Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Ett maskininlärningsexperiment är den primära enheten för organisation och kontroll för alla relaterade maskininlärningskörningar. En körning motsvarar en enstaka exekvering av modellkoden. I MLflow-baseras spårningen på experiment och körningar.
Maskininlärningsexperiment gör det möjligt för dataforskare att logga parametrar, kodversioner, mått och utdatafiler när de kör sin maskininlärningskod. Med experiment kan du också visualisera, söka efter och jämföra körningar, samt ladda ned körningsfiler och metadata för analys i andra verktyg.
I den här artikeln lär du dig mer om hur dataexperter kan interagera med och använda maskininlärningsexperiment för att organisera sin utvecklingsprocess och spåra flera körningar.
Förutsättningar
Skaffa en Microsoft Fabric-prenumeration. Eller registrera dig för en kostnadsfri Microsoft Fabric utvärderingsversion.
Logga in på Microsoft Fabric.
Växla till Fabric med hjälp av upplevelseväxlaren längst ned till vänster på startsidan.

Skapa ett experiment
Du kan skapa ett maskininlärningsexperiment direkt från Fabric användargränssnitt (UI) eller genom att skriva kod som använder MLflow-API:et.
Skapa ett experiment med hjälp av användargränssnittet
Så här skapar du ett maskininlärningsexperiment från användargränssnittet:
Skapa en ny arbetsyta eller välj en befintlig.
Längst upp till vänster på arbetsytan väljer du Nytt objekt. Under Analysera och träna data väljer du Experiment .
