Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Anmärkning
Den här artikeln förutsätter att du vet hur du använder Code First Migrations i grundläggande scenarier. Om du inte gör det måste du läsa Code First Migrations innan du fortsätter.
Ta en kaffe, måste du läsa hela den här artikeln
Problemen i teammiljöer handlar främst om att slå samman migreringar när två utvecklare har genererat migreringar i sin lokala kodbas. Även om stegen för att lösa dessa är ganska enkla, kräver de att du har en gedigen förståelse för hur migreringar fungerar. Gå inte bara vidare till slutet – ta dig tid att läsa hela artikeln för att säkerställa att du lyckas.
Vissa allmänna riktlinjer
Innan vi går in på hur du hanterar sammanslagningsmigreringar som genererats av flera utvecklare finns här några allmänna riktlinjer för att konfigurera dig för framgång.
Varje gruppmedlem bör ha en lokal utvecklingsdatabas
Migreringar använder tabellen __MigrationsHistory för att lagra vilka migreringar som har tillämpats på databasen. Om du har flera utvecklare som genererar olika migreringar när du försöker rikta in dig på samma databas (och därmed dela en __MigrationsHistory tabell) blir migreringarna mycket förvirrade.
Om du har teammedlemmar som inte genererar migreringar är det naturligtvis inga problem med att de delar en central utvecklingsdatabas.
Undvik automatiska migreringar
Slutsatsen är att automatiska migreringar från början ser bra ut i teammiljöer, men i verkligheten fungerar de bara inte. Om du vill veta varför, fortsätt läsa – om inte, kan du gå vidare till nästa avsnitt.
Med automatiska migreringar kan du uppdatera databasschemat så att det matchar den aktuella modellen utan att behöva generera kodfiler (kodbaserade migreringar). Automatiska migreringar skulle fungera mycket bra i en teammiljö om du bara använde dem och aldrig genererade några kodbaserade migreringar. Problemet är att automatiska migreringar är begränsade och inte hanterar ett antal åtgärder – egenskaps-/kolumnbyten, flytt av data till en annan tabell osv. För att hantera dessa scenarier genererar du kodbaserade migreringar (och redigerar den kod som blandas in mellan ändringar som hanteras av automatiska migreringar. Detta gör det nästan omöjligt att sammanfoga ändringar när två utvecklare checkar in migreringar.
Förstå hur migreringar fungerar
Nyckeln till att använda migreringar i en teammiljö är en grundläggande förståelse för hur migreringar spårar och använder information om modellen för att identifiera modelländringar.
Den första migreringen
När du lägger till den första migreringen i projektet kör du något som Add-Migration First i Package Manager Console. De steg på hög nivå som det här kommandot utför visas nedan.
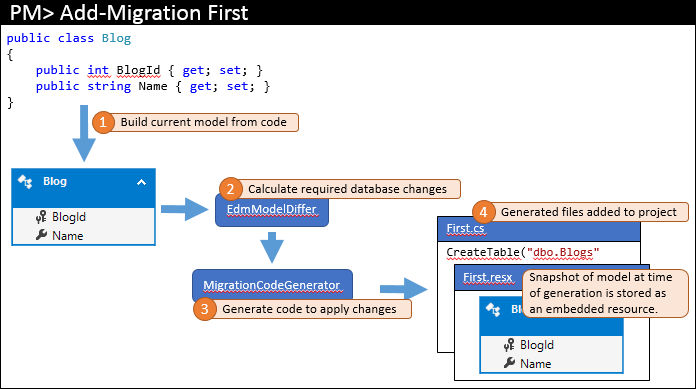
Den aktuella modellen beräknas från din kod (1). De databasobjekt som krävs beräknas sedan av modelljämförelsemotorn (2) – eftersom detta är den initiala migreringen använder modelljämförelsemotorn bara en tom modell för jämförelsen. Nödvändiga ändringar skickas till kodgeneratorn för att skapa den migreringskod (3) som sedan läggs till i Visual Studio-lösningen (4).
