Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Microsoft Fabric är en integrerad analystjänst som påskyndar tiden för insikter i informationslager och stordatasystem. Datavisualisering i notebook-filer är en viktig funktion som gör att du enkelt kan få insyn i dina data och hjälpa användarna att identifiera mönster, trender och extremvärden.
När du arbetar med Apache Spark i Fabric har du inbyggda alternativ för att visualisera data, inklusive funktioner för notebook-diagram i Fabric och åtkomst till populära bibliotek med öppen källkod.
Med fabric-anteckningsböcker kan du också konvertera tabellresultat till skräddarsydda diagram utan att skriva någon kod, vilket möjliggör en mer intuitiv och sömlös datautforskningsupplevelse.
Inbyggt visualiseringskommando – display()-funktion
Med den inbyggda visualiseringsfunktionen Fabric kan du omvandla Apache Spark DataFrames, Pandas DataFrames och SQL-frågeresultat till omfattande interaktiva datavisualiseringar.
Med hjälp av visningsfunktionen kan du återge PySpark och Scala Spark DataFrames eller Resilient Distributed Datasets (RDD) som dynamiska tabeller eller diagram.
Du kan ange radantalet för dataramen som återges. Standardvärdet är 1 000. Notebook utmatningswidgeten stöder visning och profilering av högst 10 000 rader i en dataram.

Du kan använda filterfunktionen i det globala verktygsfältet för att tillämpa anpassade regler på dina data. Filtervillkoret tillämpas på en angiven kolumn och resultatet återspeglas i både tabell- och diagramvyerna.

