Not
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Undantag används för att kommunicera fel lokalt inom tjänsten eller klientimplementeringen. Fel används å andra sidan för att kommunicera fel över tjänstgränser, till exempel från servern till klienten eller vice versa. Förutom fel använder transportkanaler ofta transportspecifika mekanismer för att kommunicera fel på transportnivå. HTTP-transport använder till exempel statuskoder som 404 för att kommunicera en icke-befintlig slutpunkts-URL (det finns ingen slutpunkt för att skicka tillbaka ett fel). Det här dokumentet består av tre avsnitt som ger guidning till författare av anpassade kanaler. Det första avsnittet innehåller vägledning om när och hur du definierar och utlöser undantag. Det andra avsnittet innehåller vägledning om hur du genererar och hanterar fel. I det tredje avsnittet beskrivs hur du tillhandahåller spårningsinformation för att hjälpa användaren av din anpassade kanal att felsöka program som körs.
Undantag
Det finns två saker att tänka på när du utlöser ett undantag: Först måste det vara av en typ som gör att användarna kan skriva rätt kod som kan reagera korrekt på undantaget. För det andra måste den ge tillräckligt med information för att användaren ska förstå vad som gick fel, felpåverkan och hur det kan åtgärdas. Följande avsnitt ger vägledning om undantagstyper och meddelanden för WCF-kanaler (Windows Communication Foundation). Det finns också allmän vägledning om undantag i .NET i dokumentet Designriktlinjer för undantag.
Undantagstyper
Alla undantag som genereras av kanaler måste vara antingen en System.TimeoutException, System.ServiceModel.CommunicationExceptioneller en typ som härletts från CommunicationException. (Undantag som ObjectDisposedException kan också genereras, men bara för att indikera att den anropande koden har missbrukat kanalen. Om en kanal används korrekt får den bara utlösa de angivna undantagen.) WCF tillhandahåller sju undantagstyper som härleds från CommunicationException och är utformade för att användas av kanaler. Det finns andra CommunicationException-härledda undantag som är utformade för att användas av andra delar av systemet. Dessa undantagstyper är:
| Undantagstyp | Innebörd | Innehåll för inre undantag | Återställningsstrategi |
|---|---|---|---|
| AddressAlreadyInUseException | Slutpunktsadressen som angetts för lyssning används redan. | Om det finns, innehåller mer information om transportfelet som orsakade det här undantaget. Till exempel. PipeException, HttpListenerException, eller SocketException. | Prova en annan adress. |
| AddressAccessDeniedException | Processen tillåts inte åtkomst till den slutpunktsadress som angetts för att lyssna. | Om det finns, innehåller mer information om transportfelet som orsakade det här undantaget. Till exempel PipeException, eller HttpListenerException. | Prova med olika autentiseringsuppgifter. |
| CommunicationObjectFaultedException | Den ICommunicationObject som används är i feltillstånd (mer information finns i Förstå tillståndsändringar). Observera att när ett objekt med flera väntande anrop övergår till feltillståndet utlöser bara ett anrop ett undantag som är relaterat till felet och resten av anropen genererar ett CommunicationObjectFaultedException. Det här undantaget utlöses vanligtvis eftersom ett program förbiser vissa undantag och försöker använda ett redan felat objekt, eventuellt på en annan tråd än den som fångade det ursprungliga undantaget. | Om det finns innehåller information om det inre undantaget. | Skapa ett nytt objekt. Observera att beroende på vad som orsakade ICommunicationObject felet kan det finnas annat arbete som krävs för att återställa. |
| CommunicationObjectAbortedException | Den ICommunicationObject som används har avbrutits (mer information finns i Förstå tillståndsändringar). På liknande sätt som CommunicationObjectFaultedException, indikerar detta undantag att programmet har kallat Abort på objektet, eventuellt från en annan tråd, och objektet är inte längre användbart av den anledningen. | Om det finns innehåller information om det inre undantaget. | Skapa ett nytt objekt. Observera att beroende på vad som orsakade att ICommunicationObject avbröts från början kan det krävas annat arbete för att återställa. |
