Project Flash – Använda Azure Resource Graph för att övervaka tillgängligheten för virtuella Azure-datorer
Azure Resource Graph är en lösning som erbjuds av Flash. Flash är det interna namnet på ett projekt som är avsett för att skapa en robust, tillförlitlig och snabb mekanism för kunder att övervaka den virtuella datorns hälsotillstånd.
Den här artikeln beskriver användningen av Azure Resource Graph för att övervaka tillgängligheten för virtuella Azure-datorer. En allmän översikt över Flash-lösningar finns i Översikt över Flash.
För dokumentation som är specifik för de andra lösningarna som erbjuds av Flash kan du välja mellan följande artiklar:
- Använda Event Grid-systemavsnitt för att övervaka tillgängligheten för virtuella Azure-datorer
- Använda Azure Monitor för att övervaka tillgängligheten för virtuella Azure-datorer
- Använda Azure Resource Health för att övervaka tillgängligheten för virtuella Azure-datorer
Azure Resource Graph – HealthResources
Den här funktionen är för närvarande allmänt tillgänglig. Det är användbart för att utföra storskaliga undersökningar. Det erbjuder en mycket användarvänlig upplevelse för informationshämtning med dess användning av Kusto-frågespråk (KQL). Det kan också fungera som en central hubb för resursinformation och möjliggör enkel hämtning av historiska data.
Förutom redan flödande vm-tillgänglighetstillstånd publicerade vi vm-tillgänglighetsanteckningar till Azure Resource Graph (ARG) för detaljerad felattribution och stilleståndstidsanalys, tillsammans med att aktivera en 14-dagars ändringsspårningsmekanism för att spåra historiska ändringar i VM-tillgänglighet för snabb felsökning. Med dessa nya tillägg är vi glada över att kunna meddela allmän tillgänglighet för information om vm-tillgänglighet i datauppsättningen HealthResources i ARG! Med det här erbjudandet kan användarna:
- Fråga effektivt den senaste ögonblicksbilden av vm-tillgängligheten i alla Azure-prenumerationer samtidigt och vid låga svarstider för regelbunden och fleetwide-övervakning.
- Utvärdera effekten på fleetwide business SLA och utlös snabbt avgörande åtgärdsåtgärder som svar på störningar och typ av signatur för fel.
- Konfigurera anpassade instrumentpaneler för att övervaka programmets omfattande hälsotillstånd genom att koppla information om VM-tillgänglighet med resursmetadata som finns i ARG.
- Spåra relevanta ändringar i vm-tillgängligheten under ett rullande 14-dagarsfönster med hjälp av mekanismen för ändringsspårning för att utföra detaljerade undersökningar.
Exempelfrågor
- Azure Resource Graph-exempelfrågor för Azure Service Health – Azure Service Health | Microsoft Learn
- Information om vm-tillgänglighet i Azure Resource Graph – Virtuella Azure-datorer | Microsoft Learn
- Lista över Exempel på Azure Resource Graph-frågor efter tabell – Azure Resource Graph | Microsoft Learn
Kom igång
Användare kan fråga ARG via PowerShell, REST API, Azure CLI eller till och med Azure-portalen. Följande steg beskriver hur data kan nås från Azure-portalen.
När du är på Azure-portalen går du till Resource Graph Explorer.
Välj fliken Tabell och (enkel) klicka på tabellen HealthResources för att hämta den senaste ögonblicksbilden av information om VM-tillgänglighet (tillgänglighetstillstånd och hälsoanteckningar).
