Anteckning
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Dricks
Det här innehållet är ett utdrag från eBook, Architecting Cloud Native .NET Applications for Azure, tillgängligt på .NET Docs eller som en kostnadsfri nedladdningsbar PDF som kan läsas offline.

Relationella (SQL) och icke-relationella (NoSQL) är två typer av databassystem som vanligtvis implementeras i molnbaserade appar. De är byggda på olika sätt, lagrar data på olika sätt och används på olika sätt. I det här avsnittet ska vi titta på båda. Senare i det här kapitlet tittar vi på en ny databasteknik med namnet NewSQL.
Relationsdatabaser har varit en utbredd teknik i årtionden. De är mogna, beprövade och allmänt implementerade. Konkurrerande databasprodukter, verktyg och expertis finns i överflöd. Relationsdatabaser tillhandahåller ett lager med relaterade datatabeller. Dessa tabeller har ett fast schema, använder SQL (Structured Query Language) för att hantera data och stöder ACID-garantier: atomitet, konsekvens, isolering och hållbarhet.
NoSQL-databaser refererar till högpresterande, icke-relationella datalager. De utmärker sig i sin användarvänlighet, skalbarhet, motståndskraft och tillgänglighetsegenskaper. I stället för att koppla tabeller med normaliserade data lagrar NoSQL ostrukturerade eller halvstrukturerade data, ofta i nyckel/värde-par eller JSON-dokument. NoSQL-databaser ger vanligtvis inte ACID-garantier utanför omfånget för en enskild databaspartition. Tjänster med hög volym som kräver svarstid under andra sekund gynnar NoSQL-datalager.
Effekten av NoSQL-tekniker för distribuerade molnbaserade system kan inte överskattas. Spridningen av ny datateknik i det här utrymmet har stört lösningar som en gång uteslutande förlitade sig på relationsdatabaser.
NoSQL-databaser innehåller flera olika modeller för att komma åt och hantera data, som var och en passar för specifika användningsfall. Bild 5-9 visar fyra vanliga modeller.

Bild 5–9: Datamodeller för NoSQL-databaser
| Modell | Egenskaper |
|---|---|
| Dokumentarkiv | Data och metadata lagras hierarkiskt i JSON-baserade dokument i databasen. |
| Nyckelvärdeslager | Det enklaste av NoSQL-databaserna är att data representeras som en samling nyckel/värde-par. |
| Wide-Column Butik | Relaterade data lagras som en uppsättning kapslade nyckel/värde-par i en enda kolumn. |
| Graflager | Data lagras i en grafstruktur som nod-, kant- och dataegenskaper. |
CAP- och PACELC-teoremer
Som ett sätt att förstå skillnaderna mellan dessa typer av databaser bör du överväga CAP-satsen, en uppsättning principer som tillämpas på distribuerade system som lagrar tillstånd. Bild 5–10 visar de tre egenskaperna för CAP-satsen.
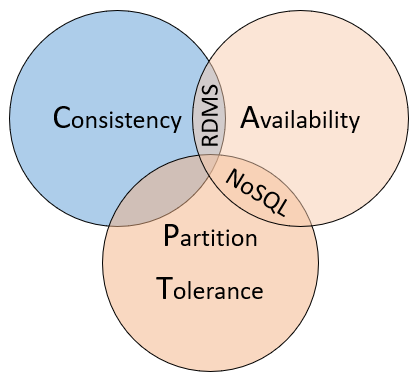
Bild 5-10. CAP-satsen
Satsen anger att distribuerade datasystem erbjuder en kompromiss mellan konsekvens, tillgänglighet och partitionstolerans. Och att alla databaser bara kan garantera två av de tre egenskaperna:
Konsekvens. Varje nod i klustret svarar med de senaste data, även om systemet måste blockera begäran tills alla repliker uppdateras. Om du frågar efter ett "konsekvent system" för ett objekt som för närvarande uppdateras väntar du på det svaret tills alla repliker har uppdaterats. Du får dock de mest aktuella data. Det bör förstås att termen "konsekvens" eftersom den används i samband med CAP-sats har en teknisk betydelse som skiljer sig från hur "konsekvens" definieras i samband med ACID-garantier.
Tillgänglighet. Varje begäran som tas emot av en nod som inte misslyckas i systemet måste resultera i ett svar. Enkelt uttryckt, om du frågar ett "tillgängligt system" för ett objekt som uppdateras får du det bästa möjliga svaret som tjänsten kan ge just då. Observera dock att "tillgänglighet" som definieras av CAP-sats skiljer sig tekniskt från "hög tillgänglighet" eftersom det är konventionellt känt för distribuerade system.
Partitionstolerans. Garanterar att systemet fortsätter att fungera även om en replikerad datanod misslyckas eller förlorar anslutningen till andra replikerade datanoder.
