Not
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Tips/Råd
Det här innehållet är ett utdrag från eBook, .NET Microservices Architecture for Containerized .NET Applications, tillgängligt på .NET Docs eller som en kostnadsfri nedladdningsbar PDF som kan läsas offline.

Utmaning nr 1: Definiera gränserna för varje mikrotjänst
Att definiera mikrotjänstgränser är förmodligen den första utmaningen som någon stöter på. Varje mikrotjänst måste vara en del av ditt program och varje mikrotjänst bör vara självständig med alla fördelar och utmaningar som den förmedlar. Men hur identifierar man dessa gränser?
Först måste du fokusera på programmets logiska domänmodeller och relaterade data. Försök att identifiera frikopplade öar med data och olika kontexter i samma program. Varje kontext kan ha olika affärsspråk (olika affärsvillkor). Kontexterna bör definieras och hanteras oberoende av varandra. De termer och entiteter som används i dessa olika kontexter kan låta liknande, men du kanske upptäcker att i ett visst sammanhang används ett affärskoncept med ett annat syfte i en annan kontext och kan till och med ha ett annat namn. Till exempel kan en användare kallas en användare i identitets- eller medlemskapskontexten, som en kund i en CRM-kontext, som en köpare i en beställningskontext och så vidare.
Hur du identifierar gränser mellan flera programkontexter med en annan domän för varje kontext är exakt hur du kan identifiera gränserna för varje affärsmikrotjänst och dess relaterade domänmodell och data. Du försöker alltid minimera kopplingen mellan dessa mikrotjänster. Den här guiden går in mer detaljerat om den här identifierings- och domänmodelldesignen i avsnittet Identifiera domänmodellgränser för varje mikrotjänst senare.
Utmaning nr 2: Så här skapar du frågor som hämtar data från flera mikrotjänster
En andra utmaning är hur du implementerar frågor som hämtar data från flera mikrotjänster, samtidigt som du undviker chattig kommunikation till mikrotjänsterna från fjärrklientappar. Ett exempel kan vara en enda skärm från en mobilapp som måste visa användarinformation som ägs av mikrotjänsterna korg, katalog och användaridentitet. Ett annat exempel är en komplex rapport som omfattar många tabeller som finns i flera mikrotjänster. Rätt lösning beror på frågornas komplexitet. Men i vilket fall som helst behöver du ett sätt att aggregera information om du vill förbättra effektiviteten i kommunikationen i systemet. De mest populära lösningarna är följande.
API Gateway. För enkel dataaggregering från flera mikrotjänster som äger olika databaser är den rekommenderade metoden en aggregeringsmikrotjänst som kallas en API Gateway. Du måste dock vara försiktig med att implementera det här mönstret, eftersom det kan vara en kvävningspunkt i systemet, och det kan bryta mot principen om mikrotjänstautonomi. För att minska den här möjligheten kan du ha flera finkorniga API Gateways som var och en fokuserar på en vertikal "del" eller ett affärsområde i systemet. API Gateway-mönstret beskrivs mer detaljerat i avsnittet API Gateway senare.
GraphQL-federation Ett alternativ att överväga om dina mikrotjänster redan använder GraphQL är GraphQL-federation. Med federation kan du definiera "subgrafer" från andra tjänster och skriva dem till en aggregerad "supergraf" som fungerar som ett fristående schema.
CQRS med frågetabeller och lästabeller. En annan lösning för att aggregera data från flera mikrotjänster är mönstret Materialiserad vy. I den här metoden genererar du i förväg (förbereder avnormaliserade data innan de faktiska frågorna inträffar) en skrivskyddad tabell med de data som ägs av flera mikrotjänster. Tabellen har ett format som passar klientappens behov.
Överväg något som liknar skärmen för en mobilapp. Om du har en enda databas kan du samla ihop data för den skärmen med hjälp av en SQL-fråga som utför en komplex koppling som involverar flera tabeller. Men när du har flera databaser och varje databas ägs av en annan mikrotjänst kan du inte köra frågor mot dessa databaser och skapa en SQL-koppling. Din komplexa fråga blir en utmaning. Du kan uppfylla kravet med en CQRS-metod – du skapar en avnormaliserad tabell i en annan databas som bara används för frågor. Tabellen kan utformas specifikt för de data du behöver för den komplexa frågan, med en en-till-en-relation mellan fält som krävs av programmets skärm och kolumnerna i frågetabellen. Det kan också fungera i rapporteringssyfte.
