Förutse kundens livstidsvärde
Förutse potentiellt värde (intäkt) som enskilda aktiva kunder ger verksamheten under en angiven tidsperiod i framtiden. Denna förutsägelse hjälper dig:
- Identifiera kunder med högt värde och bearbeta den här insikten.
- Skapa strategiska kundsegment utifrån deras potentiella värde för att köra anpassade kampanjer med riktad försäljning, marknadsföring och support.
- Vägleder produktutveckling genom att fokusera på funktioner som ökar kundvärdet.
- Optimera försäljnings- eller marknadsföringsstrategin och fördela budgeten på ett bättre sätt för att nå kunderna.
- Identifiera och uppmärksamma kunder med högt värde genom lojalitets- eller belöningsprogram.
Bestäm vad CLV betyder för din verksamhet. Vi stöder transaktionsbaserad förutsägelse av kundens livstidsvärde. Det förutsagda värdet för en kund baseras på transaktionshistoriken. Överväga att skapa flera modeller med olika indatainställningar och jämföra modellresultat för att se vilket modellscenario som passar dina affärsbehov bäst.
Dricks
Prova CLV-prediktion exempeldata: CLV (kundens livstidsvärde) prediktion exempelguide.
Förutsättningar
- Åtminstone deltagarbehörigheter
- Minst 1 000 kundprofiler i det önskade prognosfönstret
- Kundidentifierare, en unik identifierare som matchar transaktioner till en enskild kund
- Minst ett års transaktionshistorik, helst två till tre år. Vilket minst två till tre transaktioner per kund-ID, helst över flera datum. Transaktionshistoriken måste innehålla:
- Transaktions-ID: Unik identifierare för varje transaktion
- Transaktionsdatum: Datum eller tidstämpel för varje transaktion
- Transaktionsbelopp: Penningvärde (till exempel omsättning eller vinstmarginal) för varje transaktion
- Etikett tilldelad för returer: Booleskt true/false värde som anger om transaktionen är en retur
- Produkt-ID: Produkt-ID för produkten som är inblandad i transaktionen
- Data om kundaktiviteter:
- Primärnyckel: En unik identifierare för en aktivitet
- Tidsstämpel: Datum och tid för händelsen som identifierats av primärnyckeln
- Händelse (aktivitetsnamn): Namnet på händelsen som du vill använda
- Detaljer (belopp eller värde): Information om kundaktiviteten
- Ytterligare data som:
- Webbaktiviteter: webbplatsbesökshistorik, e-posthistorik
- Lojalitetsaktiviteter: insamlade lojalitetspoäng och inlösningshistorik
- Kundtjänstlogg, servicesamtal, klagomål eller returhistorik
- Information om kundprofil
- Mindre än 20 % saknade värden i obligatoriska fält
Kommentar
Det går bara att konfigurera en tabell för transaktionshistorik. Om det finns flera tabeller för inköp eller transaktion kan du kombinera dem i Power Query före datainmatningen.
Skapa en förutsägelse av kundens livstidsvärde
Välj Spara utkast om du vill prediktion utkast. Förutsägelseutkastet visas i fliken Mina förutsägelser.
Gå till Insikter>Prediktioner.
På fliken Skapa, välj Använd modell på panelen Kundens livstidsvärde.
Välj Komma igång.
Ge modellen och utdatatabellen ett namn för att särskilja dem från andra modeller eller tabeller.
Välj Nästa.
Definiera modellinställningar
Ange en tidsperiod för förutsägelse för att definiera hur långt in i framtiden som du vill förutse kundens livstidsvärde. Som standard anges enheten som månader.
Dricks
För att korrekt kunna förutse kundens livstidsvärde för den tidsperiod du anger behöver du en jämförbar period av historiska data. Om du till exempel vill förutse CLV för de kommande 12 månaderna att du har minst 18–24 månaders historisk information.
Ange tidsramen inom vilken en kund måste ha minst en transaktion för att anses vara aktiv. Modellen förutser kundens livstid för aktiva kunder.
- Låt modellen beräkna inköpsintervall (rekommenderas): Modellen analyserar dina data och fastställer en tidsperiod utifrån tidigare köp.
- Ange intervall manuellt: Tidsperiod för definitionen av en aktiv kund.
Definiera percentilen för kunder med högt värde.
- Modellberäkning (rekommenderas): Modellen använder 80/20-regel. Den procentandel kunder som under den historiska perioden har bidragit med 80 % av den kumulativa omsättningen för företaget betraktas som kunder med högt värde. Normalt bidrar mindre än 30–40 % av kunderna till en kumulativ omsättning på 80 %. Antalet kan dock variera beroende på ditt företag och din bransch.
- Procent av de mest aktiva kunderna: Specifik percentil för en kund med högt värde. Ange till exempel 25för att definiera kunder med högt värde som de översta 25 % av framtida betalande kunder.
Om ditt företag definierar kunder med högt värde på ett annat sätt, meddela oss, då vi gärna vill veta om det.
Välj Nästa.
