Anteckning
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Anteckning
Apache Airflow-jobbet drivs av Apache Airflow.
dbt(Data Build Tool) är ett kommandoradsgränssnitt med öppen källkod (CLI) som förenklar datatransformering och modellering i informationslager genom att hantera komplex SQL-kod på ett strukturerat och underhållsbart sätt. Det gör det möjligt för datateam att skapa tillförlitliga, testbara transformeringar i kärnan av sina analyspipelines.
I kombination med Apache Airflow förbättras dbts transformeringsfunktioner med Airflows funktioner för schemaläggning, orkestrering och uppgiftshantering. Den här kombinerade metoden, med hjälp av dbts transformeringsexpertis tillsammans med Airflows arbetsflödeshantering, ger effektiva och robusta datapipelines, vilket i slutändan leder till snabbare och mer insiktsfulla datadrivna beslut.
Den här handledningen beskriver hur du skapar en Apache Airflow DAG som använder dbt för att transformera data som lagras i Microsoft Fabric Data Warehouse.
Förutsättningar
För att komma igång måste du uppfylla följande krav:
Skapa tjänstens huvudnamn. Lägg till tjänstens huvudnamn som
Contributorpå arbetsytan där du skapar informationslagret.Om du inte har ett, skapa ett Fabric-lager. Mata in exempeldata i lagret med hjälp av datapipelinen. I den här handledningen använder vi exemplet Taxi-Green NYC.
Transformera datan som lagras i Fabric warehouse med hjälp av dbt
I det här avsnittet går vi igenom följande steg:
- Ange kraven.
- Skapa ett dbt-projekt i den infrastrukturhanterade lagringen som tillhandahålls av Apache Airflow-jobbet..
- Skapa en Apache Airflow DAG för att orkestrera dbt-jobb
Ange kraven
Skapa en fil requirements.txt i dags mappen. Lägg till följande paket som Apache Airflow-krav.
astronomer-cosmos: Det här paketet används för att köra dina dbt core-projekt som Apache Airflow DAGs och aktivitetsgrupper.
dbt-fabric: Det här paketet används för att skapa ett dbt-projekt, som sedan kan distribueras till ett infrastrukturdatalager
astronomer-cosmos==1.0.3 dbt-fabric==1.5.0
Skapa ett dbt-projekt i den Fabric-hanterade lagringen som tillhandahålls av Apache Airflow-jobbet.
I det här avsnittet skapar vi ett exempel på ett dbt-projekt i Apache Airflow-jobbet för datamängden
nyc_taxi_greenmed följande katalogstruktur.dags |-- my_cosmos_dag.py |-- nyc_taxi_green | |-- profiles.yml | |-- dbt_project.yml | |-- models | | |-- nyc_trip_count.sql | |-- targetSkapa mappen med namnet
nyc_taxi_greenidagsmappen medprofiles.ymlfilen. Den här mappen innehåller alla filer som krävs för dbt-projektet.