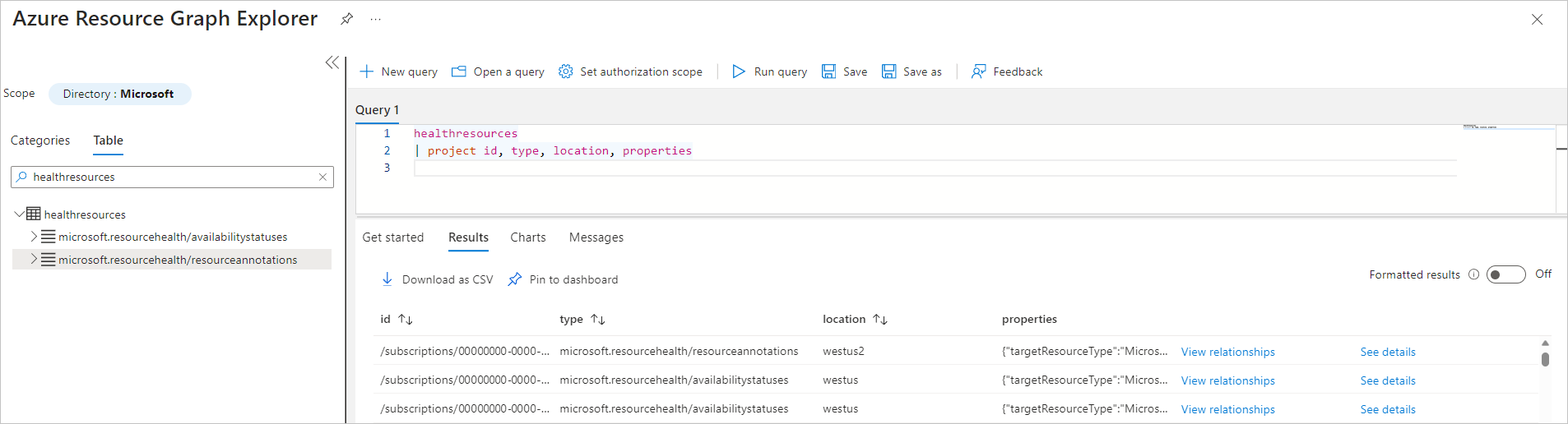


Det finns två typer av händelser i tabellen HealthResources:

- resourcehealth/availabilitystatuses
Den här händelsen anger den senaste tillgänglighetsstatusen för en virtuell dator baserat på hälsokontroller som utförs av den underliggande Azure-plattformen. De tillgänglighetstillstånd som vi för närvarande genererar för virtuella datorer är:
- Tillgänglig: Den virtuella datorn är igång som förväntat.
- Ej tillgänglig: Vi har identifierat störningar i den virtuella datorns normala funktion och därför körs inte programmen som förväntat.
- Okänd: Plattformen kan inte korrekt identifiera hälsotillståndet för den virtuella datorn. Användare kan vanligtvis checka tillbaka om några minuter för ett uppdaterat tillstånd.
Om du vill avsöka det senaste tillgänglighetstillståndet för virtuella datorer läser du egenskapsfältet som innehåller följande information:
Exempel
{
"targetResourceType": "Microsoft.Compute/virtualMachines",
"previousAvailabilityState": "Available",
"targetResourceId": "/subscriptions//resourceGroups//providers/Microsoft.Compute/virtualMachines/",
"occurredTime": "2022-10-11T11:13:59.9570000Z",
"availabilityState": "Unavailable"
}
Egenskapsbeskrivning
| Property | Beskrivning | Motsvarande resurshälsokategori (RHC) |
|---|---|---|
| targetResourceType | Typ av resurs som hälsodata flödar för | resourceType |
| targetResourceId | Resurs-ID | resourceId |
| occurredTime | Tidsstämpel när plattformen genererar det senaste tillgänglighetstillståndet | eventTimestamp |
| previousAvailabilityState | Tidigare tillgänglighetstillstånd för den virtuella datorn | previousHealthStatus |
| availabilityState | Aktuellt tillgänglighetstillstånd för den virtuella datorn | currentHealthStatus |
Se avsnittet HealthResources i dokumentationen för exempelfrågor för en lista över startfrågor för att utforska dessa data ytterligare.
- resourcehealth/resourceannotations (NYLIGEN TILLAGDA)
Den här händelsen kontextualiserar eventuella ändringar av vm-tillgängligheten genom att ange nödvändiga felattribut som hjälper användarna att undersöka och minimera störningarna efter behov. Se den fullständiga listan över vm-tillgänglighetsanteckningar som genereras av plattformen. Dessa anteckningar kan i stort sett klassificeras i tre bucketar:
- Nedtidsanteckningar: Dessa anteckningar genereras när plattformen identifierar att vm-tillgängligheten övergår till otillgänglig. (Till exempel under oväntade värdkrascher, omstartsreparationer).
- Informationsanteckningar: Dessa anteckningar genereras under kontrollplansaktiviteter utan påverkan på den virtuella datorns tillgänglighet. (Till exempel VM-allokering/Stopp/Ta bort/Starta). Vanligtvis krävs ingen ytterligare kundåtgärd som svar.