CAP-satsen förklarar de kompromisser som är kopplade till att hantera konsekvens och tillgänglighet under en nätverkspartition. men kompromisser med avseende på konsekvens och prestanda finns också med avsaknaden av en nätverkspartition.
Kommentar
Även om du väljer tillgänglighet framför konsekvens, i tider av nätverkspartition, kommer tillgängligheten att bli lidande. CAP-tillgängligt system är mer tillgängligt för vissa av sina klienter, men det är inte nödvändigtvis "högtillgängligt" för alla sina klienter.
CAP-sats utökas ofta ytterligare till PACELC för att förklara kompromisserna mer omfattande. CAP-satsen är särskilt relevant i tillfälligt anslutna miljöer, till exempel sådana som rör Sakernas Internet (IoT), miljöövervakning och mobila program. I dessa sammanhang kan enheter partitioneras på grund av utmanande fysiska förhållanden, till exempel strömavbrott eller när de kommer in i trånga utrymmen som hissar. För distribuerade system, till exempel molnprogram, är det lämpligare att använda PACELC-satsen, som är mer omfattande och tar hänsyn till kompromisser som svarstid och konsekvens även i avsaknad av nätverkspartitioner.
Relationsdatabaser ger vanligtvis konsekvens och tillgänglighet, men inte partitionstolerans. De etableras vanligtvis på en enskild server och skalas lodrätt genom att lägga till fler resurser på datorn.
Många relationsdatabassystem stöder inbyggda replikeringsfunktioner där kopior av den primära databasen kan göras till andra sekundära serverinstanser. Skrivåtgärder görs till den primära instansen och replikeras till var och en av sekundärfilerna. Vid ett fel kan den primära instansen redundansväxla till en sekundär för att ge hög tillgänglighet. Sekundärfiler kan också användas för att distribuera läsåtgärder. Skrivåtgärder går alltid mot den primära repliken, men läsåtgärder kan dirigeras till någon av sekundärfilerna för att minska systembelastningen.
Data kan också partitioneras horisontellt över flera noder, till exempel med horisontell partitionering. Men horisontell partitionering ökar avsevärt driftskostnaderna genom att spotta data över många delar som inte enkelt kan kommunicera. Det kan vara kostsamt och tidskrävande att hantera. Relationsfunktioner som inkluderar tabellkopplingar, transaktioner och referensintegritet kräver kraftiga prestandapåföljder i fragmenterade distributioner.
Replikeringskonsekvens och mål för återställningspunkter kan justeras genom att konfigurera om replikeringen sker synkront eller asynkront. Om datarepliker skulle förlora nätverksanslutningen i ett "mycket konsekvent" eller synkront relationsdatabaskluster skulle du inte kunna skriva till databasen. Systemet avvisar skrivåtgärden eftersom den inte kan replikera ändringen till den andra datarepliken. Varje datareplik måste uppdateras innan transaktionen kan slutföras.
NoSQL-databaser stöder vanligtvis hög tillgänglighet och partitionstolerans. De skalas ut horisontellt, ofta över råvaruservrar. Den här metoden ger en enorm tillgänglighet, både inom och över geografiska regioner till en reducerad kostnad. Du partitionerar och replikerar data mellan dessa datorer eller noder, vilket ger redundans och feltolerans. Konsekvens justeras vanligtvis genom konsensusprotokoll eller kvorummekanismer. De ger mer kontroll när du navigerar i kompromisser mellan justering av synkron kontra asynkron replikering i relationssystem.
Om datarepliker skulle förlora anslutningen i ett NoSQL-databaskluster med hög tillgänglighet kan du fortfarande slutföra en skrivåtgärd till databasen. Databasklustret skulle tillåta skrivåtgärden och uppdatera varje datareplik när den blir tillgänglig. NoSQL-databaser som stöder flera skrivbara repliker kan ytterligare stärka hög tillgänglighet genom att undvika behovet av redundans vid optimering av mål för återställningstid.
Moderna NoSQL-databaser implementerar vanligtvis partitioneringsfunktioner som en funktion i systemdesignen. Partitionshantering är ofta inbyggt i databasen, och routning uppnås genom placeringstips – som ofta kallas partitionsnycklar. Med en flexibel datamodell kan NoSQL-databaserna minska belastningen på schemahanteringen och förbättra tillgängligheten vid distribution av programuppdateringar som kräver ändringar i datamodellen.
Hög tillgänglighet och massiv skalbarhet är ofta viktigare för verksamheten än relationstabellkopplingar och referensintegritet. Utvecklare kan implementera tekniker och mönster som Sagas, CQRS och asynkrona meddelanden för att ta till sig eventuell konsekvens.
I dag måste man vara försiktig när man överväger begränsningarna för den gemensamma jordbrukspolitiken. En ny typ av databas, kallad NewSQL, har dykt upp som utökar relationsdatabasmotorn för att stödja både horisontell skalbarhet och skalbar prestanda för NoSQL-system.