| EndpointNotFoundException | Målets fjärrslutpunkt lyssnar inte. Detta kan bero på att valfri del av slutpunktsadressen är felaktig, oåterkallelig eller att slutpunkten är nere. Exempel är DNS-fel, Queue Manager är inte tillgängligt och tjänsten körs inte. | Det inre undantaget innehåller information, vanligtvis från den underliggande transporten. | Prova en annan adress. Alternativt kan avsändaren vänta en stund och försöka igen om tjänsten är nere |
| ProtocolException | Kommunikationsprotokoll, som beskrivs av slutpunktens policy, stämmer inte överens mellan slutpunkter. Till exempel har inramning av matchningsfel för innehållstyp eller maximal meddelandestorlek överskridits. | Om det finns finns mer information om det specifika protokollfelet. Är till exempel QuotaExceededException det inre undantaget när felorsaken överskrider MaxReceivedMessageSize. | Återställning: Se till att inställningarna för avsändare och mottagna protokoll matchar. Ett sätt att göra detta är att importera tjänstslutpunktens nuvarande metadata (princip) på nytt och använda den genererade bindningen för att återskapa kanalen. |
| ServerTooBusyException | Fjärrslutpunkten lyssnar men är inte beredd att bearbeta meddelanden. | Om det finns, ger det inre undantaget detaljer om SOAP-fel eller fel på transportnivå. | Återställning: Vänta och försök utföra åtgärden igen senare. |
| TimeoutException | Åtgärden kunde inte slutföras inom tidsgränsen. | Kan ge detaljer om timeouten. | Vänta och försök utföra åtgärden igen senare. |
Definiera endast en ny undantagstyp om den typen motsvarar en viss återställningsstrategi som skiljer sig från alla befintliga undantagstyper. Om du definierar en ny undantagstyp måste den härledas från CommunicationException eller någon av dess härledda klasser.
Undantagsmeddelanden
Undantagsmeddelanden riktas mot användaren, inte programmet, så de bör tillhandahålla tillräckligt med information för att hjälpa användaren att förstå och lösa problemet. De tre viktiga delarna i ett bra undantagsmeddelande är:
Vad hände. Ange en tydlig beskrivning av problemet med hjälp av termer som är relaterade till användarens upplevelse. Ett felaktigt undantagsmeddelande skulle till exempel vara "Ogiltigt konfigurationsavsnitt". Detta gör att användaren undrar vilket konfigurationsavsnitt som är felaktigt och varför det är felaktigt. Ett förbättrat meddelande skulle vara "Ogiltig konfigurationsavsnitt <customBinding>". Ett ännu bättre meddelande skulle vara "Det går inte att lägga till transporten med namnet myTransport i bindningen med namnet myBinding eftersom bindningen redan har en transport med namnet myTransport". Det här är ett mycket specifikt meddelande med termer och namn som användaren enkelt kan identifiera i programmets konfigurationsfil. Det saknas dock fortfarande några viktiga komponenter.
Felets betydelse. Om meddelandet inte tydligt anger vad felet innebär, kommer användaren sannolikt att undra om det är ett allvarligt fel eller om det kan ignoreras. I allmänhet bör meddelanden leda med innebörden eller betydelsen av felet. För att förbättra föregående exempel kan meddelandet vara "ServiceHost misslyckades med att öppna på grund av ett konfigurationsfel: Det går inte att lägga till transporten med namnet myTransport i bindningen med namnet myBinding eftersom bindningen redan har en transport med namnet myTransport".
Hur användaren ska åtgärda problemet. Den viktigaste delen av meddelandet är att hjälpa användaren att åtgärda problemet. Meddelandet bör innehålla vägledning eller tips om vad du ska kontrollera eller åtgärda för att åtgärda problemet. Till exempel "ServiceHost kunde inte öppna på grund av ett konfigurationsfel: Det går inte att lägga till transporten med namnet myTransport i bindningen med namnet myBinding eftersom bindningen redan har en transport med namnet myTransport. Se till att det bara finns en transport i bindningen".
Kommunicera felaktigheter
SOAP 1.1 och SOAP 1.2 definierar båda en specifik struktur för fel. Det finns vissa skillnader mellan de två specifikationerna, men i allmänhet används typerna Meddelande och MessageFault för att skapa och hantera fel.