Förutom den faktiska migreringskoden som lagras i huvudkodfilen genererar migreringar även ytterligare kod bakom filer. Dessa filer är metadata som används av migreringar och som inte är något du bör redigera. En av dessa filer är en resursfil (.resx) som innehåller en ögonblicksbild av modellen när migreringen genererades. Du ser hur detta används i nästa steg.
I det här läget skulle du förmodligen köra Update-Database för att tillämpa ändringarna på databasen och sedan implementera andra områden i programmet.
Efterföljande migreringar
Senare kommer du tillbaka och gör några ändringar i din modell – i vårt exempel lägger vi till en URL-egenskap i bloggen. Du skulle sedan utfärda ett kommando som Add-Migration AddUrl för att skapa en migrering för att tillämpa motsvarande databasändringar. De steg på hög nivå som det här kommandot utför visas nedan.
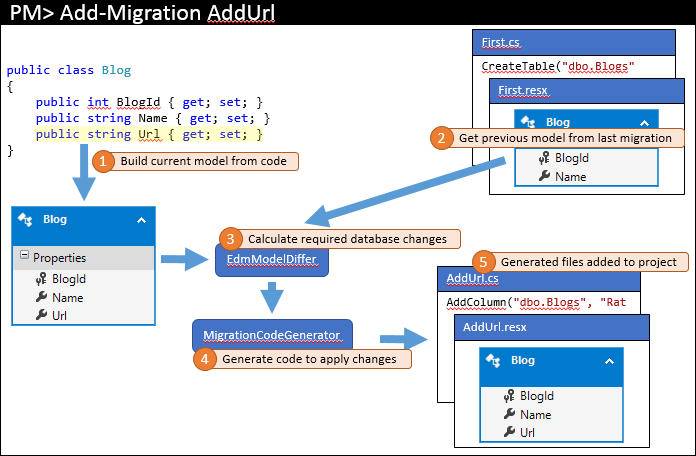
Precis som förra gången beräknas den aktuella modellen från kod (1). Men den här gången finns det befintliga migreringar så att den tidigare modellen hämtas från den senaste migreringen (2). Dessa två modeller jämförs för att hitta de nödvändiga databasändringarna (3) och sedan slutförs processen som tidigare beskrivits.
Samma process används för eventuella ytterligare migreringar som du lägger till i projektet.
Varför bry sig om modellögonblicksbilden?
Du kanske undrar varför EF bryr sig om modellögonblicksbilden – varför inte bara titta på databasen. I så fall läser du vidare. Om du inte är intresserad kan du hoppa över det här avsnittet.
Det finns ett antal orsaker till att EF behåller modellögonblicksbilden.
- Det gör att databasen kan glida från EF-modellen. Dessa ändringar kan göras direkt i databasen, eller så kan du ändra den scaffoldade koden i dina migreringar för att göra ändringarna. Här är några exempel på detta i praktiken:
- Du vill lägga till en infogad och uppdaterad kolumn i en eller flera av tabellerna, men du vill inte inkludera dessa kolumner i EF-modellen. Om migreringar tittade på databasen skulle den kontinuerligt försöka släppa dessa kolumner varje gång du skapar en migrering. Med hjälp av modellögonblicksbilden identifierar EF bara legitima ändringar i modellen.
- Du vill ändra brödtexten för en lagrad procedur som används för uppdateringar så att den innehåller viss loggning. Om migreringar tittade på den här lagrade proceduren från databasen skulle den kontinuerligt försöka återställa den till den definition som EF förväntar sig. Genom att använda en modellmomentbild kommer EF endast någonsin att generera kod för att ändra den lagrade proceduren när du ändrar strukturen på proceduren i EF-modellen.
- Samma principer gäller för att lägga till extra index, inklusive extra tabeller i databasen, mappa EF till en databasvy som finns över en tabell osv.