Utdata från SQL-instruktionen använder samma utdatawidget med display() som standard.
Tabellvy för rtf-dataram
Stöd för kostnadsfritt urval i tabellvyn
Som standardinställning visas tabellvyn när du använder kommandot display() i en Fabric-anteckningsbok. Den detaljerade förhandsvisningen av dataramen erbjuder en intuitiv funktion för fri markering som är utformad för att förbättra dataanalysupplevelsen genom att möjliggöra flexibla, interaktiva urvalsalternativ. Med den här funktionen kan användarna enkelt navigera och utforska dataramar.
Val av kolumn
- Enskild kolumn: Klicka på kolumnrubriken för att välja hela kolumnen.
- Flera kolumner: När du har valt en enda kolumn trycker du på och håller ned Skift-tangenten och klickar sedan på en annan kolumnrubrik för att välja flera kolumner.
Radsval
- Enskild rad: Klicka på en radrubrik för att markera hela raden.
- Flera rader: När du har valt en rad trycker du på och håller ned Skift-tangenten och klickar sedan på en annan radrubrik för att markera flera rader.
Förhandsgranskning av cellinnehåll: Förhandsgranska innehållet i enskilda celler för att få en snabb och detaljerad titt på data utan att behöva skriva ytterligare kod.
Kolumnsammanfattning: Få en sammanfattning av varje kolumn, inklusive datadistribution och nyckelstatistik, för att snabbt förstå dataegenskaperna.
Val av fritt område: Välj ett kontinuerligt segment i tabellen för att få en översikt över de totala markerade cellerna och de numeriska värdena i det markerade området.
Kopiera valt innehåll: I alla urvalsfall kan du snabbt kopiera det valda innehållet med genvägen Ctrl + C. De valda data kopieras i CSV-format, vilket gör det enkelt att bearbeta i andra program.
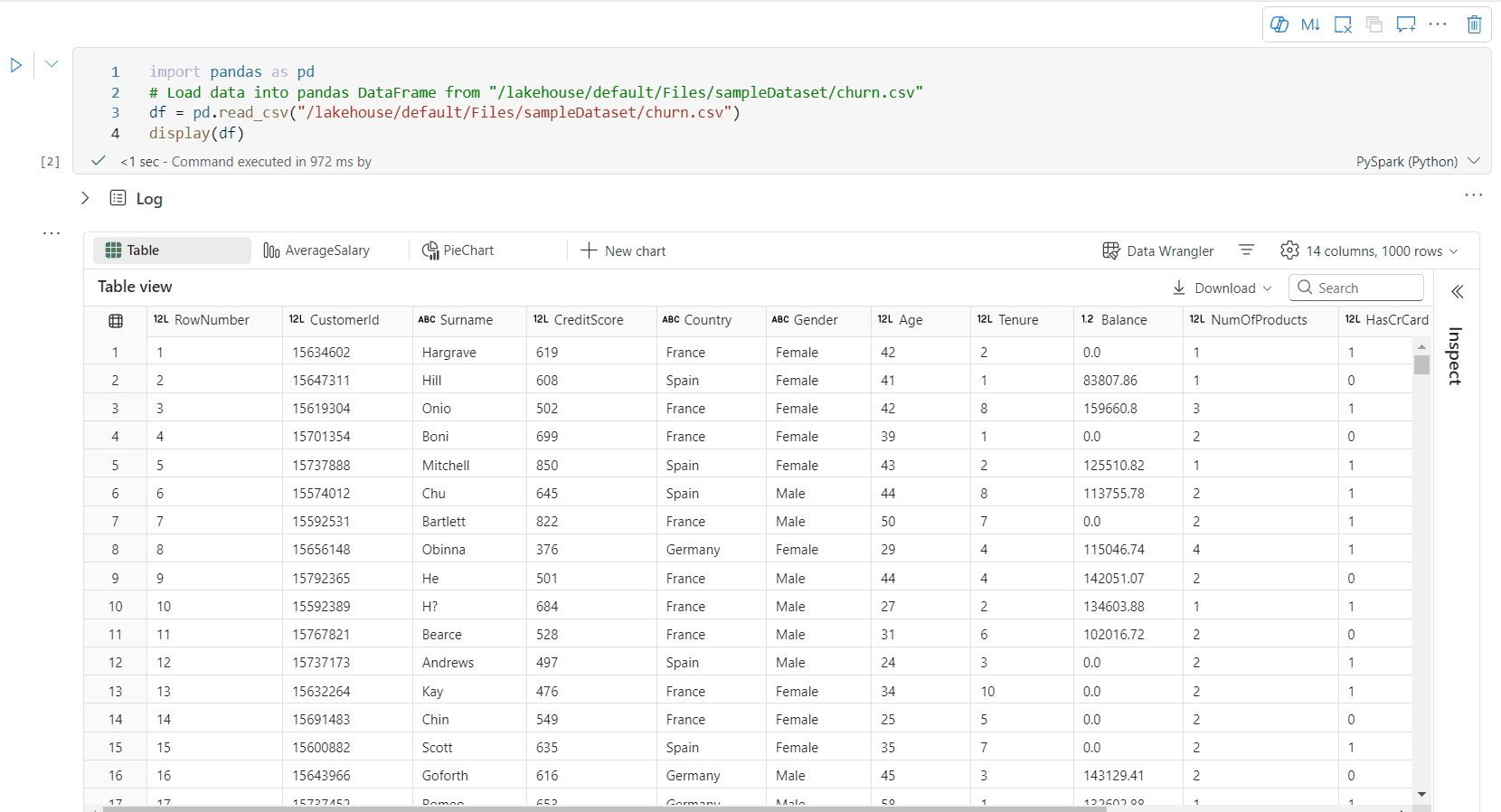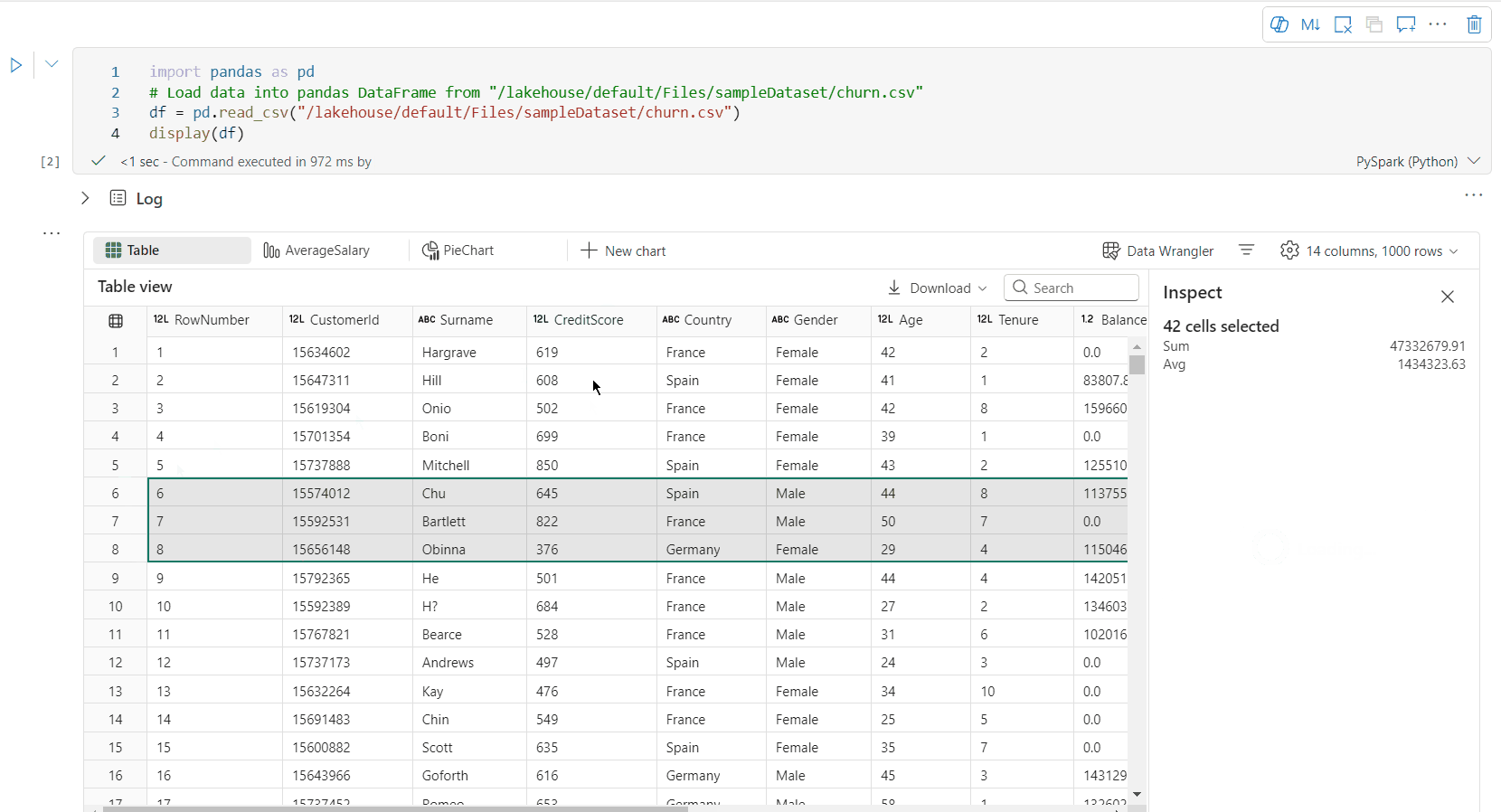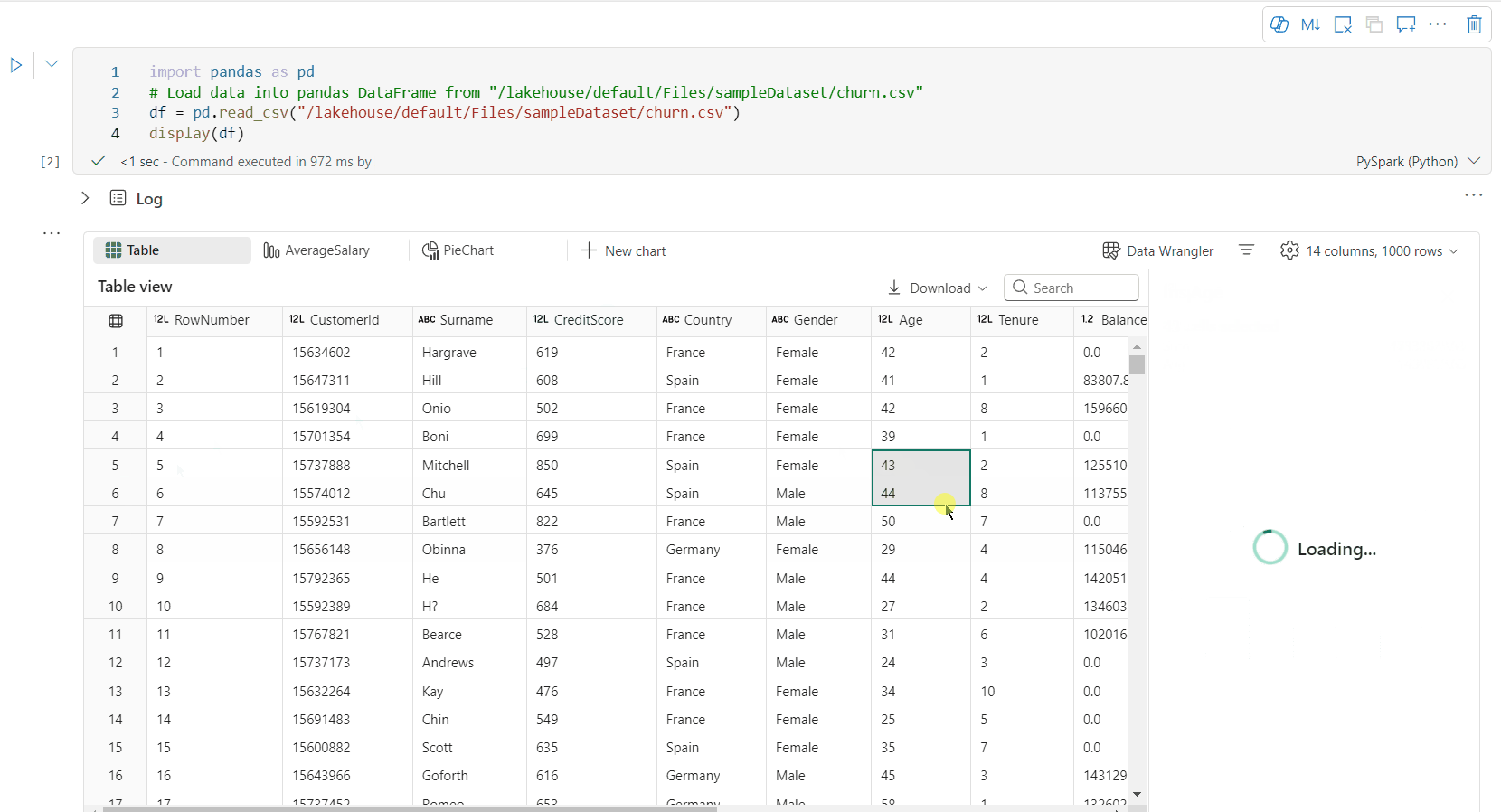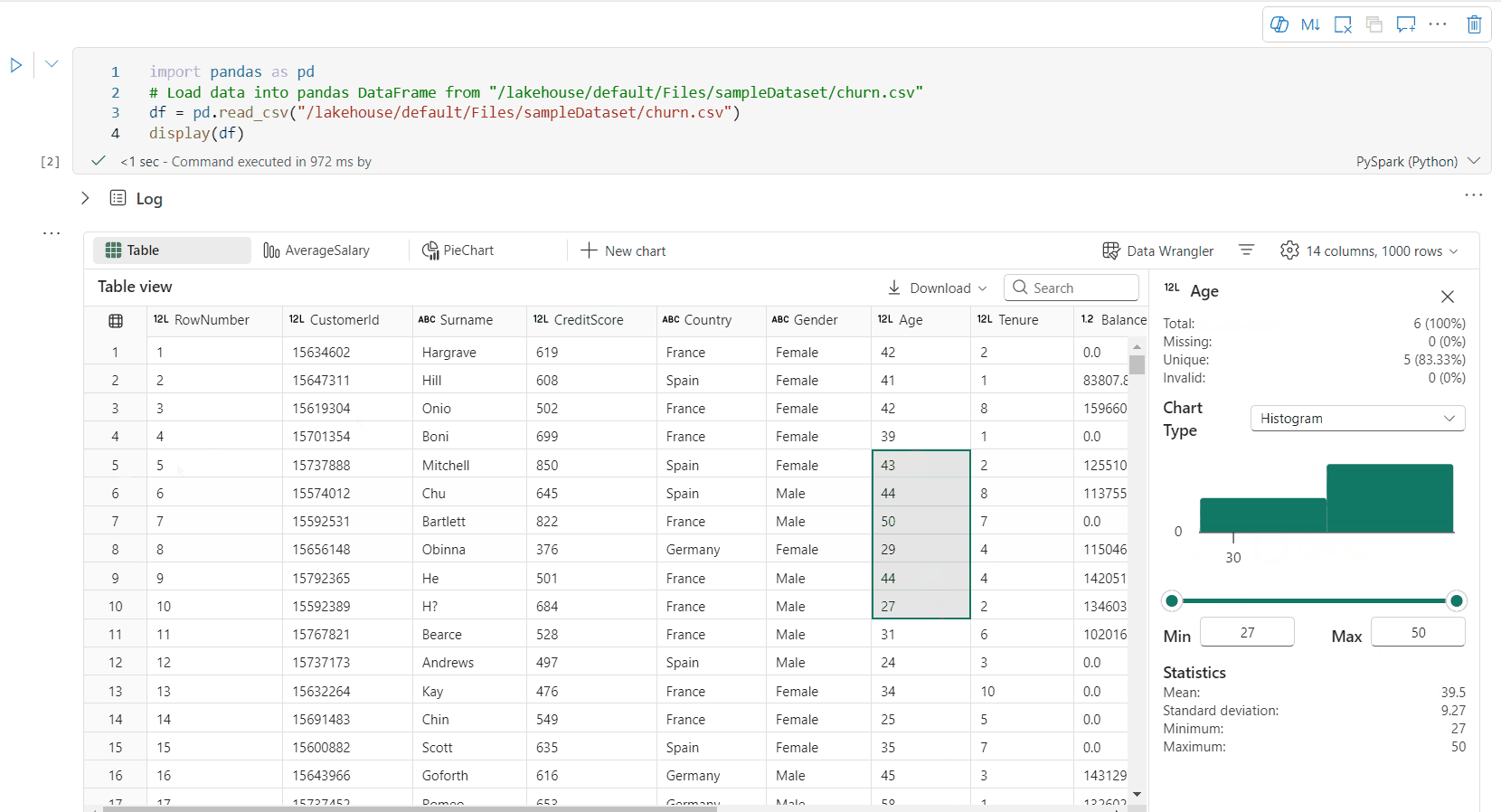