SOAP 1.2 Fel (vänster) och SOAP 1.1 Fel (höger). I SOAP 1.1 är endast felelementet namnområdeskvalificerat.
SOAP definierar ett felmeddelande som ett meddelande som endast innehåller ett felelement (ett element vars namn är <env:Fault>) som är ett barn av <env:Body>. Innehållet i felelementet skiljer sig något mellan SOAP 1.1 och SOAP 1.2 enligt bild 1. Klassen normaliserar dock System.ServiceModel.Channels.MessageFault dessa skillnader i en objektmodell:
public abstract class MessageFault
{
protected MessageFault();
public virtual string Actor { get; }
public virtual string Node { get; }
public static string DefaultAction { get; }
public abstract FaultCode Code { get; }
public abstract bool HasDetail { get; }
public abstract FaultReason Reason { get; }
public T GetDetail<T>();
public T GetDetail<T>( XmlObjectSerializer serializer);
public System.Xml.XmlDictionaryReader GetReaderAtDetailContents();
// other methods omitted
}
Egenskapen Code motsvarar env:Code (eller faultCode i SOAP 1.1) och identifierar typen av fel. SOAP 1.2 definierar fem tillåtna värden för faultCode (till exempel avsändare och mottagare) och definierar ett Subcode element som kan innehålla valfritt underkodsvärde. (Se SOAP 1.2-specifikationen för listan över tillåtna felkoder och deras innebörd.) SOAP 1.1 har en något annorlunda mekanism: Den definierar fyra faultCode värden (till exempel klient och server) som kan utökas antingen genom att definiera helt nya eller genom att använda punkt notationen för att skapa mer specifika faultCodes, till exempel Client.Authentication.
När du använder MessageFault för att programmera fel mappar FaultCode.Name och FaultCode.Namespace till namnet och namnområdet för SOAP 1.2 env:Code eller SOAP 1.1 faultCode. FaultCode.SubCode mappar till env:Subcode för SOAP 1.2 och är ogiltig för SOAP 1.1.
Du bör skapa nya felunderkoder (eller nya felkoder om du använder SOAP 1.1) om det är intressant att programmatiskt urskilja ett fel. Detta är detsamma som att skapa en ny undantagstyp. Du bör undvika att använda punkt notationen med SOAP 1.1-felkoder. WS-I Basic-profilen rekommenderar också att man undviker att använda punktnotation för felkoder.
public class FaultCode
{
public FaultCode(string name);
public FaultCode(string name, FaultCode subCode);
public FaultCode(string name, string ns);
public FaultCode(string name, string ns, FaultCode subCode);
public bool IsPredefinedFault { get; }
public bool IsReceiverFault { get; }
public bool IsSenderFault { get; }
public string Name { get; }
public string Namespace { get; }
public FaultCode SubCode { get; }
// methods omitted
}
Egenskapen Reason motsvarar env:Reason (eller faultString i SOAP 1.1) en läsbar beskrivning av feltillståndet som motsvarar ett undantagsmeddelande. Klassen FaultReason (och SOAP env:Reason/faultString) har inbyggt stöd för att ha flera översättningar i globaliseringens intresse.
public class FaultReason
{
public FaultReason(FaultReasonText translation);
public FaultReason(IEnumerable<FaultReasonText> translations);
public FaultReason(string text);
public SynchronizedReadOnlyCollection<FaultReasonText> Translations
{
get;
}
}
Innehållet i felinformationen exponeras på MessageFault med hjälp av olika metoder, inklusive GetDetail<T> och GetReaderAtDetailContents(). Felinformationen är ett ogenomskinligt element för att bära med ytterligare detaljer om felet. Detta är användbart om det finns godtyckligt strukturerade detaljer som du vill koppla till felet.
Skapa störningar
I det här avsnittet beskrivs processen för att generera ett fel som svar på ett feltillstånd som identifierats i en kanal eller i en meddelandeegenskap som skapats av kanalen. Ett vanligt exempel är att skicka tillbaka ett fel som svar på ett begärandemeddelande som innehåller ogiltiga data.