Kopiera följande innehåll till
profiles.yml. Den här konfigurationsfilen innehåller information om databasanslutningen och profiler som används av dbt. Uppdatera platshållarvärdena och spara filen.config: partial_parse: true nyc_taxi_green: target: fabric-dev outputs: fabric-dev: type: fabric driver: "ODBC Driver 18 for SQL Server" server: <sql connection string of your data warehouse> port: 1433 database: "<name of the database>" schema: dbo threads: 4 authentication: ServicePrincipal tenant_id: <Tenant ID of your service principal> client_id: <Client ID of your service principal> client_secret: <Client Secret of your service principal>dbt_project.ymlSkapa filen och kopiera följande innehåll. Den här filen anger konfigurationen på projektnivå.name: "nyc_taxi_green" config-version: 2 version: "0.1" profile: "nyc_taxi_green" model-paths: ["models"] seed-paths: ["seeds"] test-paths: ["tests"] analysis-paths: ["analysis"] macro-paths: ["macros"] target-path: "target" clean-targets: - "target" - "dbt_modules" - "logs" require-dbt-version: [">=1.0.0", "<2.0.0"] models: nyc_taxi_green: materialized: tablemodelsSkapa mappen inyc_taxi_greenmappen. I den här självstudien skapar vi exempelmodellen i filen med namnetnyc_trip_count.sqlsom skapar tabellen som visar antalet resor per dag per leverantör. Kopiera följande innehåll i filen.with new_york_taxis as ( select * from nyctlc ), final as ( SELECT vendorID, CAST(lpepPickupDatetime AS DATE) AS trip_date, COUNT(*) AS trip_count FROM [contoso-data-warehouse].[dbo].[nyctlc] GROUP BY vendorID, CAST(lpepPickupDatetime AS DATE) ORDER BY vendorID, trip_date; ) select * from final


