Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
I den här självstudien lär du dig att träna flera maskininlärningsmodeller att välja den bästa för att förutsäga vilka bankkunder som sannolikt kommer att lämna.
I den här självstudien ska du:
- Träna Random Forest- och LightGBM-modeller.
- Använd Microsoft Fabrics interna integrering med MLflow-ramverket för att logga de tränade maskininlärningsmodellerna, de använda hyperaparametrarna och utvärderingsmåtten.
- Registrera den tränade maskininlärningsmodellen.
- Utvärdera prestanda för de tränade maskininlärningsmodellerna på valideringsdatauppsättningen.
MLflow är en öppen källkod plattform för att hantera livscykeln för maskininlärning med funktioner som Spårning, Modeller och Modellregister. MLflow är inbyggt integrerat med fabric-Datavetenskap-upplevelsen.
Förutsättningar
Skaffa en Microsoft Fabric-prenumeration. Eller registrera dig för en kostnadsfri utvärderingsversion av Microsoft Fabric.
Logga in på Microsoft Fabric.
Växla till Fabric genom att använda upplevelseväxlaren längst ned till vänster på startsidan.

Det här är del 3 av 5 i självstudieserien. Slutför den här självstudien genom att först slutföra:
- Del 1: Mata in data i ett Microsoft Fabric Lakehouse med Apache Spark.
- Del 2: Utforska och visualisera data med hjälp av Microsoft Fabric-notebook-filer för att lära dig mer om data.
Följ med i notebook-filen
3-train-evaluate.ipynb är anteckningsboken som medföljer den här självstudien.
För att öppna den medföljande notebook-filen för den här självstudien följer du anvisningarna i Förbered ditt system för datavetenskapliga självstudier för att importera anteckningsboken till din arbetsyta.
Om du hellre vill kopiera och klistra in koden från den här sidan kan du skapa en ny notebook-fil.
Se till att bifoga ett lakehouse i notebook-filen innan du börjar köra kod.
Viktigt!
Fäst samma sjöhus som du använde i del 1 och del 2.
Installera anpassade bibliotek
För den här notebook-filen installerar du imbalanced-learn (importerad som imblearn) med hjälp av %pip install. Imbalanced-learn är ett bibliotek för Synthetic Minority Oversampling Technique (SMOTE) som används för att hantera obalanserade datamängder. PySpark-kerneln startas om efter %pip install, så du måste installera biblioteket innan du kör andra celler.
Du får åtkomst till SMOTE med hjälp av imblearn biblioteket. Installera den nu med hjälp av in-line-installationsfunktionerna (t.ex. %pip, %conda).
# Install imblearn for SMOTE using pip
%pip install imblearn
%pip install scikit-learn==1.6.1
%pip install "mlflow==2.12.2"
Viktigt!
Kör den här installationen varje gång du startar om anteckningsboken.
När du installerar ett bibliotek i en notebook-fil är det bara tillgängligt under notebook-sessionens varaktighet och inte på arbetsytan. Om du startar om anteckningsboken måste du installera biblioteket igen.
Om du har ett bibliotek som du ofta använder, och du vill göra det tillgängligt för alla notebook-filer på din arbetsyta, kan du använda en Infrastrukturmiljö för det ändamålet. Du kan skapa en miljö, installera biblioteket i den och sedan kan din arbetsyteadministratör koppla miljön till arbetsytan som standardmiljö. Mer information om hur du anger en miljö som standard för arbetsytan finns i Administratörsuppsättningar för standardbibliotek för arbetsytan.
Information om hur du migrerar befintliga arbetsytebibliotek och Spark-egenskaper till en miljö finns i Migrera arbetsytebibliotek och Spark-egenskaper till en standardmiljö.