Den här metoden löser inte bara det ursprungliga problemet (hur du frågar och kopplar mellan mikrotjänster), utan förbättrar också prestanda avsevärt jämfört med en komplex koppling, eftersom du redan har de data som programmet behöver i frågetabellen. Självklart innebär användningen av CQRS (Command and Query Responsibility Segregation) med fråge/läs-tabeller ytterligare utvecklingsarbete, och du måste acceptera eventual konsistens. Krav på prestanda och hög skalbarhet i samarbetsscenarier (eller konkurrensscenarier, beroende på synpunkt) är dock där du bör tillämpa CQRS med flera databaser.
"Kalla data" i centrala databaser. För komplexa rapporter och frågor som kanske inte kräver realtidsdata är en vanlig metod att exportera dina "frekventa data" (transaktionsdata från mikrotjänsterna) som "kalla data" till stora databaser som endast används för rapportering. Det centrala databassystemet kan vara ett Big Data-baserat system, som Hadoop; ett informationslager som ett baserat på Azure SQL Data Warehouse; eller till och med en enskild SQL-databas som bara används för rapporter (om storleken inte är ett problem).
Tänk på att den här centraliserade databasen endast används för frågor och rapporter som inte behöver realtidsdata. De ursprungliga uppdateringarna och transaktionerna, som din sanningskälla, måste finnas i dina mikrotjänstdata. Sättet du synkroniserar data på är antingen genom att använda händelsedriven kommunikation (som beskrivs i nästa avsnitt) eller med hjälp av andra import-/exportverktyg för databasinfrastruktur. Om du använder händelsedriven kommunikation skulle integreringsprocessen likna hur du sprider data enligt beskrivningen tidigare för CQRS-frågetabeller.
Men om din programdesign innebär att ständigt aggregera information från flera mikrotjänster för komplexa frågor kan det vara ett symptom på en dålig design -a mikrotjänst bör vara så isolerad som möjligt från andra mikrotjänster. (Detta exkluderar rapporter/analys som alltid ska använda centrala databaser med kall data.) Att ha det här problemet kan ofta vara en anledning att slå samman mikrotjänster. Du måste balansera utvecklingens och distributionens autonomi för varje mikrotjänst med starka beroenden, sammanhållning och dataaggregering.
Utmaning nr 3: Så här uppnår du konsekvens mellan flera mikrotjänster
Som tidigare nämnts är de data som ägs av varje mikrotjänst privata för den mikrotjänsten och kan endast nås med hjälp av dess mikrotjänst-API. Därför är en utmaning som presenteras hur man implementerar affärsprocesser från början till slut samtidigt som enhetligheten mellan flera mikrotjänster bibehålls.
För att analysera det här problemet ska vi titta på ett exempel från referensprogrammet eShopOnContainers. Katalogmikrotjänsten lagrar information om alla produkter, inklusive produktpriset. Basket-mikrotjänsten hanterar tidsmässiga data om produktartiklar som användarna lägger till i sina varukorgar, vilket inkluderar priset på artiklarna när de lades till i korgen. När en produkts pris uppdateras i katalogen bör priset också uppdateras i de aktiva korgar som innehåller samma produkt, plus att systemet förmodligen bör varna användaren om att ett visst objekts pris har ändrats sedan de lade till det i varukorgen.
I en hypotetisk monolitisk version av det här programmet, när priset ändras i produkttabellen, kan katalogundersystemet helt enkelt använda en ACID-transaktion för att uppdatera det aktuella priset i tabellen Korg.
Men i ett mikrotjänstbaserat program ägs tabellerna Produkt och Korg av respektive mikrotjänster. Ingen mikrotjänst får någonsin inkludera tabeller/lagring som ägs av en annan mikrotjänst i sina egna transaktioner, inte ens i direkta frågor, som visas i bild 4–9.
