Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Den här snabbstarten förklarar hur du skapar en Spark-jobbdefinition som innehåller Python-kod med Spark Structured Streaming för att landa data i ett lakehouse och sedan hantera dem via en SQL-analysslutpunkt. När du har slutfört den här snabbstarten har du en Spark-jobbdefinition som körs kontinuerligt och SQL-analysslutpunkten kan visa inkommande data.
Skapa ett Python-skript
Använd följande Python-skript för att skapa en strömmande Delta-tabell i ett datahus (lakehouse) med Apache Spark. Skriptet läser en dataström med genererade data (en rad per sekund) och skriver den i tilläggsläge till en Delta-tabell med namnet streamingtable. Den lagrar information om data och kontrollpunkter i det angivna sjöhuset.
Använd följande Python-kod som använder Spark-strukturerad strömning för att hämta data i en lakehouse-tabell.
from pyspark.sql import SparkSession if __name__ == "__main__": # Start Spark session spark = SparkSession.builder \ .appName("RateStreamToDelta") \ .getOrCreate() # Table name used for logging tableName = "streamingtable" # Define Delta Lake storage path deltaTablePath = f"Tables/{tableName}" # Create a streaming DataFrame using the rate source df = spark.readStream \ .format("rate") \ .option("rowsPerSecond", 1) \ .load() # Write the streaming data to Delta query = df.writeStream \ .format("delta") \ .outputMode("append") \ .option("path", deltaTablePath) \ .option("checkpointLocation", f"{deltaTablePath}/_checkpoint") \ .start() # Keep the stream running query.awaitTermination()Spara skriptet som Python-fil (.py) på den lokala datorn.
Skapa ett sjöhus
Använd följande steg för att skapa ett sjöhus:
Logga in på Microsoft Fabric-portalen.
Navigera till önskad arbetsyta eller skapa en ny om det behövs.
Om du vill skapa ett sjöhus väljer du Nytt objekt från arbetsytan och väljer sedan Lakehouse- i panelen som öppnas.
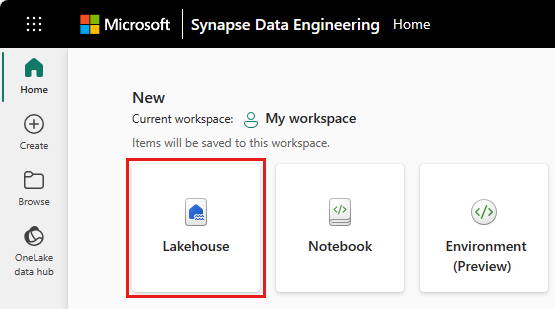
Ange namnet på ditt lakehouse och välj Skapa.

Skapa en Spark-jobbdefinition
Använd följande steg för att skapa en Spark-jobbdefinition:
På samma arbetsyta där du skapade ett sjöhus väljer du Nytt objekt.
I panelen som öppnas, under Hämta data, väljer du Spark-jobbdefinition.
Ange namnet på spark-jobbdefinitionen och välj Skapa.
Välj Ladda upp och välj den Python-fil som du skapade i föregående steg.
Under Lakehouse Reference väljer du det sjöhus som du skapade.
Ange återförsöksprincip för Spark-jobbdefinition
Använd följande steg för att ange återförsöksprincipen för spark-jobbdefinitionen:
På den översta menyn väljer du inställningsikonen.
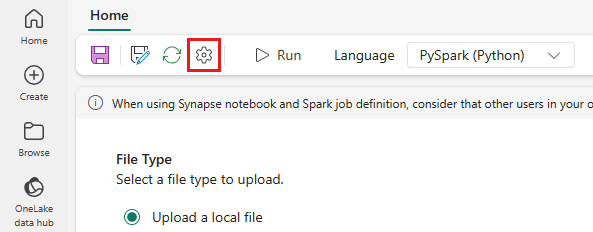
Öppna fliken Optimering och ställ in återförsöksprinciputlösarenPå.
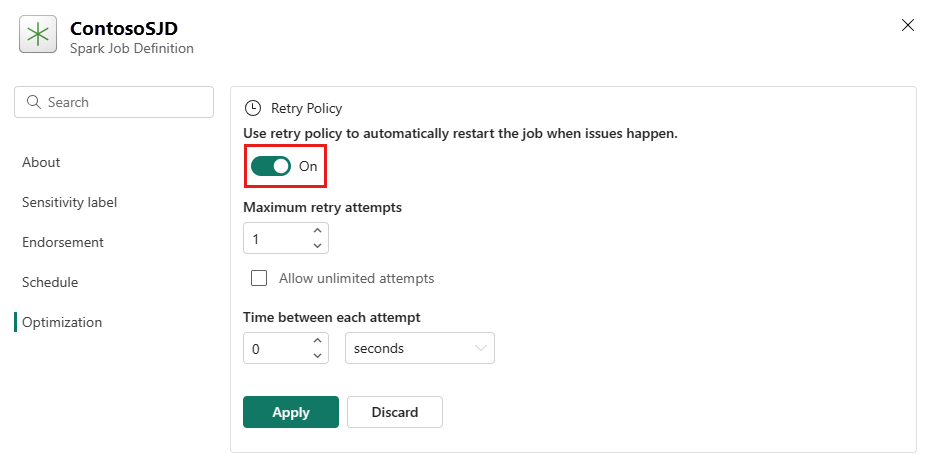
Definiera maximalt antal återförsök eller markera Tillåt obegränsade försök.
Ange tid mellan varje nytt försök och välj Använd.


Kommentar
Det finns en livstidsgräns på 90 dagar för konfigurationen av återförsöksprincipen. När återförsöksprincipen har aktiverats startas jobbet om enligt principen inom 90 dagar. Efter den här perioden upphör återförsöksprincipen automatiskt att fungera och jobbet avslutas. Användarna måste sedan starta om jobbet manuellt, vilket i sin tur återaktiverar återförsöksprincipen.
Köra och övervaka Spark-jobbdefinitionen
Välj ikonen Kör på den översta menyn.
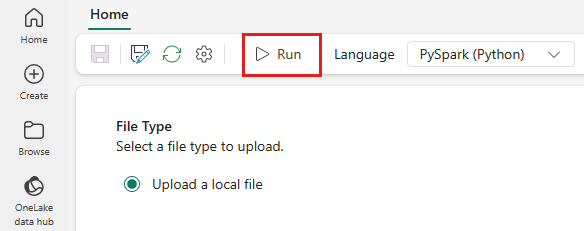
Kontrollera om Spark-jobbdefinitionen har skickats in framgångsrikt och körs.

Visa data med hjälp av en SQL-analysslutpunkt
När skriptet har körts skapas en tabell med namnet streamingtable med tidsstämpel och värdekolumner i lakehouse. Du kan visa data med hjälp av SQL-analysslutpunkten:
Från arbetsytan, öppna din Lakehouse.
Växla till SQL-analysslutpunkten från det övre högra hörnet.
I den vänstra navigeringsrutan expanderar du Scheman > dbo >Tabeller, och väljer streamingtable för att förhandsgranska data.