Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Datainmatning är processen att samla in, läsa och förbereda data från olika källor, till exempel filer, databaser, API:er eller molntjänster så att de kan användas i underordnade program. I praktiken följer den här processen arbetsflödet Extract-Transform-Load (ETL):
- Extrahera data från den ursprungliga källan, oavsett om det är en PDF, Word-dokument, ljudfil eller webb-API.
- Transformera data genom att rensa, segmentera, berika eller konvertera format.
- Läs in data till ett mål som en databas, ett vektorlager eller en AI-modell för hämtning och analys.
För AI- och maskininlärningsscenarier, särskilt Retrieval-Augmented Generation (RAG), handlar datainmatning inte bara om att konvertera data från ett format till ett annat. Det handlar om att göra data användbara för intelligenta program. Det innebär att representera dokument på ett sätt som bevarar deras struktur och betydelse, dela upp dem i hanterbara segment, berika dem med metadata eller inbäddningar och lagra dem så att de kan hämtas snabbt och korrekt.
Varför datainmatning är viktigt för AI-program
Anta att du skapar en RAG-baserad chattrobot som hjälper anställda att hitta information i företagets stora samling dokument. Dessa dokument kan innehålla PDF-filer, Word-filer, PowerPoint-presentationer och webbsidor spridda över olika system.
Chattroboten måste förstå och söka igenom tusentals dokument för att ge korrekta, kontextuella svar. Men råa dokument är inte lämpliga för AI-system. Du måste omvandla dem till ett format som bevarar innebörden samtidigt som du gör dem sökbara och hämtningsbara.
Det är här datainmatningen blir kritisk. Du måste extrahera text från olika filformat, dela upp stora dokument i mindre segment som passar inom AI-modellgränser, berika innehållet med metadata, generera inbäddningar för semantisk sökning och lagra allt på ett sätt som möjliggör snabb hämtning. Varje steg kräver noggrant övervägande av hur du bevarar den ursprungliga innebörden och kontexten.
Biblioteket Microsoft.Extensions.DataIngestion
📦 Microsoft.Extensions.DataIngestion-paketet tillhandahåller grundläggande .NET-byggstenar för datainmatning. Det gör det möjligt för utvecklare att läsa, bearbeta och förbereda dokument för AI- och maskininlärningsarbetsflöden, särskilt Retrieval-Augmented generation (RAG).
Med dessa byggstenar kan du skapa robusta, flexibla och intelligenta datainmatningspipelines som är skräddarsydda för dina programbehov:
- Enhetlig dokumentrepresentation: Representera alla filtyper (till exempel PDF, Image eller Microsoft Word) i ett konsekvent format som fungerar bra med stora språkmodeller.
- Flexibel datainmatning: Läs dokument från både molntjänster och lokala källor med flera inbyggda läsare, vilket gör det enkelt att hämta data oavsett var det finns.
- Inbyggda AI-förbättringar: Berika innehåll automatiskt med sammanfattningar, attitydanalys, extrahering av nyckelord och klassificering, förbereda dina data för intelligenta arbetsflöden.
- Anpassningsbara segmenteringsstrategier: Dela upp dokument i segment med hjälp av tokenbaserade, avsnittsbaserade eller semantiska metoder, så att du kan optimera för dina hämtnings- och analysbehov.
- Produktionsklar lagring: Lagra bearbetade segment i populära vektordatabaser och dokumentlager, med stöd för inbäddningsgenerering, vilket gör dina pipelines redo för verkliga scenarier.
- End-to-end pipelinesammansättning: Länka samman läsare, processorer, chunkare och skrivare med IngestionPipeline<T> API:et, minska skräpkod och gör det enkelt att skapa, anpassa och utöka fullständiga arbetsflöden.
- Prestanda och skalbarhet: Dessa komponenter är utformade för skalbar databearbetning och kan hantera stora mängder data effektivt, vilket gör dem lämpliga för program i företagsklass.
Alla dessa komponenter är öppna och utökningsbara avsiktligt. Du kan lägga till anpassad logik och nya anslutningsappar och utöka systemet för att stödja nya AI-scenarier. Genom att standardisera hur dokument representeras, bearbetas och lagras kan .NET-utvecklare skapa tillförlitliga, skalbara och underhållsbara datapipelines utan att "återuppfinna hjulet" för varje projekt.
