Överväganden för programplattform för verksamhetskritiska arbetsbelastningar i Azure
Azure tillhandahåller många beräkningstjänster för att hantera program med hög tillgänglighet. Tjänsterna skiljer sig åt i funktion och komplexitet. Vi rekommenderar att du väljer tjänster baserat på:
- Icke-funktionella krav för tillförlitlighet, tillgänglighet, prestanda och säkerhet.
- Beslutsfaktorer som skalbarhet, kostnad, driftbarhet och komplexitet.
Valet av programvärdplattform är ett kritiskt beslut som påverkar alla andra designområden. Äldre eller upphovsrättsskyddade utvecklingsprogram kanske till exempel inte körs i PaaS-tjänster eller containerbaserade program. Den här begränsningen skulle påverka ditt val av beräkningsplattform.
Ett verksamhetskritiskt program kan använda mer än en beräkningstjänst för att stödja flera sammansatta arbetsbelastningar och mikrotjänster, var och en med olika krav.
Det här designområdet innehåller rekommendationer som rör beräkningsval, design och konfigurationsalternativ. Vi rekommenderar också att du bekantar dig med beslutsträdet för beräkning.
Viktigt
Den här artikeln är en del av den verksamhetskritiska arbetsbelastningsserien för Azure Well-Architected Framework . Om du inte är bekant med den här serien rekommenderar vi att du börjar med Vad är en verksamhetskritisk arbetsbelastning?.
Global distribution av plattformsresurser
Ett typiskt mönster för en verksamhetskritisk arbetsbelastning omfattar globala resurser och regionala resurser.
Azure-tjänster, som inte är begränsade till en viss Azure-region, distribueras eller konfigureras som globala resurser. Vissa användningsfall omfattar distribution av trafik över flera regioner, lagring av permanent tillstånd för ett helt program och cachelagring av globala statiska data. Om du behöver hantera både en arkitektur för skalningsenheter och global distribution bör du överväga hur resurser distribueras optimalt eller replikeras i Azure-regioner.
Andra resurser distribueras regionalt. Dessa resurser, som distribueras som en del av en distributionsstämpel, motsvarar vanligtvis en skalningsenhet. En region kan dock ha mer än en stämpel och en stämpel kan ha mer än en enhet. Tillförlitligheten för regionala resurser är avgörande eftersom de ansvarar för att köra huvudarbetsbelastningen.
Följande bild visar design på hög nivå. En användare kommer åt programmet via en central global startpunkt som sedan omdirigerar begäranden till en lämplig regional distributionsstämpel:
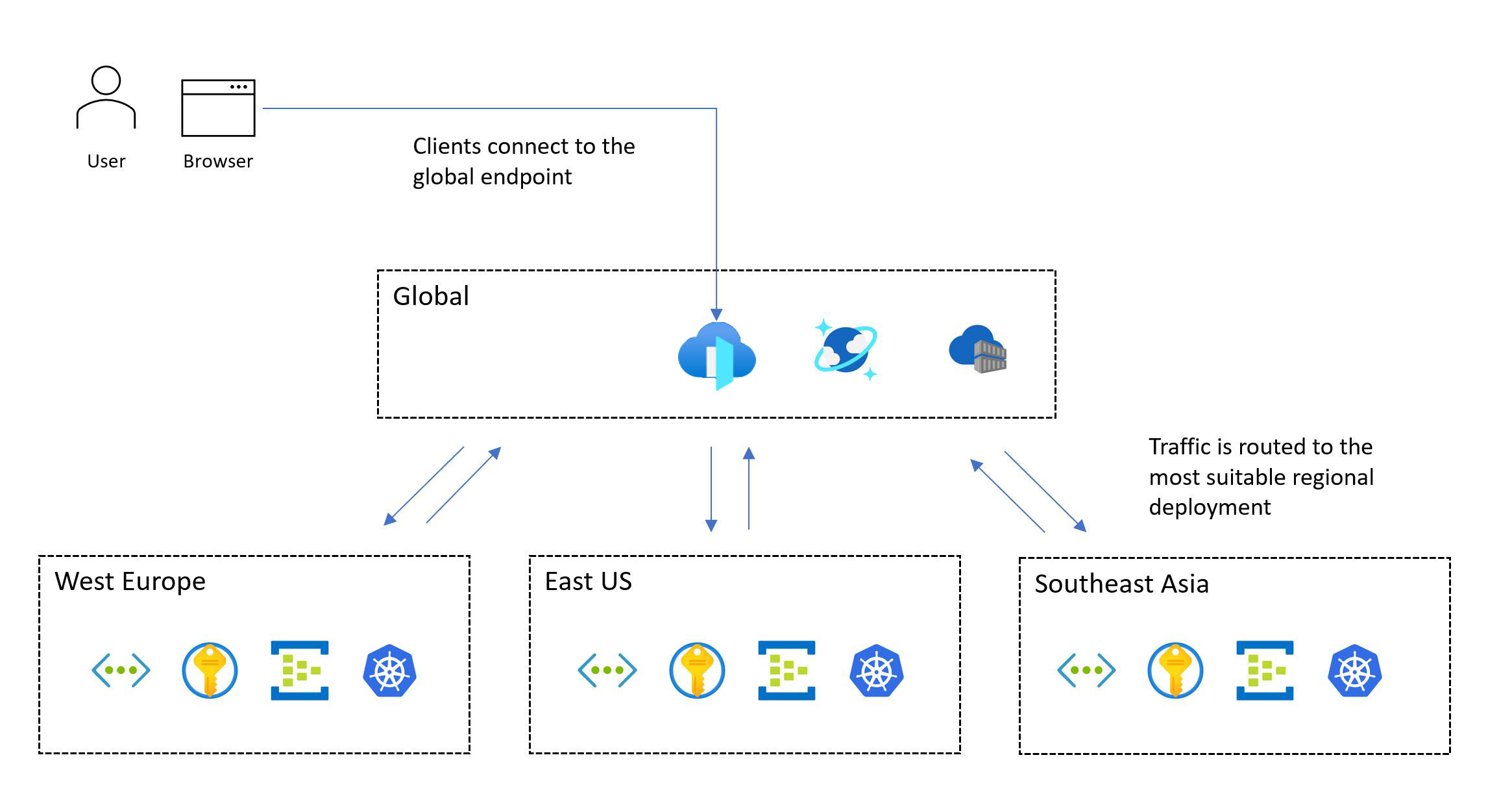
Den verksamhetskritiska designmetoden kräver en distribution i flera regioner. Den här modellen säkerställer regional feltolerans, så att programmet förblir tillgängligt även när en hel region slutar fungera. När du utformar ett program i flera regioner bör du överväga olika distributionsstrategier, till exempel aktiv/aktiv och aktiv/passiv, tillsammans med programkrav, eftersom det finns betydande kompromisser för varje metod. För verksamhetskritiska arbetsbelastningar rekommenderar vi starkt den aktiva/aktiva modellen.
Alla arbetsbelastningar stöder eller kräver inte att flera regioner körs samtidigt. Du bör väga specifika programkrav mot kompromisser för att fastställa ett optimalt designbeslut. För vissa programscenarier som har lägre tillförlitlighetsmål kan aktiv/passiv eller horisontell partitionering vara lämpliga alternativ.
