Storlekar på virtuella datorer i HBv2-serien
Gäller för: ✔️ Virtuella Linux-datorer ✔️ med virtuella Windows-datorer ✔️ – flexibla skalningsuppsättningar ✔️ Enhetliga skalningsuppsättningar
Flera prestandatester har körts på virtuella datorer i HBv2-seriens storlek. Följande är några av resultaten av den här prestandatestningen.
| Arbetsbelastning | HBv2 |
|---|---|
| STREAM Triad | 350 GB/s (21–23 GB/s per CCX) |
| Högpresterande Linpack (HPL) | 4 TeraFLOPS (Rpeak, FP64), 8 TeraFLOPS (Rmax, FP32) |
| RDMA-svarstid och bandbredd | 1,2 mikrosekunder, 190 Gb/s |
| FIO på lokal NVMe SSD | 2,7 GB/s läsningar, 1,1 GB/s skrivningar; 102k IOPS-läsningar, 115 IOPS-skrivningar |
| IOR på 8 * Azure Premium SSD (P40 Managed Disks, RAID0)** | 1,3 GB/s läsningar, 2,5 GB/skrivningar; 101k IOPS-läsningar, 105 000 IOPS-skrivningar |
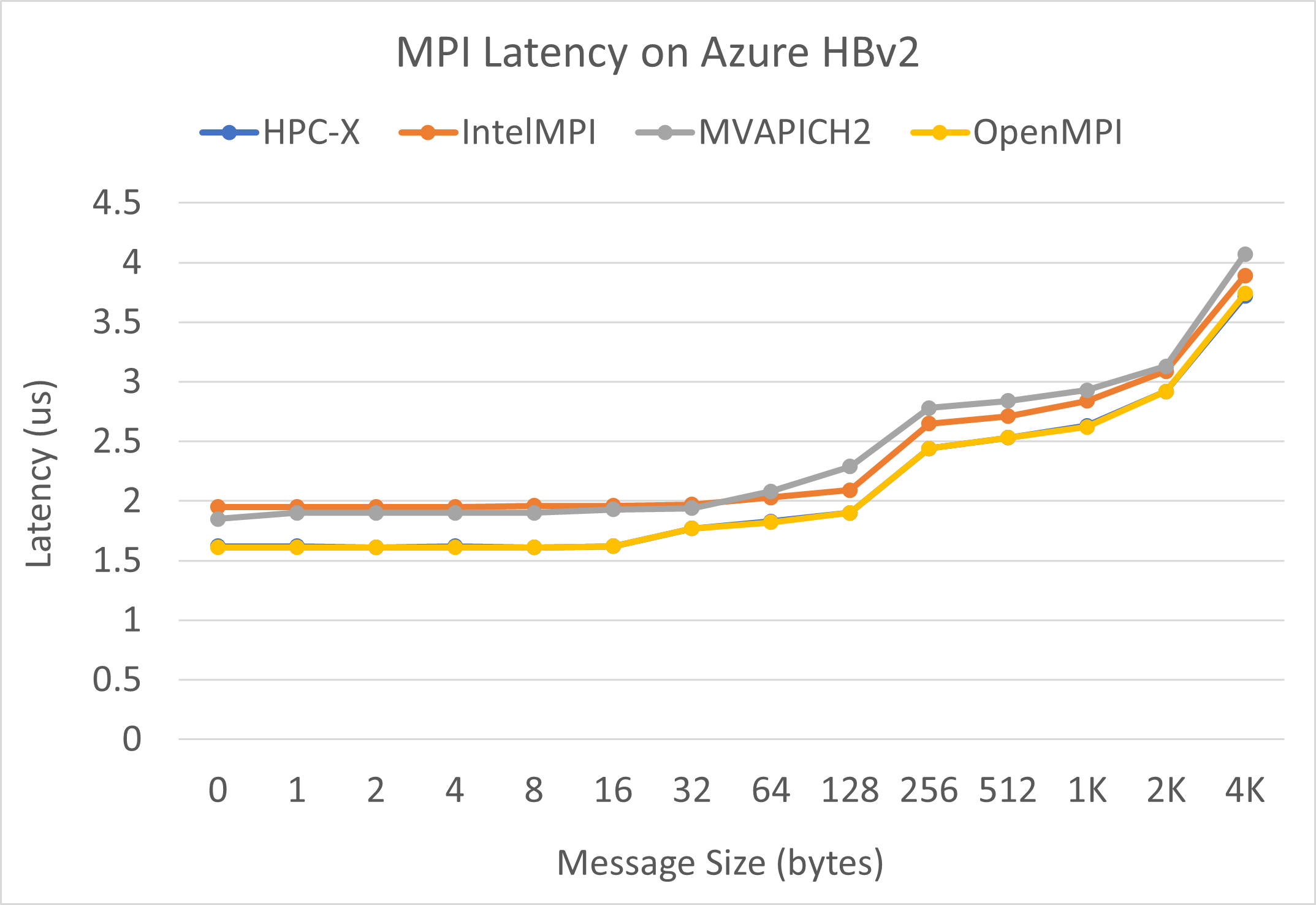
MPI-svarstid
MPI-svarstidstest från OSU microbenchmark-sviten körs. Exempelskript finns på GitHub.
