Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Lär dig hur du använder en förtränad ONNX-modell i ML.NET för att identifiera objekt i bilder.
Träning av en objektidentifieringsmodell från grunden kräver att miljontals parametrar anges, en stor mängd märkta träningsdata och en stor mängd beräkningsresurser (hundratals GPU-timmar). Med en förtränad modell kan du genväg till träningsprocessen.
I den här tutorialen lär du dig följande:
- Förstå problemet
- Lär dig vad ONNX är och hur det fungerar med ML.NET
- Förstå modellen
- Återanvänd den förtränad modellen
- Identifiera objekt med en inläst modell
Förutsättningar
- Visual Studio 2022 eller senare.
- Microsoft.ML NuGet-paket
- Microsoft.ML.ImageAnalytics NuGet-paket
- Microsoft.ML.OnnxTransformer NuGet-paket
- Liten YOLOv2 förtränad modell
- Netron (valfritt)
Översikt över EXEMPEL på ONNX-objektidentifiering
Det här exemplet skapar ett .NET Core-konsolprogram som identifierar objekt i en bild med hjälp av en förtränad ONNX-modell för djupinlärning. Koden för det här exemplet finns på lagringsplatsen dotnet/machinelearning-samples på GitHub.
Vad är objektidentifiering?
Objektidentifiering är ett problem med visuellt innehåll. Objektidentifiering är nära relaterat till bildklassificering, men utför bildklassificering i en mer detaljerad skala. Objektidentifiering både letar upp och kategoriserar entiteter i bilder. Objektidentifieringsmodeller tränas ofta med djupinlärning och neurala nätverk. Mer information finns i Djupinlärning kontra maskininlärning .
Använd objektidentifiering när bilder innehåller flera objekt av olika typer.

Några användningsfall för objektidentifiering är:
- Self-Driving bilar
- Robotteknik
- Ansiktsigenkänning
- Arbetsplatssäkerhet
- Objekträkning
- Aktivitetsigenkänning
Välj en djupinlärningsmodell
Djupinlärning är en delmängd av maskininlärning. För att träna djupinlärningsmodeller krävs stora mängder data. Mönster i data representeras av en serie lager. Relationerna i data kodas som anslutningar mellan de lager som innehåller vikter. Desto högre vikt, desto starkare relation. Tillsammans kallas den här serien lager och anslutningar för artificiella neurala nätverk. Ju fler lager i ett nätverk, desto djupare är det, vilket gör det till ett djupt neuralt nätverk.
Det finns olika typer av neurala nätverk, det vanligaste är MULTI-Layered Perceptron (MLP), Convolutional Neural Network (CNN) och Recurrent Neural Network (RNN). Det mest grundläggande är MLP, som mappar en uppsättning indata till en uppsättning utdata. Det här neurala nätverket är bra när data inte har någon rumslig komponent eller tidskomponent. CNN använder convolutional-lager för att bearbeta rumslig information som finns i data. Ett bra användningsfall för CNN är bildbearbetning för att identifiera förekomsten av en funktion i en bildregion (till exempel finns det en näsa i mitten av en bild?). Slutligen tillåter RNN:er att status eller minne kan användas som indata. RNN används för tidsserieanalys, där sekventiell ordning och kontext för händelser är viktiga.
Förstå modellen
Objektidentifiering är en bildbearbetningsuppgift. Därför är de flesta djupinlärningsmodeller som tränats för att lösa detta problem CNN:er. Modellen som används i den här självstudien är modellen Tiny YOLOv2, en mer kompakt version av YOLOv2-modellen som beskrivs i dokumentet: "YOLO9000: Better, Faster, Stronger" av Redmon och Farhadi. Tiny YOLOv2 tränas på Pascal VOC-datauppsättningen och består av 15 lager som kan förutsäga 20 olika objektklasser. Eftersom Tiny YOLOv2 är en komprimerad version av den ursprungliga YOLOv2-modellen görs en kompromiss mellan hastighet och noggrannhet. De olika lager som utgör modellen kan visualiseras med verktyg som Netron. Att inspektera modellen skulle ge en mappning av anslutningarna mellan alla lager som utgör det neurala nätverket, där varje lager skulle innehålla namnet på lagret tillsammans med dimensionerna för respektive indata/utdata. De datastrukturer som används för att beskriva indata och utdata i modellen kallas tensorer. Tensors kan betraktas som containrar som lagrar data i N-dimensioner. När det gäller Tiny YOLOv2 är image namnet på indataskiktet och förväntar sig en tensor med dimensioner 3 x 416 x 416. Namnet på utdataskiktet är grid och genererar en utdata tensor med dimensioner 125 x 13 x 13.
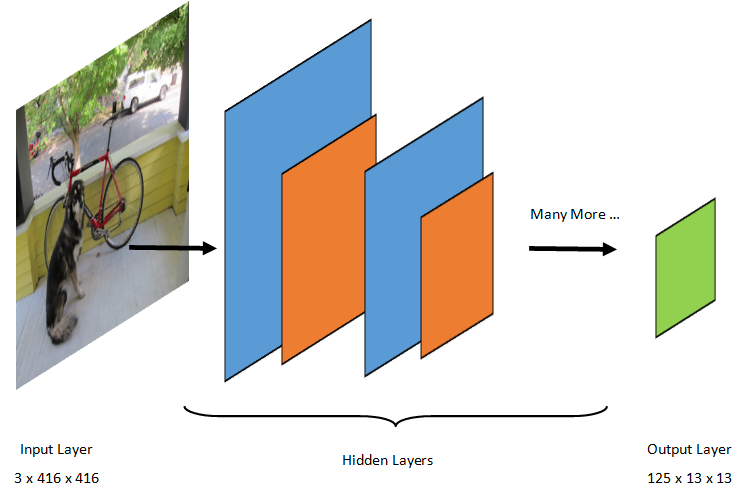
YOLO-modellen tar en bild 3(RGB) x 416px x 416px. Modellen tar den här indatan och skickar den genom de olika lagren för att skapa utdata. Utdata delar indatabilden i ett 13 x 13 rutnät, där varje cell i rutnätet består av 125 värden.
Vad är en ONNX-modell?
Open Neural Network Exchange (ONNX) är ett format med öppen källkod för AI-modeller. ONNX stöder samverkan mellan ramverk. Det innebär att du kan träna en modell i ett av de många populära maskininlärningsramverken som PyTorch, konvertera den till ONNX-format och använda ONNX-modellen i ett annat ramverk som ML.NET. Mer information finns på ONNX-webbplatsen.