Överväganden för relations- och NoSQL-system
Baserat på specifika datakrav kan en molnbaserad mikrotjänst implementera ett relations-, NoSQL-datalager eller både och.
| Överväg ett NoSQL-datalager när: | Överväg en relationsdatabas när: |
|---|---|
| Du har arbetsbelastningar med stora volymer som kräver förutsägbar svarstid i stor skala (till exempel svarstid mätt i millisekunder medan du utför miljontals transaktioner per sekund) | Din arbetsbelastningsvolym passar vanligtvis inom tusentals transaktioner per sekund |
| Dina data är dynamiska och ändras ofta | Dina data är mycket strukturerade och kräver referensintegritet |
| Relationer kan vara avnormaliserade datamodeller | Relationer uttrycks via tabellkopplingar på normaliserade datamodeller |
| Datahämtning är enkel och uttrycks utan tabellkopplingar | Du arbetar med komplexa frågor och rapporter |
| Data replikeras vanligtvis mellan geografiska områden och kräver bättre kontroll över konsekvens, tillgänglighet och prestanda | Data är vanligtvis centraliserade eller kan replikeras asynkront |
| Ditt program kommer att distribueras till maskinvara för råvaror, till exempel med offentliga moln | Ditt program kommer att distribueras till stor, avancerad maskinvara |
I nästa avsnitt ska vi utforska de alternativ som är tillgängliga i Azure-molnet för att lagra och hantera dina molnbaserade data.
Databas som en tjänst
Till att börja med kan du etablera en virtuell Azure-dator och installera valfri databas för varje tjänst. Även om du skulle ha fullständig kontroll över miljön skulle du avstå från många inbyggda funktioner i molnplattformen. Du skulle också ansvara för att hantera den virtuella datorn och databasen för varje tjänst. Den här metoden kan snabbt bli tidskrävande och dyr.
I stället föredrar molnbaserade program datatjänster som exponeras som en databas som en tjänst (DBaaS). Tjänsterna hanteras fullständigt av en molnleverantör och ger inbyggd säkerhet, skalbarhet och övervakning. I stället för att äga tjänsten använder du den bara som en säkerhetskopieringstjänst. Leverantören driver resursen i stor skala och ansvarar för prestanda och underhåll.
De kan konfigureras mellan molntillgänglighetszoner och -regioner för att uppnå hög tillgänglighet. De stöder alla just-in-time-kapacitet och en betala per användning-modell. Azure har olika typer av alternativ för hanterade datatjänster, var och en med specifika fördelar.
Vi ska först titta på relationsbaserade DBaaS-tjänster som är tillgängliga i Azure. Du ser att Microsofts flaggskeppsdatabas för SQL Server är tillgänglig tillsammans med flera alternativ med öppen källkod. Sedan pratar vi om NoSQL-datatjänsterna i Azure.
Relationsdatabaser i Azure
För molnbaserade mikrotjänster som kräver relationsdata erbjuder Azure fyra hanterade relationsdatabaser som en tjänst (DBaaS), som visas i bild 5–11.

Bild 5-11. Hanterade relationsdatabaser som är tillgängliga i Azure
I föregående bild bör du notera hur var och en sitter på en gemensam DBaaS-infrastruktur som har viktiga funktioner utan extra kostnad.
Dessa funktioner är särskilt viktiga för organisationer som etablerar ett stort antal databaser, men som har begränsade resurser för att administrera dem. Du kan etablera en Azure-databas på några minuter genom att välja mängden bearbetningskärnor, minne och underliggande lagring. Du kan skala databasen direkt och dynamiskt justera resurser med liten eller ingen stilleståndstid.
Azure SQL Database
Utvecklingsteam med expertis inom Microsoft SQL Server bör överväga Azure SQL Database. Det är en fullständigt hanterad relationsdatabas som en tjänst (DBaaS) baserat på Microsoft SQL Server Database Engine. Tjänsten delar många funktioner som finns i den lokala versionen av SQL Server och kör den senaste stabila versionen av SQL Server Database Engine.
För användning med en molnbaserad mikrotjänst är Azure SQL Database tillgängligt med tre distributionsalternativ:
En enskild databas representerar en fullständigt hanterad SQL Database som körs på en Azure SQL Database-server i Azure-molnet. Databasen anses innehålla eftersom den inte har några konfigurationsberoenden på den underliggande databasservern.
En hanterad instans är en fullständigt hanterad instans av Microsoft SQL Server Database Engine som ger nästan 100 % kompatibilitet med en lokal SQL Server. Det här alternativet stöder större databaser, upp till 35 TB och placeras i ett virtuellt Azure-nätverk för bättre isolering.
