Rekommendationer för svar på säkerhetsincidenter
Gäller för checklista för Azure Well-Architected Framework Security:
| SE:12 | Definiera och testa effektiva procedurer för incidenthantering som täcker ett spektrum av incidenter, från lokaliserade problem till haveriberedskap. Definiera tydligt vilket team eller individ som kör en procedur. |
|---|
Den här guiden beskriver rekommendationerna för att implementera ett svar på säkerhetsincidenter för en arbetsbelastning. Om det finns en säkerhetskompromiss till ett system bidrar en systematisk incidenthanteringsmetod till att minska den tid det tar att identifiera, hantera och minimera säkerhetsincidenter. Dessa incidenter kan hota konfidentialiteten, integriteten och tillgängligheten för programvarusystem och data.
De flesta företag har ett centralt säkerhetsåtgärdsteam (även kallat Security Operations Center (SOC) eller SecOps. Säkerhetsåtgärdsteamets ansvar är att snabbt identifiera, prioritera och sortera potentiella attacker. Teamet övervakar även säkerhetsrelaterade telemetridata och undersöker säkerhetsöverträdelser.
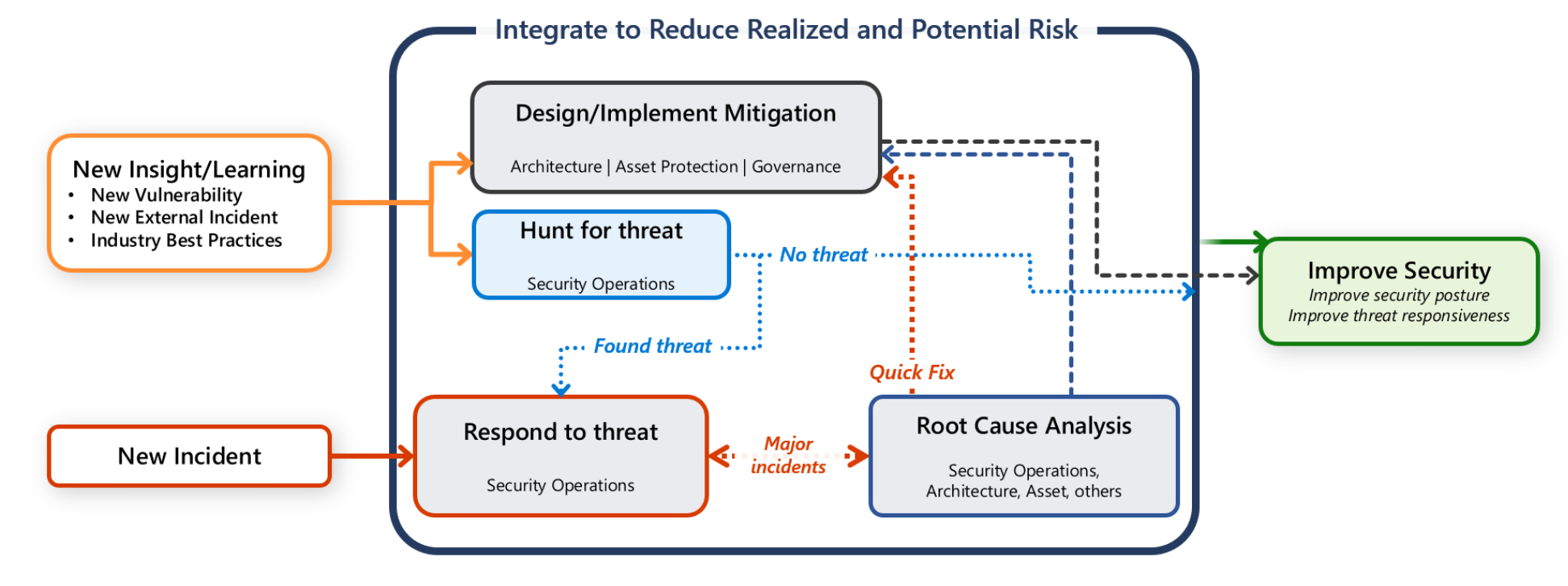
Men du har också ett ansvar för att skydda din arbetsbelastning. Det är viktigt att alla kommunikations-, undersöknings- och jaktaktiviteter är ett samarbete mellan arbetsbelastningsteamet och SecOps-teamet.