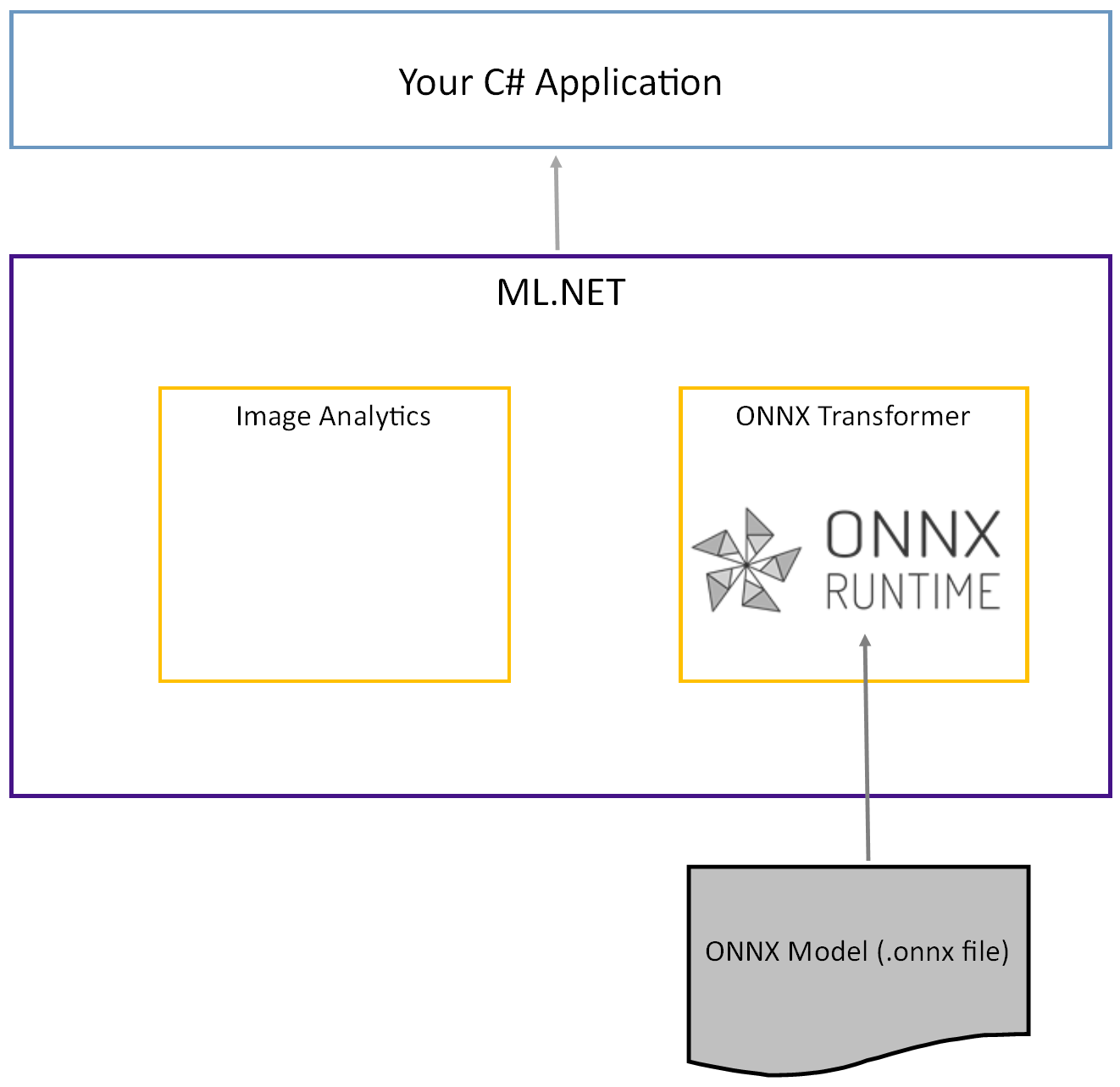
Den förtränade Tiny YOLOv2-modellen lagras i ONNX-format, en serialiserad representation av lagren och inlärda mönster i dessa lagren. I ML.NET uppnås samverkan med ONNX med NuGet-paketen ImageAnalytics och OnnxTransformer . Paketet ImageAnalytics innehåller en serie transformeringar som tar en bild och kodar den till numeriska värden som kan användas som indata i en förutsägelse- eller träningspipeline. Paketet OnnxTransformer använder ONNX Runtime för att läsa in en ONNX-modell och använda den för att göra förutsägelser baserat på angivna indata.
Konfigurera .NET-konsolprojektet
Nu när du har en allmän förståelse för vad ONNX är och hur Tiny YOLOv2 fungerar är det dags att skapa programmet.
Skapa ett konsolprogram
Skapa ett C# -konsolprogram med namnet "ObjectDetection". Klicka på knappen Nästa.
Välj .NET 8 som ramverk att använda. Klicka på knappen Skapa.
Installera Microsoft.ML NuGet-paketet:
Anmärkning
Det här exemplet använder den senaste stabila versionen av De NuGet-paket som nämns om inget annat anges.
- Högerklicka på projektet i Prieskumník riešení och välj Hantera NuGet-paket.
- Välj "nuget.org" som paketkälla, välj fliken Bläddra och sök efter Microsoft.ML.
- Välj knappen Installera.
- Välj ok-knappen i dialogrutan Förhandsgranskningsändringar och välj sedan knappen Jag accepterar i dialogrutan Godkännande av licens om du godkänner licensvillkoren för de paket som anges.
- Upprepa de här stegen för Microsoft.Windows.Compatibility, Microsoft.ML.ImageAnalytics, Microsoft.ML.OnnxTransformer och Microsoft.ML.OnnxRuntime.
Förbereda dina data och förtränad modell
Ladda ned zip-filen project assets directory och packa upp.
Kopiera
assets-katalogen till din ObjectDetection-projektkatalog. Den här katalogen och dess underkataloger innehåller de avbildningsfiler (förutom tiny YOLOv2-modellen, som du laddar ned och lägger till i nästa steg) som behövs för den här självstudien.Ladda ned Tiny YOLOv2-modellen från ONNX Model Zoo.
Kopiera filen till projektkatalogen
model.onnxassets\Modeloch byt namn på den tillTinyYolo2_model.onnx. Den här katalogen innehåller den modell som behövs för den här självstudien.Högerklicka på var och en av filerna i tillgångskatalogen och underkatalogerna i Prieskumník riešení och välj Egenskaper. Under Avancerat ändrar du värdet för Kopiera till utdatakatalog till Kopiera om det är nyare.
Skapa klasser och definiera sökvägar
Öppna filen Program.cs och lägg till följande ytterligare using direktiv överst i filen:
using System.Drawing;
using System.Drawing.Drawing2D;
using ObjectDetection.YoloParser;
using ObjectDetection.DataStructures;
using ObjectDetection;
using Microsoft.ML;
Definiera sedan sökvägarna för de olika tillgångarna.