Serverlös Azure SQL Database är en beräkningsnivå för en enskild databas som automatiskt skalar baserat på efterfrågan på arbetsbelastningar. Den fakturerar endast för den mängd beräkning som används per sekund. Tjänsten passar bra för arbetsbelastningar med tillfälliga, oförutsägbara användningsmönster, varvat med perioder av inaktivitet. Den serverlösa beräkningsnivån pausar också automatiskt databaser under inaktiva perioder så att endast lagringsavgifter debiteras. Den återupptas automatiskt när aktiviteten returneras.
Utöver den traditionella Microsoft SQL Server-stacken har Azure även hanterade versioner av tre populära databaser med öppen källkod.
Databaser med öppen källkod i Azure
Relationsdatabaser med öppen källkod har blivit ett populärt val för molnbaserade program. Många företag föredrar dem framför kommersiella databasprodukter, särskilt för kostnadsbesparingar. Många utvecklingsteam har sin flexibilitet, community-backade utveckling och ekosystem med verktyg och tillägg. Databaser med öppen källkod kan distribueras över flera molnleverantörer, vilket minimerar problemet med "leverantörslåsning".
Utvecklare kan enkelt vara värdar för valfri databas med öppen källkod på en virtuell Azure-dator. Den här metoden ger fullständig kontroll, men ger dig tillgång till hantering, övervakning och underhåll av databasen och den virtuella datorn.
Microsoft fortsätter dock sitt åtagande att hålla Azure en "öppen plattform" genom att erbjuda flera populära databaser med öppen källkod som fullständigt hanterade DBaaS-tjänster.
Azure-databas för MySQL
MySQL är en relationsdatabas med öppen källkod och en grundpelare för program som bygger på LAMP-programvarustacken. Den är ofta utvald för läsintensiva arbetsbelastningar och används av många stora organisationer, inklusive Facebook, Twitter och YouTube. Community-utgåvan är tillgänglig kostnadsfritt, medan enterprise-utgåvan kräver ett licensköp. Produkten skapades ursprungligen 1995 och köptes av Sun Microsystems 2008. Oracle förvärvade Sun och MySQL 2010.
Azure Database for MySQL är en hanterad relationsdatabastjänst baserad på MySQL Server-motorn med öppen källkod. Den använder MySQL Community Edition. Azure MySQL-servern är den administrativa platsen för tjänsten. Det är samma MySQL-servermotor som används för lokala distributioner. Motorn kan skapa en enskild databas per server eller flera databaser per server som delar resurser. Du kan fortsätta att hantera data med samma verktyg med öppen källkod utan att behöva lära dig nya kunskaper eller hantera virtuella datorer.
Azure-databas för MariaDB
MariaDB Server är en annan populär databasserver med öppen källkod. Det skapades som en förgrening av MySQL när Oracle köpte Sun Microsystems, som ägde MySQL. Avsikten var att säkerställa att MariaDB förblev öppen källkod. Eftersom MariaDB är en förgrening av MySQL är data- och tabelldefinitionerna kompatibla och klientprotokollen, strukturerna och API:erna är nära sammansvetsade.
MariaDB har en stark gemenskap och används av många stora företag. Oracle fortsätter att underhålla, förbättra och stödja MySQL, men MariaDB Foundation hanterar MariaDB, vilket ger offentliga bidrag till produkten och dokumentationen.
Azure Database for MariaDB är en fullständigt hanterad relationsdatabas som en tjänst i Azure-molnet. Tjänsten baseras på MariaDB community edition-servermotorn. Den kan hantera verksamhetskritiska arbetsbelastningar med förutsägbar prestanda och dynamisk skalbarhet.
Azure-databasen för PostgreSQL
PostgreSQL är en relationsdatabas med öppen källkod med över 30 års aktiv utveckling. PostgreSQL har ett starkt rykte för tillförlitlighet och dataintegritet. Den är funktionsrik, SQL-kompatibel och anses vara mer högpresterande än MySQL – särskilt för arbetsbelastningar med komplexa frågor och tunga skrivningar. Många stora företag som Apple, Red Hat och Fujitsu har byggt produkter med PostgreSQL.
Azure Database for PostgreSQL är en fullständigt hanterad relationsdatabastjänst som baseras på Postgres-databasmotorn med öppen källkod. Tjänsten stöder många utvecklingsplattformar, inklusive C++, Java, Python, Node, C#och PHP. Du kan migrera PostgreSQL-databaser till den med hjälp av kommandoradsgränssnittsverktyget eller Azure Data Migration Service.
Azure Database for PostgreSQL är tillgängligt med två distributionsalternativ:
Distributionsalternativet Enskild server är en central administrativ plats för flera databaser som du kan distribuera många databaser till. Prissättningen är strukturerad per server baserat på kärnor och lagring.