Byggd på stabila fundament
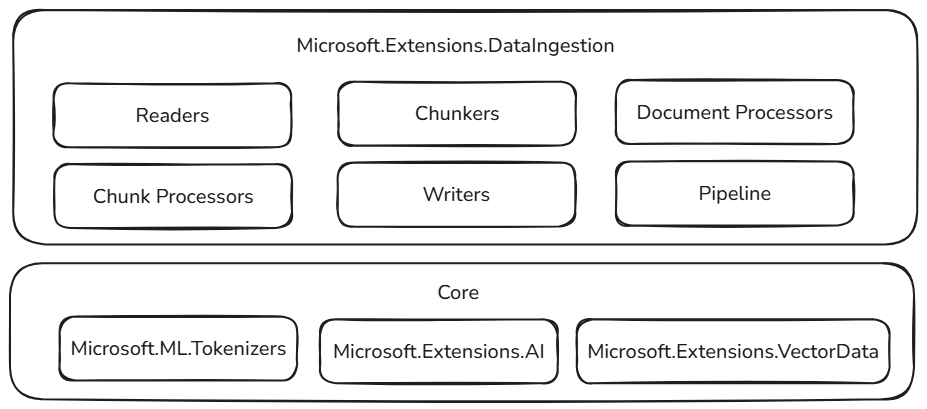
Dessa byggstenar för datainmatning bygger på beprövade och utökningsbara komponenter i .NET-ekosystemet, vilket säkerställer tillförlitlighet, samverkan och sömlös integrering med befintliga AI-arbetsflöden:
- Microsoft.ML.Tokenizers: Tokenizers utgör grunden för segmentering av dokument baserat på token. Detta möjliggör exakt uppdelning av innehåll, vilket är viktigt för att förbereda data för stora språkmodeller och optimera hämtningsstrategier.
- Microsoft.Extensions.AI: Den här uppsättningen bibliotek driver berikningstransformeringar med hjälp av stora språkmodeller. Det möjliggör funktioner som sammanfattning, attitydanalys, extrahering av nyckelord och inbäddningsgenerering, vilket gör det enkelt att förbättra dina data med intelligenta insikter.
- Microsoft.Extensions.VectorData: Den här uppsättningen bibliotek erbjuder ett konsekvent gränssnitt för lagring av bearbetade segment i en mängd olika vektorlager, inklusive Qdrant, Azure SQL, CosmosDB, MongoDB, ElasticSearch och många fler. Detta säkerställer att dina datapipelines är klara för produktion och kan skalas upp över olika lagringssystem.
Förutom välbekanta mönster och verktyg bygger dessa abstraktioner på redan utökningsbara komponenter. Plugin-funktioner och samverkan är av största vikt, så i takt med att resten av .NET AI-ekosystemet växer växer även funktionerna i komponenterna för datainmatning. Den här metoden gör det möjligt för utvecklare att enkelt integrera nya leverantörer, berikanden och lagringsalternativ, så att deras pipelines blir framtidsklara och anpassningsbara för att utveckla AI-scenarier.
Byggstenar för datainmatning
Biblioteket Microsoft.Extensions.DataIngestion bygger på flera viktiga komponenter som fungerar tillsammans för att skapa en fullständig databehandlingspipeline. Det här avsnittet utforskar varje komponent och hur de passar ihop.
Dokument och dokumentläsare
Vid grunden av biblioteket är IngestionDocument-typen, som ger ett enhetligt sätt att representera alla filformat utan att förlora viktig information.
IngestionDocument är Markdown-centrerad eftersom stora språkmodeller fungerar bäst med Markdown-formatering.
Abstraktionen IngestionDocumentReader hanterar inläsning av dokument från olika källor, oavsett om det är lokala filer eller strömmar. Några läsare är tillgängliga:
Fler läsare (inklusive LlamaParse och Azure Document Intelligence) kommer att läggas till i framtiden.
Den här designen innebär att du kan arbeta med dokument från olika källor med samma konsekventa API, vilket gör koden mer underhållsbar och flexibel.
Dokumentbearbetning
Dokumentbehandlare tillämpar transformeringar på dokumentnivå för att förbättra och förbereda innehåll. Biblioteket tillhandahåller ImageAlternativeTextEnricher klassen som en inbyggd processor som använder stora språkmodeller för att generera beskrivande alternativ text för bilder i dokument.
Segment och segmenteringsstrategier
När du har läst in ett dokument måste du vanligtvis dela upp det i mindre delar som kallas segment. Segment representerar underavsnitt i ett dokument som effektivt kan bearbetas, lagras och hämtas av AI-system. Den här segmenteringsprocessen är viktig för hämtning av förhöjda generationscenarier där du snabbt behöver hitta de mest relevanta informationsdelarna.
Biblioteket innehåller flera segmenteringsstrategier som passar olika användningsfall:
- ** Sidhuvudbaserad segmentering för att dela upp enligt sidhuvuden.
- Avsnittsbaserad segmentering som ska delas upp i avsnitt (till exempel sidor).
- Semantisk medveten segmentering för att bevara fullständiga tankar.