GetAbsolutePathSkapa först metoden längst ned i Program.cs-filen.string GetAbsolutePath(string relativePath) { FileInfo _dataRoot = new FileInfo(typeof(Program).Assembly.Location); string assemblyFolderPath = _dataRoot.Directory.FullName; string fullPath = Path.Combine(assemblyFolderPath, relativePath); return fullPath; }Under direktiven
usingskapar du sedan fält för att lagra platsen för dina tillgångar.var assetsRelativePath = @"../../../assets"; string assetsPath = GetAbsolutePath(assetsRelativePath); var modelFilePath = Path.Combine(assetsPath, "Model", "TinyYolo2_model.onnx"); var imagesFolder = Path.Combine(assetsPath, "images"); var outputFolder = Path.Combine(assetsPath, "images", "output");
Lägg till en ny katalog i projektet för att lagra indata och förutsägelseklasser.
Högerklicka på projektet i Prieskumník riešení och välj sedan Lägg till>ny mapp. När den nya mappen visas i Prieskumník riešení, ge den namnet "DataStructures".
Skapa din indataklass i den nyligen skapade katalogen DataStructures .
Högerklicka på katalogen DataStructures i Prieskumník riešení och välj sedan Lägg till>nytt objekt.
I dialogrutan Lägg till nytt objekt väljer du Klass och ändrar fältet Namn till ImageNetData.cs. Välj sedan Lägg till.
Filen ImageNetData.cs öppnas i kodredigeraren. Lägg till följande
usingdirektiv överst i ImageNetData.cs:using System.Collections.Generic; using System.IO; using System.Linq; using Microsoft.ML.Data;Ta bort den befintliga klassdefinitionen och lägg till följande kod för
ImageNetDataklassen i filen ImageNetData.cs :public class ImageNetData { [LoadColumn(0)] public string ImagePath; [LoadColumn(1)] public string Label; public static IEnumerable<ImageNetData> ReadFromFile(string imageFolder) { return Directory .GetFiles(imageFolder) .Where(filePath => Path.GetExtension(filePath) != ".md") .Select(filePath => new ImageNetData { ImagePath = filePath, Label = Path.GetFileName(filePath) }); } }ImageNetDataär en dataklass för indata och har följande String fält:-
ImagePathinnehåller sökvägen där avbildningen lagras. -
Labelinnehåller namnet på filen.
Innehåller dessutom
ImageNetDataen metodReadFromFilesom läser in flera bildfiler som lagras i denimageFolderangivna sökvägen och returnerar dem som en samlingImageNetDataobjekt.-
Skapa din förutsägelseklass i katalogen DataStructures .
Högerklicka på katalogen DataStructures i Prieskumník riešení och välj sedan Lägg till>nytt objekt.
I dialogrutan Lägg till nytt objekt väljer du Klass och ändrar fältet Namn till ImageNetPrediction.cs. Välj sedan Lägg till.
Filen ImageNetPrediction.cs öppnas i kodredigeraren. Lägg till följande
usingdirektiv överst i ImageNetPrediction.cs:using Microsoft.ML.Data;Ta bort den befintliga klassdefinitionen och lägg till följande kod för
ImageNetPredictionklassen i filen ImageNetPrediction.cs :public class ImageNetPrediction { [ColumnName("grid")] public float[] PredictedLabels; }ImageNetPredictionär förutsägelsedataklassen och har följandefloat[]fält:-
PredictedLabelsinnehåller dimensioner, objektitetspoäng och klassannolikheter för var och en av de avgränsningsrutor som identifierats i en bild.
-
Initiera variabler
KLASSEN MLContext är en startpunkt för alla ML.NET åtgärder, och initiering mlContext skapar en ny ML.NET miljö som kan delas mellan arbetsflödesobjekten för modellskapande. Det liknar konceptuellt DBContext i Entity Framework.
Initiera variabeln mlContext med en ny instans av MLContext genom att lägga till följande rad under fältet outputFolder .
MLContext mlContext = new MLContext();
Skapa en parser för modellutdata efter processen
Modellen segmenteras en bild i ett 13 x 13 rutnät, där varje rutnätscell är 32px x 32px. Varje rutnätscell innehåller 5 potentiella avgränsningsrutor för objekt. En avgränsningsruta har 25 element:
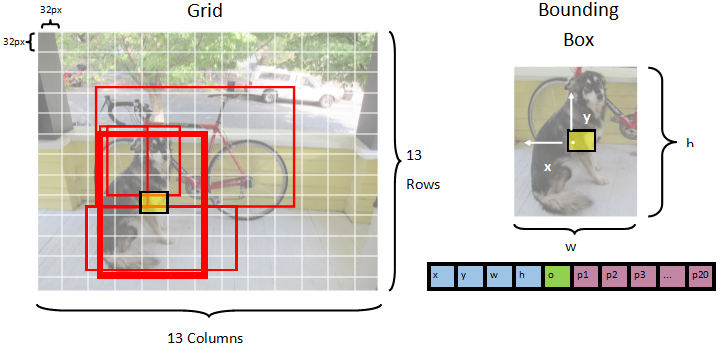
-
xx-positionen för avgränsningsrutans mittpunkt i förhållande till rutnätscellen som den är associerad med. -
yy-positionen för avgränsningsrutans mittpunkt i förhållande till rutnätscellen som den är associerad med. -
wavgränsningsrutans bredd. -
hbegränsningsrutans höjd. -
odet konfidensvärde som anger sannolikheten för att ett objekt finns i avgränsningsrutan, även kallat objektpoäng. -
p1-p20klassannolikheter för var och en av de 20 klasser som förutsägs av modellen.
Totalt utgör de 25 element som beskriver var och en av de 5 avgränsningsrutorna de 125 elementen i varje rutnätscell.
Utdata som genereras av den förtränad ONNX-modellen är en flyttalmatris med längd 21125, som representerar elementen i en tensor med dimensioner 125 x 13 x 13. För att omvandla förutsägelserna som genereras av modellen till en tensor krävs en del efterbearbetningsarbete. Det gör du genom att skapa en uppsättning klasser som hjälper dig att parsa utdata.
Lägg till en ny katalog i projektet för att organisera uppsättningen parserklasser.
- Högerklicka på projektet i Prieskumník riešení och välj sedan Lägg till>ny mapp. När den nya mappen visas i Prieskumník riešení, ge den namnet "YoloParser".
Skapa avgränsningsrutor och dimensioner
Utdata från modellen innehåller koordinater och dimensioner för avgränsningsrutor för objekt i bilden. Skapa en basklass för dimensioner.
Högerklicka på katalogen YoloParser i Prieskumník riešení och välj sedan Lägg till>nytt objekt.
