Översikt över jobb för import och export av data
För att skapa och hantera dataimport- och dataexportjobb kan du använda arbetsytan Datahantering. Som standard skapar processen för dataimport och -export ett mellanlagringsregister för varje enhet i måldatabasen. Med tillfälliga register kan du kontrollera, rensa eller konvertera data innan du flyttar dem.
Notering
I den här artikeln förutsätts att du känner till datatabeller.
Process för dataimport och -export
Här följer stegen för att importera eller exportera data.
Skapa ett import- eller exportjobb där du vill göra följande:
- Definiera projektkategorin.
- Leta upp de enheter som du vill importera eller exportera.
- Ange dataformat för jobbet.
- Ordna enheterna så att de behandlas i logiska grupper och i den serie som passar.
- Bestäm om du vill använda tillfälliga register.
Validera att källdata och måldata mappas korrekt.
Kontrollera säkerheten för import- eller exportjobbet.
Kör import- eller exportjobbet.
Validera att jobbet har körts som förväntat genom att granska jobbhistoriken.
Rensa tillfälliga register.
Övriga avsnitt i den här artikeln innehåller mer information om varje steg i processen.
Obs
Använd ikonen Uppdatera formuläret för att uppdatera importera/exportera formuläret och se senaste status. Att uppdatera webbläsaren rekommenderas inte eftersom det avbryter alla import/export-jobb som inte körs i en batch.
Skapa ett import- eller exportjobb
Ett dataimport- eller -exportjobb kan köras en gång eller flera gånger.
Definiera projektkategorin
Vi rekommenderar att du lägger tid på att välja en lämplig projektkategori för ditt import- eller exportjobb. Projektkategorier hjälper dig att hantera relaterade jobb.
Leta upp de enheter som du vill importera eller exportera
Du kan lägga till specifika enheter i import- eller exportjobb eller välja den mall som ska användas. Mallar fyller ett projekt med en lista över enheter. Alternativet Tillämpa mall blir tillgängligt när du namnger ett jobb och spara det.
Ange dataformat för jobbet
När du väljer en enhet markerar du format för de data som ska exporteras eller importeras. Du definierar format via panelen Inställningar för datakälla. Ett dataformat för källan är en kombination av typ, filformat, radavgränsare och kolumnavgränsare. Det finns även andra attribut, men dessa är viktiga att förstå. I tabellen här nedanför listas giltiga kombinationer.
| Filformat | Rad/kolumnavgränsare | XML-format |
|---|---|---|
| Excel | Excel | -NA- |
| XML | -NA- | XML-element XML-attribut |
| Avgränsad, fast bredd | Komma, semikolon, flik, lodrätt streck, kolon | -NA- |
Obs
Det är viktigt att välja rätt värde för Radavgränsare, Kolumnavgränsare och Textkvalifierare, om alternativet Filformat anges till Avgränsat. Kontrollera att dina data inte innehåller det tecken som används som avgränsare eller kvalificerare, eftersom detta kan leda till fel under import och export.
Notering
Se till att endast använda juridiska tecken för XML-baserade filformat. Mer information om giltiga tecken finns i Giltiga tecken i XML 1.0. XML 1.0 tillåter inte några kontrolltecken förutom flikar, kundvagnsreturer och radmatningar. Exempel på otillåtna tecken är hakparenteser, klammerparenteser och snedstreck.
Använd Unicode istället för en specifik teckentabell för att importera eller exportera data. Detta kommer att ge de mest konsekventa resultaten och eliminera datahanteringsjobb om de innehåller Unicode-tecken. De systemdefinierade källdataformaten som använder Unicode har alla Unicode i källnamnet. Unicode-formatet tillämpas genom att välja en Unicode-kodande ANSI-kodtabell som Kodsida på fliken Nationella inställningar. Välj en av följande teckensidor för Unicode:
| Kodsida | Visningsnamn |
|---|---|
| 1200 | Unicode |
| 12000 | Unicode (UTF-32) |
| 12001 | Unicode (UTF-32 Big-Endian) |
| 1201 | Unicode (Big-Endian) |
| 65000 | Unicode (UTF-7) |
| 65001 | Unicode (UTF-8) |
Mer information om kodsidor finns i Kodsida-identifierare.
Ordna enheterna
Enheter kan ordnas i en datamall eller i import- och exportjobb. När du kör ett jobb som innehåller mer än en datatabell måste du kontrollera att datatabellerna har ordnats korrekt. Du ordnar entiteter i första hand så att du kan lösa eventuella funktionella samband mellan olika enheter. Om enheterna inte har några funktionella samband kan de schemaläggas parallell import eller export.