När du genererar ett fel bör den anpassade kanalen inte skicka felet direkt, snarare bör den utlösa ett undantag och låta lagret ovan avgöra om undantaget ska konverteras till ett fel och hur det ska skickas. För att underlätta den här konverteringen bör kanalen tillhandahålla en FaultConverter implementering som kan konvertera undantaget som genereras av den anpassade kanalen till rätt fel.
FaultConverter definieras som:
public class FaultConverter
{
public static FaultConverter GetDefaultFaultConverter(
MessageVersion version);
protected abstract bool OnTryCreateFaultMessage(
Exception exception,
out Message message);
public bool TryCreateFaultMessage(
Exception exception,
out Message message);
}
Varje kanal som genererar anpassade fel måste implementera FaultConverter och returnera den från ett anrop till GetProperty<FaultConverter>. Den anpassade OnTryCreateFaultMessage implementeringen måste antingen konvertera undantaget till ett fel eller delegera till den inre kanalens FaultConverter. Om kanalen är en transport måste den antingen konvertera undantaget eller delegera till kodarens FaultConverter eller standardvärdet FaultConverter som anges i WCF . Standardvärdet FaultConverter konverterar fel som motsvarar felmeddelanden som anges av WS-Addressing och SOAP. Här är ett exempel på OnTryCreateFaultMessage implementering.
public override bool OnTryCreateFaultMessage(Exception exception,
out Message message)
{
if (exception is ...)
{
message = ...;
return true;
}
#if IMPLEMENTING_TRANSPORT_CHANNEL
FaultConverter encoderConverter =
this.encoder.GetProperty<FaultConverter>();
if ((encoderConverter != null) &&
(encoderConverter.TryCreateFaultMessage(
exception, out message)))
{
return true;
}
FaultConverter defaultConverter =
FaultConverter.GetDefaultFaultConverter(
this.channel.messageVersion);
return defaultConverter.TryCreateFaultMessage(
exception,
out message);
#else
FaultConverter inner =
this.innerChannel.GetProperty<FaultConverter>();
if (inner != null)
{
return inner.TryCreateFaultMessage(exception, out message);
}
else
{
message = null;
return false;
}
#endif
}
En konsekvens av det här mönstret är att undantag som utlöses mellan lager för feltillstånd som kräver fel måste innehålla tillräckligt med information för att motsvarande felgenerator ska kunna skapa rätt fel. Som anpassad kanalförfattare kan du definiera undantagstyper som motsvarar olika felvillkor om sådana undantag inte redan finns. Observera att undantag som passerar kanallager bör kommunicera feltillståndet i stället för ogenomskinliga feldata.
Felkategorier
Det finns vanligtvis tre typer av fel:
Fel som är genomgripande i hela stacken. Dessa fel kan påträffas på valfritt lager i kanalstacken, till exempel InvalidCardinalityAddressingException.
Fel som kan påträffas var som helst ovanför ett visst lager i stacken, till exempel vissa fel som rör en flödestransaktion eller säkerhetsroller.
Fel som riktar sig mot ett enda skikt i stacken, till exempel fel som sekvensnummerfel WS-RM.
Kategori 1. Fel är vanligtvis WS-Addressing- och SOAP-fel.
FaultConverter Basklassen som tillhandahålls av WCF konverterar fel som motsvarar felmeddelanden som anges av WS-Addressing och SOAP så att du inte behöver hantera konverteringen av dessa undantag själv.
Kategori 2. Fel uppstår när ett lager lägger till en egenskap i meddelandet som inte helt förbrukar meddelandeinformation som gäller för det lagret. Fel kan upptäckas senare när ett högre lager ber meddelandeegenskapen att bearbeta meddelandeinformation ytterligare. Sådana kanaler bör implementera den GetProperty som angivits tidigare för att möjliggöra för det högre lagret att skicka tillbaka rätt fel. Ett exempel på detta är TransactionMessageProperty. Den här egenskapen läggs till i meddelandet utan att alla data i rubriken verifieras fullständigt (detta kan innebära att du kontaktar den distribuerade transaktionskoordinatorn (DTC)).
Kategori 3. Fel genereras och skickas endast av ett enda lager i processorn. Därför finns alla undantag i lagret. För att förbättra konsekvensen mellan kanaler och underlätta underhåll bör din anpassade kanal använda det mönster som angavs tidigare för att generera felmeddelanden även för interna fel.