Alternativet Hyperskala (Citus) drivs av Citus Data-teknik. Det ger höga prestanda genom att horisontellt skala en enskild databas över hundratals noder för att leverera snabba prestanda och skalning. Med det här alternativet kan motorn anpassa mer data i minnet, parallellisera frågor över hundratals noder och indexera data snabbare.
NoSQL-data i Azure
Cosmos DB är en fullständigt hanterad, globalt distribuerad NoSQL-databastjänst i Azure-molnet. Det har antagits av många stora företag över hela världen, inklusive Coca-Cola, Skype, ExxonMobil och Liberty Mutual.
Om dina tjänster kräver snabba svar var som helst i världen, hög tillgänglighet eller elastisk skalbarhet är Cosmos DB ett bra val. Bild 5–12 visar Cosmos DB.
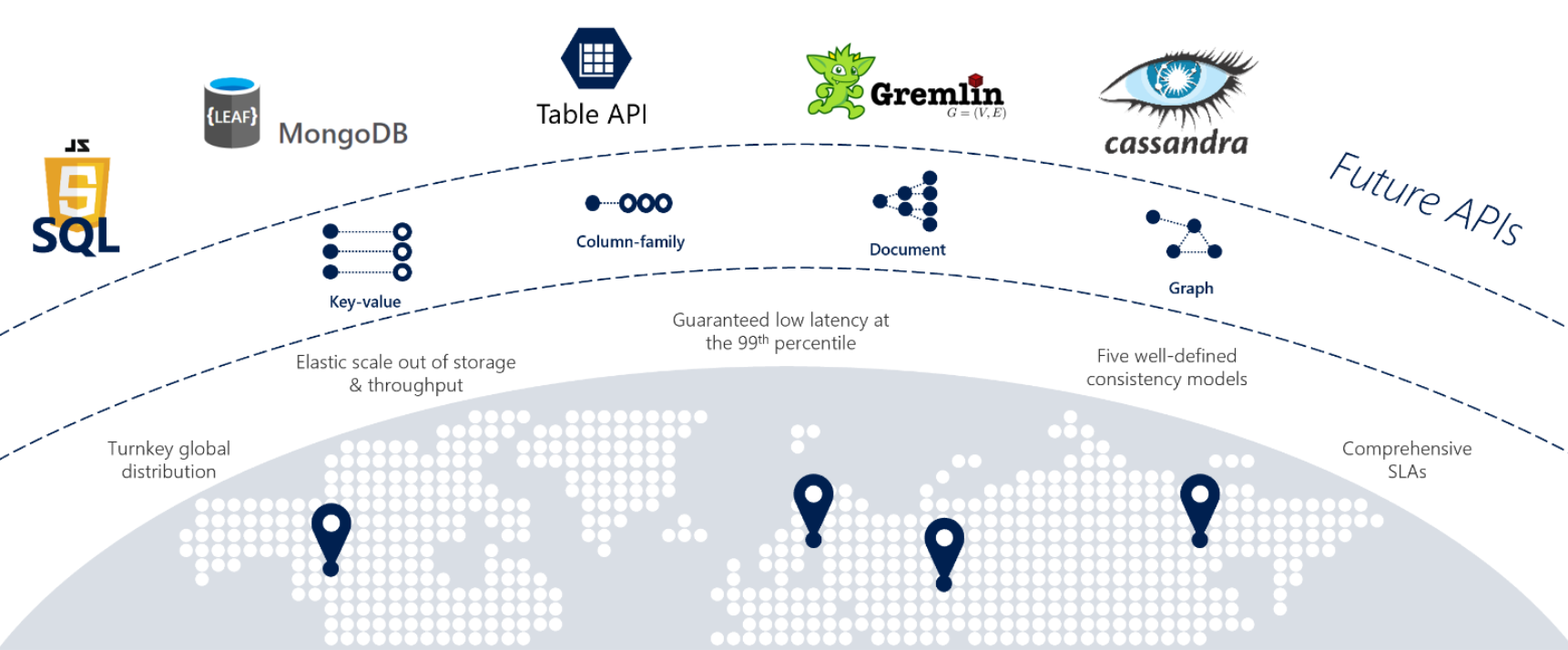
Bild 5–12: Översikt över Azure Cosmos DB
Föregående bild visar många av de inbyggda molnbaserade funktionerna som är tillgängliga i Cosmos DB. I det här avsnittet ska vi titta närmare på dem.
Globalt stöd
Molnbaserade program har ofta en global målgrupp och kräver global skala.
Du kan distribuera Cosmos-databaser mellan regioner eller runt om i världen, placera data nära dina användare, förbättra svarstiden och minska svarstiden. Du kan lägga till eller ta bort en databas från en region utan att pausa eller distribuera om dina tjänster. I bakgrunden replikerar Cosmos DB transparent data till var och en av de konfigurerade regionerna.
Cosmos DB stöder aktiv/aktiv klustring på global nivå, vilket gör att du kan konfigurera någon av dina databasregioner för både skrivningar och läsningar.