Körningsenheter, -nivåer och -sekvenser
Körningsenheten, nivån i körningsenheten samt en enhets ordningsföljd hjälper till att styra i vilken serie som data exportera eller importeras.
- Enheter i olika körningsenheter behandlas parallellt.
- Om enheterna har samma nivå bearbetas de parallellt i respektive körningsnivå.
- På respektive nivå bearbetas enheterna enligt sina löpnummer för just den nivån.
- När en nivå har bearbetats, bearbetas nästa nivå.
Omsekvensering
Du kanske vill omsekvensera dina enheterna i följande situationer:
- Om endast ett datajobb används för alla dina ändringar, kan du använda alternativen för omsekvensering för att optimera körningstiden för hela jobbet. I så fall kan du använda körningsenheten för att representera modulen, nivån för att representera modulens funktionsområde, samt sekvensen för att representera enheten. Med den här metoden kan du arbeta mellan olika moduler parallellt, men du kan ändå fortsätta arbeta i följd i en modul. För att garantera att parallella operationer lyckas, måste du beakta alla beroenden.
- Du kan använda ordningsföljd för att enheternas nivå och serie i syfte att få en optimal körning om flera datajobb används (t.ex. ett jobb för varje modul).
- Om det inte finns några beroenden alls kan du ordna enheterna i olika körningsenheter i syfte att få en maximal optimering.
Menyn Omsekvensering finns att tillgå när du väljer flera enheter. Du kan omsekvensera baserat på alternativen för körningsenhet, nivå samt serie. Du kan ange ett ökningssteg i syfte att omsekvensera de enheter som har valts. Den enhet, den nivå eller det löpnummer som väljs för respektive entitet uppdateras med angivna steg.
Sortering
Använd alternativet Sortera för att visa enhetslistan i ordningsföljd.
Trunkering
För import av projekt kan du trunkera poster i enheter innan du börjar importera. Truknering är användbart om posterna ska importeras till en ren uppsättning tabeller. Den här inställningen är vald som standard.
Bekräfta att källdata och måldata mappas korrekt
Mappning är en funktion som gäller både import- och exportjobb.
- Mappning beskriver vilka kolumner i källfilen som blir kolumner i det tillfälliga registret i samband med import. Därför kan systemet avgöra vilka kolumndata i källfilen som måste kopieras till vilken kolumn i det tillfälliga registret.
- Mappning beskriver vilka kolumner i det tillfälliga registret (dvs. källan) som kolumner i målfilen i samband med exportjobb.
Om kolumnnamnen i det tillfälliga registret och i filen stämmer överens, skapar systemet mappningen automatiskt baserat på namnen. Om namnen emellertid skiljer sig åt, mappas kolumnerna inte automatiskt. I så fall måste du slutföra mappningen genom att välja alternativet Visa mappning alternativ för enheten i datajobbet.
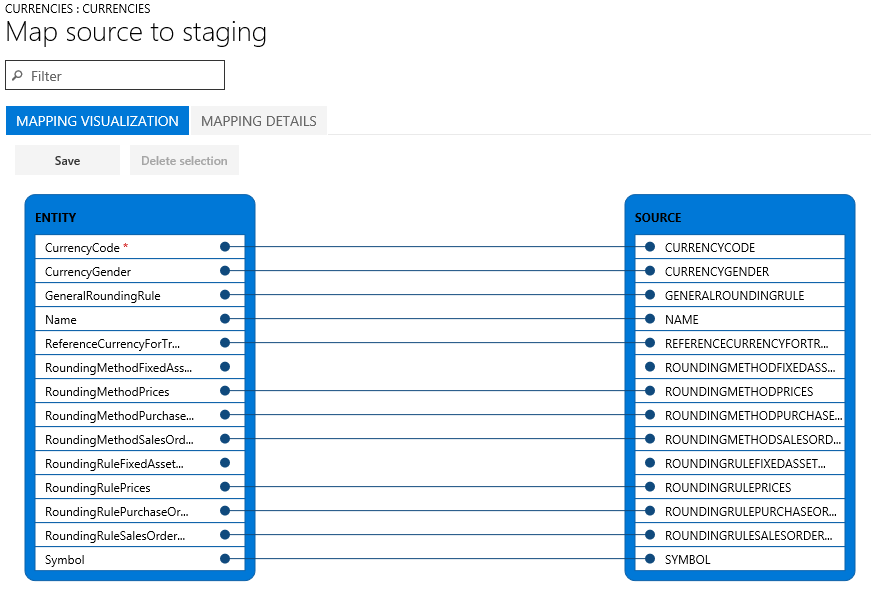
Det finns två vyer för mappning: Mappningsvisualisering, som är standard, och Mappningsdetaljer. En röd asterisk (*) markerar alla obligatoriska fält i enheten. Dessa fält måste mappas innan du kan arbeta med entiteten. Du kan ta bort mappningen av andra fält efter behov när du arbetar med enheten. Markera fältet som du vill ta bort mappningen för i kolumnen Enhet eller i kolumnen Källa, och välj sedan Ta bort val. Välj Spara om du vill spara ändringarna, och stäng sedan sidan om du vill återgå till projektet. Du kan använda samma process för att redigera fältmappning från källa till mellanlagring när du har importerat.