- EF-modellen innehåller mer än bara databasens form. Med hela modellen kan migreringar titta på information om egenskaper och klasser i din modell och hur de mappas till kolumnerna och tabellerna. Med den här informationen kan migreringar utföras mer intelligent i koden som den strukturerar. Om du till exempel ändrar namnet på kolumnen som en egenskap mappar till migreringar kan identifiera namnbytet genom att se att det är samma egenskap – något som inte kan göras om du bara har databasschemat.
Vad orsakar problem i teammiljöer
Arbetsflödet som beskrivs i föregående avsnitt fungerar bra när du är en enskild utvecklare som arbetar med ett program. Det fungerar också bra i en teammiljö om du är den enda personen som gör ändringar i modellen. I det här scenariot kan du göra modelländringar, generera migreringar och skicka dem till källkontrollen. Andra utvecklare kan synkronisera dina ändringar och köra Update-Database för att få schemaändringarna tillämpade.
Problem börjar uppstå när du har flera utvecklare som gör ändringar i EF-modellen och skickar till källkontrollen samtidigt. Vad EF saknar är ett förstklassigt sätt att slå samman dina lokala migreringar med migreringar som en annan utvecklare har skickat till källkontrollen sedan du senast synkroniserade.
Ett exempel på en sammanslagningskonflikt
Först ska vi titta på ett konkret exempel på en sådan sammanslagningskonflikt. Vi fortsätter med exemplet som vi tittade på tidigare. Som utgångspunkt antar vi att ändringarna från föregående avsnitt checkades in av den ursprungliga utvecklaren. Vi spårar två utvecklare när de gör ändringar i kodbasen.
Vi spårar EF-modellen och migreringarna genom ett antal ändringar. Som utgångspunkt har båda utvecklarna synkroniserat till källkontrolllagringsplatsen, enligt följande bild.
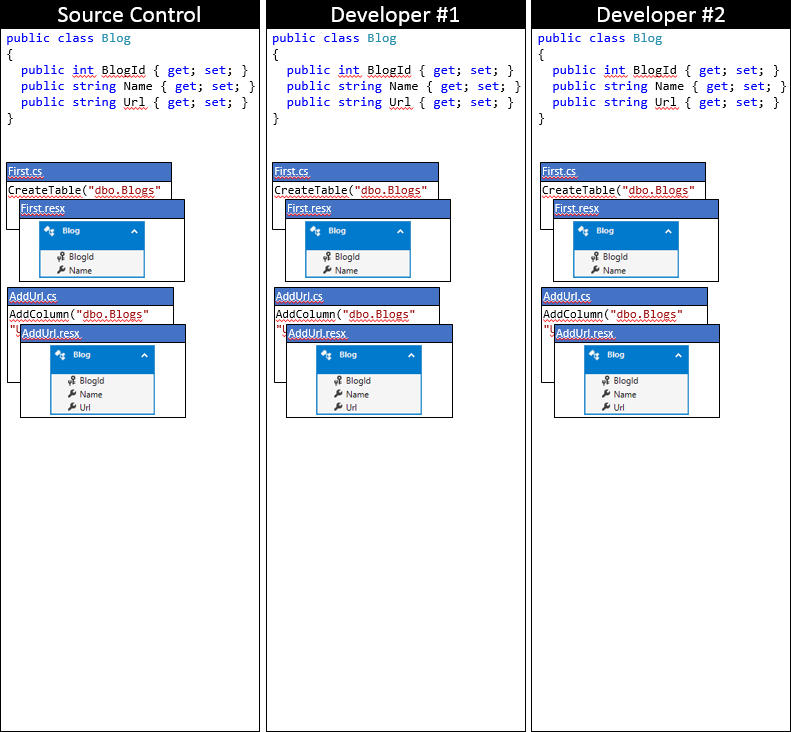
Utvecklare nr 1 och utvecklare nr 2 gör nu vissa ändringar i EF-modellen i sin lokala kodbas. Utvecklare #1 lägger till en Rating-egenskap i Blogg – och genererar en AddRating-migrering för att tillämpa ändringarna på databasen. Developer #2 lägger till en Readers-egenskap i Blogg – och genererar motsvarande AddReaders-migrering. Båda utvecklarna kör Update-Database för att tillämpa ändringarna på sina lokala databaser och sedan fortsätta utveckla programmet.
