Dataflöde Gen2-datamål och hanterade inställningar
När du har rensat och förberett dina data med Dataflow Gen2 vill du landa dina data i ett mål. Du kan göra detta med hjälp av datamålfunktionerna i Dataflöde Gen2. Med den här funktionen kan du välja mellan olika destinationer, till exempel Azure SQL, Fabric Lakehouse och många fler. Dataflöde Gen2 skriver sedan dina data till målet, och därifrån kan du använda dina data för ytterligare analys och rapportering.
Följande lista innehåller de datamål som stöds.
- Azure SQL-databaser
- Azure Data Explorer (Kusto)
- Fabric Lakehouse
- Infrastrukturlager
- Infrastruktur för KQL-databas
- Infrastruktur för SQL-databas
Startpunkter
Varje datafråga i dataflödet Gen2 kan ha ett datamål. Funktioner och listor stöds inte. du kan bara tillämpa den på tabellfrågor. Du kan ange datamålet för varje fråga individuellt och du kan använda flera olika mål i dataflödet.
Det finns tre huvudsakliga startpunkter för att ange datamålet:
Genom det övre menyfliksområdet.

Via frågeinställningar.

Via diagramvyn.

Ansluta till datamålet
Att ansluta till datamålet liknar att ansluta till en datakälla. Anslutningar kan användas för både läsning och skrivning av dina data, eftersom du har rätt behörigheter för datakällan. Du måste skapa en ny anslutning eller välja en befintlig anslutning och sedan välja Nästa.

Skapa en ny tabell eller välj en befintlig tabell
När du läser in till datamålet kan du antingen skapa en ny tabell eller välja en befintlig tabell.
Skapa en ny tabell
När du väljer att skapa en ny tabell skapas en ny tabell i datamålet under dataflödets Gen2-uppdatering. Om tabellen tas bort i framtiden genom att manuellt gå till målet återskapar dataflödet tabellen under nästa dataflödesuppdatering.
Som standard har tabellnamnet samma namn som frågenamnet. Om du har ogiltiga tecken i tabellnamnet som målet inte stöder justeras tabellnamnet automatiskt. Många mål stöder till exempel inte blanksteg eller specialtecken.

Därefter måste du välja målcontainern. Om du väljer något av infrastrukturdatamålen kan du använda navigatören för att välja den infrastrukturresursartefakt som du vill läsa in dina data i. För Azure-mål kan du antingen ange databasen när anslutningen skapas eller välja databasen från navigatörsupplevelsen.
Använda en befintlig tabell
Om du vill välja en befintlig tabell använder du växlingsknappen överst i navigatören. När du väljer en befintlig tabell måste du välja både Fabric-artefakten/databasen och tabellen med hjälp av navigatören.
När du använder en befintlig tabell kan tabellen inte återskapas i något scenario. Om du tar bort tabellen manuellt från datamålet återskapar inte Dataflow Gen2 tabellen vid nästa uppdatering.