Du kan skapa en mappning på sidan genom att markera Skapa källmappning. En skapad mappning fungerar som en automatisk mappning. Därför måste du mappa de omappade fälten manuellt.
Kontrollera säkerheten för import- eller exportjobbet
Åtkomsten till arbetsytan Datahantering kan begränsas så att icke-administratörer endast kan få åtkomst till specifika datajobb. Åtkomsten till data-jobbet innebär fullständig åtkomst till jobbets körningshistorik samt till mellanlagringsregistren. Därför måste du se till att en lämplig åtkomstkontroll finns på plats när du skapar ett datajobb.
Säkra ett jobb genom roller och användare
Använd menyn Tillämpliga roller om du vill begränsa jobbet till en eller flera säkerhetsroller. Endast användare med dessa roller får tillgång till jobbet.
Du kan även begränsa ett jobb till specifika användare. När du säkrar ett jobb med användare i stället för roller, ökar kontrollen om flera användare tilldelas en roll.
Skydda ett jobb genom en juridisk person
Datajobb har en global karaktär. Om ett datajobb har skapats och använts i en juridisk person blir jobbet därför synlig för andra juridiska personer i systemet. Detta standardbeteende kan vara att föredras i vissa tillämpningsfall. En organisation som importerar fakturor genom datatabeller kan exempelvis innehålla ett centraliserat fakturabearbetningsteam som ansvarar för att hantera fakturafel för alla avdelningar inom organisationen. I det här scenariot är det bra om det centraliserade fakturabearbetningsteamet har åtkomst till fakturaimportjobb från alla juridiska personer. Därför uppfyller standardbeteendet kravet ur perspektivet för en juridisk person.
En organisation vill emellertid kanske ha fakturabearbetningsteam per juridisk person. I det här fallet bör ett team i en juridisk person bara ha åtkomst till fakturaimportjobbet i sin egen juridiska person. För att uppfylla detta krav kan du konfigurera åtkomstkontroll baserad på juridiska personer för datajobb via menyn Tillämpbara juridiska personer i datajobbet. När inställningarna har slutförts kan användarna bara se jobb som är tillgängliga i den juridiska personen som de för närvarande är inloggade på. Om de vill visa jobb från en annan juridisk person måste användarna växla till den juridiska personen.
Ett jobb kan skyddas med roller, användare och juridisk person samtidigt.
Kör import- eller exportjobbet.
Du kan köra ett jobb en gång genom att välja knappen Importera eller Exportera när du har definierat jobbet. Välj Skapa återkommande datajobb för att skapa ett återkommande jobb.
Notering
Ett import- eller exportjobb kan köras genom att välja knappen Importera eller Exportera. Då schemaläggs ett batchjobb så att det bara körs en gång. Jobbet kanske inte körs direkt om batchtjänsten begränsas på grund av beläggning på batchtjänsten. Jobb kan även köras synkront genom att markera importera nu eller exportera nu. Det här jobbet startar omedelbart och är användbart om batchen inte startas på grund av begränsning. Jobben kan också schemaläggas att köras vid senare tillfälle. Detta gör du genom att välja alternativet Kör i batch. Batchresurser är föremål för begränsning, så batchjobbet kanske inte startar omedelbart. Det rekommenderade alternativet är att använda batch eftersom det också kommer att hjälpa till att importera eller exportera stora datavolymer. Batchjobb kan planeras på en viss batchgrupp som ger mer kontroll ur ett belastningsutjämningsperspektiv.