Anmärkning
Migreringar är prefixade med en tidsstämpel, så vårt schema visar att AddReaders-migreringen från Utvecklare #2 kommer efter AddRating-migreringen från Utvecklare #1. Om utvecklaren nr 1 eller 2 genererade migreringen först spelar ingen roll för problemen med att arbeta i ett team eller processen för att slå samman dem som vi ska titta på i nästa avsnitt.
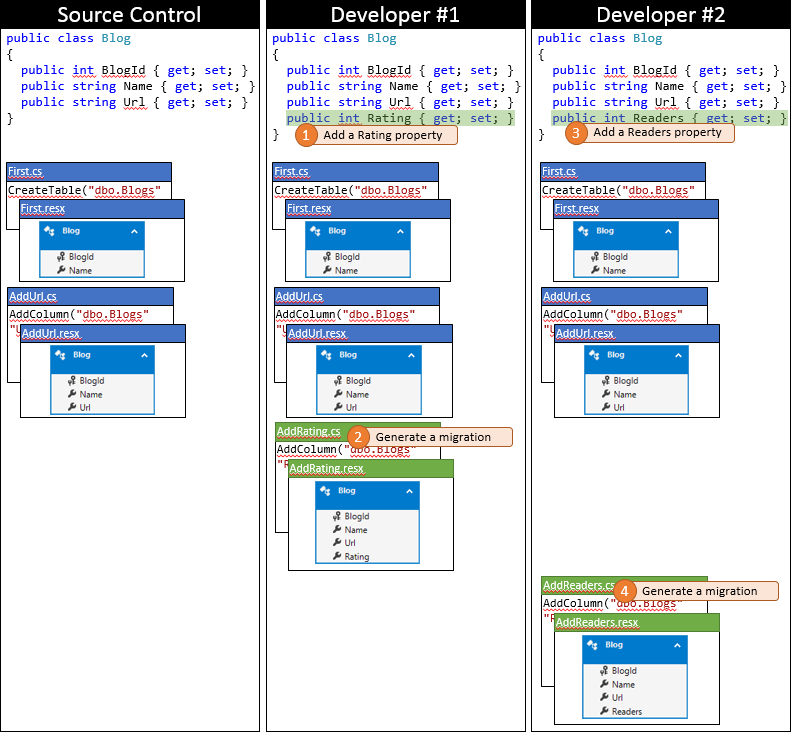
Det är en lycklig dag för utvecklare nr 1 när de skickar in sina ändringar först. Eftersom ingen annan har checkat in sedan de synkroniserade sin lagringsplats kan de bara skicka sina ändringar utan att utföra någon sammanslagning.
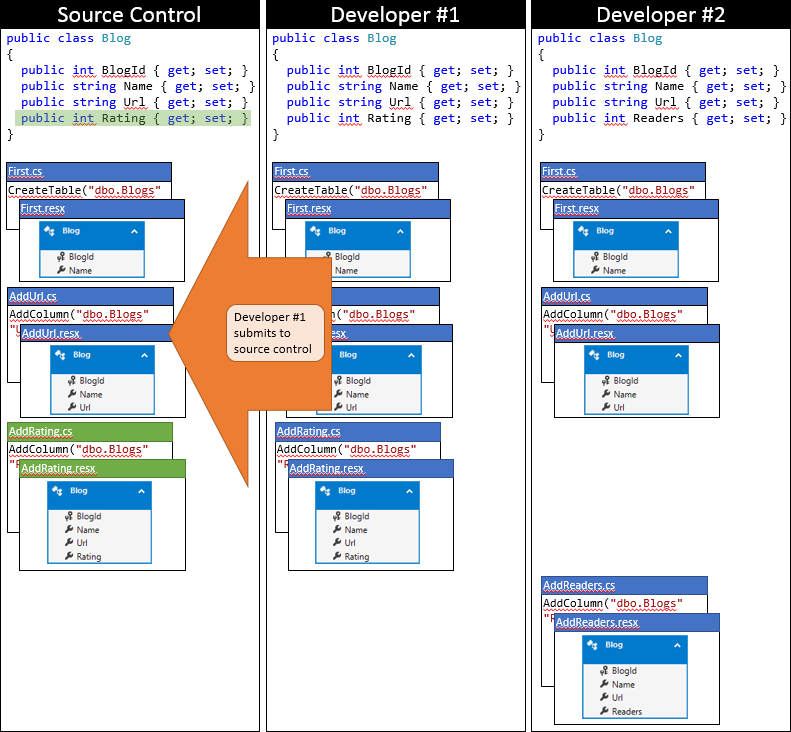
Nu är det dags för utvecklare nr 2 att skicka in. De har inte samma tur. Eftersom någon annan har skickat ändringar sedan de synkroniserades måste de hämta ändringarna och sammanfoga dem. Källkontrollsystemet kommer sannolikt att kunna sammanfoga ändringarna automatiskt på kodnivå eftersom de är mycket enkla. Tillståndet för Developer #2:s lokala lagringsplats efter synkroniseringen visas i följande bild.