Läsa in data
Innan du tränar någon maskininlärningsmodell måste du läsa in deltatabellen från lakehouse för att kunna läsa de rensade data som du skapade i föregående notebook-fil.
import pandas as pd
SEED = 12345
df_clean = spark.read.format("delta").load("Tables/df_clean").toPandas()
Generera experiment för att spåra och logga modellen med MLflow
Det här avsnittet visar hur du genererar ett experiment, anger maskininlärningsmodellen och träningsparametrarna samt bedömningsmått, tränar maskininlärningsmodellerna, loggar dem och sparar de tränade modellerna för senare användning.
import mlflow
# Setup experiment name
EXPERIMENT_NAME = "bank-churn-experiment-SBM" # MLflow experiment name
Genom att utöka MLflow-autologgningsfunktionerna fungerar automatisk loggning genom att automatiskt samla in värdena för indataparametrar och utdatamått för en maskininlärningsmodell när den tränas. Den här informationen loggas sedan till din arbetsyta, där den kan nås och visualiseras med hjälp av MLflow-API:erna eller motsvarande experiment på din arbetsyta.
Alla experiment med deras respektive namn loggas och du kommer att kunna spåra deras parametrar och prestandamått. Mer information om automatisk loggning finns i Autologgning i Microsoft Fabric.
Ange specifikationer för experiment och automatisk loggning
mlflow.set_experiment(EXPERIMENT_NAME)
mlflow.autolog(exclusive=False)
Importera scikit-learn och LightGBM
Med dina data på plats kan du nu definiera maskininlärningsmodellerna. Du använder Random Forest- och LightGBM-modeller i den här notebook-filen. Använd scikit-learn och lightgbm för att implementera modellerna inom några rader kod.
# Import the required libraries for model training
from sklearn.model_selection import train_test_split
from lightgbm import LGBMClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, f1_score, precision_score, confusion_matrix, recall_score, roc_auc_score, classification_report
Förbereda datauppsättningar för träning, validering och testning
train_test_split Använd funktionen från scikit-learn för att dela upp data i tränings-, validerings- och testuppsättningar.
y = df_clean["Exited"]
X = df_clean.drop("Exited",axis=1)
# Split the dataset to 60%, 20%, 20% for training, validation, and test datasets
# Train-Test Separation
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=SEED)
# Train-Validation Separation
X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=0.25, random_state=SEED)
Spara testdata i en deltatabell
Spara testdata i deltatabellen för användning i nästa notebook-fil.
table_name = "df_test"
# Create PySpark DataFrame from Pandas
df_test=spark.createDataFrame(X_test)
df_test.write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark test DataFrame saved to delta table: {table_name}")
Tillämpa SMOTE på träningsdata för att syntetisera nya exempel för minoritetsklassen
Datautforskningen i del 2 visade att av de 10 000 datapunkter som motsvarar 10 000 kunder har endast 2 037 kunder (cirka 20 %) lämnat banken. Detta indikerar att datamängden är mycket obalanserad. Problemet med obalanserad klassificering är att det finns för få exempel på minoritetsklassen för att en modell effektivt ska kunna lära sig beslutsgränsen. SMOTE är den mest använda metoden för att syntetisera nya exempel för minoritetsklassen. Läs mer om SMOTE här och här.
Dricks
Observera att SMOTE endast ska tillämpas på träningsdatauppsättningen. Du måste lämna testdatamängden i den ursprungliga obalanserade fördelningen för att få en giltig uppskattning av hur maskininlärningsmodellen ska fungera på de ursprungliga data som representerar situationen i produktionen.
from collections import Counter
from imblearn.over_sampling import SMOTE
sm = SMOTE(random_state=SEED)
X_res, y_res = sm.fit_resample(X_train, y_train)
new_train = pd.concat([X_res, y_res], axis=1)
Dricks
Du kan ignorera MLflow-varningsmeddelandet som visas när du kör den här cellen.
Om du ser ett ModuleNotFoundError-meddelande missade du att köra den första cellen i den här notebook-filen, som installerar imblearn biblioteket. Du måste installera det här biblioteket varje gång du startar om anteckningsboken. Gå tillbaka och kör om alla celler från och med den första cellen i den här notebook-filen.