Tillgänglighetszoner kan ge regionala distributioner med hög tillgänglighet i olika datacenter i en region. Nästan alla Azure-tjänster är tillgängliga i antingen en zonindelad konfiguration, där tjänsten delegeras till en specifik zon eller en zonredundant konfiguration, där plattformen automatiskt säkerställer att tjänsten sträcker sig över zoner och kan hantera ett zonfel. Dessa konfigurationer ger feltolerans upp till datacenternivå.
Designöverväganden
Regionala funktioner och zonindelningsfunktioner. Alla tjänster och funktioner är inte tillgängliga i alla Azure-regioner. Det här kan påverka de regioner du väljer. Dessutom är tillgänglighetszoner inte tillgängliga i alla regioner.
Regionala par. Azure-regioner grupperas i regionala par som består av två regioner i en enda geografi. Vissa Azure-tjänster använder länkade regioner för att säkerställa affärskontinuitet och för att tillhandahålla en skyddsnivå mot dataförlust. Till exempel replikerar Azure geo-redundant lagring (GRS) data till en sekundär länkad region automatiskt, vilket säkerställer att data är varaktiga om den primära regionen inte kan återställas. Om ett avbrott påverkar flera Azure-regioner prioriteras minst en region i varje par för återställning.
Datakonsekvens. För konsekvensutmaningar bör du överväga att använda ett globalt distribuerat datalager, en stämplad regional arkitektur och en delvis aktiv/aktiv distribution. I en partiell distribution är vissa komponenter aktiva i alla regioner medan andra finns centralt i den primära regionen.
Säker distribution. SDP-ramverket (Azure Safe Deployment Practice) säkerställer att alla kod- och konfigurationsändringar (planerat underhåll) till Azure-plattformen genomgår en stegvis distribution. Hälsotillståndet analyseras för försämring under lanseringen. När kanarie- och pilotfaserna har slutförts serialiseras plattformsuppdateringar mellan regionala par, så endast en region i varje par uppdateras vid en viss tidpunkt.
Plattformskapacitet. Precis som alla molnleverantörer har Azure begränsade resurser. Otillgänglighet kan bero på kapacitetsbegränsningar i regioner. Om det uppstår ett regionalt avbrott ökar efterfrågan på resurser när arbetsbelastningen försöker återställa i den kopplade regionen. Avbrottet kan skapa ett kapacitetsproblem, där utbudet tillfälligt inte uppfyller efterfrågan.
Designrekommendationer
Distribuera din lösning i minst två Azure-regioner för att skydda mot regionala avbrott. Distribuera den i regioner som har de funktioner och egenskaper som arbetsbelastningen kräver. Funktionerna bör uppfylla prestanda- och tillgänglighetsmål samtidigt som datahemvist och kvarhållningskrav uppfylls.
Vissa krav på dataefterlevnad kan till exempel begränsa antalet tillgängliga regioner och potentiellt tvinga fram designkompromisser. I sådana fall rekommenderar vi starkt att du lägger till extra investeringar i driftomslutningar för att förutsäga, identifiera och reagera på fel. Anta att du är begränsad till ett geografiskt område med två regioner, och endast en av dessa regioner stöder tillgänglighetszoner (3 + 1 datacentermodell). Skapa ett sekundärt distributionsmönster med hjälp av feldomänisering så att båda regionerna kan distribueras i en aktiv konfiguration och se till att den primära regionen innehåller flera distributionsstämplar.
