- En optimerad csv-parser (kommaavgränsat värde). Om du använder PARSER_VERSION='2.0' för att läsa CSV-filer ökar mängden data som läss från lagringen något. En optimerad CSV-parser läser filer parallellt, i segment med samma storlek. Bitar innehåller inte nödvändigtvis hela rader. För att säkerställa att alla rader parsas läser den optimerade CSV-parsern även små fragment av intilliggande segment. Den här processen lägger till en liten mängd omkostnader.
Statistik
Frågeoptimeraren för serverlös SQL-pool förlitar sig på statistik för att generera optimala frågekörningsplaner. Du kan skapa statistik manuellt. Annars skapar serverlös SQL-pool dem automatiskt. Hur som helst skapas statistik genom att köra en separat fråga som returnerar en specifik kolumn med en angiven exempelfrekvens. Den här frågan har en associerad mängd bearbetad data.
Om du kör samma eller någon annan fråga som skulle dra nytta av den skapade statistiken återanvänds statistik om möjligt. Det finns inga ytterligare data som bearbetas för att skapa statistik.
När statistik skapas för en Parquet-kolumn läss endast relevant kolumn från filer. När statistik skapas för en CSV-kolumn läss och parsas hela filer.
Avrundning
Mängden data som bearbetas avrundas upp till närmaste MB per fråga. Varje fråga har minst 10 MB data bearbetade.
Vilka data som bearbetas inkluderar inte
- Metadata på servernivå (till exempel inloggningar, roller och autentiseringsuppgifter på servernivå).
- Databaser som du skapar i slutpunkten. Dessa databaser innehåller endast metadata (till exempel användare, roller, scheman, vyer, infogade tabellvärdesfunktioner [TVF:er], lagrade procedurer, databasomfattande autentiseringsuppgifter, externa datakällor, externa filformat och externa tabeller).
- Om du använder schemainferens läss filfragment för att härleda kolumnnamn och datatyper, och mängden dataläsning läggs till i mängden data som bearbetas.
- Instruktioner för datadefinitionsspråk (DDL), förutom instruktionen CREATE STATISTICS eftersom den bearbetar data från lagring baserat på den angivna exempelprocenten.
- Frågor som endast gäller metadata.
Minska mängden data som bearbetas
Du kan optimera mängden data per fråga som bearbetas och förbättra prestanda genom att partitionera och konvertera dina data till ett komprimerat kolumnbaserat format som Parquet.
Exempel
Tänk dig tre tabeller.
- Tabellen population_csv backas upp av 5 TB CSV-filer. Filerna är ordnade i fem kolumner med samma storlek.
- Tabellen population_parquet har samma data som tabellen population_csv. Den backas upp av 1 TB Parquet-filer. Den här tabellen är mindre än den tidigare eftersom data komprimeras i Parquet-format.
- Tabellen very_small_csv backas upp av 100 KB CSV-filer.
Fråga 1: VÄLJ SUM(population) FRÅN population_csv
Den här frågan läser och parsar hela filer för att hämta värden för populationskolumnen. Noder bearbetar fragment i den här tabellen och populationssumman för varje fragment överförs mellan noder. Den slutliga summan överförs till slutpunkten.
Den här sökfrågan bearbetar 5 TB data plus en liten mängd överhead för överföring av fragmentens summor.
Fråga 2: VÄLJ SUM(population) FRÅN population_parquet
När du kör frågor mot komprimerade och kolumnbaserade format som Parquet läss mindre data än i fråga 1. Du ser det här resultatet eftersom en serverlös SQL-pool läser en enda komprimerad kolumn i stället för hela filen. I det här fallet läses 0,2 TB. (Fem lika stora kolumner är 0,2 TB vardera.) Noder bearbetar fragment i den här tabellen och populationssumman för varje fragment överförs mellan noder. Den slutliga summan överförs till slutpunkten.
Den här frågan bearbetar 0,2 TB plus en liten mängd omkostnader för överföring av summor av fragment.
Fråga 3: VÄLJ * FRÅN population_parquet
Den här frågan läser alla kolumner och överför alla data i ett okomprimerat format. Om komprimeringsformatet är 5:1 bearbetar frågan 6 TB eftersom det läser 1 TB och överför 5 TB okomprimerade data.
Fråga 4: VÄLJ ANTAL(*) FRÅN very_small_csv
Den här sökfrågan läser hela filer. Den totala storleken på filer i lagringen för den här tabellen är 100 KB. Noder bearbetar fragment i den här tabellen och summan för varje fragment överförs mellan noder. Den slutliga summan överförs till slutpunkten.
Den här frågan bearbetar drygt 100 KB data. Mängden data som bearbetas för den här frågan avrundas upp till 10 MB enligt beskrivningen i avrundningsavsnittet i den här artikeln.
Kostnadskontroll
Med funktionen Kostnadskontroll i en serverlös SQL-pool kan du ange budgeten för mängden data som bearbetas. Du kan ange budgeten i TB för data som bearbetas för en dag, vecka och månad. Samtidigt kan du ha en eller flera budgetar angivna. Om du vill konfigurera kostnadskontroll för serverlös SQL-pool kan du använda Synapse Studio eller T-SQL.
Konfigurera kostnadskontroll för serverlös SQL-pool i Synapse Studio
Om du vill konfigurera kostnadskontroll för serverlös SQL-pool i Synapse Studio navigerar du till Hantera objekt i menyn till vänster än att välja SQL-poolobjekt under Analyspooler. När du hovra över en serverlös SQL-pool ser du en ikon för kostnadskontroll – klicka på den här ikonen.