Tolkning av mottagna fel
Det här avsnittet innehåller vägledning för att generera lämpligt undantag när du tar emot ett felmeddelande. Beslutsträdet för bearbetning av ett meddelande på varje lager i stacken är följande:
Om lagret anser att meddelandet är ogiltigt bör lagret utföra sin "ogiltiga meddelandebearbetning". Sådan bearbetning är specifik för lagret, men kan omfatta att släppa meddelandet, spåra eller utlösa ett undantag som konverteras till ett fel. Exempel är säkerhetsavdelningen som tar emot ett meddelande som inte är korrekt säkrat, eller RM som tar emot ett meddelande med ett felaktigt sekvensnummer.
Om meddelandet annars är ett felmeddelande som gäller specifikt för lagret och meddelandet inte är meningsfullt utanför lagrets interaktion, bör lagret hantera feltillståndet. Ett exempel på detta är ett RM Sequence Refused-fel som är meningslöst för lager ovanför RM-kanalen och som innebär fel i RM-kanalen och kastas från pågående operationer.
Annars ska meddelandet returneras från Request() eller Receive(). Detta inkluderar fall där lagret känner igen felet, men felet bara indikerar att en begäran misslyckades och inte innebär att kanalen felas och utlöser väntande åtgärder. För att förbättra användbarheten i ett sådant fall bör lagret implementera
GetProperty<FaultConverter>och returnera enFaultConverterhärledd klass som kan konvertera felet till ett undantag genom attOnTryCreateExceptionåsidosätta .
Följande objektmodell stöder konvertering av meddelanden till undantag:
public class FaultConverter
{
public static FaultConverter GetDefaultFaultConverter(
MessageVersion version);
protected abstract bool OnTryCreateException(
Message message,
MessageFault fault,
out Exception exception);
public bool TryCreateException(
Message message,
MessageFault fault,
out Exception exception);
}
Ett kanallager kan implementera GetProperty<FaultConverter> för att stödja konvertering av felmeddelanden till undantag. Det gör du genom att åsidosätta OnTryCreateException och inspektera felmeddelandet. Om du känner igen gör du konverteringen, annars ber du den inre kanalen att konvertera den. Transportkanaler bör delegera till FaultConverter.GetDefaultFaultConverter för att hämta standard-SOAP/WS-Addressing FaultConverter.
En typisk implementering ser ut så här:
public override bool OnTryCreateException(
Message message,
MessageFault fault,
out Exception exception)
{
if (message.Action == "...")
{
exception = ...;
return true;
}
// OR
if ((fault.Code.Name == "...") && (fault.Code.Namespace == "..."))
{
exception = ...;
return true;
}
if (fault.IsMustUnderstand)
{
if (fault.WasHeaderNotUnderstood(
message.Headers, "...", "..."))
{
exception = new ProtocolException(...);
return true;
}
}
#if IMPLEMENTING_TRANSPORT_CHANNEL
FaultConverter encoderConverter =
this.encoder.GetProperty<FaultConverter>();
if ((encoderConverter != null) &&
(encoderConverter.TryCreateException(
message, fault, out exception)))
{
return true;
}
FaultConverter defaultConverter =
FaultConverter.GetDefaultFaultConverter(
this.channel.messageVersion);
return defaultConverter.TryCreateException(
message, fault, out exception);
#else
FaultConverter inner =
this.innerChannel.GetProperty<FaultConverter>();
if (inner != null)
{
return inner.TryCreateException(message, fault, out exception);
}
else
{
exception = null;
return false;
}
#endif
}
För specifika feltillstånd som har distinkta återställningsscenarier bör du överväga att definiera en härledd klass av ProtocolException.
MustUnderstand-bearbetning
SOAP definierar ett allmänt fel för att signalera att en obligatorisk rubrik inte förstods av mottagaren. Det här felet kallas felet mustUnderstand . I WCF genererar anpassade kanaler aldrig mustUnderstand fel. I stället kontrollerar WCF Dispatcher, som finns överst i WCF-kommunikationsstacken, att alla rubriker som har markerats som MustUnderstand=true tolkades av den underliggande stacken. Om något inte förstods genereras ett mustUnderstand fel vid den tidpunkten. (Användaren kan välja att inaktivera den här mustUnderstand bearbetningen och låta programmet ta emot alla meddelandehuvuden. I så fall ansvarar programmet för att utföra mustUnderstand bearbetningen.) Det genererade felet innehåller en NotUnderstood-rubrik som innehåller namnen på alla rubriker med MustUnderstand=true som inte förstods.