./bin/mpirun_rsh -np 2 -hostfile ~/hostfile MV2_CPU_MAPPING=[INSERT CORE #] ./osu_latency
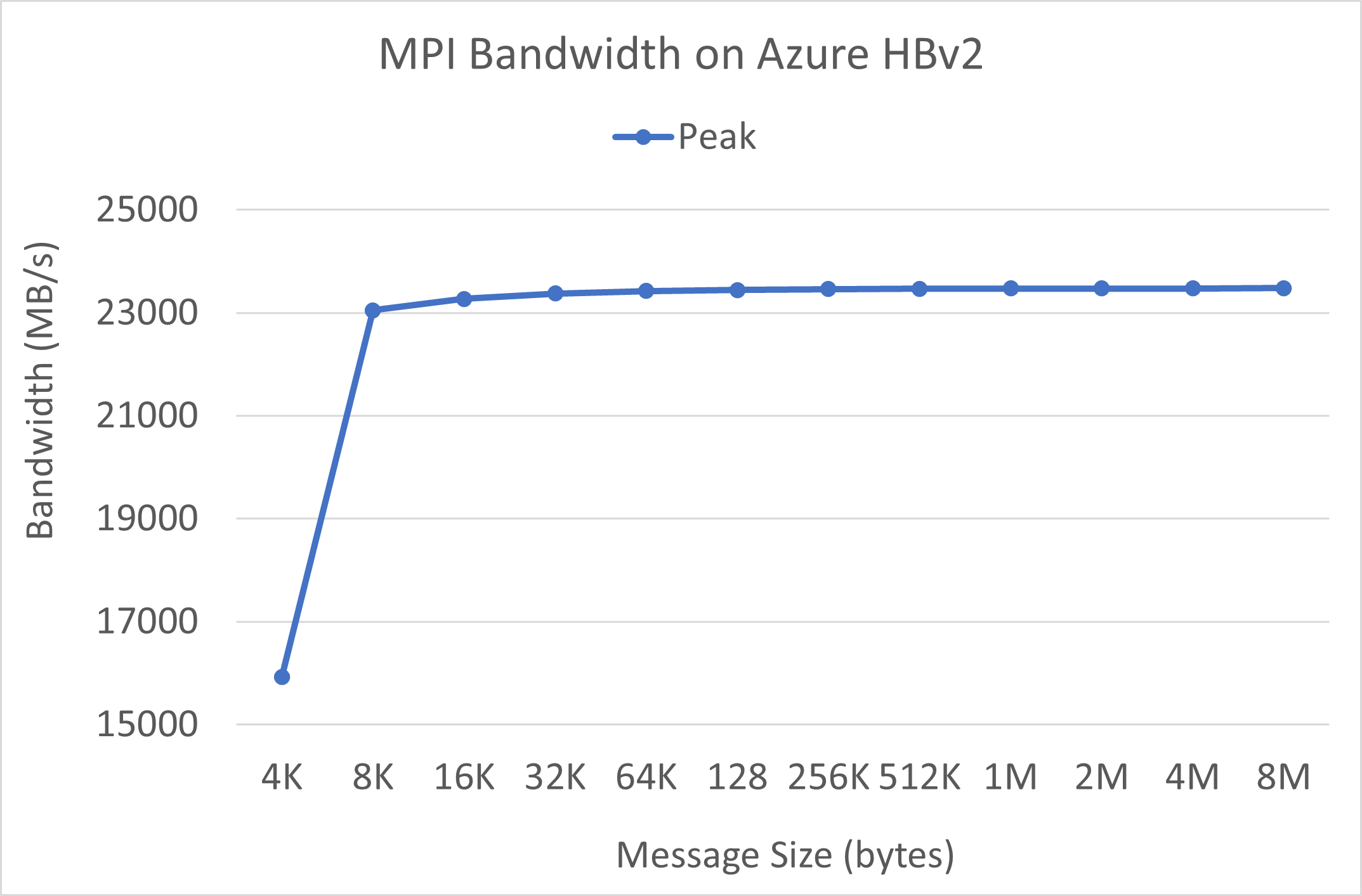
MPI-bandbredd
MPI-bandbreddstest från OSU microbenchmark-sviten körs. Exempelskript finns på GitHub.
./mvapich2-2.3.install/bin/mpirun_rsh -np 2 -hostfile ~/hostfile MV2_CPU_MAPPING=[INSERT CORE #] ./mvapich2-2.3/osu_benchmarks/mpi/pt2pt/osu_bw
Mellanox Perftest
Mellanox Perftest-paketet har många InfiniBand-tester som svarstid (ib_send_lat) och bandbredd (ib_send_bw). Ett exempelkommando finns nedan.
numactl --physcpubind=[INSERT CORE #] ib_send_lat -a
Nästa steg
- Läs om de senaste meddelandena, HPC-arbetsbelastningsexempel och prestandaresultat på Azure Compute Tech Community-bloggarna.
- En arkitekturvy på högre nivå för att köra HPC-arbetsbelastningar finns i HPC (High Performance Computing) på Azure.
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för