Stöd för dataprofilering via fönstret Inspektera

Du kan profilera din dataram genom att klicka på knappen Inspektera . Den innehåller sammanfattad datadistribution och visar statistik för varje kolumn.
Varje kort i sidofönstret "Inspektera" mappar till en kolumn i dataramen. Du kan visa mer information genom att klicka på kortet eller välja en kolumn i tabellen.
Du kan visa cellinformationen genom att klicka på cellen i tabellen. Den här funktionen är användbar när dataramen innehåller lång strängtyp av innehåll.
Utökad vy över rich dataframe-diagram
Den förbättrade diagramvyn i kommandot display() ger ett mer intuitivt och dynamiskt sätt att visualisera dina data.
Viktiga förbättringar:
Stöd för flera diagram: Lägg till upp till fem diagram i en enda display() utdatawidget genom att välja Nytt diagram, vilket möjliggör enkla jämförelser mellan olika kolumner.
Rekommendationer för smart diagram: Hämta en lista över föreslagna diagram baserat på din DataFrame. Välj att redigera en rekommenderad visualisering eller skapa ett anpassat diagram från grunden.

Flexibel anpassning: Anpassa dina visualiseringar med justerbara inställningar som anpassas baserat på den valda diagramtypen.
Kategori Grundläggande inställningar Beskrivning Diagramtyp Visningsfunktionen stöder ett brett spektrum av diagramtyper, inklusive stapeldiagram, punktdiagram, linjediagram, pivottabell med mera. Titel Titel Diagrammets rubrik. Titel Undertext Underrubriken för diagrammet med fler beskrivningar. Uppgifter X-axel Ange nyckeln i diagrammet. Uppgifter Y-axel Ange diagrammets värden. Legenda Visa teckenförklaring Aktivera/inaktivera teckenförklaringen. Legenda Ställning Anpassa legendens position. Övrigt Seriegrupp Använd den här konfigurationen för att fastställa grupperna för aggregeringen. Övrigt Aggregering Använd den här metoden för att aggregera data i visualiseringen. Övrigt Staplad Konfigurera visningsformatet för resultatet. Övrigt Saknade värden och NULL-värden Konfigurera hur värden för saknade diagram eller NULL-diagram visas. Anmärkning
Dessutom kan du ange antalet rader som visas, med en standardinställning på 1 000. Utdatawidgeten för notebook-visning stöder visning och profilering av upp till 10 000 rader i en DataFrame. Välj Sammansättning över alla resultat och välj sedan Tillämpa för att tillämpa diagramgenereringen från hela dataramen. Ett Spark-jobb utlöses när diagraminställningen ändras. Det kan ta flera minuter att slutföra beräkningen och återge diagrammet.