Skapa en Apache Airflow DAG för att orkestrera dbt-jobb
Skapa filen med namnet
my_cosmos_dag.pyidagsmappen och klistra in följande innehåll i den.import os from pathlib import Path from datetime import datetime from cosmos import DbtDag, ProjectConfig, ProfileConfig, ExecutionConfig from airflow import DAG DEFAULT_DBT_ROOT_PATH = Path(__file__).parent.parent / "dags" / "nyc_taxi_green" DBT_ROOT_PATH = Path(os.getenv("DBT_ROOT_PATH", DEFAULT_DBT_ROOT_PATH)) profile_config = ProfileConfig( profile_name="nyc_taxi_green", target_name="fabric-dev", profiles_yml_filepath=DBT_ROOT_PATH / "profiles.yml", ) dbt_fabric_dag = DbtDag( project_config=ProjectConfig(DBT_ROOT_PATH,), operator_args={"install_deps": True}, profile_config=profile_config, schedule_interval="@daily", start_date=datetime(2023, 9, 10), catchup=False, dag_id="dbt_fabric_dag", )
Kör din DAG
Kör DAG i Apache Airflow-jobbet.
För att se din DAG laddas i Apache Airflows användargränssnitt klickar du på
Monitor in Apache Airflow.
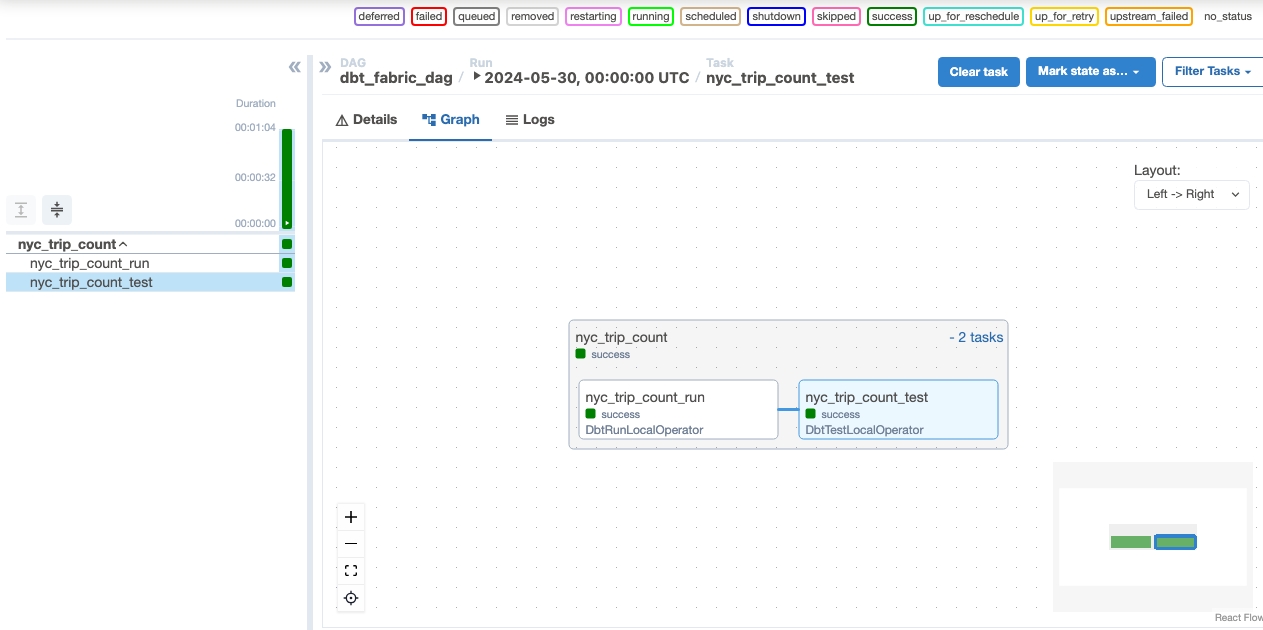



Verifiera dina data
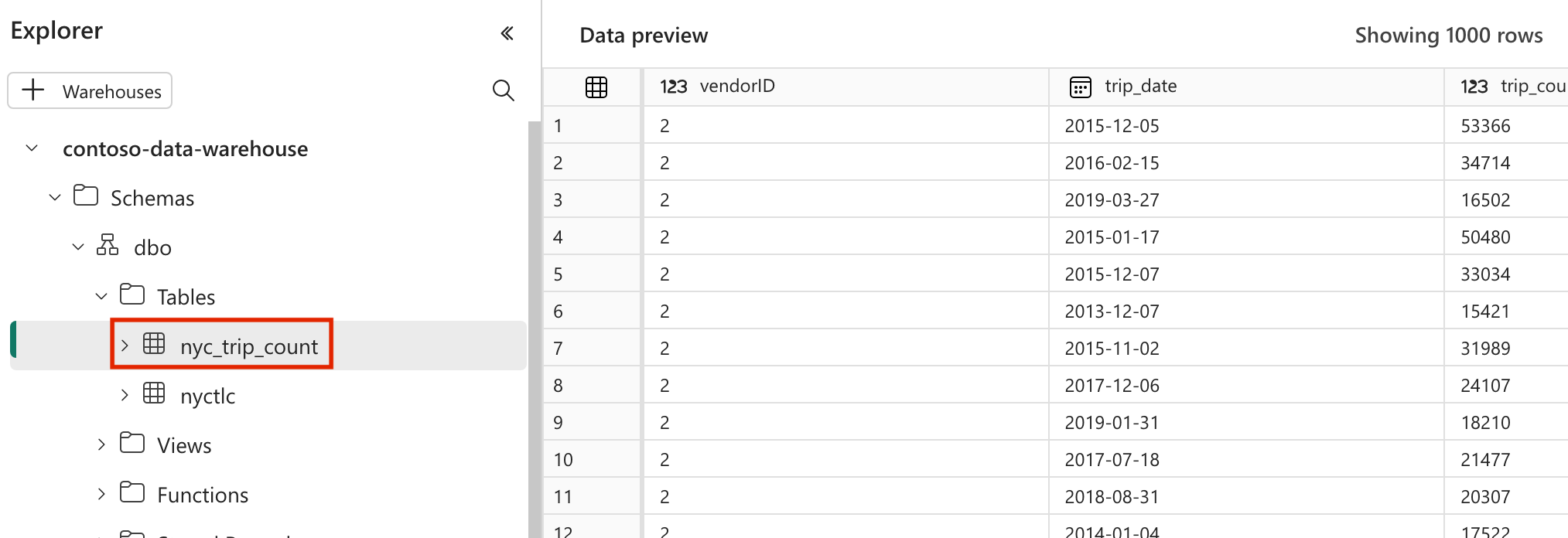
- Efter en lyckad körning kan du, för att validera dina data, se den nya tabellen med namnet "nyc_trip_count.sql" som skapats i ditt Fabric-datalager.