Validera att jobbet har körts som förväntat
Jobbhistoriken blir tillgänglig för felsökning och undersökning för såväl import- som exportjobb. Historiska jobbkörningar ordnas efter tidsintervall.
Varje gång du kör jobbet erhåller du följande information:
- Information om körning
- Körningslogg
Körningsinformationen anger statusen för varje dataenhet som jobbet bearbetat. Därför kan du snabbt hitta följande information:
- Vilka enheter som har bearbetats.
- Hur många poster som bearbetats för en enhet, och hur många som misslyckades
- Mellanlagringsposter för respektive enhet
Du kan hämta mellanlagringsdatan i en fil för exportjobb, eller också du kan hämta den i form av ett paket för import- och exportjobb.
Du kan också öppna körningsloggen från körningsinformationen.
Parallella importer
För att påskynda importen av data kan parallell bearbetning av import av en fil aktiveras om enheten stöder parallell import. Om du vill konfigurera parallell import för en entitet måste följande steg följas.
Gå till Systemadministration > Arbetsytor > Datahantering.
I avsnittet importera/exportera väljer du panelen Ramverksparametrar för att öppna sidan Ramverket för dataimport/-export.
På fliken Entitetsinställningar, välj Konfigurera parametrar för entitetskörning för att öppna sidan Parametrar för körning av entitetsimport.
Ställ in följande fält för att konfigurera parallell import för en entitet:
- Välj den entitet i fältet Entitet. Om enhetsfältet är tomt används det tomma värdet som standardinställning för alla efterföljande importer, om enheten har stöd för parallell import.
- I fältet Importera antal för tröskelvärdepost anger du antal för tröskelvärdepost för import. Detta bestämmer antalet poster som ska bearbetas av en tråd. Om en fil har 10 000 poster innebär detta att antalet poster på 2 500 med antalet uppgifter är 4 och varje tråd bearbetar 2 500 poster.
- I fältet Import uppgiftsantal anger du antalet importerade uppgifter. Antalet får inte överskrida de maximalt antal trådar som allokerats för batchbearbetning i Systemadministration >Serverkonfiguration.
Rensa jobbhistorik
Jobbhistorikposter och relaterade mellanlagringsregisterdata som är äldre än 90 dagar tas som standard bort automatiskt. Rensningsfunktionerna i jobbhistoriken i datahantering kan användas för att konfigurera periodisk rensning av körningshistoriken med en lägre lagringsperiod än standardvärdet. Den här funktionen ersätter den tidigare mellanlagringsfunktionen, som nu är inaktuell. Följande tabeller kommer att rensas upp av rensningsprocessen.
Alla mellanlagringsregister
DMFSTAGINGVALIDATIONLOG
DMFSTAGINGEXECUTIONERRORS
DMFSTAGINGLOGDETAIL
DMFSTAGINGLOG
DMFDEFINITIONGROUPEXECUTIONHISTORY
DMFEXECUTION
DMFDEFINITIONGROUPEXECUTION
Rensningsfunktionen för körningshistorik kan öppnas från Datahantering > Rensning av jobbhistorik.
Planeringsparametrar
När du schemalägger rensningsprocessen måste följande parametrar anges för att definiera rensningskriterierna.
Antal dagar att behålla historiken – den här inställningen används för att kontrollera mängden körningshistorik som ska bevaras. Historik anges i antal dagar. När rensningsjobbet schemaläggs som ett återkommande batchjobb, kommer den här inställningen att fungera som ett kontinuerligt rörligt fönster och därmed alltid lämna historiken för angivet antal dagar intakt medan resten tas bort. Standardvärdet är sju dagar.
Antal timmar för att utföra jobbet – beroende på hur mycket historik som ska rensas kan den totala körningstiden för rensningsjobbet kan variera från några minuter till några timmar. Den här parametern måste anges till det antal timmar som jobbet ska köras. När rensningsjobbet har körts i det angivna antalet timmar avslutas jobbet och återupptar rensningen nästa gång det körs baserat på det återkommande schemat.