Lägg till obligatoriska data
Välj Lägg till data för Historik för kundtransaktioner.
Välj typ av semantisk aktivitet SalesOrder eller SalesOrderLine, som innehåller transaktionshistorik. Om aktiviteten inte har ställts in väljer du här och skapar den.
Under Aktiviteter, om aktivitetsattributen var semantiskt mappade när aktiviteten skapades, välj de specifika attributen eller tabeller som du vill att beräkningen ska fokusera på. Om ingen mappning har inträffat väljer du Redigera och mappar dina data.
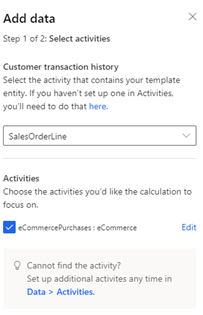
Välj Nästa och granska attributen som krävs för modellen.
Välj Spara.
Lägg till fler aktiviteter eller välj Näst.
Lägg till valfri aktivitetsdata
För data som återspeglar viktiga kundinteraktioner (som webb-, kundtjänst- och händelseloggar) läggs sammanhang till i transaktionsposter. Fler mönster i dina kundaktivitetsdata kan förbättra precisionen för förutsägelserna.
Välj Lägg data under Skapa bättre modellinsikter med ytterligare aktivitetsdata.
Välj en aktivitetstyp som överensstämmer med den typ av kundaktivitet du lägger till. Om aktiviteten inte har ställts in väljer du här och skapar den.
Under Aktiviteter, om aktivitetsattributen var mappade när aktiviteten skapades, välj de specifika attributen eller tabellen som du vill att beräkningen ska fokusera på. Om ingen mappning har inträffat väljer du Redigera och mappar dina data.
Välj Nästa och granska attributen som krävs för modellen.
Välj Spara.
Välj Nästa.
Lägg till valfria kunddata eller välj Nästa och gå till Ange uppdateringsschema.
Lägg till ytterligare kunddata
Välj bland de 18 vanliga kundprofilattribut som ska ingå som indata i modellen. De här attributen kan leda till mer anpassade, relevanta och användbara modellresultat för ärenden som används i företaget.
Exempel: Contoso Coffee vill rikta kundens livstidsvärde till kunder med ett anpassat erbjudande om lanseringen av den nya automaten. Contoso använder CLV-modellen och lägger till alla 18 kundprofilattribut för att se vilka faktorer som påverkar kundernas högsta värde. De tycker att kundens plats är den mest inflytelserika faktorn för dessa kunder. Med den här informationen ordnar de en lokal händelse för lanseringen av maskinen och samarbetar med lokala leverantörer för personliga erbjudanden och en speciell upplevelse på händelse. Utan den här informationen kanske Contoso bara har skickat generiska marknadsföringsmeddelanden och missade möjligheten att anpassa för detta lokala segment av deras kunder med högt värde.
Välj Lägg till data under Skapa ännu bättre modellinsikter med ytterligare kunddata.
För Tabell, välj Kund: Customer Insights för att välja den enhetliga kundprofilen som mappas till kundattributdata. För Kund-ID, välj System.Customer.CustomerId.
Mappa fler fält om data är tillgängliga i dina enhetliga kundprofiler.
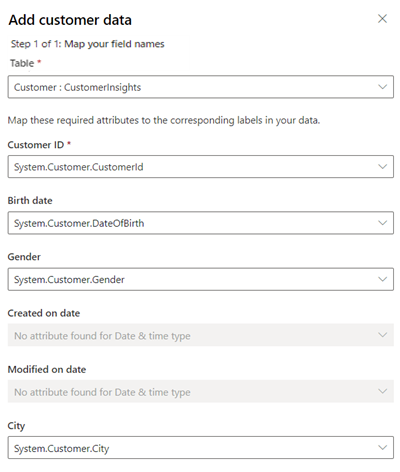
Välj Spara.
Välj Nästa.
Ange uppdateringsschema
Välj frekvens för att träna om din modell baserat på de senaste uppgifterna. Den här inställningen är viktig för att uppdatera noggrannheten i förutsägelser när nya data matas in. De flesta företag kan träna om en gång i månaden och få en god exakthet för sina förutsägelser.
Välj Nästa.
Granska och köra modellkonfigurationen
Steget Granska och kör visar en sammanfattning av konfigurationen och ger en chans att göra ändringar innan du skapar förutsägelse.
Välj Redigera på något av stegen för att granska och göra eventuella ändringar.
Om du är nöjd med dina val, välj Spara och kör för att starta modellen. Välj Klar. Fliken Mina prognoser visas när prediktion skapas. Det kan ta flera timmar att slutföra processen beroende på mängden data som används i förutsägelsen.
Dricks
Det finns statusar för uppgifter och processer. De flesta processer är beroende av andra processförlopp, t.ex. datakällor och uppdateringar av dataprofiler.
Välj status för att öppna rutan Förloppsinformation och se framstegen för uppgifter. Om du vill avbryta jobbet väljer du Avbryt jobbet längst ned i fönstret.