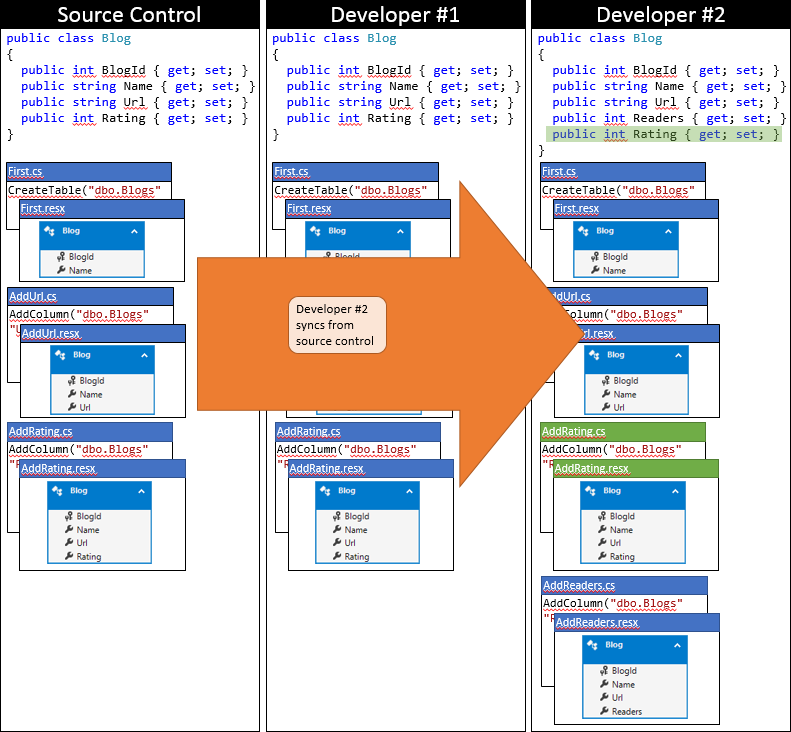
I det här skedet kan utvecklare nr 2 köra Update-Database som identifierar den nya migreringen addRating (som inte har tillämpats på developer #2-databasen) och tillämpa den. Nu läggs kolumnen Klassificering till i tabellen Bloggar och databasen är synkroniserad med modellen.
Det finns dock ett par problem:
- Även om Update-Database tillämpar migreringen AddRating visas även en varning: Det går inte att uppdatera databasen så att den matchar den aktuella modellen eftersom det finns väntande ändringar och automatisk migrering är inaktiverad... Problemet är att den modellögonblicksbild som lagrades vid den senaste migreringen (AddReader) saknar egenskapen Rating på bloggen (eftersom den inte ingick i modellen när migreringen genererades). Code First identifierar att modellen i den senaste migreringen inte matchar den aktuella modellen och genererar varningen.