Skrivprotokollet för flera regioner är en viktig funktion i Cosmos DB som möjliggör följande funktioner:
Obegränsad elastisk skrivning och lässkalbarhet.
99,999 % läs- och skrivtillgänglighet över hela världen.
Garanterade läsningar och skrivningar på mindre än 10 millisekunder i den 99:e percentilen.
Med Cosmos DB Multi-Homing-API:er är din mikrotjänst automatiskt medveten om den närmaste Azure-regionen och skickar begäranden till den. Den närmaste regionen identifieras av Cosmos DB utan några konfigurationsändringar. Om en region blir otillgänglig dirigerar funktionen Multi-Homing automatiskt begäranden till nästa närmaste tillgängliga region.
Stöd för flera modeller
När du omplatformerar monolitiska program till en molnbaserad arkitektur måste utvecklingsteam ibland migrera NoSQL-datalager med öppen källkod. Cosmos DB kan hjälpa dig att bevara din investering i dessa NoSQL-datalager med dess dataplattform med flera modeller . I följande tabell visas de NoSQL-kompatibilitets-API :er som stöds.
| Leverantör | beskrivning |
|---|---|
| NoSQL API | API för NoSQL lagrar data i dokumentformat |
| API för Mongo DB | Stöder Mongo DB-API:er och JSON-dokument |
| Gremlin-API | Stöder Gremlin API med grafbaserade noder och gränsdatarepresentationer |
| Cassandra-API | Stöder Casandra API för datarepresentationer med bred kolumn |
| Tabell-API | Stöder Azure Table Storage med premiumförbättringar |
| PostgreSQL API | Hanterad tjänst för att köra PostgreSQL i valfri skala |
Utvecklingsteam kan migrera befintliga Mongo-, Gremlin- eller Cassandra-databaser till Cosmos DB med minimala ändringar i data eller kod. För nya appar kan utvecklingsteam välja bland alternativ med öppen källkod eller den inbyggda SQL API-modellen.
Internt lagrar Cosmos data i ett enkelt structformat som består av primitiva datatyper. För varje begäran översätter databasmotorn primitiva data till den modellrepresentation som du har valt.
Observera alternativet Tabell-API i föregående tabell. Det här API:et är en utveckling av Azure Table Storage. Båda delar samma underliggande tabellmodell, men Cosmos DB Table API lägger till premiumförbättringar som inte är tillgängliga i Azure Storage-API:et. Följande tabell kontrasterar funktionerna.
| Funktion | Azure Table Storage-lagringslösning | Azure Cosmos DB |
|---|---|---|
| Svarstid | Snabbt | Svarstid på ensiffrig millisekunder för läsningar och skrivningar var som helst i världen |
| Genomflöde | Gräns på 20 000 åtgärder per tabell | Obegränsade åtgärder per tabell |
| Global distribution | Enskild region med valfri enskild sekundär läsregion | Nyckelfärdiga distributioner till alla regioner med automatisk redundans |
| Indexering | Endast tillgängligt för partitions- och radnyckelegenskaper | Automatisk indexering av alla egenskaper |
| Prissättning | Optimerad för kalla arbetsbelastningar (lågt dataflöde: lagringsförhållande) | Optimerad för frekventa arbetsbelastningar (högt dataflöde: lagringsförhållande) |
Mikrotjänster som använder Azure Table Storage kan enkelt migreras till Cosmos DB Table API. Inga kodändringar krävs.
Justerbar konsekvens
Tidigare i avsnittet Relational jämfört med NoSQL diskuterade vi ämnet datakonsekvens. Datakonsekvens avser integriteten för dina data. Molnbaserade tjänster med distribuerade data förlitar sig på replikering och måste göra en grundläggande kompromiss mellan läskonsekvens, tillgänglighet och svarstid.
De flesta distribuerade databaser gör det möjligt för utvecklare att välja mellan två konsekvensmodeller: stark konsekvens och slutlig konsekvens. Stark konsekvens är guldstandarden för dataprogrammability. Det garanterar att en fråga alltid returnerar de mest aktuella data – även om systemet måste medföra svarstid i väntan på att en uppdatering ska replikeras i alla databaskopior. Även om en databas som har konfigurerats för slutlig konsekvens returnerar data omedelbart, även om dessa data inte är den mest aktuella kopian. Det senare alternativet möjliggör högre tillgänglighet, större skalning och ökad prestanda.
Azure Cosmos DB erbjuder fem väldefinierade konsekvensmodeller som visas i bild 5–13.