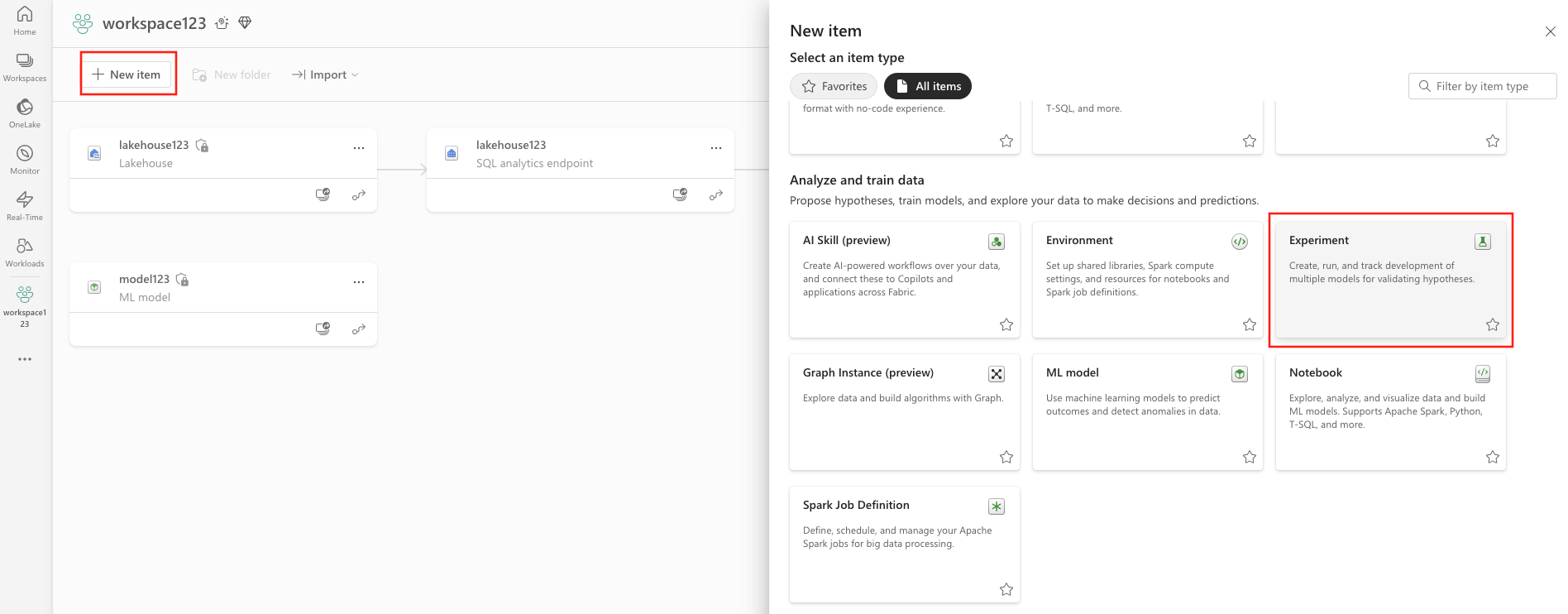 ELLER
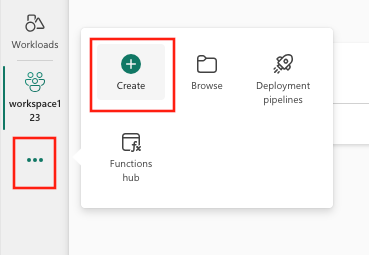
ELLERVälj Skapa, som du hittar i ... från den lodräta menyn.
Under Data science väljer du Experiment.
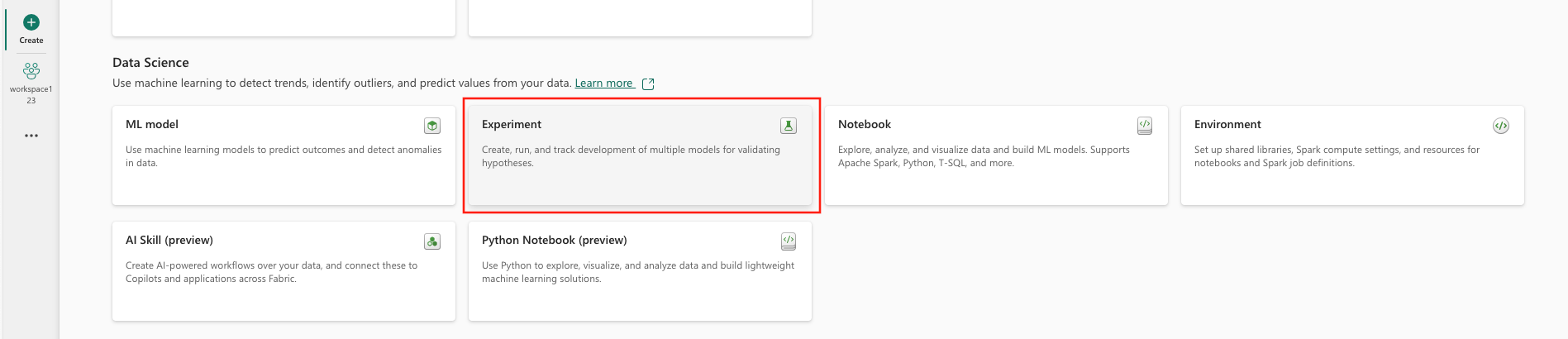
Ange ett experimentnamn och välj Skapa. Den här åtgärden skapar ett tomt experiment på din arbetsyta.



När du har skapat experimentet kan du börja lägga till körningar för att spåra körningsmått och parametrar.
Skapa ett experiment med MLflow-API:et
Du kan också skapa ett maskininlärningsexperiment direkt från redigeringsupplevelsen med hjälp av API:erna mlflow.create_experiment() eller mlflow.set_experiment() . Ersätt med experimentets namn i följande kod <EXPERIMENT_NAME> .
import mlflow
# This will create a new experiment with the provided name.
mlflow.create_experiment("<EXPERIMENT_NAME>")
# This will set the given experiment as the active experiment.
# If an experiment with this name does not exist, a new experiment with this name is created.
mlflow.set_experiment("<EXPERIMENT_NAME>")
Hantera körningar i ett experiment
Ett maskininlärningsexperiment innehåller en samling körningar för förenklad spårning och jämförelse. I ett experiment kan en dataexpert navigera i olika körningar och utforska underliggande parametrar och mått. Dataexperter kan också jämföra körningar i ett maskininlärningsexperiment för att identifiera vilka delmängder av parametrar som ger önskad modellprestanda.
Om du vill visa körningarna för ett experiment väljer du Körningslista från experimentets vy.