I dialogrutan Lägg till nytt objekt väljer du Klass och ändrar fältet Namn till DimensionsBase.cs. Välj sedan Lägg till.
Filen DimensionsBase.cs öppnas i kodredigeraren. Ta bort alla
usingdirektiv och befintlig klassdefinition.Lägg till följande kod för
DimensionsBaseklassen i filen DimensionsBase.cs :public class DimensionsBase { public float X { get; set; } public float Y { get; set; } public float Height { get; set; } public float Width { get; set; } }DimensionsBasehar följandefloategenskaper:-
Xinnehåller objektets position längs x-axeln. -
Yinnehåller objektets position längs y-axeln. -
Heightinnehåller objektets höjd. -
Widthinnehåller objektets bredd.
-
Skapa sedan en klass för dina avgränsningsrutor.
Högerklicka på katalogen YoloParser i Prieskumník riešení och välj sedan Lägg till>nytt objekt.
I dialogrutan Lägg till nytt objekt väljer du Klass och ändrar fältet Namn till YoloBoundingBox.cs. Välj sedan Lägg till.
Filen YoloBoundingBox.cs öppnas i kodredigeraren. Lägg till följande
usingdirektiv överst i YoloBoundingBox.cs:using System.Drawing;Precis ovanför den befintliga klassdefinitionen lägger du till en ny klassdefinition med namnet
BoundingBoxDimensionssom ärver frånDimensionsBaseklassen för att innehålla dimensionerna för respektive avgränsningsruta.public class BoundingBoxDimensions : DimensionsBase { }Ta bort den befintliga
YoloBoundingBoxklassdefinitionen och lägg till följande kod förYoloBoundingBoxklassen i filen YoloBoundingBox.cs :public class YoloBoundingBox { public BoundingBoxDimensions Dimensions { get; set; } public string Label { get; set; } public float Confidence { get; set; } public RectangleF Rect { get { return new RectangleF(Dimensions.X, Dimensions.Y, Dimensions.Width, Dimensions.Height); } } public Color BoxColor { get; set; } }YoloBoundingBoxhar följande egenskaper:-
Dimensionsinnehåller avgränsningsrutans dimensioner. -
Labelinnehåller objektklassen som detekterats inom avgränsningsrutan. -
Confidenceinnehåller klassens förtroende. -
Rectinnehåller rektangelrepresentationen av avgränsningsrutans dimensioner. -
BoxColorinnehåller den färg som är associerad med respektive klass som används för att rita på bilden.
-
Skapa parsern
Nu när klasserna för dimensioner och avgränsningsrutor har skapats är det dags att skapa parsern.
Högerklicka på katalogen YoloParser i Prieskumník riešení och välj sedan Lägg till>nytt objekt.
I dialogrutan Lägg till nytt objekt väljer du Klass och ändrar fältet Namn till YoloOutputParser.cs. Välj sedan Lägg till.
Filen YoloOutputParser.cs öppnas i kodredigeraren. Lägg till följande
usingdirektiv överst i YoloOutputParser.cs:using System; using System.Collections.Generic; using System.Drawing; using System.Linq;I den befintliga
YoloOutputParserklassdefinitionen lägger du till en kapslad klass som innehåller dimensionerna för var och en av cellerna i bilden. Lägg till följande kod för klassenCellDimensionssom ärver frånDimensionsBaseklassen högst upp i klassdefinitionenYoloOutputParser.class CellDimensions : DimensionsBase { }Lägg till följande konstanter och fält i
YoloOutputParserklassdefinitionen.public const int ROW_COUNT = 13; public const int COL_COUNT = 13; public const int CHANNEL_COUNT = 125; public const int BOXES_PER_CELL = 5; public const int BOX_INFO_FEATURE_COUNT = 5; public const int CLASS_COUNT = 20; public const float CELL_WIDTH = 32; public const float CELL_HEIGHT = 32; private int channelStride = ROW_COUNT * COL_COUNT;-
ROW_COUNTär antalet rader i rutnätet som bilden är indelad i. -
COL_COUNTär antalet kolumner i rutnätet som bilden är indelad i. -
CHANNEL_COUNTär det totala antalet värden som finns i en cell i rutnätet. -
BOXES_PER_CELLär antalet avgränsningsrutor i en cell, -
BOX_INFO_FEATURE_COUNTär antalet funktioner som finns i en ruta (x,y,höjd,bredd,konfidens). -
CLASS_COUNTär antalet klassförutsägelser som finns i varje avgränsningsruta. -
CELL_WIDTHär bredden på en cell i bildrutnätet. -
CELL_HEIGHTär höjden på en cell i bildrutnätet. -
channelStrideär startpositionen för den aktuella cellen i rutnätet.
När modellen gör en förutsägelse, även kallad bedömning, delar den
416px x 416pxindatabilden i ett rutnät med celler med storleken13 x 13. Varje cell innehåller är32px x 32px. I varje cell finns det 5 avgränsningsrutor som var och en innehåller 5 funktioner (x, y, bredd, höjd, konfidens). Dessutom innehåller varje avgränsningsruta sannolikheten för var och en av klasserna, vilka i det här fallet är 20 till antalet. Därför innehåller varje cell 125 informationsdelar (5 funktioner + 20 klassannolikheter).-
Skapa en lista med ankare nedan channelStride för alla 5 avgränsningsrutor:
private float[] anchors = new float[]
{
1.08F, 1.19F, 3.42F, 4.41F, 6.63F, 11.38F, 9.42F, 5.11F, 16.62F, 10.52F
};
Ankare är fördefinierade höjd- och breddförhållanden för avgränsningsrutor. De flesta objekt eller klasser som identifieras av en modell har liknande förhållanden. Detta är värdefullt när det gäller att skapa avgränsningsrutor. I stället för att beräkna avgränsningsrutorna beräknas förskjutningen från de fördefinierade dimensionerna, vilket minskar den beräkning som krävs för att bestämma avgränsningsrutan. Normalt beräknas dessa fästpunktskvoter baserat på den datamängd som används. I det här fallet, eftersom datamängden är känd och värdena har förberäknats, kan fästpunkterna hårdkodas.
Definiera sedan de etiketter eller klasser som modellen ska förutsäga. Den här modellen förutsäger 20 klasser, vilket är en delmängd av det totala antalet klasser som förutsägs av den ursprungliga YOLOv2-modellen.