Under varje uppgift kan du välja Visa information om du vill ha mer förloppsinformation, till exempel bearbetningstid, senaste bearbetningsdatum och eventuella tillämpliga fel och varningar för uppgiften eller processen. Välj Visa systemstatus längst ned i panelen om du vill se andra processer i systemet.
Visa förutsägelsens resultat
Gå till Insikter>Prediktioner.
På fliken Mina förutsägelser, välj den förutsägelse du vill visa.
Det finns tre primära dataområden på resultatsidan.
Prestanda för övningsmodell: Betyget A, B eller C indikerar prestandan för förutsägelsen och kan hjälpa dig att fatta beslutet att använda de resultat som är lagrade i utdatatabellen.
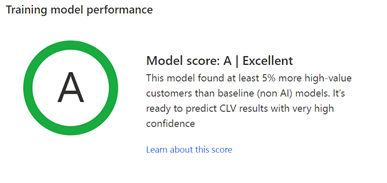
Systemet bedömer hur AI-modellen presterade för att förutsäga kunder med högt värde jämfört med en baslinjemodell.
Betyg fastställs utifrån följande regler:
- A när modellen korrekt förutsade minst 5 % fler kunder med högt värde jämfört med grundmodellen.
- B när modellen korrekt förutsade mellan 0 och 5 % fler kunder med högt värde jämfört med grundmodellen.
- C när modellen korrekt förutsade färre kunder med högt värde än grundmodellen.
Välj Läs om den här poängen för att öppna Modellbetyg som visar ytterligare detaljer om AI-modellens prestanda och grundmodellen. Det hjälper dig bättre förstå de underliggande måtten för modellprestandan och hur det slutliga modellprestandabetyget sattes. Grundmodellen bygger på en icke-AI-baserad metod för beräkning av kundens livstidsvärde, främst baserat på tidigare köp som gjorts av kunder.
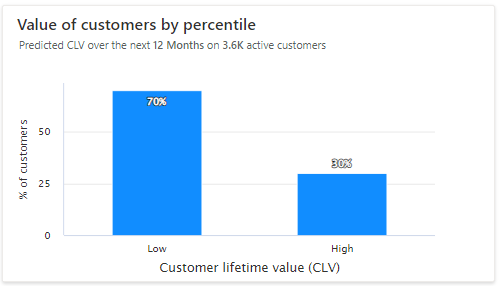
Kundernas värde efter percentil: Kunder med låg eller högt värde visas i ett diagram. Håll markör över staplarna i histogrammet kan du se antalet kunder i varje grupp och det genomsnittliga kundlivstidsvärdet för gruppen. Alternativ, skapa kundsegment utifrån förutsägelser av kundens livstidsvärde.
Mest inflytelserika faktorer: Olika faktorer beaktas när du skapar förutsägelser av kundens livstidsvärde baserat på indata till AI-modellen. Betydelsen för var och en av faktorerna beräknas för de ansamlade förutsägelser som skapas av en modell. Använda dessa faktorer för att validera resultatet av en förutsägelse. Dessa faktorer ger också en bättre inblick i de mest inflytelserika faktorerna som bidrog till förutsägelsen av kundens livtidsvärde för alla dina kunder.

Läs om den här poängen
Standardformeln som används för att beräkna kundens livstidsvärde enligt grundmodellen:
Kundens livstidsvärde för varje kund = Genomsnittligt månatligt köp som gjorts av kunden i det aktiva kundfönstret * Antal månader i perioden för förutsägelse av kundens livstidsvärde * Övergripande kvarhållning av alla kunder
AI-modellen jämförs med grundmodellen utifrån två prestandamått.
Andel lyckade försök med att förutse kunder med högt värde
Se skillnaden mellan att förutse kunder med högt värde med AI-modellen jämfört med grundmodellen. En framgångsfrekvens på 84 % innebär till exempel att av alla kunder med högt värde i utbildningsdata kunde AI-modellen samla in 84 %. Sedan jämför vi den här framgångsfrekvensen med grundmodellens framgångsfrekvens och rapporterar den relativa förändringen. Det här värdet används för att tilldela modellen ett betyg.
Felmått
Granska modellens övergripande prestanda när det gäller fel vid förutsägelse av framtida värden. Vi använder det övergripande RMSE-måttet (Root Mean Squared Error) för att utvärdera felet. RMSE är ett standardiserat sätt att mäta fel i en modell när det gäller att förutse kvantitativa data. AI-modellens RMSE jämförs med RMSE för grundmodellen och den relativa skillnaden rapporteras.
AI-modellen prioriterar korrekt rangordning av kunder enligt det värde de ger verksamheten. Endast framgångsfrekvensen för förutsägelse av kunder med högt värde används för att få det slutliga modellbetyget. RMSE-måttet är känsligt för extremvärden. Om det finns en mindre procentandel kunder med extremt stora köpvärden kanske det övergripande RMSE-måttet inte ger en fullständig bild av modellens prestanda.