Hanterade inställningar för nya tabeller
När du läser in i en ny tabell är de automatiska inställningarna aktiverade som standard. Om du använder de automatiska inställningarna hanterar Dataflow Gen2 mappningen åt dig. De automatiska inställningarna anger följande beteende:
Ersätt uppdateringsmetod: Data ersätts vid varje uppdatering av dataflödet. Alla data i målet tas bort. Data i målet ersätts med dataflödets utdata.
Hanterad mappning: Mappning hanteras åt dig. När du behöver göra ändringar i dina data/frågor för att lägga till en annan kolumn eller ändra en datatyp justeras mappningen automatiskt för den här ändringen när du publicerar om dataflödet. Du behöver inte gå in på datamålmiljön varje gång du gör ändringar i ditt dataflöde, vilket gör det möjligt att enkelt göra schemaändringar när du publicerar om dataflödet.
Ta bort och återskapa tabellen: För att tillåta dessa schemaändringar tas tabellen bort och återskapas vid varje dataflödesuppdatering. Dataflödesuppdateringen kan orsaka borttagning av relationer eller mått som lades till tidigare i tabellen.
Kommentar
För närvarande stöds endast automatiska inställningar för Lakehouse- och Azure SQL-databaser som datamål.
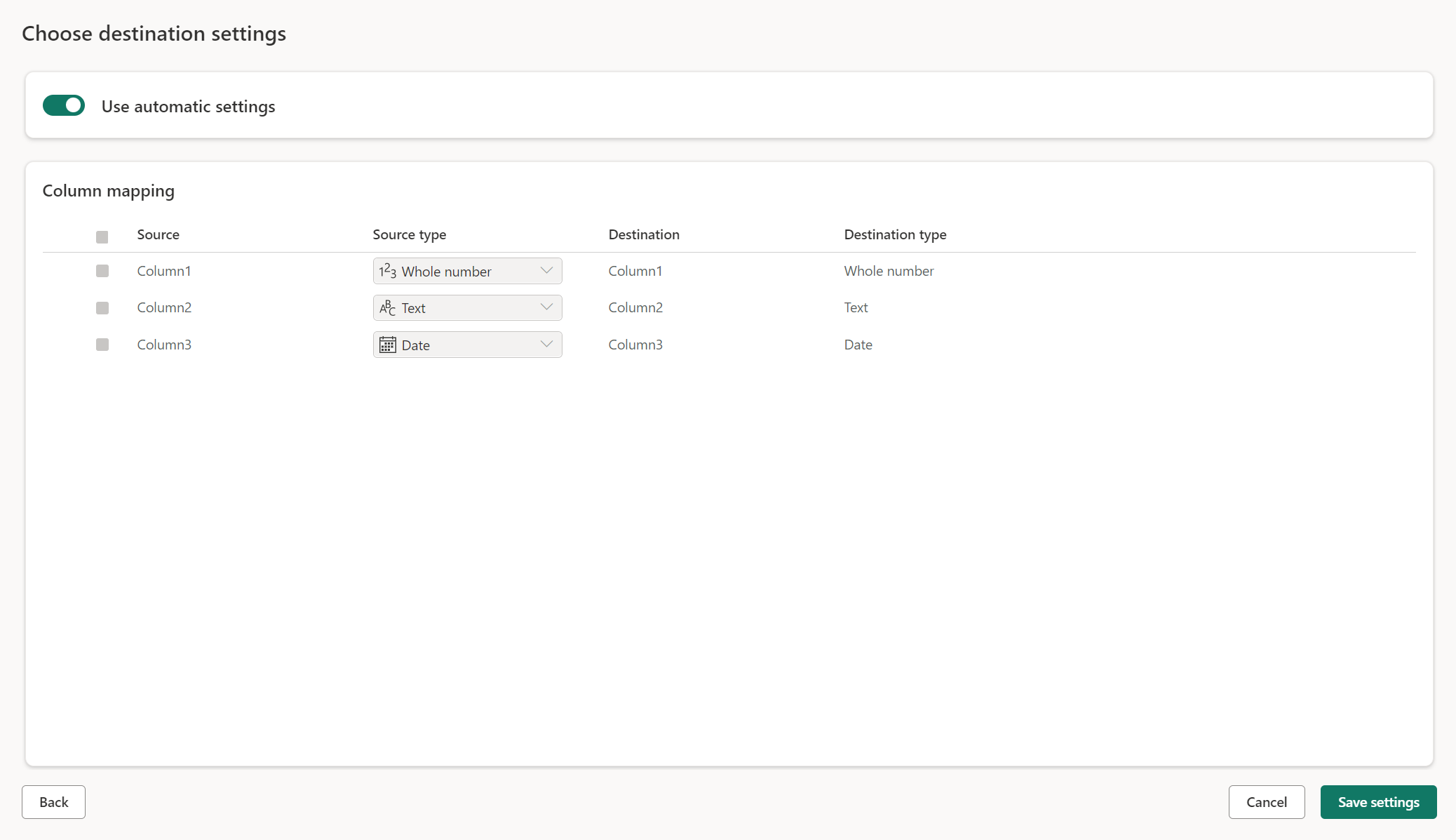
Manuella inställningar
Genom att växla Använd automatiska inställningar får du fullständig kontroll över hur du läser in dina data till datamålet. Du kan göra ändringar i kolumnmappningen genom att ändra källtypen eller exkludera valfri kolumn som du inte behöver i ditt datamål.