Lägg till listan med etiketter under anchors.
private string[] labels = new string[]
{
"aeroplane", "bicycle", "bird", "boat", "bottle",
"bus", "car", "cat", "chair", "cow",
"diningtable", "dog", "horse", "motorbike", "person",
"pottedplant", "sheep", "sofa", "train", "tvmonitor"
};
Det finns färger som är associerade med var och en av klasserna. Tilldela dina klassfärger under :labels
private static Color[] classColors = new Color[]
{
Color.Khaki,
Color.Fuchsia,
Color.Silver,
Color.RoyalBlue,
Color.Green,
Color.DarkOrange,
Color.Purple,
Color.Gold,
Color.Red,
Color.Aquamarine,
Color.Lime,
Color.AliceBlue,
Color.Sienna,
Color.Orchid,
Color.Tan,
Color.LightPink,
Color.Yellow,
Color.HotPink,
Color.OliveDrab,
Color.SandyBrown,
Color.DarkTurquoise
};
Skapa hjälpfunktioner
Det finns en rad steg som ingår i efterbearbetningsfasen. För att hjälpa till med detta kan flera hjälpmetoder användas.
De hjälpmetoder som används i av parsern är:
-
Sigmoidanvänder sigmoidfunktionen som matar ut ett tal mellan 0 och 1. -
Softmaxnormaliserar en indatavektor till en sannolikhetsfördelning. -
GetOffsetmappar element i den endimensionella modellens utdata till motsvarande position i en125 x 13 x 13tensor. -
ExtractBoundingBoxesextraherar avgränsningsrutans dimensioner med hjälp avGetOffsetmetoden från modellutdata. -
GetConfidenceextraherar konfidensvärdet som anger hur säker modellen är på att den har identifierat ett objekt och använderSigmoidfunktionen för att omvandla den till en procentandel. -
MapBoundingBoxToCellanvänder avgränsningsrutans dimensioner och mappar dem till sin respektive cell i bilden. -
ExtractClassesextraherar klassförutsägelserna för avgränsningsrutan från modellutdata med hjälp avGetOffsetmetoden och omvandlar dem till en sannolikhetsfördelning med hjälp avSoftmaxmetoden. -
GetTopResultväljer klassen i listan över förutsagda klasser med högst sannolikhet. -
IntersectionOverUnionfiltrerar överlappande avgränsningsrutor med lägre sannolikheter.
Lägg till koden för alla hjälpmetoder under listan med classColors.
private float Sigmoid(float value)
{
var k = (float)Math.Exp(value);
return k / (1.0f + k);
}
private float[] Softmax(float[] values)
{
var maxVal = values.Max();
var exp = values.Select(v => Math.Exp(v - maxVal));
var sumExp = exp.Sum();
return exp.Select(v => (float)(v / sumExp)).ToArray();
}
private int GetOffset(int x, int y, int channel)
{
// YOLO outputs a tensor that has a shape of 125x13x13, which
// WinML flattens into a 1D array. To access a specific channel
// for a given (x,y) cell position, we need to calculate an offset
// into the array
return (channel * this.channelStride) + (y * COL_COUNT) + x;
}
private BoundingBoxDimensions ExtractBoundingBoxDimensions(float[] modelOutput, int x, int y, int channel)
{
return new BoundingBoxDimensions
{
X = modelOutput[GetOffset(x, y, channel)],
Y = modelOutput[GetOffset(x, y, channel + 1)],
Width = modelOutput[GetOffset(x, y, channel + 2)],
Height = modelOutput[GetOffset(x, y, channel + 3)]
};
}
private float GetConfidence(float[] modelOutput, int x, int y, int channel)
{
return Sigmoid(modelOutput[GetOffset(x, y, channel + 4)]);
}
private CellDimensions MapBoundingBoxToCell(int x, int y, int box, BoundingBoxDimensions boxDimensions)
{
return new CellDimensions
{
X = ((float)x + Sigmoid(boxDimensions.X)) * CELL_WIDTH,
Y = ((float)y + Sigmoid(boxDimensions.Y)) * CELL_HEIGHT,
Width = (float)Math.Exp(boxDimensions.Width) * CELL_WIDTH * anchors[box * 2],
Height = (float)Math.Exp(boxDimensions.Height) * CELL_HEIGHT * anchors[box * 2 + 1],
};
}
public float[] ExtractClasses(float[] modelOutput, int x, int y, int channel)
{
float[] predictedClasses = new float[CLASS_COUNT];
int predictedClassOffset = channel + BOX_INFO_FEATURE_COUNT;
for (int predictedClass = 0; predictedClass < CLASS_COUNT; predictedClass++)
{
predictedClasses[predictedClass] = modelOutput[GetOffset(x, y, predictedClass + predictedClassOffset)];
}
return Softmax(predictedClasses);
}
private ValueTuple<int, float> GetTopResult(float[] predictedClasses)
{
return predictedClasses
.Select((predictedClass, index) => (Index: index, Value: predictedClass))
.OrderByDescending(result => result.Value)
.First();
}
private float IntersectionOverUnion(RectangleF boundingBoxA, RectangleF boundingBoxB)
{
var areaA = boundingBoxA.Width * boundingBoxA.Height;
if (areaA <= 0)
return 0;
var areaB = boundingBoxB.Width * boundingBoxB.Height;
if (areaB <= 0)
return 0;
var minX = Math.Max(boundingBoxA.Left, boundingBoxB.Left);
var minY = Math.Max(boundingBoxA.Top, boundingBoxB.Top);
var maxX = Math.Min(boundingBoxA.Right, boundingBoxB.Right);
var maxY = Math.Min(boundingBoxA.Bottom, boundingBoxB.Bottom);
var intersectionArea = Math.Max(maxY - minY, 0) * Math.Max(maxX - minX, 0);
return intersectionArea / (areaA + areaB - intersectionArea);
}
När du har definierat alla hjälpmetoder är det dags att använda dem för att bearbeta modellutdata.
IntersectionOverUnion Under metoden skapar ParseOutputs du metoden för att bearbeta utdata som genereras av modellen.
public IList<YoloBoundingBox> ParseOutputs(float[] yoloModelOutputs, float threshold = .3F)
{
}
Skapa en lista för att lagra dina avgränsningsrutor och definiera variabler i ParseOutputs-metoden.
var boxes = new List<YoloBoundingBox>();
Varje bild är indelad i ett rutnät med 13 x 13 celler. Varje cell innehåller fem avgränsningsrutor. Under variabeln boxes lägger du till kod för att bearbeta alla rutor i var och en av cellerna.
for (int row = 0; row < ROW_COUNT; row++)
{
for (int column = 0; column < COL_COUNT; column++)
{
for (int box = 0; box < BOXES_PER_CELL; box++)
{
}
}
}
I den innersta loopen beräknar man startpositionen för den aktuella rutan i den endimensionella modellens utdata.
var channel = (box * (CLASS_COUNT + BOX_INFO_FEATURE_COUNT));
Direkt under det använder du ExtractBoundingBoxDimensions metoden för att hämta dimensionerna för den aktuella avgränsningsrutan.