- Degraderade anteckningar: Dessa anteckningar genereras när vm-tillgängligheten identifieras vara i fara. (Till exempel när felförutsägelsemodeller förutsäger en degraderad maskinvarukomponent som kan orsaka att den virtuella datorn startas om vid en viss tidpunkt). Vi uppmanar starkt användarna att omdistribuera efter den tidsgräns som anges i anteckningsmeddelandet för att undvika oväntade dataförluster eller avbrott. Du kan få en avisering i Azures vm-skalningsuppsättningar Resource Health eller aktivitetsloggen i något av följande scenarier:
- Virtuella datorer i skalningsuppsättningarna för virtuella Azure-datorer håller på att stoppas, frigöras, tas bort eller startas.
- Du utförde in- eller utskalningsåtgärder på vm-skalningsuppsättningarna.
- Aviseringen anger att den aggregerade plattformshälsan för vm-skalningsuppsättningarna är i ett tillfälligt tillstånd av "Degraderad".
Om du vill avsöka de associerade VM-tillgänglighetsanteckningarna för en resurs läser du fältet egenskaper, som innehåller följande information:
Exempel
{
"targetResourceType": "Microsoft.Compute/virtualMachines", "targetResourceId": "/subscriptions//resourceGroups//providers/Microsoft.Compute/virtualMachines/",
"annotationName": "VirtualMachineHostRebootedForRepair",
"occurredTime": "2022-09-25T20:21:37.5280000Z",
"category": "Unplanned",
"summary": "We're sorry, your virtual machine isn't available because an unexpected failure on the host server. Azure has begun the auto-recovery process and is currently rebooting the host server. No further action is required from you at this time. The virtual machine will be back online after the reboot completes.",
"context": "Platform Initiated",
"reason": "Unexpected host failure"
}
Egenskapsbeskrivning
| Property | Beskrivning | Motsvarande RHC |
|---|---|---|
| targetResourceType | Typ av resurs som hälsodata flödar för | resourceType |
| targetResourceId | Resurs-ID | resourceId |
| occurredTime | Tidsstämpel när det senaste tillgänglighetstillståndet genereras av plattformen | eventTimestamp |
| annotationName | Namnet på anteckningen som genereras | eventName |
| orsak | Kort översikt över tillgänglighetspåverkan som observerats av kunden | rubrik |
| category | Anger om plattformsaktiviteten som utlöste anteckningen antingen var planerat underhåll eller oplanerad reparation. Det här fältet gäller inte för kund-/VM-initierade händelser. Möjliga värden: Planerad, oplanerad, Ej tillämplig, Null | category |
| sammanhang | Anger om aktiviteten som utlöste anteckningen berodde på en auktoriserad användare eller process (kundinitierad), Azure-plattformen (plattformsinitierad) eller aktiviteten i gästoperativsystemet som resulterade i tillgänglighetspåverkan (VM-initierad). Möjliga värden: Plattformsinitierad, användarinitierad, VM-initierad, Ej tillämplig, Null | sammanhang |
| Sammanfattning | Instruktion som beskriver orsaken till anteckningsutsläpp, tillsammans med reparationssteg som användarna kan vidta | Sammanfattning |
Se avsnittet HealthResources i dokumentationen för exempelfrågor för en lista över startfrågor för att utforska dessa data ytterligare.
Vi har flera förbättringar planerade för anteckningsmetadata som visas i datauppsättningen HealthResources. Dessa berikanden ger användarna tillgång till mer omfattande felattribut för att på ett avgörande sätt förbereda ett svar på ett avbrott. Parallellt vill vi utöka varaktigheten för historiska återblickar till minst 30 dagar så att användarna kan spåra tidigare ändringar i vm-tillgängligheten på ett omfattande sätt.
Nästa steg
Om du vill veta mer om de lösningar som erbjuds går du vidare till motsvarande lösningsartikel:
- Använda Event Grid-systemavsnitt för att övervaka tillgängligheten för virtuella Azure-datorer
- Använda Azure Monitor för att övervaka tillgängligheten för virtuella Azure-datorer
- Använda Azure Resource Health för att övervaka tillgängligheten för virtuella Azure-datorer
En allmän översikt över hur du övervakar virtuella Azure-datorer finns i Övervaka virtuella Azure-datorer och referensen Övervaka virtuella Azure-datorer.