I körningslistan kan du navigera till information om en specifik körning genom att välja körningsnamnet.
Spåra körningsinformation
En maskininlärningskörning motsvarar en enda körning av modellkod. Du kan spåra följande information för varje körning:

Varje körning innehåller följande information:
- Källa: Namnet på anteckningsboken som skapade körningen.
- Registrerad version: Anger om körningen sparades som en maskininlärningsmodell.
- Startdatum: Starttid för körningen.
- Status: Körningens förlopp.
- Hyperparametrar: Hyperparametrar sparas som nyckel/värde-par. Både nycklar och värden är strängar.
- Mått: Kör mått som sparats som nyckel/värde-par. Värdet är numeriskt.
- Utdatafiler: Utdatafiler i valfritt format. Du kan till exempel spela in bilder, miljö, modeller och datafiler.
- Taggar: Metadata i form av nyckel-värde-par till utföranden.
Visa körningslistan
Du kan visa alla körningar i ett experiment i Körlistavy. Med den här vyn kan du hålla reda på den senaste aktiviteten, snabbt hoppa till det relaterade Spark-programmet och tillämpa filter baserat på körningsstatusen.
Jämföra och filtrera körningar
Om du vill jämföra och utvärdera kvaliteten på dina maskininlärningskörningar kan du jämföra parametrar, mått och metadata mellan valda körningar i ett experiment.
Applicera taggar på exekveringar
MLflow-taggning för experimentkörningar gör det möjligt för användare att lägga till anpassade metadata i form av nyckel/värde-par i sina körningar. De här taggarna hjälper dig att kategorisera, filtrera och söka efter körningar baserat på specifika attribut, vilket gör det enklare att hantera och analysera experiment inom MLflow-plattformen. Användare kan använda taggar för att märka körningar med information som modelltyper, parametrar eller relevanta identifierare, vilket förbättrar den övergripande organisationen och spårbarheten för experiment.
Det här kodfragmentet startar en MLflow-körning, loggar några parametrar och mått och lägger till taggar för att kategorisera och ge ytterligare kontext för körningen.
import mlflow
import mlflow.sklearn
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
from sklearn.datasets import fetch_california_housing
# Autologging
mlflow.autolog()
# Load the California housing dataset
data = fetch_california_housing(as_frame=True)
X = data.data
y = data.target
# Split the data
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Start an MLflow run
with mlflow.start_run() as run:
# Train the model
model = LinearRegression()
model.fit(X_train, y_train)
# Predict and evaluate
y_pred = model.predict(X_test)
# Add tags
mlflow.set_tag("model_type", "Linear Regression")
mlflow.set_tag("dataset", "California Housing")
mlflow.set_tag("developer", "Bob")
När taggarna har tillämpats kan du visa resultatet direkt från den infogade MLflow-widgeten eller från sidan med körningsinformation.

Varning
Varning: Begränsningar för att tillämpa taggar på MLflow-experimentkörningar i Fabric
- Taggar som inte är tomma: Taggnamn eller värden får inte vara tomma. Om du försöker använda en tagg med ett tomt namn eller värde misslyckas åtgärden.
- Taggnamn: Taggnamn kan vara upp till 250 tecken långa.
- Taggvärden: Taggvärden kan vara upp till 5 000 tecken långa.
-
Begränsade taggnamn: Taggnamn som börjar med vissa prefix stöds inte. Mer specifikt är taggnamn som börjar med
synapseml,mlflowellertridentär begränsade och kommer inte att accepteras.
Jämför körningar visuellt
Du kan visuellt jämföra och filtrera körningar inom ett befintligt experiment. Med visuell jämförelse kan du enkelt navigera mellan flera körningar och sortera mellan dem.