Om lämpliga Azure-regioner inte erbjuder de funktioner som du behöver kan du vara beredd att kompromissa med konsekvensen i de regionala distributionsstämplarna för att prioritera geografisk distribution och maximera tillförlitligheten. Om endast en enskild Azure-region är lämplig distribuerar du flera distributionsstämplar (regionala skalningsenheter) i den valda regionen för att minska vissa risker och använder tillgänglighetszoner för att tillhandahålla feltolerans på datacenternivå. En sådan betydande kompromiss i den geografiska fördelningen begränsar dock dramatiskt det uppnåeliga sammansatta serviceavtalet och den övergripande tillförlitligheten.
Viktigt
För scenarier som är inriktade på ett serviceavtal som är större än eller lika med 99,99 % rekommenderar vi minst tre distributionsregioner för att maximera det sammansatta serviceavtalet och den övergripande tillförlitligheten. Beräkna det sammansatta serviceavtalet för alla användarflöden. Kontrollera att det sammansatta serviceavtalet är i linje med affärsmålen.
För storskaliga programscenarier som har betydande trafikvolymer utformar du lösningen för att skala över flera regioner för att navigera i potentiella kapacitetsbegränsningar i en enda region. Ytterligare regionala distributionsstämplar ger ett högre sammansatt serviceavtal. Om du använder globala resurser begränsas den ökning av det sammansatta serviceavtalet som du uppnår genom att lägga till fler regioner.
Definiera och verifiera mål för återställningspunkt (RPO) och mål för återställningstid (RTO).
Inom ett enskilt geografiskt område prioriterar du användningen av regionala par för att dra nytta av SDP-serialiserade distributioner för planerat underhåll och regional prioritering för oplanerat underhåll.
Geografiskt samordna Azure-resurser med användare för att minimera nätverksfördröjningen och maximera prestanda från slutpunkt till slutpunkt.
- Du kan också använda lösningar som ett cdn-nätverk (Content Delivery Network) eller edge-cachelagring för att ge optimal nätverksfördröjning för distribuerade användarbaser. Mer information finns i Global trafikroutning, Programleveranstjänster samt Cachelagring och leverans av statiskt innehåll.
Justera aktuell tjänsttillgänglighet med produktöversikter när du väljer distributionsregioner. Vissa tjänster kanske inte är omedelbart tillgängliga i varje region.
Containerisering
En container innehåller programkod och relaterade konfigurationsfiler, bibliotek och beroenden som programmet behöver köra. Containerindelning ger ett abstraktionslager för programkod och dess beroenden och skapar separation från den underliggande värdplattformen. Det enda programvarupaketet är mycket portabelt och kan köras konsekvent på olika infrastrukturplattformar och molnleverantörer. Utvecklare behöver inte skriva om kod och kan distribuera program snabbare och mer tillförlitligt.
Viktigt
Vi rekommenderar att du använder containrar för verksamhetskritiska programpaket. De förbättrar infrastrukturanvändningen eftersom du kan vara värd för flera containrar i samma virtualiserade infrastruktur. Eftersom all programvara ingår i containern kan du flytta programmet mellan olika operativsystem, oavsett körning eller biblioteksversioner. Hantering är också enklare med containrar än med traditionell virtualiserad värd.
Verksamhetskritiska program måste skalas snabbt för att undvika flaskhalsar i prestanda. Eftersom containeravbildningar är färdiga kan du begränsa start till att endast ske under start av programmet, vilket ger snabb skalbarhet.
Designöverväganden
Övervakning. Det kan vara svårt för övervakningstjänster att komma åt program som finns i containrar. Du behöver vanligtvis programvara från tredje part för att samla in och lagra indikatorer för containertillstånd som CPU- eller RAM-användning.
Säkerhet. Värdplattformens OS-kernel delas mellan flera containrar, vilket skapar en enda attackpunkt. Risken för åtkomst till virtuella värddatorer är dock begränsad eftersom containrar är isolerade från det underliggande operativsystemet.
Tillstånd. Även om det är möjligt att lagra data i en containers filsystem som körs, bevaras inte data när containern återskapas. Spara i stället data genom att montera extern lagring eller använda en extern databas.
Designrekommendationer
Containerisera alla programkomponenter. Använd containeravbildningar som primär modell för programdistributionspaket.
Prioritera Linux-baserade containerkörningar när det är möjligt. Avbildningarna är enklare och nya funktioner för Linux-noder/-containrar släpps ofta.
Gör containrar oföränderliga och utbytbara med korta livscykeler.
Se till att samla in alla relevanta loggar och mått från containern, containervärden och det underliggande klustret. Skicka de insamlade loggarna och måtten till en enhetlig datamottagare för vidare bearbetning och analys.
Lagra containeravbildningar i Azure Container Registry. Använd geo-replikering för att replikera containeravbildningar i alla regioner. Aktivera Microsoft Defender för containerregister för att tillhandahålla sårbarhetsgenomsökning för containeravbildningar. Kontrollera att åtkomsten till registret hanteras av Microsoft Entra-ID.