- Att köra programmet skulle resultera i en InvalidOperationException som anger att "Modellen som stöder kontexten BloggingContext har ändrats sedan databasen skapades. Överväg att använda Code First Migrations för att uppdatera databasen..." Återigen är problemet att modellögonblicksbilden som lagrades i den senaste migreringen inte matchar den aktuella modellen.
- Slutligen förväntar vi oss att körningen av Add-Migration nu skulle generera en tom migrering (eftersom det inte finns några ändringar att tillämpa på databasen). Men eftersom migreringar jämför den aktuella modellen med den från den senaste migreringen (som saknar egenskapen Rating ) kommer den faktiskt att skapa ett annat AddColumn-anrop för att lägga till kolumnen Rating. Den här migreringen skulle naturligtvis misslyckas under Update-Database eftersom kolumnen Rating redan finns.
Lösa sammanslagningskonflikten
Den goda nyheten är att det inte är för svårt att hantera sammanslagningen manuellt – förutsatt att du har en förståelse för hur migreringar fungerar. Så om du har hoppat framåt till det här avsnittet... ledsen, du måste gå tillbaka och läsa resten av artikeln först!
Det finns två alternativ, det enklaste är att generera en tom migrering som har rätt aktuell modell som en ögonblicksbild. Det andra alternativet är att uppdatera ögonblicksbilden från den senaste migreringen för att säkerställa att modellens ögonblicksbild är korrekt. Det andra alternativet är lite svårare och kan inte användas i varje scenario, men det är också renare eftersom det inte innebär att lägga till en extra migrering.
Alternativ 1: Lägg till en tom sammanslagningsmigrering
I det här alternativet genererar vi en tom migrering enbart för att se till att den senaste migreringen har rätt modellögonblicksbild lagrad i den.
Det här alternativet kan användas oavsett vem som genererade den senaste migreringen. I exemplet som vi har följt tar utvecklare nr 2 hand om sammanslagningen och av en slump genererade de den senaste migreringen. Men samma steg kan användas om Developer #1 genererade den senaste migreringen. Stegen gäller även om det finns flera migreringar inblandade – vi har bara tittat på två för att hålla det enkelt.
Följande process kan användas för den här metoden, från och med den tidpunkt då du inser att du har ändringar som måste synkroniseras från källkontrollen.
- Se till att eventuella väntande modelländringar i din lokala kodbas har skrivits till en migrering. Det här steget säkerställer att du inte missar några legitima ändringar när det är dags att generera den tomma migreringen.
- Synkronisera med källkontroll.
- Kör Update-Database för att tillämpa alla nya migreringar som andra utvecklare har checkat in. Obs!Om du inte får några varningar från kommandot Update-Database så fanns det inga nya migreringar från andra utvecklare och det finns ingen anledning att utföra någon ytterligare sammanslagning.
- Kör Add-Migration <pick_a_name> – IgnoreChanges (till exempel Add-Migration Merge – IgnoreChanges). Detta genererar en migrering med alla metadata (inklusive en ögonblicksbild av den aktuella modellen) men ignorerar alla ändringar som identifieras när den aktuella modellen jämförs med ögonblicksbilden under de senaste migreringarna (vilket innebär att du får en tom upp - och ned-metod ).
- Kör Update-Database för att tillämpa den senaste migreringen igen med uppdaterade metadata.
- Fortsätt att utveckla eller skicka till källkontrollen (när du har kört enhetstesterna förstås).
Här är tillståndet för Developer #2:s lokala kodbas när du har använt den här metoden.
