Konfigurera och hantera datateknik och datavetenskapsinställningar för Infrastrukturkapaciteter
Gäller för:![]() Datateknik och Datavetenskap i Microsoft Fabric
Datateknik och Datavetenskap i Microsoft Fabric
När du skapar Microsoft Fabric från Azure-portalen läggs det automatiskt till i infrastrukturresursklientorganisationen som är associerad med den prenumeration som används för att skapa kapaciteten. Med den förenklade installationen i Microsoft Fabric behöver du inte länka kapaciteten till Fabric-klientorganisationen. Eftersom den nyligen skapade kapaciteten visas i fönstret administratörsinställningar. Den här konfigurationen ger en snabbare upplevelse för administratörer att börja konfigurera kapaciteten för sina företagsanalysteam.
Om du vill göra ändringar i inställningarna för Datateknik/vetenskap i en kapacitet måste du ha administratörsrollen för den kapaciteten. Mer information om de roller som du kan tilldela användare i en kapacitet finns i Roller i kapaciteter.
Använd följande steg för att hantera inställningarna för Datateknik/vetenskap för Microsoft Fabric-kapacitet:
Välj alternativet Inställningar för att öppna inställningsfönstret för ditt Infrastruktur-konto. Välj administratörsportal under avsnittet Styrning och insikter
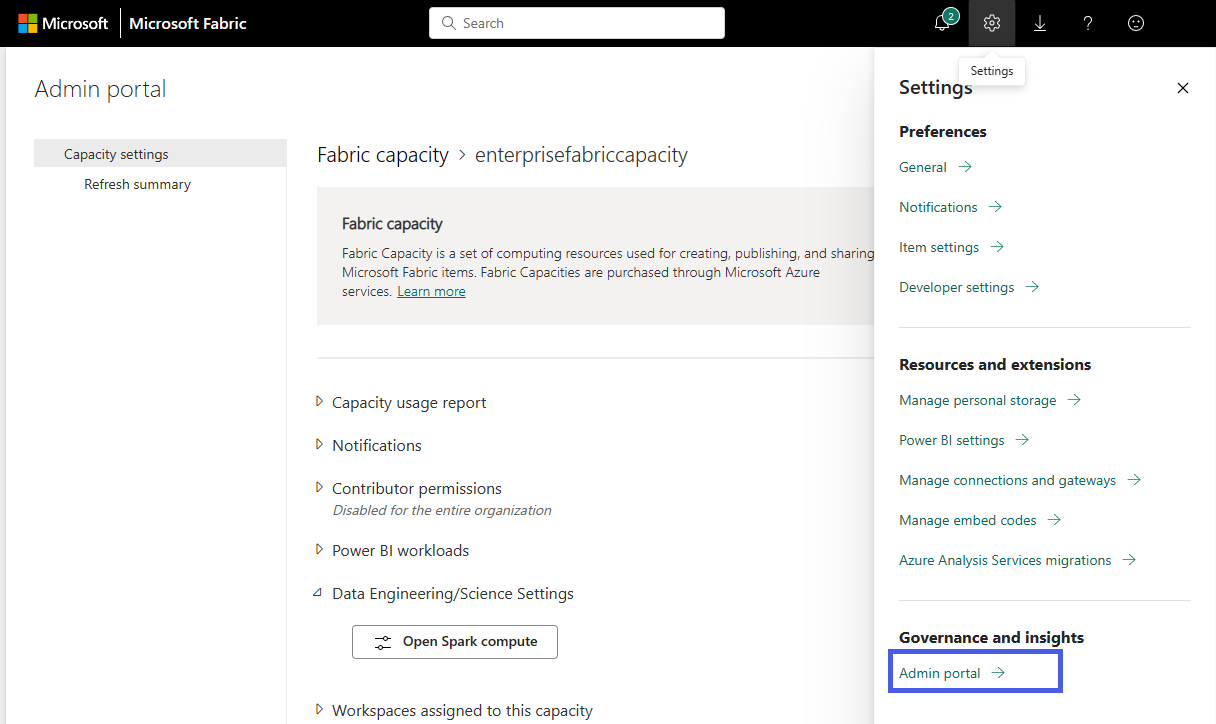
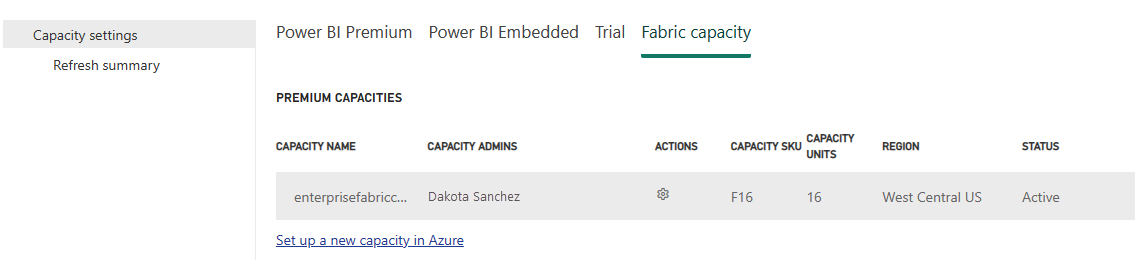
Välj alternativet Kapacitetsinställningar för att expandera menyn och välj fliken Infrastrukturkapacitet. Här bör du se de kapaciteter som du har skapat i din klientorganisation. Välj den kapacitet som du vill konfigurera.