Kategori Avancerade inställningar Beskrivning Färg Tema Definiera temafärguppsättningen i diagrammet. X-axel Etikett Ange en etikett för X-axeln. X-axel Skala Ange skalningsfunktionen för X-axeln. X-axel Räckvidd Ange värdeintervallet X-axel. Y-axel Etikett Ange en etikett för Y-axeln. Y-axel Skala Ange skalningsfunktionen för Y-axeln. Y-axel Räckvidd Ange värdeintervallet Y-axel. Skärm Visa etiketter Visa/dölj resultatetiketterna i diagrammet. Konfigurationsändringarna börjar gälla omedelbart och alla konfigurationer sparas automatiskt i notebook-innehåll.
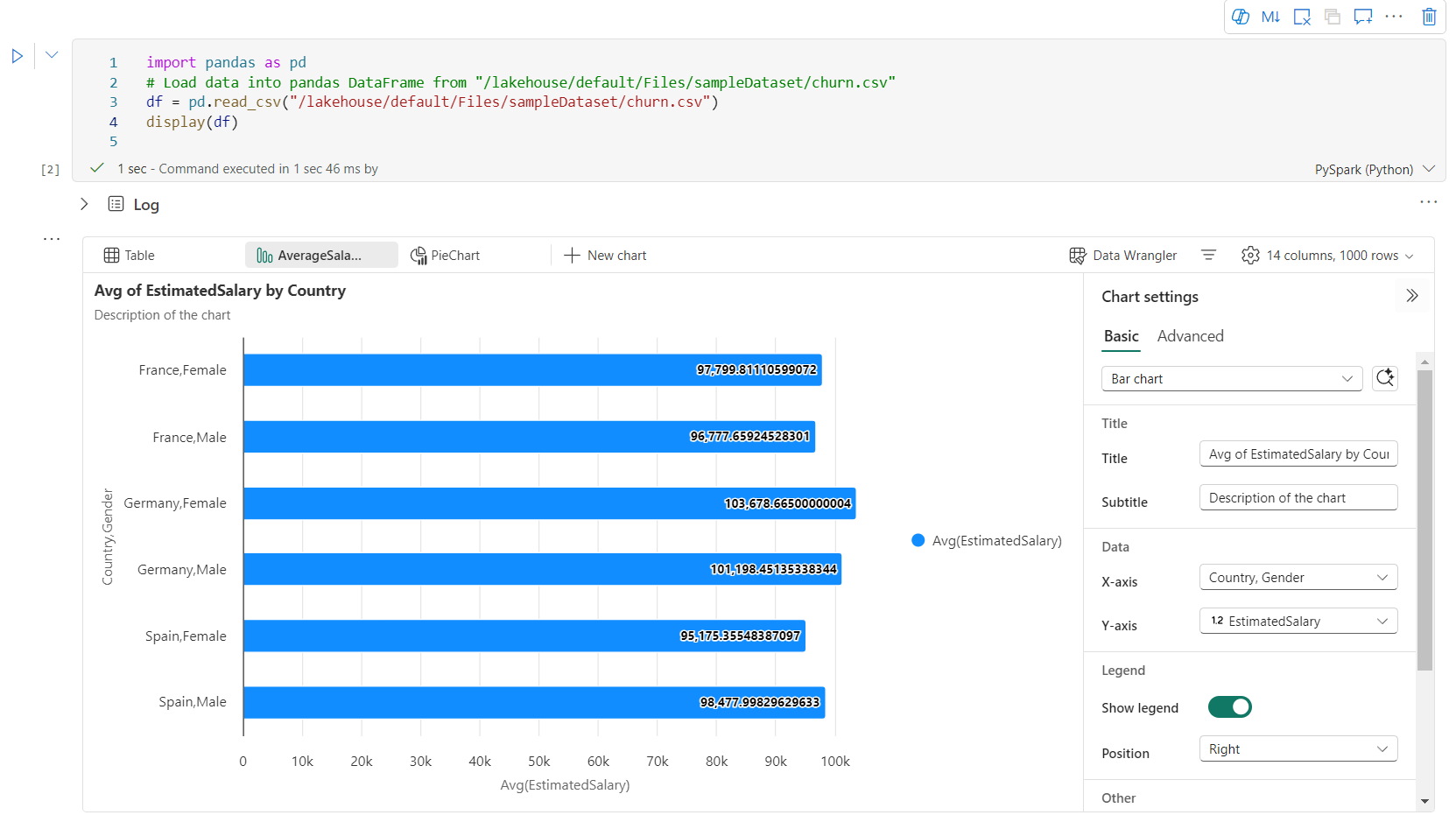
Du kan enkelt byta namn på, duplicera, ta bort eller flytta diagram på diagramfliksmenyn. Du kan också dra och släppa flikar för att ordna om dem. Den första fliken visas som standard när anteckningsboken öppnas.
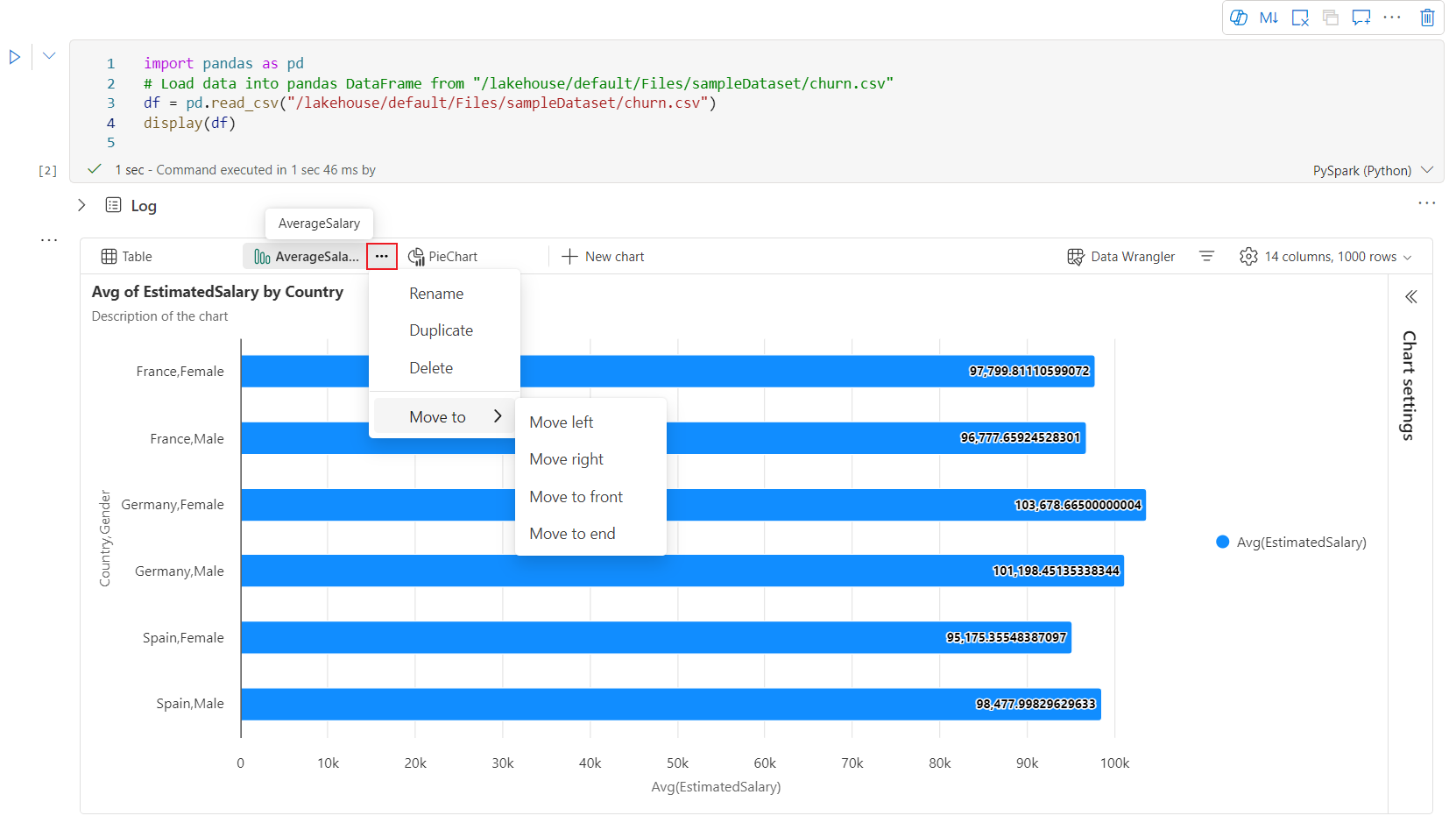
Ett interaktivt verktygsfält är tillgängligt i den nya diagramupplevelsen när användaren hovrar på ett diagram. Stödåtgärder som att zooma in, zooma ut, välja att zooma, återställa, panorera, kommentera redigering osv.
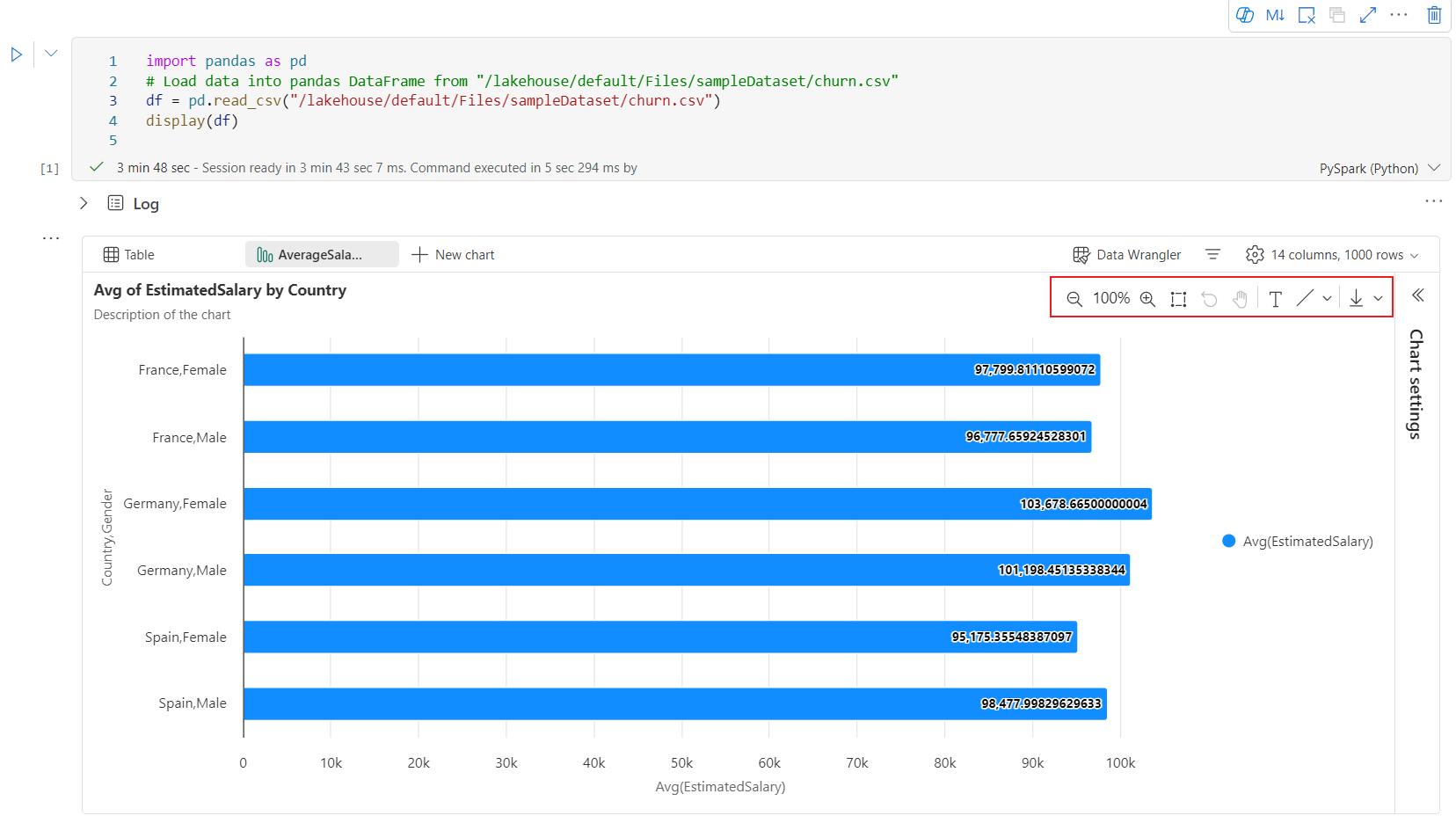
Här är ett exempel på diagramanteckning.
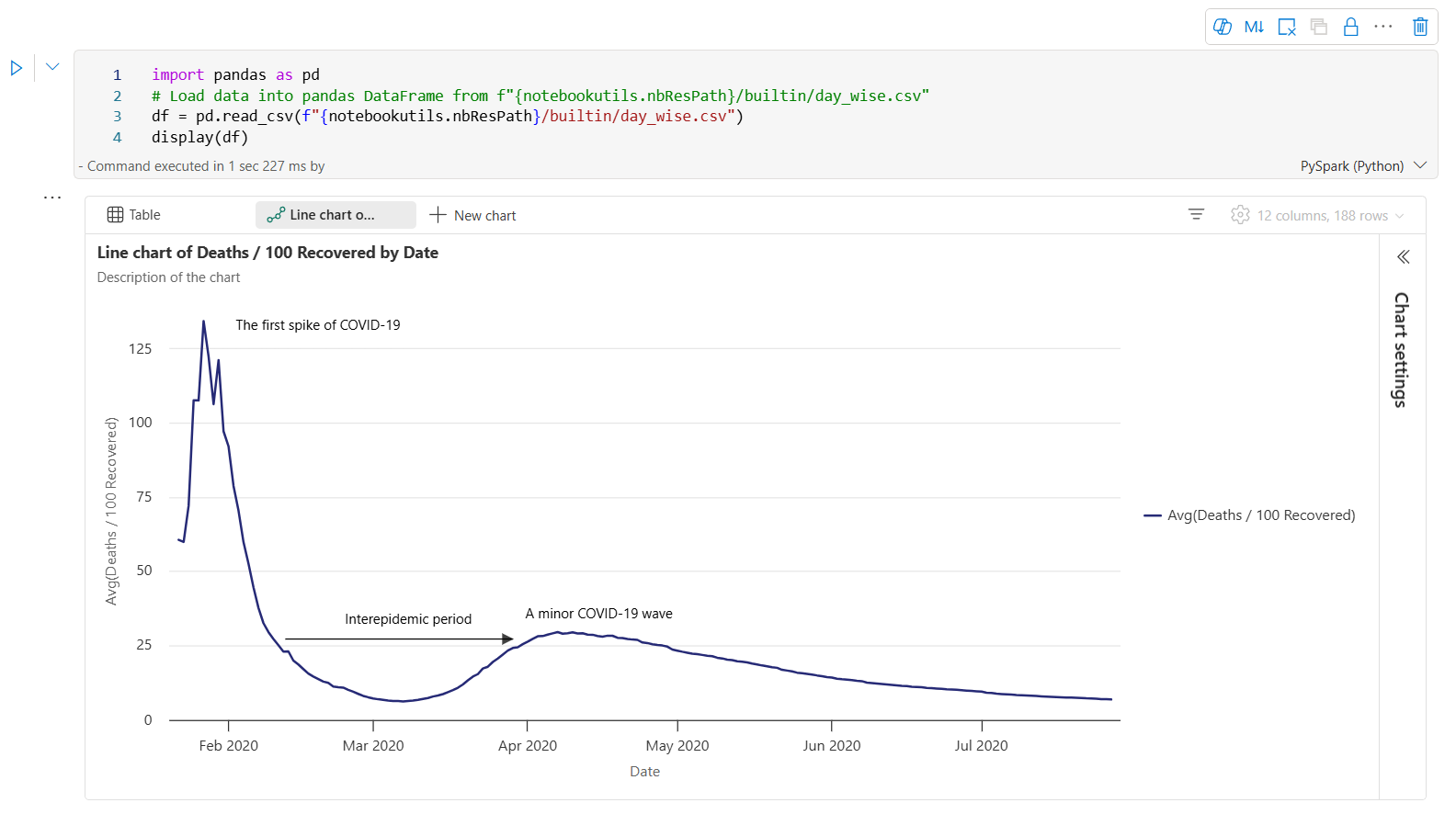