BoundingBoxDimensions boundingBoxDimensions = ExtractBoundingBoxDimensions(yoloModelOutputs, row, column, channel);
GetConfidence Använd sedan metoden för att få konfidensen för den aktuella avgränsningsrutan.
float confidence = GetConfidence(yoloModelOutputs, row, column, channel);
Därefter använder du MapBoundingBoxToCell metoden för att mappa den aktuella avgränsningsrutan till den aktuella cell som bearbetas.
CellDimensions mappedBoundingBox = MapBoundingBoxToCell(row, column, box, boundingBoxDimensions);
Innan du utför ytterligare bearbetning kontrollerar du om ditt konfidensvärde är större än det angivna tröskelvärdet. Om inte, bearbeta nästa avgränsningsruta.
if (confidence < threshold)
continue;
Annars fortsätter du att bearbeta utdata. Nästa steg är att få sannolikhetsfördelningen för de förutsagda klasserna för den aktuella avgränsningsrutan med ExtractClasses-metoden.
float[] predictedClasses = ExtractClasses(yoloModelOutputs, row, column, channel);
Använd GetTopResult sedan metoden för att hämta värdet och indexet för klassen med den högsta sannolikheten för den aktuella rutan och beräkna dess poäng.
var (topResultIndex, topResultScore) = GetTopResult(predictedClasses);
var topScore = topResultScore * confidence;
Använd om du topScore vill behålla endast de avgränsningsrutor som ligger över det angivna tröskelvärdet.
if (topScore < threshold)
continue;
Slutligen, om den aktuella avgränsningsrutan överskrider tröskelvärdet, skapa ett nytt BoundingBox-objekt och lägg till det i listan boxes.
boxes.Add(new YoloBoundingBox()
{
Dimensions = new BoundingBoxDimensions
{
X = (mappedBoundingBox.X - mappedBoundingBox.Width / 2),
Y = (mappedBoundingBox.Y - mappedBoundingBox.Height / 2),
Width = mappedBoundingBox.Width,
Height = mappedBoundingBox.Height,
},
Confidence = topScore,
Label = labels[topResultIndex],
BoxColor = classColors[topResultIndex]
});
När alla celler i bilden har bearbetats returnerar du boxes listan. Lägg till följande retursats under den yttre mest for-loopen i ParseOutputs -metoden.
return boxes;
Filtrera överlappande rutor
Nu när alla avgränsningsrutor med hög säkerhet har extraherats från modellutdata måste ytterligare filtrering göras för att ta bort överlappande bilder. Lägg till en metod som heter FilterBoundingBoxes under ParseOutputs metoden:
public IList<YoloBoundingBox> FilterBoundingBoxes(IList<YoloBoundingBox> boxes, int limit, float threshold)
{
}
FilterBoundingBoxes I metoden börjar du med att skapa en matris som är lika med storleken på identifierade rutor och markera alla platser som aktiva eller redo för bearbetning.
var activeCount = boxes.Count;
var isActiveBoxes = new bool[boxes.Count];
for (int i = 0; i < isActiveBoxes.Length; i++)
isActiveBoxes[i] = true;
Sortera sedan listan som innehåller dina avgränsningsrutor i fallande ordning baserat på konfidens.
var sortedBoxes = boxes.Select((b, i) => new { Box = b, Index = i })
.OrderByDescending(b => b.Box.Confidence)
.ToList();
Därefter skapar du en lista som innehåller de filtrerade resultaten.
var results = new List<YoloBoundingBox>();
Börja bearbeta varje avgränsningsruta genom att iterera över var och en av avgränsningsrutorna.
for (int i = 0; i < boxes.Count; i++)
{
}
I den här for-loopen kontrollerar du om den aktuella avgränsningsrutan kan hanteras.
if (isActiveBoxes[i])
{
}
I så fall lägger du till avgränsningsrutan i listan med resultat. Om resultatet överskrider den angivna gränsen för rutor som ska extraheras bryter du ut från loopen. Lägg till följande kod i if-instruktionen.
var boxA = sortedBoxes[i].Box;
results.Add(boxA);
if (results.Count >= limit)
break;
Annars kan du titta på de intilliggande avgränsningsrutorna. Lägg till följande kod under gränskontrollen.
for (var j = i + 1; j < boxes.Count; j++)
{
}
Precis som den första rutan, om den intilliggande rutan är aktiv eller redo att bearbetas, använder du IntersectionOverUnion metoden för att kontrollera om den första rutan och den andra rutan överskrider det angivna tröskelvärdet. Lägg till följande kod i din innersta for-loop.
if (isActiveBoxes[j])
{
var boxB = sortedBoxes[j].Box;
if (IntersectionOverUnion(boxA.Rect, boxB.Rect) > threshold)
{
isActiveBoxes[j] = false;
activeCount--;
if (activeCount <= 0)
break;
}
}
Utanför den innersta for-loopen som kontrollerar närliggande avgränsningsrutor, kontrollera om det finns några återstående avgränsningsrutor som ska bearbetas. Annars bryter du ut ur den yttre for-loopen.
if (activeCount <= 0)
break;
Slutligen returnerar du resultatet utanför den inledande for-loopen för FilterBoundingBoxes metoden:
return results;
Toppen! Nu är det dags att använda den här koden tillsammans med modellen för bedömning.
Använda modellen för bedömning
Precis som vid efterbearbetning finns det några steg i bedömningsstegen. För att hjälpa till med detta lägger du till en klass som innehåller bedömningslogik i projektet.
Högerklicka på projektet i Prieskumník riešení och välj sedan Lägg till>nytt objekt.
I dialogrutan Lägg till nytt objekt väljer du Klass och ändrar fältet Namn till OnnxModelScorer.cs. Välj sedan Lägg till.
Filen OnnxModelScorer.cs öppnas i kodredigeraren. Lägg till följande
usingdirektiv överst i OnnxModelScorer.cs:using System; using System.Collections.Generic; using System.Linq; using Microsoft.ML; using Microsoft.ML.Data; using ObjectDetection.DataStructures; using ObjectDetection.YoloParser;Lägg till följande variabler i
OnnxModelScorerklassdefinitionen.private readonly string imagesFolder; private readonly string modelLocation; private readonly MLContext mlContext; private IList<YoloBoundingBox> _boundingBoxes = new List<YoloBoundingBox>();Direkt under det skapar du en konstruktor för klassen
OnnxModelScorersom initierar de tidigare definierade variablerna.public OnnxModelScorer(string imagesFolder, string modelLocation, MLContext mlContext) { this.imagesFolder = imagesFolder; this.modelLocation = modelLocation; this.mlContext = mlContext; }När du har skapat konstruktorn definierar du ett par structs som innehåller variabler relaterade till bild- och modellinställningarna. Skapa en struct med namnet
ImageNetSettingsför att innehålla den höjd och bredd som förväntas som indata för modellen.public struct ImageNetSettings { public const int imageHeight = 416; public const int imageWidth = 416; }Därefter skapar du en annan struct med namnet
TinyYoloModelSettingssom innehåller namnen på modellens indata- och utdataskikt. Om du vill visualisera namnet på indata- och utdataskikten i modellen kan du använda ett verktyg som Netron.public struct TinyYoloModelSettings { // for checking Tiny yolo2 Model input and output parameter names, //you can use tools like Netron, // which is installed by Visual Studio AI Tools // input tensor name public const string ModelInput = "image"; // output tensor name public const string ModelOutput = "grid"; }Skapa sedan den första uppsättningen metoder som används för bedömning.