Den här guiden innehåller rekommendationer för dig och ditt arbetsbelastningsteam som hjälper dig att snabbt identifiera, sortera och undersöka attacker.
Definitioner
| Period | Definition |
|---|---|
| Varning | Ett meddelande som innehåller information om en incident. |
| Aviseringsåtergivning | Noggrannheten för de data som avgör en avisering. Aviseringar med hög återgivning innehåller den säkerhetskontext som behövs för att vidta omedelbara åtgärder. Låg återgivningsaviseringar saknar information eller innehåller brus. |
| Falsk positiv identifiering | En avisering som anger en incident som inte inträffade. |
| Incident | En händelse som indikerar obehörig åtkomst till ett system. |
| Incidenthantering | En process som identifierar, svarar på och minimerar risker som är associerade med en incident. |
| Sortera | En incidenthanteringsåtgärd som analyserar säkerhetsproblem och prioriterar deras åtgärd. |
Viktiga designstrategier
Du och ditt team utför incidenthanteringsåtgärder när det finns en signal eller avisering om en potentiell kompromiss. Aviseringar med hög återgivning innehåller gott om säkerhetskontexter som gör det enkelt för analytiker att fatta beslut. Aviseringar med hög återgivning resulterar i ett lågt antal falska positiva identifieringar. Den här guiden förutsätter att ett aviseringssystem filtrerar låg återgivningssignaler och fokuserar på aviseringar med hög återgivning som kan tyda på en verklig incident.
Utse incidentmeddelandekontakter
Säkerhetsaviseringar måste nå rätt personer i ditt team och i din organisation. Upprätta en utsedd kontaktpunkt i arbetsbelastningsteamet för att ta emot incidentaviseringar. Dessa meddelanden bör innehålla så mycket information som möjligt om resursen som komprometteras och systemet. Aviseringen måste innehålla nästa steg, så att ditt team kan påskynda åtgärder.
Vi rekommenderar att du loggar och hanterar incidentmeddelanden och åtgärder med hjälp av specialiserade verktyg som behåller en spårningslogg. Med hjälp av standardverktyg kan du bevara bevis som kan krävas för potentiella juridiska utredningar. Leta efter möjligheter att implementera automatisering som kan skicka meddelanden baserat på ansvarsområdena för ansvariga parter. Håll en tydlig kedja av kommunikation och rapportering under en incident.
Dra nytta av SIEM-lösningar (Security Information Event Management) och soar-lösningar (Security Orchestration Automated Response) som din organisation tillhandahåller. Du kan också skaffa verktyg för incidenthantering och uppmuntra din organisation att standardisera dem för alla arbetsbelastningsteam.
Undersök med ett sorteringsteam
Den teammedlem som tar emot ett incidentmeddelande ansvarar för att konfigurera en triageprocess som involverar lämpliga personer baserat på tillgängliga data. Triage-teamet, som ofta kallas bryggteamet, måste komma överens om kommunikationsläget och kommunikationsprocessen. Kräver den här incidenten asynkrona diskussioner eller brygganrop? Hur ska teamet spåra och kommunicera förloppet för utredningar? Var kan teamet komma åt incidenttillgångar?
Incidenthantering är en viktig orsak till att hålla dokumentationen uppdaterad, till exempel systemets arkitekturlayout, information på komponentnivå, sekretess- eller säkerhetsklassificering, ägare och viktiga kontaktpunkter. Om informationen är felaktig eller inaktuell slösar bridgeteamet värdefull tid på att försöka förstå hur systemet fungerar, vem som ansvarar för varje område och vilken effekt händelsen kan ha.