visa() sammanfattningsvy
Använd display(df, summary = true) för att kontrollera statistiksammanfattningen för en viss Apache Spark DataFrame. Sammanfattningen innehåller kolumnnamn, kolumntyp, unika värden och saknade värden för varje kolumn. Du kan också välja en specifik kolumn för att se dess minsta värde, högsta värde, medelvärde och standardavvikelse.

displayHTML()-alternativ
Anteckningsböcker för Fabric stöder HTML-grafik med hjälp av funktionen displayHTML.
Följande bild är ett exempel på hur du skapar visualiseringar med hjälp av D3.js.

Kör följande kod för att skapa den här visualiseringen.
displayHTML("""<!DOCTYPE html>
<meta charset="utf-8">
<!-- Load d3.js -->
<script src="https://d3js.org/d3.v4.js"></script>
<!-- Create a div where the graph will take place -->
<div id="my_dataviz"></div>
<script>
// set the dimensions and margins of the graph
var margin = {top: 10, right: 30, bottom: 30, left: 40},
width = 400 - margin.left - margin.right,
height = 400 - margin.top - margin.bottom;
// append the svg object to the body of the page
var svg = d3.select("#my_dataviz")
.append("svg")
.attr("width", width + margin.left + margin.right)
.attr("height", height + margin.top + margin.bottom)
.append("g")
.attr("transform",
"translate(" + margin.left + "," + margin.top + ")");
// Create Data
var data = [12,19,11,13,12,22,13,4,15,16,18,19,20,12,11,9]
// Compute summary statistics used for the box:
var data_sorted = data.sort(d3.ascending)
var q1 = d3.quantile(data_sorted, .25)
var median = d3.quantile(data_sorted, .5)
var q3 = d3.quantile(data_sorted, .75)
var interQuantileRange = q3 - q1
var min = q1 - 1.5 * interQuantileRange
var max = q1 + 1.5 * interQuantileRange
// Show the Y scale
var y = d3.scaleLinear()
.domain([0,24])
.range([height, 0]);
svg.call(d3.axisLeft(y))
// a few features for the box
var center = 200
var width = 100
// Show the main vertical line
svg
.append("line")
.attr("x1", center)
.attr("x2", center)
.attr("y1", y(min) )
.attr("y2", y(max) )
.attr("stroke", "black")
// Show the box
svg
.append("rect")
.attr("x", center - width/2)
.attr("y", y(q3) )
.attr("height", (y(q1)-y(q3)) )
.attr("width", width )
.attr("stroke", "black")
.style("fill", "#69b3a2")
// show median, min and max horizontal lines
svg
.selectAll("toto")
.data([min, median, max])
.enter()
.append("line")
.attr("x1", center-width/2)
.attr("x2", center+width/2)
.attr("y1", function(d){ return(y(d))} )
.attr("y2", function(d){ return(y(d))} )
.attr("stroke", "black")
</script>
"""
)
Bädda in en Power BI-rapport i en notebook-fil
Viktigt!
Den här funktionen är i förhandsversion.
Powerbiclient Python-paketet stöds nu internt i Fabric Notebooks. Du behöver inte göra någon extra installation (t.ex. autentiseringsprocess) i Spark-körningsmiljön i Fabric Notebook 3.4.
powerbiclient Importera bara och fortsätt sedan din utforskning. Mer information om hur du använder powerbiclient-paketet finns i powerbiclient-dokumentationen.
Powerbiclient stöder följande viktiga funktioner.
Rendera en befintlig Power BI-rapport
Du kan enkelt bädda in och interagera med Power BI-rapporter i dina notebook-filer med bara några rader kod.
Följande bild är ett exempel på återgivning av befintlig Power BI-rapport.