Värd- och orkestrering av containrar
Flera Azure-programplattformar kan effektivt vara värdar för containrar. Det finns fördelar och nackdelar som är associerade med var och en av dessa plattformar. Jämför alternativen i kontexten för dina affärsbehov. Optimera dock alltid tillförlitlighet, skalbarhet och prestanda. Mer information finns i de här artiklarna:
Viktigt
Azure Kubernetes Service (AKS) och Azure Container Apps bör vara bland de första alternativen för containerhantering beroende på dina behov. Även om Azure App Service inte är en orkestrerare, är det som en containerplattform med låg friktion fortfarande ett genomförbart alternativ till AKS.
Designöverväganden och rekommendationer för Azure Kubernetes Service
AKS, en hanterad Kubernetes-tjänst, möjliggör snabb klusteretablering utan att kräva komplexa aktiviteter för klusteradministration och erbjuder en funktionsuppsättning som innehåller avancerade nätverks- och identitetsfunktioner. En fullständig uppsättning rekommendationer finns i Azure Well-Architected Framework-granskning – AKS.
Viktigt
Det finns några grundläggande konfigurationsbeslut som du inte kan ändra utan att distribuera om AKS-klustret. Exempel är valet mellan offentliga och privata AKS-kluster, aktivering av Azure Network Policy, Microsoft Entra integrering och användning av hanterade identiteter för AKS i stället för tjänstens huvudnamn.
Tillförlitlighet
AKS hanterar det inbyggda Kubernetes-kontrollplanet. Om kontrollplanet inte är tillgängligt får arbetsbelastningen avbrottstid. Dra nytta av de tillförlitlighetsfunktioner som erbjuds av AKS:
Distribuera AKS-kluster i olika Azure-regioner som en skalningsenhet för att maximera tillförlitligheten och tillgängligheten. Använd tillgänglighetszoner för att maximera motståndskraften i en Azure-region genom att distribuera AKS-kontrollplan och agentnoder mellan fysiskt separata datacenter. Men om svarstiden för samlokalisering är ett problem kan du utföra AKS-distribution inom en enda zon eller använda närhetsplaceringsgrupper för att minimera svarstiden för internode.
Använd serviceavtalet för AKS-drifttid för produktionskluster för att maximera kubernetes API-slutpunktens tillgänglighetsgarantier.
Skalbarhet
Ta hänsyn till AKS-skalningsgränser, till exempel antalet noder, nodpooler per kluster och kluster per prenumeration.
Om skalningsgränser är en begränsning kan du dra nytta av strategin för skalningsenheter och distribuera fler enheter med kluster.
Aktivera autoskalning av kluster för att automatiskt justera antalet agentnoder som svar på resursbegränsningar.
Använd horisontell autoskalning av poddar för att justera antalet poddar i en distribution baserat på CPU-användning eller andra mått.
För scenarier med hög skala och burst bör du överväga att använda virtuella noder för omfattande och snabb skalning.
Definiera begäranden och begränsningar för poddar i programdistributionsmanifest. Om du inte gör det kan det uppstå prestandaproblem.
Isolering
Upprätthålla gränser mellan den infrastruktur som används av arbetsbelastnings- och systemverktygen. Delningsinfrastrukturen kan leda till hög resursanvändning och störningar i närliggande scenarier.
Använd separata nodpooler för system- och arbetsbelastningstjänster. Dedikerade nodpooler för arbetsbelastningskomponenter bör baseras på krav för specialiserade infrastrukturresurser som virtuella GPU-datorer med hög minnesanvändning. För att minska onödiga hanteringskostnader bör du i allmänhet undvika att distribuera ett stort antal nodpooler.
Använd taints och toleranser för att tillhandahålla dedikerade noder och begränsa resursintensiva program.
Utvärdera programtillhörighets- och antitillhörighetskrav och konfigurera lämplig samlokalisering av containrar på noder.
Säkerhet
Standardinställningen för Kubernetes kräver betydande konfiguration för att säkerställa en lämplig säkerhetsstatus för verksamhetskritiska scenarier. AKS hanterar olika säkerhetsrisker direkt. Funktionerna omfattar privata kluster, granskning och loggning av Log Analytics, härdade nodavbildningar och hanterade identiteter.
Använd konfigurationsvägledningen i AKS-säkerhetsbaslinjen.
Använd AKS-funktioner för hantering av klusteridentitet och åtkomsthantering för att minska driftskostnaderna och tillämpa konsekvent åtkomsthantering.
Använd hanterade identiteter i stället för tjänstens huvudnamn för att undvika hantering och rotation av autentiseringsuppgifter. Du kan lägga till hanterade identiteter på klusternivå. På poddnivå kan du använda hanterade identiteter via Microsoft Entra Workload ID.
Använd Microsoft Entra integrering för centraliserad kontohantering och lösenord, hantering av programåtkomst och förbättrat identitetsskydd. Använd Kubernetes RBAC med Microsoft Entra-ID för lägsta behörighet och minimera beviljandet av administratörsprivilegier för att skydda åtkomsten till konfiguration och hemligheter. Begränsa också åtkomsten till Kubernetes-klusterkonfigurationsfilen med hjälp av rollbaserad åtkomstkontroll i Azure. Begränsa åtkomsten till åtgärder som containrar kan utföra, ange minst antal behörigheter och undvik att använda eskalering av rotprivilegier.