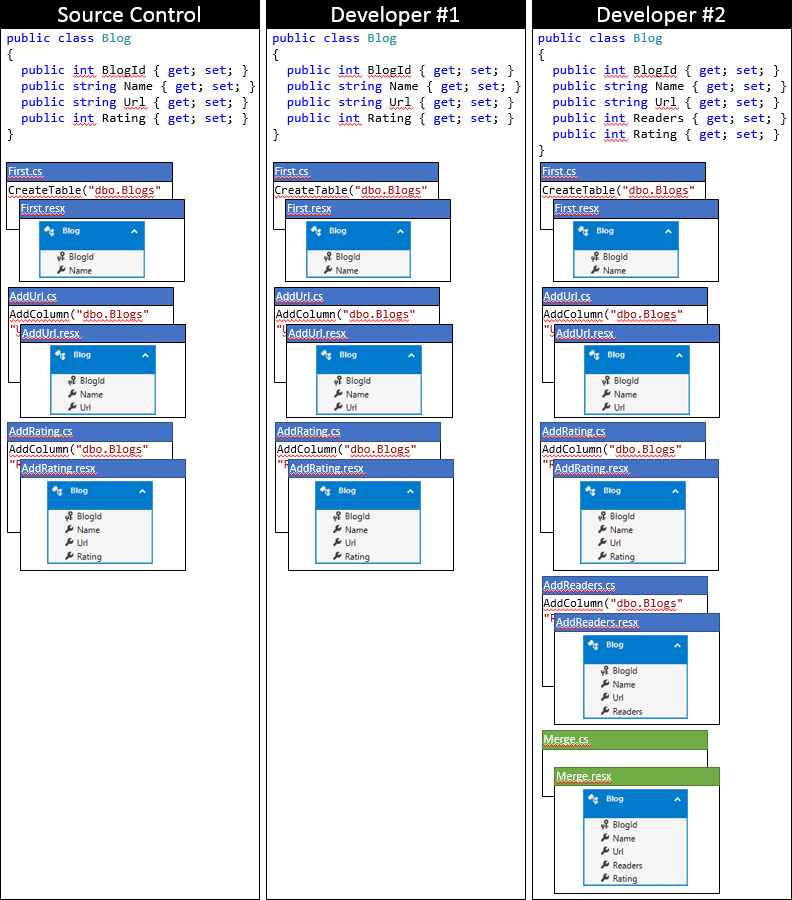
Alternativ 2: Uppdatera modellögonblicksbilden under den senaste migreringen
Det här alternativet är mycket likt alternativ 1 men tar bort den extra tomma migreringen – för låt oss vara ärliga, vem vill ha extra kodfiler i sin lösning.
Den här metoden är endast möjlig om den senaste migreringen bara finns i din lokala kodbas och ännu inte har skickats till källkontrollen (till exempel om den senaste migreringen genererades av användaren som gjorde sammanfogningen). Att redigera metadata för migreringar som andra utvecklare kanske redan har tillämpat på sin utvecklingsdatabas – eller ännu värre som tillämpas på en produktionsdatabas – kan leda till oväntade biverkningar. Under processen ska vi återställa den senaste migreringen i vår lokala databas och tillämpa den igen med uppdaterade metadata.
Den senaste migreringen behöver bara finnas i den lokala kodbasen, men det finns inga begränsningar för antalet eller ordningen på migreringar som fortsätter. Det kan finnas flera migreringar från flera olika utvecklare och samma steg gäller– vi har bara tittat på två för att hålla det enkelt.
Följande process kan användas för den här metoden, från och med den tidpunkt då du inser att du har ändringar som måste synkroniseras från källkontrollen.
- Se till att eventuella väntande modelländringar i din lokala kodbas har skrivits till en migrering. Det här steget säkerställer att du inte missar några legitima ändringar när det är dags att generera den tomma migreringen.
- Synkronisera med källkontrollen.
- Kör Update-Database för att tillämpa alla nya migreringar som andra utvecklare har checkat in. Obs!Om du inte får några varningar från kommandot Update-Database så fanns det inga nya migreringar från andra utvecklare och det finns ingen anledning att utföra någon ytterligare sammanslagning.
- Kör Update-Database – TargetMigration <second_last_migration> (i exemplet som vi har följt skulle detta vara Update-Database – TargetMigration AddRating). Detta rullar tillbaka databasen till tillståndet för den näst sista migreringen – i praktiken återkallas den senaste migreringen från databasen. Obs!Det här steget krävs för att göra det säkert att redigera metadata för migreringen eftersom metadata också lagras i databasens __MigrationsHistoryTable. Därför bör du bara använda det här alternativet om den senaste migreringen endast finns i din lokala kodbas. Om andra databaser hade tillämpat den senaste migreringen skulle du också behöva återställa dem och tillämpa den senaste migreringen igen för att uppdatera metadata.