Om din protokollkanal skickar en anpassad rubrik med MustUnderstand=true och får ett mustUnderstand fel, måste den ta reda på om felet beror på rubriken som skickades. Det finns två medlemmar i MessageFault klassen som är användbara för detta:
public class MessageFault
{
...
public bool IsMustUnderstandFault { get; }
public static bool WasHeaderNotUnderstood(MessageHeaders headers,
string name, string ns) { }
...
}
IsMustUnderstandFault returnerar true om felet är ett mustUnderstand fel.
WasHeaderNotUnderstood returnerar true om rubriken med det angivna namnet och namnrymd ingår i felet som en 'NotUnderstood'-header. Annars returneras false.
Om en kanal genererar en rubrik som är märkt MustUnderstand = true, bör det lagret även implementera API-mönstret för undantagsgenerering. Dessutom bör mustUnderstand-fel som orsakas av rubriken omvandlas till ett mer användbart undantag, enligt tidigare beskrivning.
Spårning
.NET Framework tillhandahåller en mekanism för att spåra programkörning som ett sätt att diagnostisera produktionsprogram eller tillfälliga problem där det inte är möjligt att bara bifoga ett felsökningsprogram och gå igenom koden. Kärnkomponenterna i den här mekanismen System.Diagnostics finns i namnområdet och består av:
System.Diagnostics.TraceSource, som är källan till spårningsinformation som ska skrivas, System.Diagnostics.TraceListener, som är en abstrakt basklass för konkreta lyssnare som tar emot den information som ska spåras från TraceSource och matar ut den till ett lyssnarspecifikt mål. Till exempel XmlWriterTraceListener matar ut spårningsinformation till en XML-fil. Slutligen , System.Diagnostics.TraceSwitchsom gör att programanvändaren kan styra spårningens utförlighet och som vanligtvis anges i konfigurationen.
Förutom kärnkomponenterna kan du använda verktyget För tjänstspårningsvisare (SvcTraceViewer.exe) för att visa och söka efter WCF-spårningar. Verktyget är särskilt utformat för spårningsfiler som genereras av WCF och skrivs ut med hjälp av XmlWriterTraceListener. Följande bild visar de olika komponenter som ingår i spårningen.
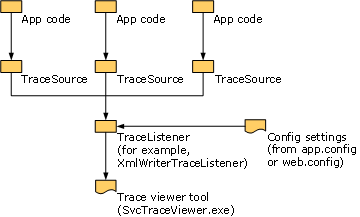
Spåra från en anpassad kanal
Anpassade kanaler bör skriva ut spårningsmeddelanden för att hjälpa till att diagnostisera problem när det inte går att koppla ett felsökningsprogram till det program som körs. Detta omfattar två uppgifter på hög nivå: Instansiera en TraceSource och anropa dess metoder för att skriva spårningar.
När du instansierar en TraceSourceblir strängen som du anger namnet på källan. Det här namnet används för att konfigurera spårningskällan (aktivera/inaktivera/ange spårningsnivå). Det visas också i själva spårningsutdata. Anpassade kanaler bör använda ett unikt källnamn för att hjälpa läsarna av spårningsutdata att förstå var spårningsinformationen kommer ifrån. Det är vanligt att använda namnet på sammansättningen som skriver informationen som namnet på spårningskällan. WCF använder till exempel System.ServiceModel som spårningskälla för information som skrivits från sammansättningen System.ServiceModel.
När du har en spårningskälla, kan du anropa dess TraceData, TraceEvent eller TraceInformation metoder för att skriva spårningsposter till spårningslyssnare. För varje spårningspost som du skriver måste du klassificera typen av händelse som en av de händelsetyper som definieras i TraceEventType. Den här klassificeringen och inställningen för spårningsnivå i konfigurationen avgör om spårningsposten skickas till lyssnaren. Om du till exempel anger spårningsnivån i konfigurationen till Warning tillåts spårningsposter för Warning, Error och Critical att skrivas, men poster för Information och Utförligt blockeras. Här är ett exempel på hur du instansierar en spårningskälla och skriver ut en post på informationsnivå:
using System.Diagnostics;
//...