Uppgraderingar
Kluster och noder måste uppgraderas regelbundet. AKS stöder Kubernetes-versioner i enlighet med versionscykeln för inbyggda Kubernetes.
Prenumerera på den offentliga AKS-översikten och viktig information på GitHub för att hålla dig uppdaterad om kommande ändringar, förbättringar och, viktigast av allt, Versioner av Kubernetes och utfasningar.
Använd vägledningen i AKS-checklistan för att säkerställa att de överensstämmer med bästa praxis.
Tänk på de olika metoder som stöds av AKS för att uppdatera noder och/eller kluster. Dessa metoder kan vara manuella eller automatiserade. Du kan använda Planerat underhåll för att definiera underhållsperioder för dessa åtgärder. Nya bilder släpps varje vecka. AKS stöder även automatiska uppgraderingskanaler för automatisk uppgradering av AKS-kluster till nyare versioner av Kubernetes och/eller nyare nodavbildningar när de är tillgängliga.
Nätverk
Utvärdera de nätverksplugin-program som passar bäst för ditt användningsfall. Avgör om du behöver detaljerad kontroll över trafiken mellan poddar. Azure stöder kubenet, Azure CNI och bring your own CNI för specifika användningsfall.
Prioritera användningen av Azure CNI när du har utvärderat nätverkskrav och klustrets storlek. Med Azure CNI kan du använda Azure - eller Calico-nätverksprinciper för att styra trafiken i klustret.
Övervakning
Övervakningsverktygen ska kunna samla in loggar och mått från poddar som körs. Du bör också samla in information från Kubernetes Metrics API för att övervaka hälsotillståndet för resurser och arbetsbelastningar som körs.
Använd Azure Monitor och Application Insights för att samla in mått, loggar och diagnostik från AKS-resurser för felsökning.
Aktivera och granska Kubernetes-resursloggar.
Konfigurera Prometheus-mått i Azure Monitor. Containerinsikter i Monitor ger registrering, möjliggör övervakningsfunktioner direkt och möjliggör mer avancerade funktioner via inbyggt Prometheus-stöd.
Styrning
Använd principer för att tillämpa centraliserade skydd på AKS-kluster på ett konsekvent sätt. Tillämpa principtilldelningar i ett prenumerationsomfång eller högre för att skapa konsekvens mellan utvecklingsteamen.
Kontrollera vilka funktioner som beviljas poddar och om körningen strider mot principen med hjälp av Azure Policy. Den här åtkomsten definieras via inbyggda principer som tillhandahålls av Azure Policy-tillägget för AKS.
Upprätta en konsekvent tillförlitlighets- och säkerhetsbaslinje för AKS-kluster- och poddkonfigurationer med hjälp av Azure Policy.
Använd Azure Policy-tillägget för AKS för att styra poddfunktioner, till exempel rotprivilegier, och för att neka poddar som inte följer principen.
Anteckning
När du distribuerar till en Azure-landningszon bör Azure-principerna som hjälper dig att säkerställa konsekvent tillförlitlighet och säkerhet tillhandahållas av implementeringen av landningszonen.
De verksamhetskritiska referensimplementeringarna tillhandahåller en uppsättning baslinjeprinciper för att driva rekommenderade tillförlitlighets- och säkerhetskonfigurationer.
Designöverväganden och rekommendationer för Azure App Service
För webb- och API-baserade arbetsbelastningsscenarier kan App Service vara ett genomförbart alternativ till AKS. Det ger en containerplattform med låg friktion utan kubernetes komplexitet. En fullständig uppsättning rekommendationer finns i Tillförlitlighetsöverväganden för App Service och driftseffektivitet för App Service.
Tillförlitlighet
Utvärdera användningen av TCP- och SNAT-portar. TCP-anslutningar används för alla utgående anslutningar. SNAT-portar används för utgående anslutningar till offentliga IP-adresser. SNAT-portöverbelastning är ett vanligt felscenario. Du bör förutsäga problemet genom att läsa in testning när du använder Azure Diagnostics för att övervaka portar. Om SNAT-fel inträffar måste du antingen skala över fler eller större arbetare eller implementera kodningsmetoder för att bevara och återanvända SNAT-portar. Exempel på kodningsmetoder som du kan använda är anslutningspooler och lat inläsning av resurser.
TCP-portöverbelastning är ett annat felscenario. Det inträffar när summan av utgående anslutningar från en viss arbetare överskrider kapaciteten. Antalet tillgängliga TCP-portar beror på arbetarens storlek. Rekommendationer finns i TCP- och SNAT-portar.
Skalbarhet
Planera för framtida skalbarhetskrav och programtillväxt så att du kan tillämpa lämpliga rekommendationer från början. På så sätt kan du undvika tekniska migreringsskulder när lösningen växer.
Aktivera autoskalning för att säkerställa att lämpliga resurser är tillgängliga för tjänstbegäranden. Utvärdera skalning per app för högdensitetsvärd på App Service.