LoadModelSkapa -metoden i klassenOnnxModelScorer.private ITransformer LoadModel(string modelLocation) { }LoadModelI metoden lägger du till följande kod för loggning.Console.WriteLine("Read model"); Console.WriteLine($"Model location: {modelLocation}"); Console.WriteLine($"Default parameters: image size=({ImageNetSettings.imageWidth},{ImageNetSettings.imageHeight})");ML.NET pipelines måste känna till dataschemat som ska användas när
Fitmetoden anropas. I det här fallet används en process som liknar utbildning. Men eftersom ingen faktisk utbildning sker är det acceptabelt att använda en tomIDataView. Skapa en nyIDataViewför pipelinen från en tom lista.var data = mlContext.Data.LoadFromEnumerable(new List<ImageNetData>());Under det definierar du pipelinen. Pipelinen består av fyra transformeringar.
-
LoadImagesläser in bilden som en bitmapp. -
ResizeImagesomskalar bilden till den angivna storleken (i det här fallet416 x 416). -
ExtractPixelsändrar bildpunktsrepresentationen av bilden från en bitmapp till en numerisk vektor. -
ApplyOnnxModelläser in ONNX-modellen och använder den för att poängsätta de data som tillhandahålls.
Important
Använd endast modeller från betrodda källor. Att tillämpa modeller från ej betrodda källor är en säkerhetsrisk.
Definiera din pipeline i
LoadModelmetoden under variabelndata.var pipeline = mlContext.Transforms.LoadImages(outputColumnName: "image", imageFolder: "", inputColumnName: nameof(ImageNetData.ImagePath)) .Append(mlContext.Transforms.ResizeImages(outputColumnName: "image", imageWidth: ImageNetSettings.imageWidth, imageHeight: ImageNetSettings.imageHeight, inputColumnName: "image")) .Append(mlContext.Transforms.ExtractPixels(outputColumnName: "image")) .Append(mlContext.Transforms.ApplyOnnxModel(modelFile: modelLocation, outputColumnNames: new[] { TinyYoloModelSettings.ModelOutput }, inputColumnNames: new[] { TinyYoloModelSettings.ModelInput }));Nu är det dags att instansiera modellen för bedömning.
FitAnropa metoden i pipelinen och returnera den för vidare bearbetning.var model = pipeline.Fit(data); return model;-
När modellen har lästs in kan den sedan användas för att göra förutsägelser. Skapa en metod som kallas PredictDataUsingModel under metoden för att underlätta processen LoadModel .
private IEnumerable<float[]> PredictDataUsingModel(IDataView testData, ITransformer model)
{
}
PredictDataUsingModelI lägger du till följande kod för loggning.
Console.WriteLine($"Images location: {imagesFolder}");
Console.WriteLine("");
Console.WriteLine("=====Identify the objects in the images=====");
Console.WriteLine("");
Transform Använd sedan metoden för att poängsätta data.
IDataView scoredData = model.Transform(testData);
Extrahera de förväntade sannolikheterna och returnera dem för ytterligare bearbetning.
IEnumerable<float[]> probabilities = scoredData.GetColumn<float[]>(TinyYoloModelSettings.ModelOutput);
return probabilities;
Nu när båda stegen har konfigurerats kombinerar du dem till en enda metod.
PredictDataUsingModel Under metoden lägger du till en ny metod med namnet Score.
public IEnumerable<float[]> Score(IDataView data)
{
var model = LoadModel(modelLocation);
return PredictDataUsingModel(data, model);
}
Nästan där! Nu är det dags att använda allt.
Identifiera objekt
Nu när hela installationen är klar är det dags att identifiera vissa objekt.
Poängsätta och parsa modellutdata
Lägg till en try-catch-instruktion under skapandet av variabeln mlContext .
try
{
}
catch (Exception ex)
{
Console.WriteLine(ex.ToString());
}
I blocket try börjar du implementera logiken för objektidentifiering. Läs först in data i en IDataView.
IEnumerable<ImageNetData> images = ImageNetData.ReadFromFile(imagesFolder);
IDataView imageDataView = mlContext.Data.LoadFromEnumerable(images);
Skapa sedan en instans av OnnxModelScorer och använd den för att poängsätta inlästa data.
// Create instance of model scorer
var modelScorer = new OnnxModelScorer(imagesFolder, modelFilePath, mlContext);
// Use model to score data
IEnumerable<float[]> probabilities = modelScorer.Score(imageDataView);
Nu är det dags för efterbearbetningssteget. Skapa en instans av YoloOutputParser och använd den för att bearbeta modellutdata.
YoloOutputParser parser = new YoloOutputParser();
var boundingBoxes =
probabilities
.Select(probability => parser.ParseOutputs(probability))
.Select(boxes => parser.FilterBoundingBoxes(boxes, 5, .5F));
När modellutdata har bearbetats är det dags att rita avgränsningsrutorna på bilderna.
Visualisera förutsägelser
Efter att modellen har bedömt bilderna och utdata har bearbetats måste markeringsrutorna ritas på bilden. Det gör du genom att lägga till en metod som kallas DrawBoundingBox under GetAbsolutePath metoden inuti Program.cs.
void DrawBoundingBox(string inputImageLocation, string outputImageLocation, string imageName, IList<YoloBoundingBox> filteredBoundingBoxes)
{
}
Läs först in bilden och hämta måtten för höjd och bredd i DrawBoundingBox metoden.
