Not
Åtkomst till denna sida kräver auktorisation. Du kan prova att logga in eller byta katalog.
Åtkomst till denna sida kräver auktorisation. Du kan prova att byta katalog.
gäller för:✅ Warehouse i Microsoft Fabric
Den här artikeln beskriver de funktioner och innovationer i Fabric Data Warehouses arkitektur som driver dess prestanda, skalbarhet och kostnadseffektivitet.
Fabric Data Warehouse körs på en framtidsklar arkitektur i en konvergerad dataplattform. Med ett öppet Delta-lagringsformat och OneLake-integrering är dina data i Fabric Data Warehouse redo för analys.
Arkitektur på hög nivå

Fabric Data Warehouse är specialbyggt för analys i stor skala med följande byggstenar:
| Byggsten | Beskrivning |
|---|---|
| Samlad frågeoptimerare | Genererar en optimal körningsplan för distribuerade molnmiljöer, oavsett kvaliteten på användarskapade SQL-frågor. |
| Bearbetning av distribuerade frågor | Stöder massiv parallell frågekörning med snabb automatisk skalning av molninfrastrukturen, vilket omedelbart ger nödvändiga beräkningsresurser för frågor. Separata SELECT- och DML-belastningar använder distinkta pooler för effektiv och isolerad körning. |
| Frågekörningsmotor | En SQL-baserad motor för att köra analysfrågor på stora mängder data med snabb prestanda och hög samtidighet. |
| Metadata och transaktionshantering | Metadata finns i klientdelen, serverdelen och i både den lokala SSD-cachen och den fjärranslutna OneLake-lagringen. Stöder samtidiga transaktioner och säkerställer ACID-efterlevnad. |
| Lagring i OneLake | Log Structured Tables implementeras med det öppna Delta-tabellformatet, en lakehouse-modell med säker öppen lagring. |
| Infrastrukturplattform | Infrastrukturplattformen tillhandahåller en enhetlig autentiserings- och säkerhetsmodell, övervakning och granskning. Ditt Infrastrukturdatalager är automatiskt tillgängligt för andra Infrastrukturplattformstjänster för att uppfylla affärsbehov, inklusive Power BI, datapipelines i Data Factory, Real-Time Intelligence med mera. |
Motor för enhetlig frågeoptimerare
Unified Query Optimizer i Fabric Data Warehouse är den motor som bestämmer det smartaste sättet att köra dina SQL-frågor.
När du skickar en fråga tittar den enhetliga frågeoptimeraren på möjliga sätt att köra den: hur du ansluter tabeller, var data ska flyttas och hur du använder resurser som PROCESSOR, minne och nätverk. Den enhetliga frågeoptimeraren väljer inte bara det första alternativet, utan väljer den mest optimala planen inom den tid som tillåts genom att utvärdera kostnader för dessa faktorer och tillgängliga metadata och statistik.
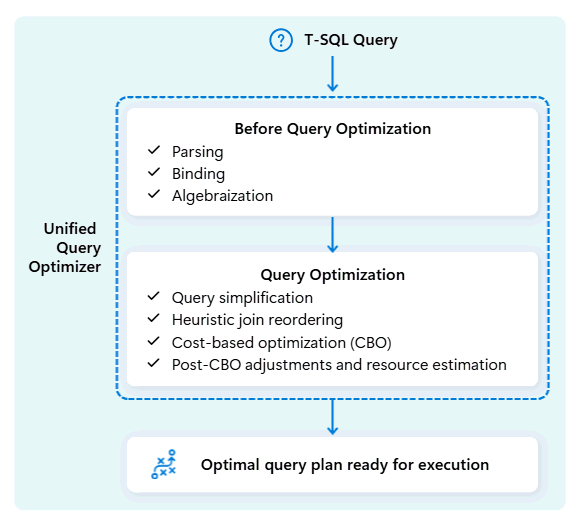
När du optimerar en frågas körningsplan tar den enhetliga frågeoptimeraren hänsyn till allt på en och samma sätt: frågans form, datadistributionen av tabellerna och kostnaden för att flytta data jämfört med bearbetning lokalt. Den enhetliga frågeoptimeraren kan göra smarta kompromisser, såsom att avgöra om sändning av en liten tabell är billigare än att omfördela en stor. Det innebär färre onödiga datablandningar, bättre användning av beräkning och snabbare prestanda, även för komplexa eller dåligt skrivna T-SQL-frågor.
Konsekventa prestanda kräver inte att utvecklare lägger tid på manuell T-SQL-frågejustering. Du behöver till exempel inte manuellt bestämma den bästa JOIN ordningen i frågor. Om din SQL listar den stora tabellen först och en mindre, mycket selektiv datatabell sekund, kan optimeraren automatiskt växla sina positioner för bättre prestanda. Den använder den mindre tabellen som startpunkt för matchande rader ("build"-sidan) och den större tabellen som den som ska sökas igenom (avsökningssidan, kontrollerad efter matchningar). Den här metoden minimerar minnesanvändningen, minskar dataförflyttningen och förbättrar parallelliteten, samtidigt som den ger korrekta resultat.