Tänk på att App Service har en standardmässig, mjuk gräns för instanser per App Service plan.
Tillämpa regler för autoskalning. En App Service plan skalas ut om någon regel i profilen uppfylls men bara skalas in om alla regler i profilen uppfylls. Använd en regelkombination för utskalning och inskalning för att säkerställa att autoskalning kan vidta åtgärder för att både skala ut och skala in. Förstå beteendet för flera skalningsregler i en enda profil.
Tänk på att du kan aktivera skalning per app på nivån för den App Service planen så att ett program kan skalas oberoende av den App Service plan som är värd för den. Appar allokeras till tillgängliga noder via en metod för bästa förmåga för en jämn distribution. Även om en jämn distribution inte garanteras ser plattformen till att två instanser av samma app inte finns på samma instans.
Övervakning
Övervaka programmets beteende och få åtkomst till relevanta loggar och mått för att säkerställa att programmet fungerar som förväntat.
Du kan använda diagnostikloggning för att mata in loggar på programnivå och plattformsnivå i Log Analytics, Azure Storage eller ett verktyg från tredje part via Azure Event Hubs.
Övervakning av programprestanda med Application Insights ger djupgående insikter om programmets prestanda.
Verksamhetskritiska program måste ha möjlighet att läka sig själv om det uppstår fel. Aktivera Automatisk läkning för att automatiskt återvinna arbetare som inte är felfria.
Du måste använda lämpliga hälsokontroller för att utvärdera alla kritiska underordnade beroenden, vilket bidrar till att säkerställa övergripande hälsa. Vi rekommenderar starkt att du aktiverar hälsokontroll för att identifiera icke-dynamiska arbetare.
Distribution
Om du vill kringgå standardgränsen för instanser per App Service plan distribuerar du App Service planer i flera skalningsenheter i en enda region. Distribuera App Service planer i en konfiguration av tillgänglighetszonen för att säkerställa att arbetsnoder distribueras mellan zoner i en region. Överväg att öppna ett supportärende för att öka det maximala antalet arbetare till dubbelt så många instanser som du behöver för att hantera normal belastning.
Containerregister
Containerregister är värd för avbildningar som distribueras till containerkörningsmiljöer som AKS. Du måste konfigurera dina containerregister för verksamhetskritiska arbetsbelastningar noggrant. Ett avbrott bör inte orsaka fördröjningar vid borttagning av bilder, särskilt under skalningsåtgärder. Följande överväganden och rekommendationer fokuserar på Azure Container Registry och utforskar de kompromisser som är associerade med centraliserade och federerade distributionsmodeller.
Designöverväganden
Format. Överväg att använda ett containerregister som förlitar sig på det Docker-tillhandahållna formatet och standarderna för både push- och pull-åtgärder. Dessa lösningar är kompatibla och mest utbytbara.
Distributionsmodell. Du kan distribuera containerregistret som en centraliserad tjänst som används av flera program i din organisation. Eller så kan du distribuera den som en dedikerad komponent för en specifik programarbetsbelastning.
Offentliga register. Containeravbildningar lagras i Docker Hub eller andra offentliga register som finns utanför Azure och ett visst virtuellt nätverk. Det här är inte nödvändigtvis ett problem, men det kan leda till olika problem som rör tjänstens tillgänglighet, begränsning och dataexfiltrering. I vissa programscenarier måste du replikera offentliga containeravbildningar i ett privat containerregister för att begränsa utgående trafik, öka tillgängligheten eller undvika potentiell begränsning.
Designrekommendationer
Använd containerregisterinstanser som är dedikerade till programarbetsbelastningen. Undvik att skapa ett beroende av en centraliserad tjänst om inte organisationens tillgänglighets- och tillförlitlighetskrav är helt i linje med programmet.
I det rekommenderade kärnarkitekturmönstret är containerregister globala resurser som är långvariga. Överväg att använda ett enda globalt containerregister per miljö. Använd till exempel ett globalt produktionsregister.
Se till att serviceavtalet för det offentliga registret är i linje med dina tillförlitlighets- och säkerhetsmål. Notera särskilt begränsningar för användningsfall som är beroende av Docker Hub.
Prioritera Azure Container Registry som värd för containeravbildningar.
Designöverväganden och rekommendationer för Azure Container Registry
Den här interna tjänsten innehåller en rad funktioner, inklusive geo-replikering, Microsoft Entra autentisering, automatiserad containerbyggnad och korrigering via Container Registry-uppgifter.
Tillförlitlighet
Konfigurera geo-replikering till alla distributionsregioner för att ta bort regionala beroenden och optimera svarstiden. Container Registry stöder hög tillgänglighet via geo-replikering till flera konfigurerade regioner, vilket ger återhämtning mot regionala avbrott. Om en region blir otillgänglig fortsätter de andra regionerna att hantera bildbegäranden. När regionen är online igen återställer containerregistret och replikerar ändringar i den. Den här funktionen tillhandahåller även registersamlokalisering inom varje konfigurerad region, vilket minskar nätverksfördröjningen och kostnaderna för dataöverföring mellan regioner.