Kör följande kod för att återge en befintlig Power BI-rapport.
from powerbiclient import Report
report_id="Your report id"
report = Report(group_id=None, report_id=report_id)
report
Skapa visuella rapportobjekt från en Spark DataFrame
Du kan använda en Spark DataFrame i notebook-filen för att snabbt generera insiktsfulla visualiseringar. Du kan också välja Spara i den inbäddade rapporten för att skapa ett rapportobjekt på en målarbetsyta.
Följande bild är ett exempel på en QuickVisualize() från en Spark DataFrame.

Kör följande kod för att återge en rapport från en Spark DataFrame.
# Create a spark dataframe from a Lakehouse parquet table
sdf = spark.sql("SELECT * FROM testlakehouse.table LIMIT 1000")
# Create a Power BI report object from spark data frame
from powerbiclient import QuickVisualize, get_dataset_config
PBI_visualize = QuickVisualize(get_dataset_config(sdf))
# Render new report
PBI_visualize
Skapa rapportvisualiseringar från en pandas DataFrame
Du kan också skapa rapporter baserat på en Pandas DataFrame i en anteckningsbok.
Följande bild är ett exempel på en QuickVisualize() från en pandas dataframe.

Kör följande kod för att återge en rapport från en Spark DataFrame.
import pandas as pd
# Create a pandas dataframe from a URL
df = pd.read_csv("https://raw.githubusercontent.com/plotly/datasets/master/fips-unemp-16.csv")
# Create a pandas dataframe from a Lakehouse csv file
from powerbiclient import QuickVisualize, get_dataset_config
# Create a Power BI report object from your data
PBI_visualize = QuickVisualize(get_dataset_config(df))
# Render new report
PBI_visualize
Populära bibliotek
När det gäller datavisualisering erbjuder Python flera grafbibliotek som är fyllda med många olika funktioner. Som standard innehåller varje Apache Spark-pool i Fabric en uppsättning kuraterade och populära bibliotek med öppen källkod.
Matplotlib
Du kan rendera standardritningsbibliotek, till exempel Matplotlib, med hjälp av de inbyggda återgivningsfunktionerna för varje bibliotek.
Följande bild är ett exempel på hur du skapar ett stapeldiagram med hjälp av Matplotlib.


Kör följande exempelkod för att rita det här stapeldiagrammet.
# Bar chart
import matplotlib.pyplot as plt
x1 = [1, 3, 4, 5, 6, 7, 9]
y1 = [4, 7, 2, 4, 7, 8, 3]
x2 = [2, 4, 6, 8, 10]
y2 = [5, 6, 2, 6, 2]
plt.bar(x1, y1, label="Blue Bar", color='b')
plt.bar(x2, y2, label="Green Bar", color='g')
plt.plot()
plt.xlabel("bar number")
plt.ylabel("bar height")
plt.title("Bar Chart Example")
plt.legend()
plt.show()
Bokeh-effekt
Du kan rendera HTML- eller interaktiva bibliotek, till exempel bokeh, med hjälp av displayHTML(df).
Följande bild är ett exempel på ritning av glyfer över en karta med hjälp av bokeh.

Om du vill rita den här avbildningen kör du följande exempelkod.
from bokeh.plotting import figure, output_file
from bokeh.tile_providers import get_provider, Vendors
from bokeh.embed import file_html
from bokeh.resources import CDN
from bokeh.models import ColumnDataSource
tile_provider = get_provider(Vendors.CARTODBPOSITRON)
# range bounds supplied in web mercator coordinates
p = figure(x_range=(-9000000,-8000000), y_range=(4000000,5000000),
x_axis_type="mercator", y_axis_type="mercator")
p.add_tile(tile_provider)
# plot datapoints on the map
source = ColumnDataSource(
data=dict(x=[ -8800000, -8500000 , -8800000],
y=[4200000, 4500000, 4900000])
)
p.circle(x="x", y="y", size=15, fill_color="blue", fill_alpha=0.8, source=source)
# create an html document that embeds the Bokeh plot
html = file_html(p, CDN, "my plot1")
# display this html
displayHTML(html)
Plotly
Du kan rendera HTML- eller interaktiva bibliotek som Plotly med hjälp av displayHTML().
Om du vill rita den här avbildningen kör du följande exempelkod.

from urllib.request import urlopen
import json
with urlopen('https://raw.githubusercontent.com/plotly/datasets/master/geojson-counties-fips.json') as response:
counties = json.load(response)
import pandas as pd
df = pd.read_csv("https://raw.githubusercontent.com/plotly/datasets/master/fips-unemp-16.csv",
dtype={"fips": str})
import plotly
import plotly.express as px
fig = px.choropleth(df, geojson=counties, locations='fips', color='unemp',
color_continuous_scale="Viridis",
range_color=(0, 12),
scope="usa",
labels={'unemp':'unemployment rate'}
)
fig.update_layout(margin={"r":0,"t":0,"l":0,"b":0})
# create an html document that embeds the Plotly plot
h = plotly.offline.plot(fig, output_type='div')
# display this html
displayHTML(h)
Pandor
Du kan visa HTML-utdata från Pandas DataFrames som standardutdata. Fabric-anteckningsböcker visar automatiskt det formaterade HTML-innehållet.

import pandas as pd
import numpy as np
df = pd.DataFrame([[38.0, 2.0, 18.0, 22.0, 21, np.nan],[19, 439, 6, 452, 226,232]],
index=pd.Index(['Tumour (Positive)', 'Non-Tumour (Negative)'], name='Actual Label:'),
columns=pd.MultiIndex.from_product([['Decision Tree', 'Regression', 'Random'],['Tumour', 'Non-Tumour']], names=['Model:', 'Predicted:']))
df