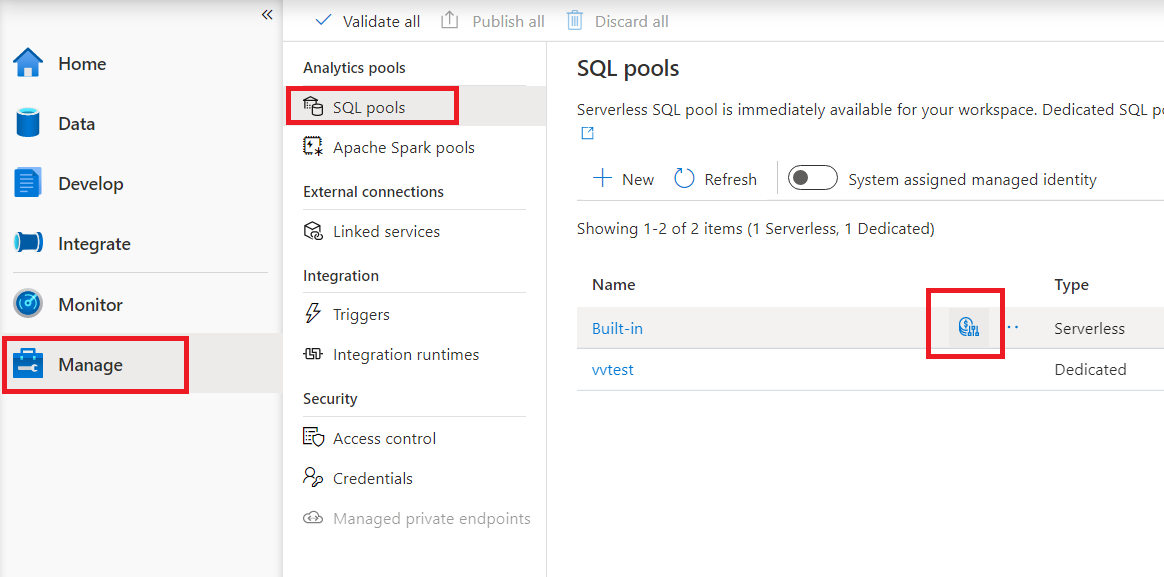
När du klickar på kostnadskontrollikonen visas ett sidofält:
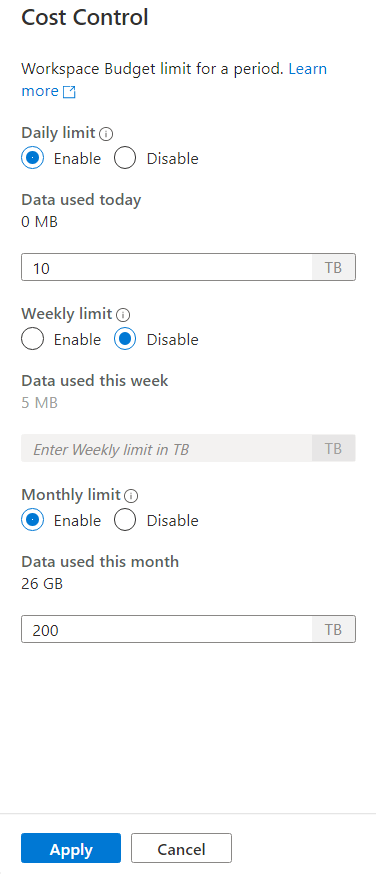
Om du vill ange en eller flera budgetar, klickar du först på radioknappen Aktivera för en budget som du vill ange, sedan anger du heltalsvärdet i textrutan. Enheten för värdet är TBs. När du har konfigurerat de budgetar som du vill använda klickar du på knappen Tillämpa längst ned i sidofältet. Nu är din budget klar.
Konfigurera kostnadskontroll för serverlös SQL-pool i T-SQL
För att konfigurera kostnadskontroll för serverlös SQL-pool i T-SQL måste du köra en eller flera av följande lagrade procedurer.
sp_set_data_processed_limit
@type = N'daily',
@limit_tb = 1
sp_set_data_processed_limit
@type= N'weekly',
@limit_tb = 2
sp_set_data_processed_limit
@type= N'monthly',
@limit_tb = 3334
Om du vill se den aktuella konfigurationen kör du följande T-SQL-instruktion:
SELECT * FROM sys.configurations
WHERE name like 'Data processed %';
Om du vill se hur mycket data som bearbetades under den aktuella dagen, veckan eller månaden kör du följande T-SQL-instruktion:
SELECT * FROM sys.dm_external_data_processed
Överskrider de gränser som definierats i kostnadskontrollen
Om någon gräns överskrids under databaskörningen avslutas inte frågan.
När gränsen överskrids avvisas den nya frågan med felmeddelandet som innehåller information om perioden, definierad gräns för perioden och data som bearbetas för den perioden. Om till exempel en ny fråga körs, där veckogränsen är inställd på 1 TB och den har överskridits, visas felmeddelandet:
Query is rejected because SQL Serverless budget limit for a period is exceeded. (Period = Weekly: Limit = 1 TB, Data processed = 1 TB))
Nästa steg
Information om hur du optimerar dina frågor för prestanda finns i Metodtips för serverlös SQL-pool.