Image image = Image.FromFile(Path.Combine(inputImageLocation, imageName));
var originalImageHeight = image.Height;
var originalImageWidth = image.Width;
Skapa sedan en for-each-loop för att iterera över var och en av de avgränsningsrutor som identifierats av modellen.
foreach (var box in filteredBoundingBoxes)
{
}
Inuti for-each-loopen hämtar du dimensionerna för avgränsningsrutan.
var x = (uint)Math.Max(box.Dimensions.X, 0);
var y = (uint)Math.Max(box.Dimensions.Y, 0);
var width = (uint)Math.Min(originalImageWidth - x, box.Dimensions.Width);
var height = (uint)Math.Min(originalImageHeight - y, box.Dimensions.Height);
Eftersom avgränsningsrutans dimensioner motsvarar modellindata 416 x 416, ska du skala avgränsningsrutans dimensioner för att matcha bildens faktiska storlek.
x = (uint)originalImageWidth * x / OnnxModelScorer.ImageNetSettings.imageWidth;
y = (uint)originalImageHeight * y / OnnxModelScorer.ImageNetSettings.imageHeight;
width = (uint)originalImageWidth * width / OnnxModelScorer.ImageNetSettings.imageWidth;
height = (uint)originalImageHeight * height / OnnxModelScorer.ImageNetSettings.imageHeight;
Definiera sedan en mall för text som visas ovanför varje avgränsningsruta. Texten kommer att innehålla objektets klass inuti respektive avgränsningsruta samt självsäkerheten.
string text = $"{box.Label} ({(box.Confidence * 100).ToString("0")}%)";
Om du vill rita på bilden konverterar du den till ett Graphics objekt.
using (Graphics thumbnailGraphic = Graphics.FromImage(image))
{
}
I kodblocket using justerar du grafikens Graphics objektinställningar.
thumbnailGraphic.CompositingQuality = CompositingQuality.HighQuality;
thumbnailGraphic.SmoothingMode = SmoothingMode.HighQuality;
thumbnailGraphic.InterpolationMode = InterpolationMode.HighQualityBicubic;
Under detta anger du teckensnitts- och färgalternativen för text- och avgränsningsrutan.
// Define Text Options
Font drawFont = new Font("Arial", 12, FontStyle.Bold);
SizeF size = thumbnailGraphic.MeasureString(text, drawFont);
SolidBrush fontBrush = new SolidBrush(Color.Black);
Point atPoint = new Point((int)x, (int)y - (int)size.Height - 1);
// Define BoundingBox options
Pen pen = new Pen(box.BoxColor, 3.2f);
SolidBrush colorBrush = new SolidBrush(box.BoxColor);
Skapa och fyll en rektangel ovanför avgränsningsrutan för att innehålla texten med hjälp av FillRectangle metoden. Detta hjälper till att kontrastera texten och förbättra läsbarheten.
thumbnailGraphic.FillRectangle(colorBrush, (int)x, (int)(y - size.Height - 1), (int)size.Width, (int)size.Height);
Rita sedan text- och avgränsningsrutan på bilden genom att använda metoderna DrawString och DrawRectangle.
thumbnailGraphic.DrawString(text, drawFont, fontBrush, atPoint);
// Draw bounding box on image
thumbnailGraphic.DrawRectangle(pen, x, y, width, height);
Utanför for-each-loopen lägger du till kod för att spara bilderna i outputFolder.
if (!Directory.Exists(outputImageLocation))
{
Directory.CreateDirectory(outputImageLocation);
}
image.Save(Path.Combine(outputImageLocation, imageName));
Om du vill ha ytterligare feedback om att programmet gör förutsägelser som förväntat vid körningen lägger du till en metod som heter LogDetectedObjects under DrawBoundingBox metoden i Program.cs-filen för att mata ut de identifierade objekten till konsolen.
void LogDetectedObjects(string imageName, IList<YoloBoundingBox> boundingBoxes)
{
Console.WriteLine($".....The objects in the image {imageName} are detected as below....");
foreach (var box in boundingBoxes)
{
Console.WriteLine($"{box.Label} and its Confidence score: {box.Confidence}");
}
Console.WriteLine("");
}
Nu när du har hjälpmetoder för att skapa visuell feedback från förutsägelserna lägger du till en for-loop för att iterera över var och en av de poängsatta bilderna.
for (var i = 0; i < images.Count(); i++)
{
}
I for-loopen hämtar du namnet på bildfilen och de avgränsningsrutor som är associerade med den.
string imageFileName = images.ElementAt(i).Label;
IList<YoloBoundingBox> detectedObjects = boundingBoxes.ElementAt(i);
Under detta använder du DrawBoundingBox metoden för att rita avgränsningsrutorna på bilden.
DrawBoundingBox(imagesFolder, outputFolder, imageFileName, detectedObjects);
Slutligen använder du LogDetectedObjects metoden för att mata ut förutsägelser till konsolen.
LogDetectedObjects(imageFileName, detectedObjects);
Efter try-catch-instruktionen lägger du till extra logik som visar att processen har körts klart.
Console.WriteLine("========= End of Process..Hit any Key ========");
Det var allt!
Results
När du har följt föregående steg kör du konsolappen (Ctrl + F5). Resultatet bör likna följande utdata. Du kan se varningar eller meddelanden om bearbetning, men dessa meddelanden har tagits bort från följande resultat för att underlätta förståelsen.
=====Identify the objects in the images=====
.....The objects in the image image1.jpg are detected as below....
car and its Confidence score: 0.9697262
car and its Confidence score: 0.6674225
person and its Confidence score: 0.5226039
car and its Confidence score: 0.5224892
car and its Confidence score: 0.4675332
.....The objects in the image image2.jpg are detected as below....
cat and its Confidence score: 0.6461141
cat and its Confidence score: 0.6400049
.....The objects in the image image3.jpg are detected as below....
chair and its Confidence score: 0.840578
chair and its Confidence score: 0.796363
diningtable and its Confidence score: 0.6056048
diningtable and its Confidence score: 0.3737402
.....The objects in the image image4.jpg are detected as below....
dog and its Confidence score: 0.7608147
person and its Confidence score: 0.6321323
dog and its Confidence score: 0.5967442
person and its Confidence score: 0.5730394
person and its Confidence score: 0.5551759
========= End of Process..Hit any Key ========
Om du vill se bilderna med avgränsningsrutor går du till assets/images/output/ katalogen. Nedan visas ett exempel från en av de bearbetade bilderna.

Grattis! Nu har du skapat en maskininlärningsmodell för objektidentifiering genom att återanvända en förtränad ONNX modell i ML.NET.
Du hittar källkoden för den här handledningen på lagringsplatsen dotnet/machinelearning-samples.
I den här handledningen lärde du dig att:
- Förstå problemet
- Lär dig vad ONNX är och hur det fungerar med ML.NET
- Förstå modellen
- Återanvänd den förtränad modellen
- Identifiera objekt med en inläst modell
Kolla in GitHub-lagringsplatsen strojové učenie-exempel för att utforska ett utökat objektidentifieringsexempel.
Samarbeta med oss på GitHub
Källan för det här innehållet finns på GitHub, där du även kan skapa och granska ärenden och pull-begäranden. Se vår deltagarguide för mer information.