Uppdatera metoder
De flesta mål stöder både tillägg och ersättning som uppdateringsmetoder. Fabric KQL-databaser och Azure Data Explorer stöder dock inte ersätt som en uppdateringsmetod.
Ersätt: Vid varje dataflödesuppdatering tas dina data bort från målet och ersätts av dataflödets utdata.
Tillägg: Vid varje dataflödesuppdatering läggs utdata från dataflödet till i befintliga data i datamåltabellen.
Schemaalternativ vid publicering
Schemaalternativ för publicering gäller endast när uppdateringsmetoden ersätts. När du lägger till data är det inte möjligt att ändra schemat.
Dynamiskt schema: När du väljer dynamiskt schema tillåter du schemaändringar i datamålet när du publicerar om dataflödet. Eftersom du inte använder hanterad mappning måste du fortfarande uppdatera kolumnmappningen i dataflödesmålflödet när du gör några ändringar i frågan. När dataflödet uppdateras tas tabellen bort och återskapas. Dataflödesuppdateringen kan orsaka borttagning av relationer eller mått som lades till tidigare i tabellen.
Fast schema: Schemaändringar är inte möjliga när du väljer ett fast schema. När dataflödet uppdateras tas endast raderna i tabellen bort och ersätts med utdata från dataflödet. Eventuella relationer eller mått i tabellen förblir intakta. Om du gör några ändringar i frågan i dataflödet misslyckas publiceringen av dataflödet om det upptäcker att frågeschemat inte matchar datamålschemat. Använd den här inställningen när du inte planerar att ändra schemat och låta relationer eller mått läggas till i måltabellen.
Kommentar
När du läser in data i lagret stöds endast ett fast schema.

Typer av datakällor som stöds per mål
| Datatyper som stöds per lagringsplats | DataflowStagingLakehouse | Utdata från Azure DB (SQL) | Utdata från Azure Data Explorer | Utdata från Fabric Lakehouse (LH) | Utdata från infrastrukturlager (WH) | Sql Database-utdata (SQL) för infrastrukturresurser |
|---|---|---|---|---|---|---|
| Åtgärd | Nej | Nej | Nej | Nej | Nej | Nej |
| Alla | Nej | Nej | Nej | Nej | Nej | Nej |
| Binära | Nej | Nej | Nej | Nej | Nej | Nej |
| Valuta | Ja | Ja | Ja | Ja | No | Ja |
| DateTimeZone | Ja | Ja | Ja | Nej | Nej | Ja |
| Tidslängd | Nej | Nej | Ja | Nej | Nej | Nej |
| Funktion | Nej | Nej | Nej | Nej | Nej | Nej |
| Ingen | Nej | Nej | Nej | Nej | Nej | Nej |
| Null | Nej | Nej | Nej | Nej | Nej | Nej |
| Tid | Ja | Ja | Nej | Nej | Nej | Ja |
| Typ | Nej | Nej | Nej | Nej | Nej | Nej |
| Strukturerad (lista, post, tabell) | Nej | Nej | Nej | Nej | Nej | Nej |
Avancerade ämnen
Använda mellanlagring innan du läser in till ett mål
För att förbättra prestandan för frågebearbetning kan mellanlagring användas i Dataflöden Gen2 för att använda Infrastrukturberäkning för att köra dina frågor.
När mellanlagring är aktiverat på dina frågor (standardbeteendet) läses dina data in på mellanlagringsplatsen, vilket är en intern Lakehouse som endast är tillgänglig för själva dataflödena.
Att använda mellanlagringsplatser kan förbättra prestanda i vissa fall där det går snabbare att vika frågan till SQL-analysslutpunkten än i minnesbearbetningen.
När du läser in data i Lakehouse eller andra icke-lagermål inaktiverar vi som standard mellanlagringsfunktionen för att förbättra prestandan. När du läser in data till datamålet skrivs data direkt till datamålet utan mellanlagring. Om du vill använda mellanlagring för din fråga kan du aktivera den igen.
Om du vill aktivera mellanlagring högerklickar du på frågan och aktiverar mellanlagring genom att välja knappen Aktivera mellanlagring . Frågan blir sedan blå.

Läsa in data i informationslagret
När du läser in data i informationslagret krävs mellanlagring innan skrivåtgärden till datamålet. Det här kravet förbättrar prestandan. För närvarande stöds endast inläsning till samma arbetsyta som dataflödet. Se till att mellanlagring är aktiverat för alla frågor som läses in i lagret.
När mellanlagring är inaktiverat och du väljer Lager som utdatamål får du en varning om att aktivera mellanlagring först innan du kan konfigurera datamålet.