Du navigerar till kapacitetsdetaljfönstret, där du kan visa användningen och andra administratörskontroller för din kapacitet. Gå till avsnittet Datateknik/Science Inställningar och välj Öppna Spark Compute. Konfigurera följande parametrar:
- Anpassade arbetsytepooler: Du kan begränsa eller demokratisera anpassningen av beräkning till arbetsyteadministratörer genom att aktivera eller inaktivera det här alternativet. Om du aktiverar det här alternativet kan arbetsyteadministratörer skapa, uppdatera eller ta bort anpassade spark-pooler på arbetsytenivå. Dessutom kan du ändra storlek på dem baserat på beräkningskraven inom den maximala kärngränsen för en kapacitet.
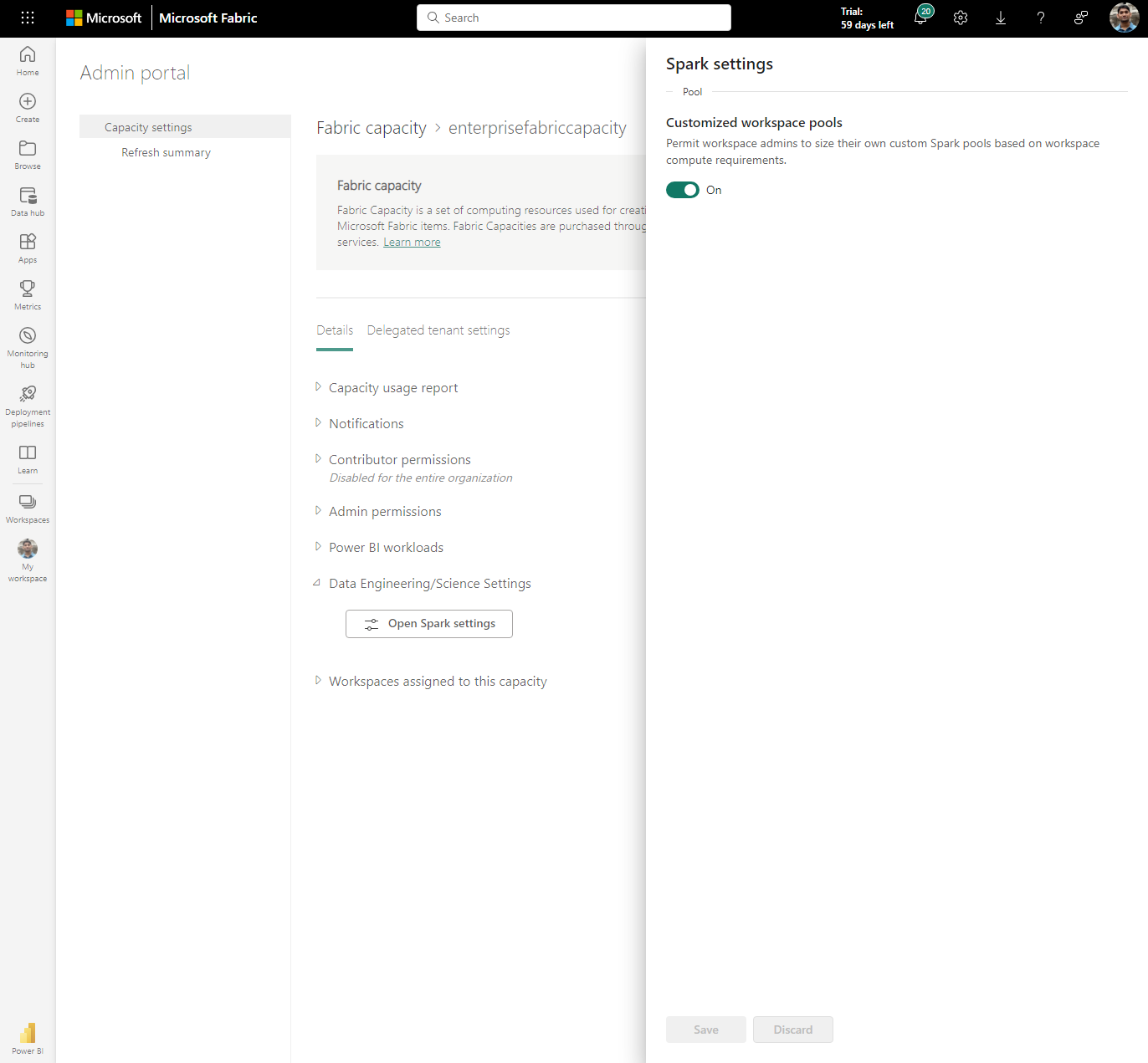
När du har konfigurerat väljer du Använd

Relaterat innehåll
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för