Den enhetliga frågeoptimeraren lär sig kontinuerligt från tidigare frågekörningar när arbetsbelastningar utvecklas och förfinar optimeringsalgoritmen för att ge bästa möjliga prestanda. Användarna drar nytta av snabb frågekörning automatiskt, oavsett komplexitet och utan att behöva ingripa.
Distribuerad frågebearbetningsmotor
I Fabric Data Warehouse allokerar den distribuerade frågebearbetningsmotorn beräkningsresurser till uppgifter i frågeplaner. Den distribuerade frågebearbetningsmotorn kan schemalägga uppgifter mellan beräkningsnoder så att varje nod kör en del av en frågeplan, vilket möjliggör parallell körning för snabbare prestanda. Komplexa rapporter om stora datamängder kan dra nytta av distribuerad frågebearbetning.
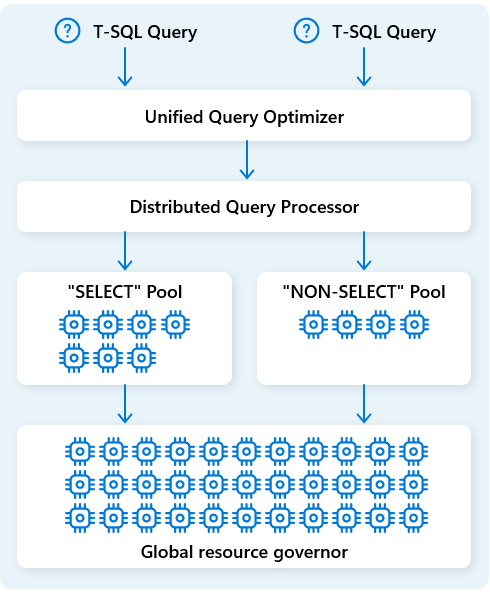
För att ytterligare optimera resurser separerar den distribuerade frågebearbetningsmotorn beräkningsresurser i två pooler: för SELECT frågor och för datainmatningsuppgifter (NON-SELECT frågor). Varje arbetsbelastning tar emot dedikerade resurser efter behov. Det innebär till exempel att dina nattliga ETL-jobb inte fördröjer morgondashboards.
Med snabb nodetablering i molnet skalar den distribuerade frågebearbetningsmotorn automatiskt upp eller ned beräkningsresurser som svar på ändringar i frågevolym, datastorlek och frågekomplexitet. Fabric Data Warehouse har funktioner för parallell bearbetning för små datamängder eller data i skalan för flera petabyte.
Frågekörningsmotor
Frågekörningsmotorn är en process som kör delar av den distribuerade körningsplanen som har tilldelats till de enskilda beräkningsnoderna. Frågekörningsmotorn baseras på samma motor som används av SQL Server och Azure SQL Database för att använda körning av batchläge och kolumndataformat för effektiv analys av stordata till en optimal kostnad.
Frågekörningsmotorn läser data direkt från Delta Parquet-filer som lagras i Fabric OneLake och utnyttjar flera cachelagringslager (minne och SSD) för att påskynda frågeprestanda och säkerställa att frågor körs med optimal hastighet. Frågekörningsmotorn bearbetar data i minnet och hämtar vid behov ytterligare data från SSD-cachen eller OneLake-lagringen.
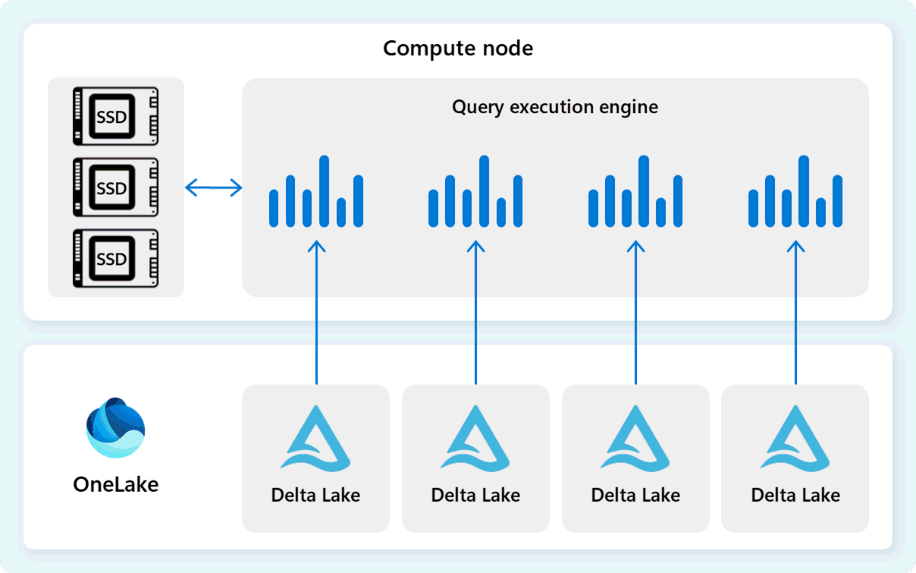
När den bearbetar data utför frågekörningsmotorn kolumn- och radgruppseliminering för att hoppa över segment som inte är relevanta för frågan. Den här optimeringen minskar mängden data som genomsöks från filer och minnescachen, vilket hjälper till att minimera resursanvändningen och förbättra den totala körningstiden.