Modellträning
- Träna modellen med slumpmässig skog med maximalt djup på 4 och 4 funktioner
mlflow.sklearn.autolog(registered_model_name='rfc1_sm') # Register the trained model with autologging
rfc1_sm = RandomForestClassifier(max_depth=4, max_features=4, min_samples_split=3, random_state=1) # Pass hyperparameters
with mlflow.start_run(run_name="rfc1_sm") as run:
rfc1_sm_run_id = run.info.run_id # Capture run_id for model prediction later
print("run_id: {}; status: {}".format(rfc1_sm_run_id, run.info.status))
# rfc1.fit(X_train,y_train) # Imbalanaced training data
rfc1_sm.fit(X_res, y_res.ravel()) # Balanced training data
rfc1_sm.score(X_val, y_val)
y_pred = rfc1_sm.predict(X_val)
cr_rfc1_sm = classification_report(y_val, y_pred)
cm_rfc1_sm = confusion_matrix(y_val, y_pred)
roc_auc_rfc1_sm = roc_auc_score(y_res, rfc1_sm.predict_proba(X_res)[:, 1])
- Träna modellen med slumpmässig skog med maximalt djup på 8 och 6 funktioner
mlflow.sklearn.autolog(registered_model_name='rfc2_sm') # Register the trained model with autologging
rfc2_sm = RandomForestClassifier(max_depth=8, max_features=6, min_samples_split=3, random_state=1) # Pass hyperparameters
with mlflow.start_run(run_name="rfc2_sm") as run:
rfc2_sm_run_id = run.info.run_id # Capture run_id for model prediction later
print("run_id: {}; status: {}".format(rfc2_sm_run_id, run.info.status))
# rfc2.fit(X_train,y_train) # Imbalanced training data
rfc2_sm.fit(X_res, y_res.ravel()) # Balanced training data
rfc2_sm.score(X_val, y_val)
y_pred = rfc2_sm.predict(X_val)
cr_rfc2_sm = classification_report(y_val, y_pred)
cm_rfc2_sm = confusion_matrix(y_val, y_pred)
roc_auc_rfc2_sm = roc_auc_score(y_res, rfc2_sm.predict_proba(X_res)[:, 1])
- Träna modellen med Hjälp av LightGBM
# lgbm_model
mlflow.lightgbm.autolog(registered_model_name='lgbm_sm') # Register the trained model with autologging
lgbm_sm_model = LGBMClassifier(learning_rate = 0.07,
max_delta_step = 2,
n_estimators = 100,
max_depth = 10,
eval_metric = "logloss",
objective='binary',
random_state=42)
with mlflow.start_run(run_name="lgbm_sm") as run:
lgbm1_sm_run_id = run.info.run_id # Capture run_id for model prediction later
# lgbm_sm_model.fit(X_train,y_train) # Imbalanced training data
lgbm_sm_model.fit(X_res, y_res.ravel()) # Balanced training data
y_pred = lgbm_sm_model.predict(X_val)
accuracy = accuracy_score(y_val, y_pred)
cr_lgbm_sm = classification_report(y_val, y_pred)
cm_lgbm_sm = confusion_matrix(y_val, y_pred)
roc_auc_lgbm_sm = roc_auc_score(y_res, lgbm_sm_model.predict_proba(X_res)[:, 1])
Experimentartefakt för att spåra modellprestanda
Experimentkörningarna sparas automatiskt i experimentartefakten som kan hittas från arbetsytan. De namnges baserat på det namn som används för att ange experimentet. Alla tränade maskininlärningsmodeller, deras körningar, prestandamått och modellparametrar loggas.
Så här visar du dina experiment:
Välj din arbetsyta i den vänstra panelen.
Längst upp till höger filtrerar du för att endast visa experiment, så att det blir enklare att hitta experimentet du letar efter.
Leta upp och välj experimentnamnet, i det här fallet bank-churn-experiment. Om du inte ser experimentet på din arbetsyta uppdaterar du webbläsaren.