Bild 5–13: Konsekvensnivåer i Cosmos DB
Med de här alternativen kan du göra exakta val och detaljerade kompromisser för konsekvens, tillgänglighet och prestanda för dina data. Nivåerna visas i följande tabell.
| Konsekvensnivå | beskrivning |
|---|---|
| Eventuell | Ingen beställningsgaranti för läsningar. Repliker konvergerar så småningom. |
| Konstant prefix | Läsningar är fortfarande slutgiltiga, men data returneras i den ordning som de skrivs i. |
| Sittning | Garanterar att du kan läsa alla data som skrivs under den aktuella sessionen. Det är standardkonsekvensnivån. |
| Begränsad föråldring | Läser spårskrivningar efter intervall som du anger. |
| Stark | Läsningar returnerar garanterat den senaste bekräftade versionen av ett objekt. En klient ser aldrig en icke-utelämnad eller partiell läsning. |
I artikeln Getting Behind the 9-Ball: Cosmos DB Consistency Levels Explained (Komma bakom 9-Ball: Cosmos DB Consistency Levels Explained) ger Microsoft Program Manager Jeremy Likness en utmärkt förklaring av de fem modellerna.
Partitionering
Azure Cosmos DB omfattar automatisk partitionering för att skala en databas för att uppfylla prestandabehoven för dina molnbaserade tjänster.
Du hanterar data i Cosmos DB-data genom att skapa databaser, containrar och objekt.
Containrar finns i en Cosmos DB-databas och representerar en schemaagnostisk gruppering av objekt. Objekt är de data som du lägger till i containern. De representeras som dokument, rader, noder eller kanter. Alla objekt som läggs till i en container indexeras automatiskt.
För att partitionera containern delas objekt in i distinkta delmängder som kallas logiska partitioner. Logiska partitioner fylls i baserat på värdet för en partitionsnyckel som är associerad med varje objekt i en container. Bild 5–14 visar två containrar var och en med en logisk partition baserat på ett partitionsnyckelvärde.
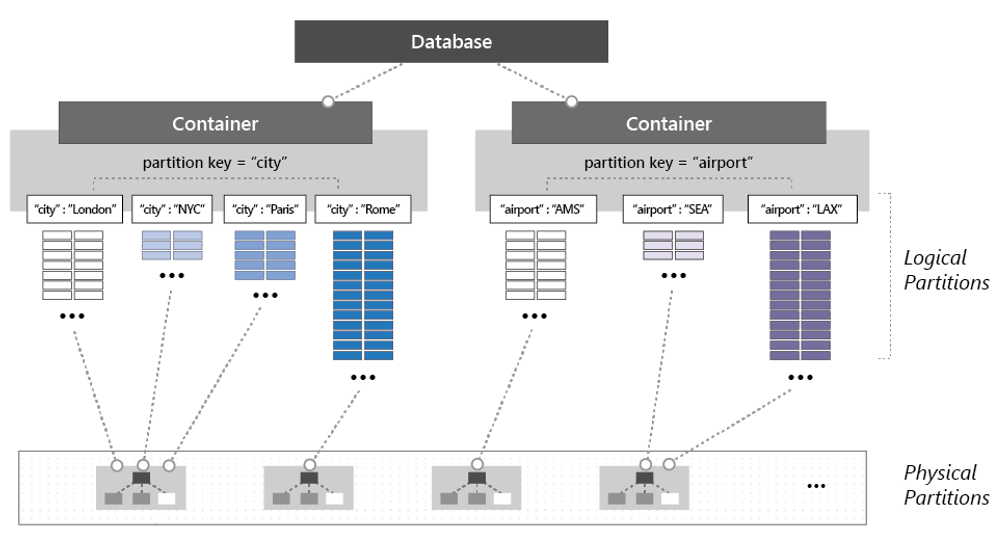
Bild 5–14: Cosmos DB-partitioneringsmekanik
Observera i föregående bild hur varje objekt innehåller en partitionsnyckel för antingen "stad" eller "flygplats". Nyckeln avgör objektets logiska partition. Objekt med en stadskod tilldelas containern till vänster och objekt med en flygplatskod till containern till höger. Genom att kombinera partitionsnyckelvärdet med ID-värdet skapas ett objekts index, som unikt identifierar objektet.
Internt hanterar Cosmos DB automatiskt placeringen av logiska partitioner på fysiska partitioner för att uppfylla containerns skalbarhets- och prestandabehov. I takt med att kraven på programdataflöde och lagring ökar distribuerar Azure Cosmos DB om logiska partitioner över ett större antal servrar. Omdistributionsåtgärder hanteras av Cosmos DB och anropas utan avbrott eller driftstopp.
NewSQL-databaser
NewSQL är en ny databasteknik som kombinerar den distribuerade skalbarheten för NoSQL med ACID-garantierna för en relationsdatabas. NewSQL-databaser är viktiga för affärssystem som måste bearbeta stora mängder data i distribuerade miljöer med fullständigt transaktionsstöd och ACID-efterlevnad. Även om en NoSQL-databas kan ge massiv skalbarhet garanterar den inte datakonsekvens. Tillfälliga problem från inkonsekventa data kan belasta utvecklingsteamet. Utvecklare måste skapa skydd i sin mikrotjänstkod för att hantera problem som orsakas av inkonsekventa data.