Om du redan har ett lager som mål och försöker inaktivera mellanlagring visas en varning. Du kan antingen ta bort lagret som mål eller stänga mellanlagringsåtgärden.

Dammsuger ditt Lakehouse-datamål
När du använder Lakehouse som mål för Dataflow Gen2 i Microsoft Fabric är det viktigt att utföra regelbundet underhåll för att säkerställa optimal prestanda och effektiv lagringshantering. En viktig underhållsuppgift är att dammsuga datamålet. Den här processen hjälper till att ta bort gamla filer som inte längre refereras av Delta-tabellloggen, vilket optimerar lagringskostnaderna och upprätthåller dataintegriteten.
Varför dammsugning är viktigt
- Lagringsoptimering: Med tiden ackumulerar Delta-tabeller gamla filer som inte längre behövs. Dammsugning hjälper till att rensa upp dessa filer, frigöra lagringsutrymme och minska kostnaderna.
- Prestandaförbättring: Om du tar bort onödiga filer kan du förbättra frågeprestandan genom att minska antalet filer som behöver genomsökas under läsåtgärder.
- Dataintegritet: Att se till att endast relevanta filer bevaras bidrar till att upprätthålla integriteten för dina data, vilket förhindrar potentiella problem med ogenomförda filer som kan leda till läsarfel eller skadade tabeller.
Så här dammsuger du datamålet
Följ dessa steg för att dammsuga deltatabellerna i Lakehouse:
- Gå till ditt Lakehouse: Från ditt Microsoft Fabric-konto går du till önskad Lakehouse.
- Underhåll av åtkomsttabell: Högerklicka på den tabell som du vill underhålla i Lakehouse Explorer eller använd ellipsen för att komma åt snabbmenyn.
- Välj underhållsalternativ: Välj menyposten Underhåll och välj alternativet Vakuum .
- Kör vakuumkommandot: Ange kvarhållningströskelvärdet (standardvärdet är sju dagar) och kör vakuumkommandot genom att välja Kör nu.
Bästa praxis
- Kvarhållningsperiod: Ange ett kvarhållningsintervall på minst sju dagar för att säkerställa att gamla ögonblicksbilder och ogenomförda filer inte tas bort i förtid, vilket kan störa samtidiga tabellläsare och skrivare.
- Regelbundet underhåll: Schemalägg regelbunden dammsugning som en del av din rutin för dataunderhåll för att hålla deltatabellerna optimerade och redo för analys.
Genom att införliva dammsugning i din strategi för dataunderhåll kan du se till att ditt Lakehouse-mål förblir effektivt, kostnadseffektivt och tillförlitligt för dina dataflödesåtgärder.
Mer detaljerad information om tabellunderhåll i Lakehouse finns i deltatabellens underhållsdokumentation.
Kan ha värdet null
I vissa fall när du har en nullbar kolumn identifieras den av Power Query som icke-nullbar och när du skriver till datamålet kan kolumntypen inte vara null. Under uppdateringen uppstår följande fel:
E104100 Couldn't refresh entity because of an issue with the mashup document MashupException.Error: DataFormat.Error: Error in replacing table's content with new data in a version: #{0}., InnerException: We can't insert null data into a non-nullable column., Underlying error: We can't insert null data into a non-nullable column. Details: Reason = DataFormat.Error;Message = We can't insert null data into a non-nullable column.; Message.Format = we can't insert null data into a non-nullable column.
Om du vill framtvinga nullbara kolumner kan du prova följande steg:
Ta bort tabellen från datamålet.
Ta bort datamålet från dataflödet.
Gå till dataflödet och uppdatera datatyperna med hjälp av följande Power Query-kod:
Table.TransformColumnTypes( #"PREVIOUS STEP", { {"COLLUMNNAME1", type nullable text}, {"COLLUMNNAME2", type nullable Int64.Type} } )Lägg till datamålet.
Konvertering och uppskalning av datatyper
I vissa fall skiljer sig datatypen i dataflödet från vad som stöds i datamålet nedan är några standardkonverteringar som vi har infört för att säkerställa att du fortfarande kan hämta dina data i datamålet:
| Mål | Dataflödesdatatyp | Måldatatyp |
|---|---|---|
| Infrastrukturlager | Int8.Type | Int16.Type |