För ytterligare undersökningar, involvera lämpliga personer. Du kan inkludera en incidenthanterare, säkerhetsansvarig eller arbetsbelastningscentrerade leads. För att hålla prioriteringen fokuserad undantar du personer som ligger utanför problemets omfattning. Ibland undersöker separata team incidenten. Det kan finnas ett team som först undersöker problemet och försöker åtgärda incidenten, och ett annat specialiserat team som kan utföra kriminalteknik för en djupgående undersökning för att ta reda på stora problem. Du kan placera arbetsbelastningsmiljön i karantän så att kriminalteknikteamet kan utföra sina undersökningar. I vissa fall kan samma team hantera hela undersökningen.
I den inledande fasen ansvarar triageteamet för att fastställa den potentiella vektorn och dess effekt på systemets konfidentialitet, integritet och tillgänglighet (även kallat CIA).
Inom kategorierna för CIA tilldelar du en initial allvarlighetsgrad som anger djupet av skadan och hur brådskande reparationen är. Den här nivån förväntas ändras över tid när mer information identifieras i triagenivåerna.
I identifieringsfasen är det viktigt att fastställa ett omedelbart åtgärds- och kommunikationsplaner. Finns det några ändringar i systemets körningstillstånd? Hur kan attacken begränsas för att stoppa ytterligare utnyttjande? Behöver teamet skicka ut intern eller extern kommunikation, till exempel ett ansvarsfullt avslöjande? Överväg identifierings- och svarstid. Du kan vara juridiskt skyldig att rapportera vissa typer av överträdelser till en tillsynsmyndighet inom en viss tidsperiod, vilket ofta är timmar eller dagar.
Om du väljer att stänga av systemet leder nästa steg till arbetsbelastningens haveriberedskapsprocess (DR).
Om du inte stänger av systemet bestämmer du hur du åtgärdar incidenten utan att påverka systemets funktioner.
Återställa från en incident
Behandla en säkerhetsincident som en katastrof. Om reparationen kräver fullständig återställning använder du lämpliga DR-mekanismer ur ett säkerhetsperspektiv. Återställningsprocessen måste förhindra risk för upprepning. Annars återinför återställning från en skadad säkerhetskopia problemet igen. Omdistribution av ett system med samma säkerhetsrisk leder till samma incident. Verifiera steg och processer för redundans och återställning efter fel.
Om systemet fortfarande fungerar utvärderar du effekten på de delar av systemet som körs. Fortsätt att övervaka systemet för att säkerställa att andra tillförlitlighets- och prestandamål uppfylls eller justeras genom att implementera lämpliga nedbrytningsprocesser. Äventyra inte sekretessen på grund av riskreducering.
Diagnos är en interaktiv process tills vektorn och en potentiell korrigering och återställning identifieras. Efter diagnosen arbetar teamet med reparation, vilket identifierar och tillämpar den nödvändiga korrigeringen inom en acceptabel period.
Återställningsmått mäter hur lång tid det tar att åtgärda ett problem. I händelse av en avstängning kan det vara brådskande när det gäller reparationstiderna. För att stabilisera systemet tar det tid att tillämpa korrigeringar, korrigeringar och tester och distribuera uppdateringar. Fastställa inneslutningsstrategier för att förhindra ytterligare skador och spridningen av incidenten. Utveckla utrotningsprocedurer för att helt ta bort hotet från miljön.
Kompromiss: Det finns en kompromiss mellan tillförlitlighetsmål och reparationstider. Under en incident är det troligt att du inte uppfyller andra icke-funktionella eller funktionella krav. Du kan till exempel behöva inaktivera delar av systemet när du undersöker incidenten, eller så kan du till och med behöva ta hela systemet offline tills du fastställer incidentens omfattning. Företagsbeslutsfattarna måste uttryckligen bestämma vilka godtagbara mål som är under incidenten. Ange tydligt den person som är ansvarig för det beslutet.