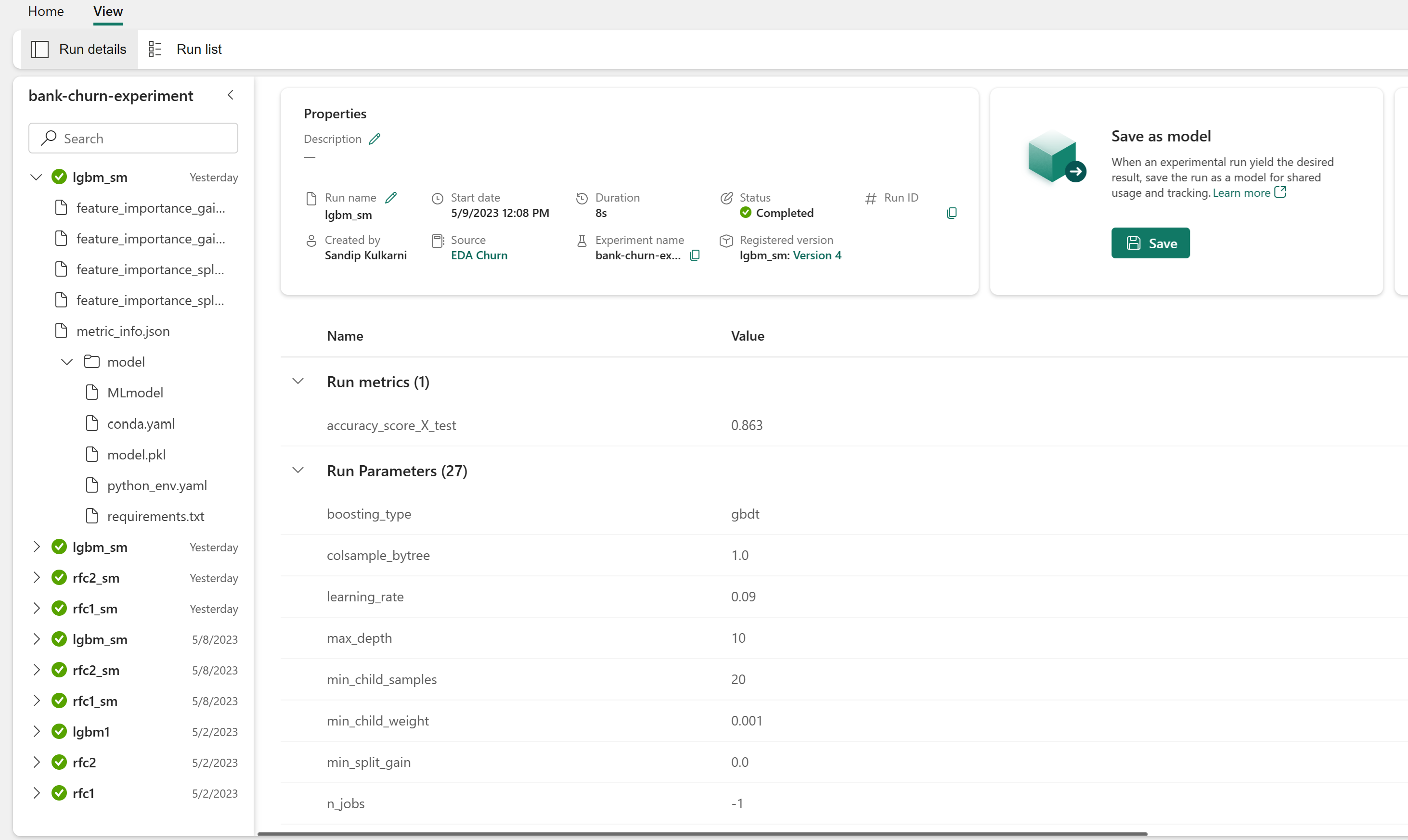


Utvärdera prestanda för de tränade modellerna på valideringsdatauppsättningen
När du är klar med maskininlärningsmodellträning kan du utvärdera prestanda för tränade modeller på två sätt.
Öppna det sparade experimentet från arbetsytan, läs in maskininlärningsmodellerna och utvärdera sedan prestanda för de inlästa modellerna på valideringsdatauppsättningen.
# Define run_uri to fetch the model # mlflow client: mlflow.model.url, list model load_model_rfc1_sm = mlflow.sklearn.load_model(f"runs:/{rfc1_sm_run_id}/model") load_model_rfc2_sm = mlflow.sklearn.load_model(f"runs:/{rfc2_sm_run_id}/model") load_model_lgbm1_sm = mlflow.lightgbm.load_model(f"runs:/{lgbm1_sm_run_id}/model") # Assess the performance of the loaded model on validation dataset ypred_rfc1_sm_v1 = load_model_rfc1_sm.predict(X_val) # Random Forest with max depth of 4 and 4 features ypred_rfc2_sm_v1 = load_model_rfc2_sm.predict(X_val) # Random Forest with max depth of 8 and 6 features ypred_lgbm1_sm_v1 = load_model_lgbm1_sm.predict(X_val) # LightGBMUtvärdera prestandan för de tränade maskininlärningsmodellerna direkt på valideringsdatauppsättningen.