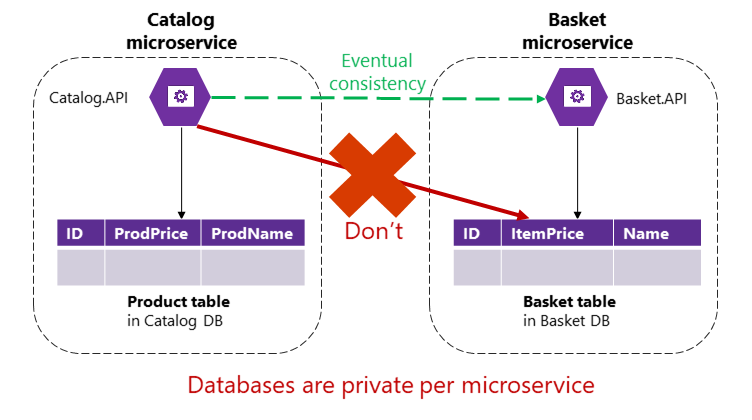
Bild 4-9. En mikrotjänst kan inte komma åt en tabell direkt i en annan mikrotjänst
Katalogmikrotjänsten bör inte uppdatera tabellen Basket direkt eftersom tabellen Basket ägs av mikrotjänsten Basket. För att göra en uppdatering av basketmikrotjänsten bör katalogmikrotjänsten använda slutlig konsekvens förmodligen baserat på asynkron kommunikation, till exempel integrationshändelser (meddelande och händelsebaserad kommunikation). Så här utför referensprogrammet eShopOnContainers den här typen av konsekvens mellan mikrotjänster.
Som anges i CAP-teoremet måste du välja mellan tillgänglighet och ACID-stark konsistens. De flesta mikrotjänstbaserade scenarier kräver tillgänglighet och hög skalbarhet snarare än stark konsistens. Verksamhetskritiska applikationer måste förbli igång, och utvecklare kan kringgå stark konsistens genom att använda tekniker för att arbeta med svag eller slutlig konsistens. Det här är den metod som används av de flesta mikrotjänstbaserade arkitekturer.
Dessutom är transaktioner i ACID-format eller två faser inte bara emot mikrotjänstprinciper. de flesta NoSQL-databaser (t.ex. Azure Cosmos DB, MongoDB osv.) stöder inte incheckningstransaktioner i två faser, vilket är typiskt i scenarier med distribuerade databaser. Det är dock viktigt att upprätthålla datakonsekvens mellan tjänster och databaser. Den här utmaningen gäller även frågan om hur ändringar ska spridas över flera mikrotjänster när vissa data måste vara redundanta, till exempel när du behöver ha produktens namn eller beskrivning i katalogmikrotjänsten och varukorgens mikrotjänst.
En bra lösning för det här problemet är att använda eventuell konsekvens mellan mikrotjänster som använder sig av händelsedriven kommunikation och ett publicera-och-prenumerera-system. De här avsnitten beskrivs i avsnittet Asynkron händelsedriven kommunikation senare i den här guiden.
Utmaning nr 4: Utforma kommunikation över mikrotjänstgränser
Kommunikation över mikrotjänstgränser är en verklig utmaning. I det här sammanhanget refererar kommunikationen inte till vilket protokoll du ska använda (HTTP och REST, AMQP, meddelanden och så vidare). I stället tar den upp vilken kommunikationsstil du bör använda, och särskilt hur kopplade dina mikrotjänster ska vara. Beroende på kopplingsnivån varierar effekten av felet på systemet avsevärt när felet inträffar.
I ett distribuerat system som ett mikrotjänstbaserat program, där så många artefakter flyttas runt och med distribuerade tjänster på många servrar eller värdar, kommer komponenterna så småningom att misslyckas. Partiella fel och ännu större avbrott kommer att inträffa, så du måste utforma dina mikrotjänster och kommunikationen mellan dem med tanke på de vanliga riskerna i den här typen av distribuerat system.
En populär metod är att implementera HTTP-baserade mikrotjänster (REST) på grund av deras enkelhet. En HTTP-baserad metod är helt acceptabel. problemet här är relaterat till hur du använder det. Om du använder HTTP-begäranden och svar bara för att interagera med dina mikrotjänster från klientprogram eller från API Gateways är det bra. Men om du skapar långa kedjor av synkrona HTTP-anrop över mikrotjänster och kommunicerar över deras gränser som om mikrotjänsterna var objekt i ett monolitiskt program, kommer ditt program så småningom att stöta på problem.