Dessa segmenteringsstrategier bygger på biblioteket Microsoft.ML.Tokenizers för att på ett intelligent sätt dela upp text i lämpliga delar som fungerar bra med stora språkmodeller. Rätt segmenteringsstrategi beror på dina dokumenttyper och hur du planerar att hämta information.
Tokenizer tokenizer = TiktokenTokenizer.CreateForModel("gpt-5");
IngestionChunkerOptions options = new(tokenizer)
{
MaxTokensPerChunk = 2000,
OverlapTokens = 0
};
IngestionChunker<string> chunker = new HeaderChunker(options);
Segmentbearbetning och berikning
När dokument har delats upp i segment kan du använda processorer för att förbättra och utöka innehållet. Segmentprocessorer fungerar på enskilda delar och kan utföra:
-
Innehållsberikning inklusive automatiska sammanfattningar (
SummaryEnricher), attitydanalys (SentimentEnricher) och extrahering av nyckelord (KeywordEnricher). -
Klassificering för automatiserad innehållskategorisering baserat på fördefinierade kategorier (
ClassificationEnricher).
Dessa processorer använder Microsoft.Extensions.AI.Abstractions för att utnyttja stora språkmodeller för intelligent innehållstransformering, vilket gör dina segment mer användbara för underordnade AI-program.
Dokumentskrivare och lagring
IngestionChunkWriter<T> lagrar bearbetade segment i ett datalager för senare hämtning. Biblioteket, som använder Microsoft.Extensions.AI och Microsoft.Extensions.VectorData, tillhandahåller VectorStoreWriter<T> klassen. Den här komponenten stöder lagring av delar i vilket vektorlager som helst som stöds av Microsoft.Extensions.VectorData.
Vektorlager innehåller populära alternativ som Qdrant, SQL Server, CosmosDB, MongoDB och ElasticSearch. Mer information om leverantörer finns i Out-of-the-box Vector Store-leverantörer. (Trots att "SemanticKernel" ingår i paketnamnen har dessa leverantörer inget att göra med semantisk kernel och kan användas var som helst i .NET, inklusive Agent Framework.)
Skrivaren kan också automatiskt generera inbäddningar för dina segment med hjälp av Microsoft.Extensions.AI, förbereda dem för semantisk sökning och hämtningsscenarier.
OpenAIClient openAIClient = new(
new ApiKeyCredential(Environment.GetEnvironmentVariable("GITHUB_TOKEN")!),
new OpenAIClientOptions { Endpoint = new Uri("https://models.github.ai/inference") });
IEmbeddingGenerator<string, Embedding<float>> embeddingGenerator =
openAIClient.GetEmbeddingClient("text-embedding-3-small").AsIEmbeddingGenerator();
using SqliteVectorStore vectorStore = new(
"Data Source=vectors.db;Pooling=false",
new()
{
EmbeddingGenerator = embeddingGenerator
});
// The writer requires the embedding dimension count to be specified.
// For OpenAI's `text-embedding-3-small`, the dimension count is 1536.
using VectorStoreWriter<string> writer = new(vectorStore, dimensionCount: 1536);
Dokumentbearbetningspipeline
Med API:et IngestionPipeline<T> kan du länka samman de olika komponenterna för datainmatning till ett fullständigt arbetsflöde. Du kan kombinera:
- Läsare för att läsa in dokument från olika källor.
- Processorer för att transformera och berika dokumentinnehåll.
- Segment för att dela upp dokument i hanterbara delar.
- Författare för att lagra de slutliga resultaten i ditt valda datalager.
Den här pipelinemetoden minskar exempelkoden och gör det enkelt att skapa, testa och underhålla komplexa arbetsflöden för datainmatning.
using IngestionPipeline<string> pipeline = new(reader, chunker, writer, loggerFactory: loggerFactory)
{
DocumentProcessors = { imageAlternativeTextEnricher },
ChunkProcessors = { summaryEnricher }
};
await foreach (var result in pipeline.ProcessAsync(new DirectoryInfo("."), searchPattern: "*.md"))
{
Console.WriteLine($"Completed processing '{result.DocumentId}'. Succeeded: '{result.Succeeded}'.");
}
Ett enda dokumentinmatningsfel bör inte få hela pipelinen att misslyckas. Det är därför IngestionPipeline<T>.ProcessAsync implementerar partiell framgång genom att returnera IAsyncEnumerable<IngestionResult>. Anroparen ansvarar för att hantera eventuella fel (till exempel genom att försöka igen misslyckade dokument eller stoppa det första felet).
Samarbeta med oss på GitHub
Källan för det här innehållet finns på GitHub, där du även kan skapa och granska ärenden och pull-begäranden. Se vår deltagarguide för mer information.