I Azure-regioner som tillhandahåller stöd för tillgänglighetszoner stöder Premium Container Registry-nivån zonredundans för att ge skydd mot zonfel. Premium-nivån stöder även privata slutpunkter för att förhindra obehörig åtkomst till registret, vilket kan leda till tillförlitlighetsproblem.
Värdbilder nära de förbrukande beräkningsresurserna i samma Azure-regioner.
Bildlåsning
Bilder kan tas bort, till exempel på grund av ett manuellt fel. Container Registry stöder låsning av en avbildningsversion eller en lagringsplats för att förhindra ändringar eller borttagningar. När en tidigare distribuerad avbildningsversion ändras på plats kan distributioner av samma version ge olika resultat före och efter ändringen.
Om du vill skydda Container Registry-instansen från borttagning använder du resurslås.
Taggade bilder
Taggade Container Registry-avbildningar kan ändras som standard, vilket innebär att samma tagg kan användas på flera avbildningar som skickas till registret. I produktionsscenarier kan detta leda till oförutsägbart beteende som kan påverka programmets drifttid.
Identitets- och åtkomsthantering
Använd Microsoft Entra integrerad autentisering för att push-överföra och hämta avbildningar i stället för att förlita dig på åtkomstnycklar. För förbättrad säkerhet inaktiverar du fullständigt användningen av administratörsåtkomstnyckeln.
Serverlös databearbetning
Serverlös databehandling tillhandahåller resurser på begäran och eliminerar behovet av att hantera infrastrukturen. Molnleverantören etablerar, skalar och hanterar automatiskt de resurser som krävs för att köra distribuerad programkod. Azure tillhandahåller flera serverlösa beräkningsplattformar:
Azure Functions. När du använder Azure Functions implementeras programlogiken som distinkta kodblock eller funktioner som körs som svar på händelser, till exempel en HTTP-begäran eller ett kömeddelande. Varje funktion skalas efter behov för att möta efterfrågan.
Azure Logic Apps. Logic Apps passar bäst för att skapa och köra automatiserade arbetsflöden som integrerar olika appar, datakällor, tjänster och system. Precis som Azure Functions använder Logic Apps inbyggda utlösare för händelsedriven bearbetning. Men i stället för att distribuera programkod kan du skapa logikappar med hjälp av ett grafiskt användargränssnitt som stöder kodblock som villkor och loopar.
Azure API Management. Du kan använda API Management för att publicera, transformera, underhålla och övervaka API:er med förbättrad säkerhet med hjälp av förbrukningsnivån.
Power Apps och Power Automate. De här verktygen ger en utvecklingsupplevelse med lite kod eller ingen kod, med enkel arbetsflödeslogik och integreringar som kan konfigureras via anslutningar i ett användargränssnitt.
För verksamhetskritiska program ger serverlös teknik förenklad utveckling och drift, vilket kan vara värdefullt för enkla affärsanvändningsfall. Den här enkelheten kostar dock flexibilitet när det gäller skalbarhet, tillförlitlighet och prestanda, och det är inte genomförbart för de flesta verksamhetskritiska programscenarier.
Följande avsnitt innehåller designöverväganden och rekommendationer för användning av Azure Functions och Logic Apps som alternativa plattformar för icke-kritiska arbetsflödesscenarier.
Designöverväganden och rekommendationer för Azure Functions
Verksamhetskritiska arbetsbelastningar har kritiska och icke-kritiska systemflöden. Azure Functions är ett genomförbart val för flöden som inte har samma strikta affärskrav som kritiska systemflöden. Det passar bra för händelsedrivna flöden som har kortvariga processer eftersom funktioner utför distinkta åtgärder som körs så snabbt som möjligt.
Välj ett Azure Functions värdalternativ som är lämpligt för programmets tillförlitlighetsnivå. Vi rekommenderar Premium-planen eftersom du kan konfigurera beräkningsinstansens storlek. Den dedikerade planen är det minst serverlösa alternativet. Den tillhandahåller autoskalning, men dessa skalningsåtgärder är långsammare än de i de andra planerna. Vi rekommenderar att du använder Premium-planen för att maximera tillförlitlighet och prestanda.
Det finns vissa säkerhetsöverväganden. När du använder en HTTP-utlösare för att exponera en extern slutpunkt använder du en brandvägg för webbaserade program (WAF) för att tillhandahålla en skyddsnivå för HTTP-slutpunkten från vanliga externa attackvektorer.
Vi rekommenderar att du använder privata slutpunkter för att begränsa åtkomsten till privata virtuella nätverk. De kan också minimera dataexfiltreringsrisker, till exempel skadliga administratörsscenarier.
Du måste använda kodgenomsökningsverktyg på Azure Functions kod och integrera dessa verktyg med CI/CD-pipelines.
Designöverväganden och rekommendationer för Azure Logic Apps
Precis som Azure Functions använder Logic Apps inbyggda utlösare för händelsedriven bearbetning. Men i stället för att distribuera programkod kan du skapa logikappar med hjälp av ett grafiskt användargränssnitt som stöder block som villkor, loopar och andra konstruktioner.
Flera distributionslägen är tillgängliga. Vi rekommenderar standardläget för att säkerställa en distribution med en enda klientorganisation och minimera störningar i närliggande scenarier. Det här läget använder Logic Apps-körningen för en containerbaserad enskild klientorganisation, som baseras på Azure Functions. I det här läget kan logikappen ha flera tillståndskänsliga och tillståndslösa arbetsflöden. Du bör vara medveten om konfigurationsgränserna.