Anta till exempel att klientprogrammet gör ett HTTP API-anrop till en enskild mikrotjänst som mikrotjänsten Ordering. Om mikrotjänsten Ordering i sin tur anropar ytterligare mikrotjänster med HTTP inom samma begäran/svarscykel skapar du en kedja med HTTP-anrop. Det kan låta rimligt från början. Det finns dock viktiga saker att tänka på när du går den här vägen:
Blockering och låga prestanda. På grund av HTTP:s synkrona karaktär får den ursprungliga begäran inte något svar förrän alla interna HTTP-anrop har slutförts. Tänk dig om antalet dessa anrop ökar avsevärt och samtidigt blockeras ett av de mellanliggande HTTP-anropen till en mikrotjänst. Resultatet är att prestanda påverkas och den övergripande skalbarheten påverkas exponentiellt när ytterligare HTTP-begäranden ökar.
Koppla mikrotjänster med HTTP. Affärsmikrotjänster bör inte kopplas till andra affärsmikrotjänster. Helst bör de inte "veta" om förekomsten av andra mikrotjänster. Om ditt program förlitar sig på att koppla mikrotjänster som i exemplet blir det nästan omöjligt att uppnå autonomi per mikrotjänst.
Fel i en mikrotjänst. Om du har implementerat en kedja med mikrotjänster som är länkade via HTTP-anrop kommer hela kedjan av mikrotjänster att misslyckas när någon av mikrotjänsterna misslyckas (och så småningom kommer de att misslyckas). Ett mikrotjänstbaserat system bör utformas för att fortsätta att fungera så bra som möjligt vid partiella fel. Även om du implementerar klientlogik som använder återförsök med exponentiella backoff- eller kretsbrytarmekanismer, desto mer komplexa är HTTP-anropskedjorna, desto mer komplext är det att implementera en felstrategi baserad på HTTP.
Om dina interna mikrotjänster kommunicerar genom att skapa kedjor med HTTP-begäranden enligt beskrivningen kan det hävdas att du har ett monolitiskt program, men ett som baseras på HTTP mellan processer i stället för kommunikationsmekanismer inom processen.
För att upprätthålla mikrotjänstautonomi och få bättre återhämtning bör du därför minimera användningen av kedjor av begäran/svar-kommunikation mellan mikrotjänster. Vi rekommenderar att du endast använder asynkron interaktion för kommunikation mellan mikrotjänster, antingen med hjälp av asynkron meddelande- och händelsebaserad kommunikation, eller med hjälp av (asynkron) HTTP-avsökning oberoende av den ursprungliga HTTP-begäran/svarscykeln.
Användningen av asynkron kommunikation förklaras med ytterligare information senare i den här guiden i avsnitten Asynkron mikrotjänstintegrering tvingar mikrotjänstens autonomi och asynkrona meddelandebaserad kommunikation.
Ytterligare resurser
CAP-teoremet
https://en.wikipedia.org/wiki/CAP_theoremEventuell konsistens
https://en.wikipedia.org/wiki/Eventual_consistencyIntroduktion till datakonsekvens
https://learn.microsoft.com/previous-versions/msp-n-p/dn589800(v=pandp.10)Martin Fowler. CQRS (kommando- och frågeansvarsfördelning)
https://martinfowler.com/bliki/CQRS.htmlMaterialiserad vy
https://learn.microsoft.com/azure/architecture/patterns/materialized-viewCharles Row. ACID vs. BASE: Den föränderliga pH-balansen i databastransaktionsbehandling
https://www.dataversity.net/acid-vs-base-the-shifting-ph-of-database-transaction-processing/Kompenserande transaktion
https://learn.microsoft.com/azure/architecture/patterns/compensating-transactionUdi Dahan. Tjänstorienterad sammansättning
https://udidahan.com/2014/07/30/service-oriented-composition-with-video/
Samarbeta med oss på GitHub
Källan för det här innehållet finns på GitHub, där du också kan skapa och granska problem och pull-begäranden. Mer information finns i vår deltagarguide.