- Kör Add-Migration <full_name_including_timestamp_of_last_migration> (i exemplet som vi har följt skulle det vara ungefär som Add-Migration 201311062215252_AddReaders). Obs!Du måste inkludera tidsstämpeln så att migreringar vet att du vill redigera den befintliga migreringen i stället för att skapa en ny. Då uppdateras metadata för den senaste migreringen så att de matchar den aktuella modellen. Du får följande varning när kommandot har slutförts, men det är precis vad du vill ha. "Endast designerkoden för migrering "201311062215252_AddReaders" omkodades. Om du vill omgenerera hela migreringen använder du parametern -Force."
- Kör Update-Database för att tillämpa den senaste migreringen igen med uppdaterade metadata.
- Fortsätt att utveckla eller skicka till källkontrollen (när du har kört enhetstesterna förstås).
Här är tillståndet för Developer #2:s lokala kodbas när du har använt den här metoden.
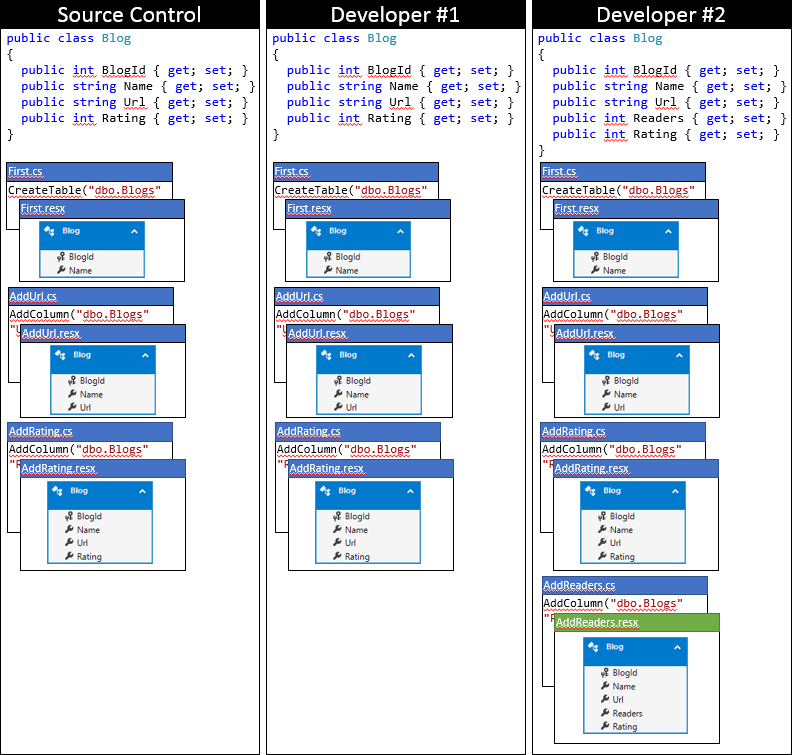
Sammanfattning
Det finns vissa utmaningar när du använder Code First Migrations i en teammiljö. Men en grundläggande förståelse för hur migreringar fungerar och några enkla metoder för att lösa sammanslagningskonflikter gör det enkelt att övervinna dessa utmaningar.
Det grundläggande problemet är felaktiga metadata som lagras i den senaste migreringen. Detta gör att Code First felaktigt identifierar att den aktuella modellen och databasschemat inte matchar, vilket leder till att felaktig kod genereras i nästa migrering. Den här situationen kan lösas genom att generera en tom migrering med rätt modell eller genom att uppdatera metadata i den senaste migreringen.
Samarbeta med oss på GitHub
Källan för det här innehållet finns på GitHub, där du även kan skapa och granska ärenden och pull-begäranden. Se vår deltagarguide för mer information.