Begränsad migrering via IaaS
Många program som har befintliga lokala distributioner använder virtualiseringstekniker och redundant maskinvara för att tillhandahålla verksamhetskritiska nivåer av tillförlitlighet. Modernisering hindras ofta av affärsbegränsningar som förhindrar fullständig anpassning till det molnbaserade baslinjearkitekturmönstret (North Star) som rekommenderas för verksamhetskritiska arbetsbelastningar. Det är därför många program använder en stegvis metod, där inledande molndistributioner använder virtualisering och Azure Virtual Machines som primär programvärdmodell. Användning av virtuella IaaS-datorer kan krävas i vissa scenarier:
- Tillgängliga PaaS-tjänster ger inte nödvändig prestanda eller kontrollnivå.
- Arbetsbelastningen kräver operativsystemåtkomst, specifika drivrutiner eller nätverks- och systemkonfigurationer.
- Arbetsbelastningen stöder inte körning i containrar.
- Det finns inget leverantörsstöd för arbetsbelastningar från tredje part.
Det här avsnittet fokuserar på de bästa sätten att använda Azure Virtual Machines och associerade tjänster för att maximera programplattformens tillförlitlighet. Den belyser viktiga aspekter av den verksamhetskritiska designmetodik som transponerar molnbaserade scenarier och IaaS-migreringsscenarier.
Designöverväganden
Driftskostnaderna för att använda virtuella IaaS-datorer är betydligt högre än kostnaderna för att använda PaaS-tjänster på grund av hanteringskraven för de virtuella datorerna och operativsystemen. Hanteringen av virtuella datorer kräver den frekventa distributionen av programvarupaket och uppdateringar.
Azure tillhandahåller funktioner för att öka tillgängligheten för virtuella datorer:
- Tillgänglighetsuppsättningar kan skydda mot nätverks-, disk- och strömavbrott genom att distribuera virtuella datorer mellan feldomäner och uppdateringsdomäner.
- Tillgänglighetszoner kan hjälpa dig att uppnå ännu högre tillförlitlighetsnivåer genom att distribuera virtuella datorer mellan fysiskt avgränsade datacenter i en region.
- Virtual Machine Scale Sets tillhandahåller funktioner för automatisk skalning av antalet virtuella datorer i en grupp. De innehåller också funktioner för övervakning av instanshälsa och automatisk reparation av instanser med feltillstånd.
Designrekommendationer
Viktigt
Använd PaaS-tjänster och -containrar när det är möjligt för att minska driftskomplexiteten och kostnaden. Använd endast virtuella IaaS-datorer när du behöver det.
Ange rätt storlek på VM SKU-storlekar för att säkerställa effektiv resursanvändning.
Distribuera tre eller fler virtuella datorer mellan tillgänglighetszoner för att uppnå feltolerans på datacenternivå.
- Om du distribuerar kommersiell extern programvara bör du kontakta programvaruleverantören och testa på lämpligt sätt innan du distribuerar programvaran till produktion.
För arbetsbelastningar som inte kan distribueras mellan tillgänglighetszoner använder du tillgänglighetsuppsättningar som innehåller tre eller flera virtuella datorer.
- Överväg endast tillgänglighetsuppsättningar om tillgänglighetszoner inte uppfyller arbetsbelastningskraven, till exempel för trafikintensiva arbetsbelastningar med låga svarstidskrav.
Prioritera användningen av Virtual Machine Scale Sets för skalbarhet och zonredundans. Den här punkten är särskilt viktig för arbetsbelastningar som har olika belastningar. Om till exempel antalet aktiva användare eller begäranden per sekund är en varierande belastning.
Få inte direkt åtkomst till enskilda virtuella datorer. Använd lastbalanserare framför dem när det är möjligt.
För att skydda mot regionala avbrott distribuerar du virtuella programdatorer i flera Azure-regioner.
- Mer information om hur du dirigerar trafik mellan aktiva distributionsregioner finns i designområdet för nätverk och anslutningar .
För arbetsbelastningar som inte stöder aktiva/aktiva distributioner i flera regioner bör du överväga att implementera aktiva/passiva distributioner med hjälp av virtuella datorer med hett/varmt vänteläge för regional redundans.
Använd standardbilder från Azure Marketplace i stället för anpassade avbildningar som behöver underhållas.
Implementera automatiserade processer för att distribuera och distribuera ändringar till virtuella datorer och undvika manuella åtgärder. Mer information finns i IaaS-överväganden i designområdet för operativa procedurer .
Implementera kaosexperiment för att mata in programfel i komponenter för virtuella datorer och observera risken för fel. Mer information finns i Kontinuerlig validering och testning.
Övervaka virtuella datorer och se till att diagnostikloggar och mått matas in i en enhetlig datamottagare.
Implementera säkerhetsmetoder för verksamhetskritiska programscenarier, i förekommande fall, och rekommenderade säkerhetsmetoder för IaaS-arbetsbelastningar i Azure.
Nästa steg
Granska övervägandena för dataplattformen.
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för