Frågekörningsmotorn utmärker sig när det gäller att filtrera och aggregera miljarder rader, vilket stöder de generiska dataanalysmönster som används i moderna informationslagerlösningar. Körningen av batchläge drar nytta av modern cpu-förmåga att bearbeta flera rader parallellt, vilket avsevärt minskar kostnaderna och gör att frågor körs upp till hundratals gånger snabbare jämfört med traditionell körning rad för rad.
Metadata och transaktionshantering
Lagermotorn använder metadata för att beskriva tabellschema, filorganisation, versionshistorik och transaktionstillstånd. Med dessa metadata kan lagermotorn effektivt hantera och fråga efter data. Fabric Data Warehouse erbjuder en robust och omfattande arkitektur för metadata- och transaktionshantering, vilket utökar en OLTP-transaktionshanterare för att samordna mycket samtidiga metadataåtgärder och säkerställa ACID-efterlevnad.
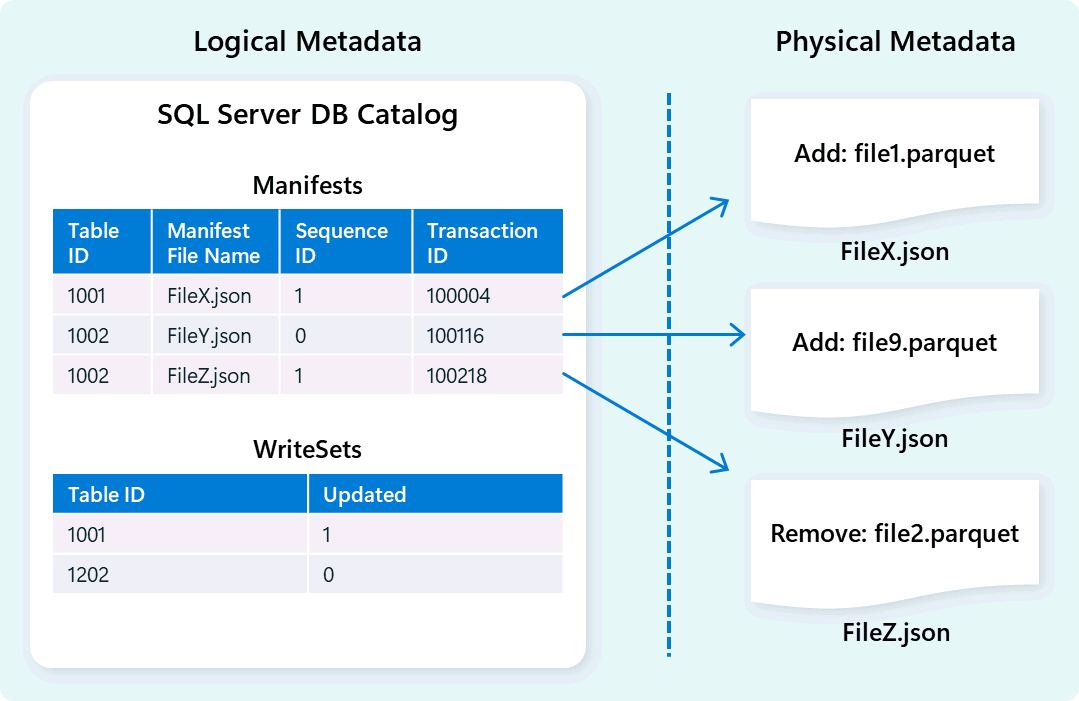
Den här designen möjliggör snabb och tillförlitlig navigering av transaktionstillstånd och stödjer arbetsbelastningar med hög samtidighet samtidigt som konsekvens säkerställs.
Lagring och datainmatning
Fabric Data Warehouse använder en lakehouse-arkitektur med deltaformatet med öppen källkod för skalbar, säker lagring med höga prestanda. Delta-tabellformatet stöder dataversionshantering, vilket ger omedelbar åtkomst till historiska ögonblicksbilder via tidsresa och nollkopieringskloning för säker testning och återställning. Användardata lagras i OneLake, vilket gör att alla Fabric-motorer effektivt kan komma åt delade data utan redundans.
Med utgångspunkt i den här grunden är Fabric Data Warehouse utformat för att leverera optimala datainmatningsprestanda med fokus på enkelhet och flexibilitet. Motorn hanterar effektivt tabelldatalagring genom automatisk datakomprimering, vilket konsoliderar fragmenterade filer i bakgrunden för att minska onödig datagenomsökning. Dess intelligenta datadistributionsmetod delar upp och organiserar data i mikropartitionerade celler för att öka parallell bearbetning och förbättra frågeresultat. Dessa funktioner fungerar autonomt, utan att behöva göra manuella justeringar.