ypred_rfc1_sm_v2 = rfc1_sm.predict(X_val) # Random Forest with max depth of 4 and 4 features ypred_rfc2_sm_v2 = rfc2_sm.predict(X_val) # Random Forest with max depth of 8 and 6 features ypred_lgbm1_sm_v2 = lgbm_sm_model.predict(X_val) # LightGBM
Beroende på vad du föredrar är endera metoden bra och bör erbjuda identiska föreställningar. I den här notebook-filen väljer du den första metoden för att bättre demonstrera funktionerna för automatisk MLflow-loggning i Microsoft Fabric.
Visa sanna/falska positiva/negativa värden med hjälp av förvirringsmatrisen
Därefter ska du utveckla ett skript för att rita förvirringsmatrisen för att utvärdera klassificeringens noggrannhet med hjälp av valideringsdatauppsättningen. Förvirringsmatrisen kan också ritas med hjälp av SynapseML-verktyg, som visas i exempel på bedrägeriidentifiering som är tillgängligt här.
import seaborn as sns
sns.set_theme(style="whitegrid", palette="tab10", rc = {'figure.figsize':(9,6)})
import matplotlib.pyplot as plt
import matplotlib.ticker as mticker
from matplotlib import rc, rcParams
import numpy as np
import itertools
def plot_confusion_matrix(cm, classes,
normalize=False,
title='Confusion matrix',
cmap=plt.cm.Blues):
print(cm)
plt.figure(figsize=(4,4))
plt.rcParams.update({'font.size': 10})
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45, color="blue")
plt.yticks(tick_marks, classes, color="blue")
fmt = '.2f' if normalize else 'd'
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, format(cm[i, j], fmt),
horizontalalignment="center",
color="red" if cm[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
- Förvirringsmatris för slumpmässig skogsklassificerare med maximalt djup på 4 och 4 funktioner
cfm = confusion_matrix(y_val, y_pred=ypred_rfc1_sm_v1)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='Random Forest with max depth of 4')
tn, fp, fn, tp = cfm.ravel()
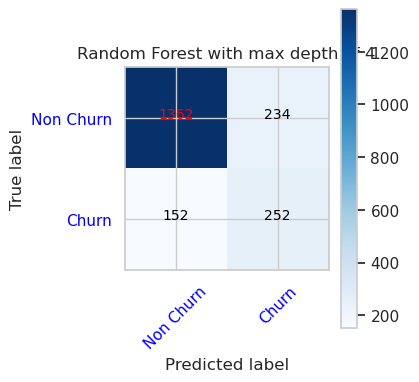
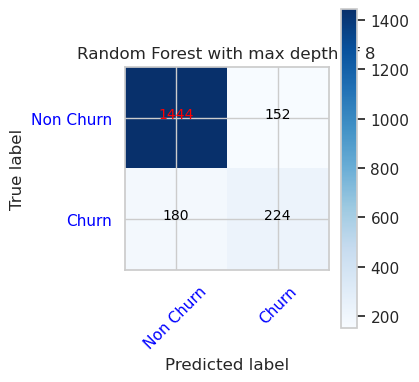
- Förvirringsmatris för slumpmässig skogsklassificerare med maximalt djup på 8 och 6 funktioner
cfm = confusion_matrix(y_val, y_pred=ypred_rfc2_sm_v1)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='Random Forest with max depth of 8')
tn, fp, fn, tp = cfm.ravel()
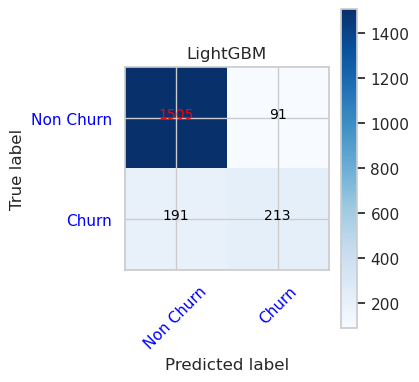
- Förvirringsmatris för LightGBM
cfm = confusion_matrix(y_val, y_pred=ypred_lgbm1_sm_v1)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='LightGBM')
tn, fp, fn, tp = cfm.ravel()