Cloud Native Computing Foundation (CNCF) har flera NewSQL-databasprojekt.
| Projekt | Egenskaper |
|---|---|
| Kackerlacka DB | En ACID-kompatibel relationsdatabas som skalar globalt. Lägg till en ny nod i ett kluster och CockroachDB tar hand om att balansera data mellan instanser och geografiska områden. Den skapar, hanterar och distribuerar repliker för att säkerställa tillförlitlighet. Det är öppen källkod och fritt tillgängligt. |
| TiDB | En databas med öppen källkod som stöder HTAP-arbetsbelastningar (Hybrid Transactional and Analytical Processing). Det är MySQL-kompatibelt och har horisontell skalbarhet, stark konsekvens och hög tillgänglighet. TiDB fungerar som en MySQL-server. Du kan fortsätta att använda befintliga MySQL-klientbibliotek utan att kräva omfattande kodändringar i ditt program. |
| YugabyteDB | En öppen källkod distribuerad SQL-databas med höga prestanda. Den stöder låg frågesvarstid, motståndskraft mot fel och global datadistribution. YugabyteDB är PostgreSQL-kompatibelt och hanterar skalbara RDBMS- och OLTP-arbetsbelastningar i internetskala. Produkten har också stöd för NoSQL och är kompatibel med Cassandra. |
| Vitess | Vitess är en databaslösning för att distribuera, skala och hantera stora kluster av MySQL-instanser. Den kan köras i en offentlig eller privat molnarkitektur. Vitess kombinerar och utökar många viktiga MySQL-funktioner och funktioner för både lodrät och vågrät horisontell partitionering. Vitess har sitt ursprung i YouTube och har betjänat all YouTube-databastrafik sedan 2011. |
Projekt med öppen källkod i föregående bild är tillgängliga från Cloud Native Computing Foundation. Tre av erbjudandena är fullständiga databasprodukter, som omfattar .NET-support. Den andra, Vitess, är ett databasklustersystem som vågrätt skalar stora kluster av MySQL-instanser.
Ett viktigt designmål för NewSQL-databaser är att arbeta internt i Kubernetes och dra nytta av plattformens återhämtning och skalbarhet.
NewSQL-databaser är utformade för att utvecklas i tillfälliga molnmiljöer där underliggande virtuella datorer kan startas om eller schemaläggas om med ett ögonblicks varsel. Databaserna är utformade för att överleva nodfel utan dataförlust eller stilleståndstid. KackerlackaDB kan till exempel överleva en datorförlust genom att underhålla tre konsekventa repliker av alla data över noderna i ett kluster.
Kubernetes använder en tjänstkonstruktion för att tillåta en klient att hantera en grupp identiska NewSQL-databasprocesser från en enda DNS-post. Genom att koppla bort databasinstanserna från adressen till tjänsten som den är associerad med kan vi skala utan att störa befintliga programinstanser. Att skicka en begäran till en tjänst vid en viss tidpunkt ger alltid samma resultat.
I det här scenariot är alla databasinstanser lika. Det finns inga primära eller sekundära relationer. Tekniker som konsensusreplikering som finns i CockroachDB gör att alla databasnoder kan hantera alla begäranden. Om noden som tar emot en belastningsutjäxad begäran har de data som behövs lokalt svarar den omedelbart. Annars blir noden en gateway och vidarebefordrar begäran till lämpliga noder för att få rätt svar. Från klientens perspektiv är varje databasnod densamma: De visas som en enda logisk databas med konsekvensgarantierna för ett system med en enda dator, trots att de har dussintals eller till och med hundratals noder som fungerar bakom kulisserna.
En detaljerad titt på mekaniken bakom NewSQL-databaser finns i artikeln DASH: Four Properties of Kubernetes-Native Databases (DASH: Four Properties of Kubernetes-Native Databases ).
Datamigrering till molnet
En av de mer tidskrävande uppgifterna är att migrera data från en dataplattform till en annan. Azure Data Migration Service kan hjälpa dig att påskynda sådana åtgärder. Den kan migrera data från flera externa databaskällor till Azure Data-plattformar med minimal stilleståndstid. Målplattformarna innehåller följande tjänster:
- Azure SQL Database
- Azure-databas för MySQL
- Azure-databas för MariaDB
- Azure-databasen för PostgreSQL
- Azure Cosmos DB
Tjänsten ger rekommendationer som vägleder dig genom de ändringar som krävs för att utföra en migrering, både liten eller stor.
Samarbeta med oss på GitHub
Källan för det här innehållet finns på GitHub, där du även kan skapa och granska ärenden och pull-begäranden. Se vår deltagarguide för mer information.