En maximal körningstid kan anges genom att ange en max.gräns för antalet timmar som jobbet måste köras med den här inställningen. Rensningslogiken går igenom ett jobbkörnings-ID i taget i en kronologiskt ordnad sekvens, med äldsta först för rensning av relaterade körningshistoriken. Det slutar att plocka upp nya körnings-ID för rensning när återstående körningstid är inom de senaste 10 % av den angivna varaktigheten. I vissa fall kommer det att förväntas att rensningsjobbet kommer att fortsätta efter den angivna maxtiden. Detta beror till stor del på hur många poster som ska tas bort för det aktuella körnings-ID som startades innan tröskelvärdet på 10 % uppnåddes. Rensningen som startades måste slutföras för att säkerställa dataintegriteten, vilket innebär att rensningen fortsätter trots att den angivna gränsen överskrids. När detta är klart hämtas inte nya körnings-ID och rensningsjobbet har slutförts. Den återstående körningshistoriken som inte har rensats på grund av bristande körningstid kommer att plockas upp nästa gång som rensningsjobbet schemaläggs. Standard- och minimivärdet för den här inställningen är inställt på 2 timmar.
Återkommande batch – rensningsjobbet kan köras som en engångs, manuell körning eller det kan också schemaläggas för återkommande körning i batch. Batchen kan schemaläggas med hjälp inställningarna Kör i bakgrund, vilket är standarduppsättningen för batch.
Obs
Om rensningsfunktionen för jobbhistorik inte används kommer körningshistorik som är äldre än 90 dagar fortfarande att tas bort automatiskt. Rensningen av jobbhistorik kan utöver denna automatiska borttagning köras. Kontrollera att rensningsjobbet är tidsplanerat att köras på nytt. Som förklaras ovan kommer jobbet att bara rensa så många körnings-ID som möjligt inom de maximalt angivna timmarna i alla rensningskörningar.
Rensning och arkivering för jobbhistorik
Funktionen för rensning och arkivering av jobbhistorik ersätter de tidigare versionerna av rensningsfunktionen. Det här avsnittet innehåller en beskrivning av de nya funktionerna.
En av de viktigaste ändringarna i rensningsfunktionen är användningen av systembatchjobbet för att rensa historiken. Med systembatchjobbet kan appar för ekonomi och drift schemaläggas att köra rensningsbatchjobbet automatiskt så fort systemet är redo. Du behöver inte längre tidsplanera batchjobbet manuellt. I detta standardkörningsläge körs batchjobbet varje timme med början vid midnatt, och bibehåller sedan körningshistoriken för de senaste sju dagarna. Den rensade historiken arkiveras för framtida hämtning. Från och med version 10.0.20 är den här funktionen alltid på.
Den andra ändringen i rensningsprocessen är arkiveringen av den rensade körningshistoriken. Rensningsjobbet kommer att arkivera de raderade posterna till den blob-lagring som DIXF använder för vanliga integreringar. Den arkiverade filen kommer att vara i DIXF-paketformat och den kommer att vara tillgänglig i blobben för hämtning i sju dagar. Standardlivslängden på sju dagar för den arkiverade filen kan ändras i parametrarna till maximalt 90 dagar.
Ändra standardinställningarna
Den här funktionen är för närvarande i förhandsversion och måste uttryckligen aktiveras på ett sätt som aktiverar DMFEnableExecutionHistoryCleanupSystemJob. Funktionen för rensning av mellanlagring måste också aktiveras i funktionshanteringen.
Om du vill ändra standardinställningen för livslängd för den arkiverade filen ska du gå till arbetsytan för datahantering och välja Rensning av jobbhistorik. Ange Dagar att behålla paketet i blobben som ett värde mellan 7 och 90 (inklusive). Detta kommer att börja gälla för de arkiv som skapas efter att ändringen gjorts.
Hämta det arkiverade paketet
Den här funktionen är för närvarande i förhandsversion och måste uttryckligen aktiveras på ett sätt som aktiverar DMFEnableExecutionHistoryCleanupSystemJob. Funktionen för rensning av mellanlagring måste också aktiveras i funktionshanteringen.
För att hämta den arkiverade körningshistoriken ska du gå till arbetsytan för datahanterings och välja Rensning av jobbhistorik. Välj Historik för säkerhetskopiering av paket för att öppna formuläret historik. I det här formuläret visas en lista med alla arkiverade paket. Du kan välja och hämta ett arkiv genom att välja Hämta paket. Det hämtade paketet kommer att vara i DIXF-paketformat och innehålla följande filer:
- Registerfilen för entitetens mellanlagring
- DMFDEFINITIONGROUPEXECUTION
- DMFDEFINITIONGROUPEXECUTIONHISTORY
- DMFEXECUTION
- DMFSTAGINGEXECUTIONERRORS
- DMFSTAGINGLOG
- DMFSTAGINGLOGDETAILS
- DMFSTAGINGVALIDATIONLOG
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för