Så här jämför du körningar:
- Välj ett befintligt maskininlärningsexperiment som innehåller flera körningar.
- Välj fliken Visa och gå sedan till vyn Kör lista . Du kan också välja alternativet att visa körlistan direkt från vyn Körningsdetaljer.
- Anpassa kolumnerna i tabellen genom att expandera fönstret Anpassa kolumner . Här kan du välja de egenskaper, mått, taggar och hyperparametrar som du vill se.
- Expandera fönstret Filter för att begränsa dina resultat baserat på vissa valda villkor.
- Välj flera körningar för att jämföra deras resultat i jämförelsefönstret för mått. I det här fönstret kan du anpassa diagrammen genom att ändra diagramrubriken, visualiseringstypen, X-axeln, Y-axeln med mera.
Jämför körningar med MLflow-API:et
Dataforskare kan också använda MLflow för att fråga och söka bland körningar i ett experiment. Du kan utforska fler MLflow-API:er för att söka, filtrera och jämföra körningar genom att gå till MLflow-dokumentationen.
Hämta alla körningar
Du kan använda MLflow-sök-API mlflow.search_runs() för att hämta alla körningar i ett experiment genom att ersätta <EXPERIMENT_NAME> med ditt experimentnamn eller <EXPERIMENT_ID> med ditt experiment-ID i följande kod.
import mlflow
# Get runs by experiment name:
mlflow.search_runs(experiment_names=["<EXPERIMENT_NAME>"])
# Get runs by experiment ID:
mlflow.search_runs(experiment_ids=["<EXPERIMENT_ID>"])
Tips/Råd
Du kan söka i flera experiment genom att ange en lista över experiment-ID:t till parametern experiment_ids . På samma sätt gör en lista över experimentnamn till parametern experiment_names att MLflow kan söka i flera experiment. Detta kan vara användbart om du vill jämföra mellan körningar i olika experiment.
Orderkörningar och begränsningskörningar
Använd parametern max_results från search_runs för att begränsa antalet körningar som returneras. Med order_by parametern kan du lista kolumnerna som ska sorteras efter och kan innehålla ett valfritt DESC värde eller ASC värde. I följande exempel returneras till exempel den senaste körningen av ett experiment.
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], max_results=1, order_by=["start_time DESC"])
Jämför körningar i en Fabric notebook
Du kan använda MLflow-redigeringswidgeten i Fabric notebook-filer för att spåra MLflow-körningar som genereras i varje cell i anteckningsboken. Med widgeten kan du spåra dina körningar, associerade mått, parametrar och egenskaper ända ned till den enskilda cellnivån.
Om du vill få en visuell jämförelse kan du också växla till vyn Kör jämförelse . Den här vyn visar data grafiskt, vilket underlättar snabb identifiering av mönster eller avvikelser mellan olika körningar.

Spara körning som en maskininlärningsmodell
När en körning ger önskat resultat kan du spara körningen som en modell för förbättrad modellspårning och för modelldistribution genom att välja Spara som en ML-modell.

Övervaka ML-experiment (förhandsversion)
ML-experiment integreras direkt i Monitor. Den här funktionen är utformad för att ge mer insikt i dina Spark-program och de ML-experiment som de genererar, vilket gör det enklare att hantera och felsöka dessa processer.
Spåra körningar från övervakningssystemet
Användare kan spåra experimentkörningar direkt från övervakningsverktyget, vilket ger en enhetlig vy över alla deras aktiviteter. Den här integreringen innehåller filtreringsalternativ som gör det möjligt för användare att fokusera på experiment eller körningar som skapats under de senaste 30 dagarna eller andra angivna perioder.

Spåra relaterade ML-experimentkörningar från ditt Spark-program
ML-experimentet integreras direkt i Monitor, där du kan välja ett specifikt Spark-program och komma åt objektögonblicksbilder. Här hittar du en lista över alla experiment och körningar som genereras av programmet.