Lär dig av en incident
En incident upptäcker luckor eller sårbara punkter i en design eller implementering. Det är en förbättringsmöjlighet som drivs av lektioner i tekniska designaspekter, automatisering, produktutvecklingsprocesser som omfattar testning och effektiviteten i incidenthanteringsprocessen. Underhålla detaljerade incidentposter, inklusive åtgärder som vidtagits, tidslinjer och resultat.
Vi rekommenderar starkt att du genomför strukturerade granskningar efter incident, till exempel rotorsaksanalys och retrospektiv. Spåra och prioritera resultatet av dessa granskningar och överväg att använda det du lär dig i framtida arbetsbelastningsdesign.
Förbättringsplaner bör omfatta uppdateringar av säkerhetsgranskningar och -testning, till exempel bcdr-detaljgranskningar (business continuity and disaster recovery). Använd säkerhetskompromiss som ett scenario för att utföra ett BCDR-detaljtest. Detaljgranskningar kan verifiera hur de dokumenterade processerna fungerar. Det bör inte finnas flera spelböcker för incidenthantering. Använd en enda källa som du kan justera baserat på incidentens storlek och hur utbredd eller lokaliserad effekten är. Övningar baseras på hypotetiska situationer. Utför övningar i en miljö med låg risk och inkludera inlärningsfasen i övningarna.
Genomför granskningar efter incident, eller postmortems, för att identifiera svagheter i svarsprocessen och förbättringsområden. Baserat på de lärdomar du lär dig av incidenten uppdaterar du planen för incidenthantering (IRP) och säkerhetskontrollerna.
Definiera en kommunikationsplan
Implementera en kommunikationsplan för att meddela användarna om ett avbrott och informera interna intressenter om reparationen och förbättringarna. Andra personer i din organisation måste meddelas om ändringar i arbetsbelastningens säkerhetsbaslinje för att förhindra framtida incidenter.
Generera incidentrapporter för internt bruk och, om det behövs, för regelefterlevnad eller juridiska ändamål. Anta också en standardformatrapport (en dokumentmall med definierade avsnitt) som SOC-teamet använder för alla incidenter. Se till att varje incident har en associerad rapport innan du avslutar undersökningen.
Azure-underlättande
Microsoft Sentinel är en SIEM- och SOAR-lösning. Det är en enda lösning för aviseringsidentifiering, hotsynlighet, proaktiv jakt och hotsvar. Mer information finns i Vad är Microsoft Sentinel?
Se till att Azure-registreringsportalen innehåller administratörskontaktinformation så att säkerhetsåtgärder kan meddelas direkt via en intern process. Mer information finns i Uppdatera meddelandeinställningar.
Mer information om hur du upprättar en utsedd kontaktpunkt som tar emot Azure-incidentaviseringar från Microsoft Defender för molnet finns i Konfigurera e-postaviseringar för säkerhetsaviseringar.
Organisatorisk anpassning
Cloud Adoption Framework för Azure ger vägledning om planering av incidenthantering och säkerhetsåtgärder. Mer information finns i Säkerhetsåtgärder.
Relaterade länkar
- Skapa incidenter automatiskt från Microsofts säkerhetsaviseringar
- Genomför hotjakt från slutpunkt till slutpunkt med hjälp av jaktfunktionen
- Konfigurera e-postaviseringar för säkerhetsmeddelanden
- Översikt över incidenthantering
- Incidentberedskap för Microsoft Azure
- Navigera och undersöka incidenter i Microsoft Sentinel
- Säkerhetskontroll: Incidenthantering
- SOAR-lösningar i Microsoft Sentinel
- Utbildning: Introduktion till Azure-incidentberedskap
- Uppdatera meddelandeinställningarna för Azure-portalen
- Vad är en SOC?
- Vad är Microsoft Sentinel?
Säkerhetskontrollista
Se den fullständiga uppsättningen rekommendationer.