TraceSource udpSource = new TraceSource("Microsoft.Samples.Udp");
//...
udpsource.TraceInformation("UdpInputChannel received a message");
Viktigt!
Vi rekommenderar starkt att du anger ett namn på spårningskällan som är unikt för din anpassade kanal för att hjälpa spårningsläsare att förstå var utdata kom ifrån.
Integrera med spårningsvisaren
Spår som genereras av din kanal kan exporteras i ett format som kan läsas av Verktyget för tjänstspårningsvisare (SvcTraceViewer.exe) genom att använda System.Diagnostics.XmlWriterTraceListener som spårningslyssnare. Det här är inte något som du som kanalutvecklare behöver göra. I stället är det programanvändaren (eller personen som felsöker programmet) som behöver konfigurera den här spårningslyssnaren i programmets konfigurationsfil. Följande konfiguration matar till exempel ut spårningsinformation från både System.ServiceModel och Microsoft.Samples.Udp till filen med namnet TraceEventsFile.e2e:
<configuration>
<system.diagnostics>
<sources>
<!-- configure System.ServiceModel trace source -->
<source name="System.ServiceModel" switchValue="Verbose"
propagateActivity="true">
<listeners>
<add name="e2e" />
</listeners>
</source>
<!-- configure Microsoft.Samples.Udp trace source -->
<source name="Microsoft.Samples.Udp" switchValue="Verbose" >
<listeners>
<add name="e2e" />
</listeners>
</source>
</sources>
<!--
Define a shared trace listener that outputs to TraceFile.e2e
The listener name is e2e
-->
<sharedListeners>
<add name="e2e" type="System.Diagnostics.XmlWriterTraceListener"
initializeData=".\TraceFile.e2e"/>
</sharedListeners>
<trace autoflush="true" />
</system.diagnostics>
</configuration>
Spåra strukturerade data
System.Diagnostics.TraceSource har en TraceData metod som tar ett eller flera objekt som ska ingå i spårningsposten. I allmänhet anropas Object.ToString-metoden på varje objekt och den resulterande strängen skrivs som en del av loggposten. När du använder System.Diagnostics.XmlWriterTraceListener för att skicka spårningar kan du skicka ett System.Xml.XPath.IXPathNavigable som dataobjekt till TraceData. Den resulterande spårningsposten innehåller den XML som tillhandahålls av System.Xml.XPath.XPathNavigator. Här är en exempelpost med XML-programdata:
<E2ETraceEvent xmlns="http://schemas.microsoft.com/2004/06/E2ETraceEvent">
<System xmlns="...">
<EventID>12</EventID>
<Type>3</Type>
<SubType Name="Information">0</SubType>
<Level>8</Level>
<TimeCreated SystemTime="2006-01-13T22:58:03.0654832Z" />
<Source Name="Microsoft.ServiceModel.Samples.Udp" />
<Correlation ActivityID="{00000000-0000-0000-0000-000000000000}" />
<Execution ProcessName="UdpTestConsole"
ProcessID="3348" ThreadID="4" />
<Channel />
<Computer>COMPUTER-LT01</Computer>
</System>
<!-- XML application data -->
<ApplicationData>
<TraceData>
<DataItem>
<TraceRecord
Severity="Information"
xmlns="…">
<TraceIdentifier>some trace id</TraceIdentifier>
<Description>EndReceive called</Description>
<AppDomain>UdpTestConsole.exe</AppDomain>
<Source>UdpInputChannel</Source>
</TraceRecord>
</DataItem>
</TraceData>
</ApplicationData>
</E2ETraceEvent>
WCF-spårningsvisaren förstår schemat för det TraceRecord element som visades tidigare och extraherar data från dess underordnade element och visar dem i tabellformat. Kanalen bör använda det här schemat när du spårar strukturerade programdata för att hjälpa Svctraceviewer.exe användare att läsa data.