Not
Åtkomst till denna sida kräver auktorisation. Du kan prova att logga in eller byta katalog.
Åtkomst till denna sida kräver auktorisation. Du kan prova att byta katalog.
Gäller för:✅ SQL-analysslutpunkt och lager i Microsoft Fabric
Att hämta data från datasjön är en viktig indata-/utdataåtgärd (I/O) med betydande konsekvenser för frågeprestanda. Fabric Data Warehouse använder förfinade åtkomstmönster för att förbättra dataläsningar från lagring och höja frågekörningshastigheten. Dessutom minimerar det på ett intelligent sätt behovet av fjärrlagringsläsningar genom att utnyttja lokala cacheminnen.
Cachelagring är en teknik som förbättrar prestandan för databehandlingsprogram genom att minska I/O-åtgärderna. Cachelagring lagrar data och metadata som används ofta i ett snabbare lagringslager, till exempel lokalt minne eller lokal SSD-disk, så att efterföljande begäranden kan hanteras snabbare, direkt från cachen. Om en viss uppsättning data tidigare har använts av en fråga hämtar efterföljande frågor dessa data direkt från minnesintern cache. Den här metoden minskar I/O-svarstiden avsevärt, eftersom lokala minnesåtgärder är betydligt snabbare jämfört med att hämta data från fjärrlagring.
Minnesintern cachelagring och diskcachelagring i Fabric Data Warehouse är helt transparent för användaren. Oavsett ursprung, om det är en lagertabell, en OneLake-genväg eller till och med en OneLake-genväg som refererar till icke-Azure-tjänster, cachelagrar frågan alla data som den kommer åt.
Det finns två typer av cacheminnen som beskrivs senare i den här artikeln, minnesintern cache och diskcache. Cachelagring av resultatuppsättningar beskrivs i en annan artikel.
Minnesintern cache
När frågan kommer åt och hämtar data från lagringen utför den en transformeringsprocess som kodar data från det ursprungliga filbaserade formatet till mycket optimerade strukturer i minnesintern cache.

Data i cachen ordnas i ett komprimerat kolumnformat som är optimerat för analysfrågor. Varje kolumn med data lagras tillsammans, separat från de andra, vilket möjliggör bättre komprimering eftersom liknande datavärden lagras tillsammans, vilket leder till minskat minnesfotavtryck. När frågor behöver utföra åtgärder på en specifik kolumn, till exempel aggregeringar eller filtrering, kan motorn fungera effektivare eftersom den inte behöver bearbeta onödiga data från andra kolumner.
Dessutom bidrar den här kolumnlagringen också till parallell bearbetning, vilket avsevärt kan påskynda frågekörningen för stora datamängder. Motorn kan utföra åtgärder på flera kolumner samtidigt och dra nytta av moderna processorer med flera kärnor.
Den här metoden är särskilt fördelaktig för analytiska arbetsbelastningar där frågor omfattar genomsökning av stora mängder data för att utföra aggregeringar, filtrering och andra datamanipuleringar.
Diskcache
Vissa datauppsättningar är för stora för att rymmas i ett minnesinternt cacheminne. För att upprätthålla snabba frågeprestanda för dessa datauppsättningar använder Warehouse diskutrymme som ett kompletterande tillägg till minnesintern cache. All information som läses in i minnesintern cache serialiseras också till SSD-cachen.
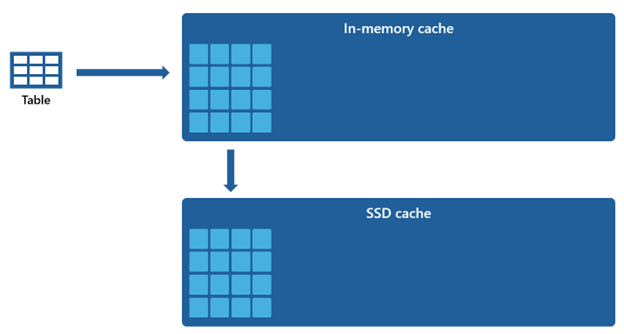
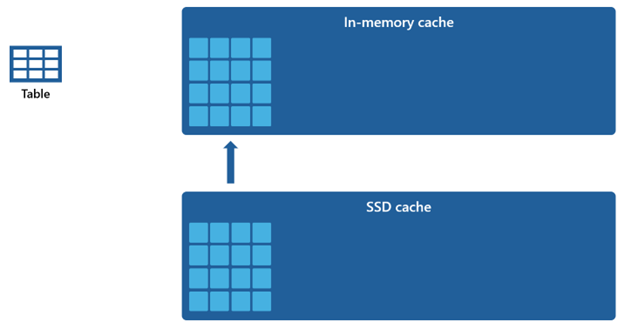
Med tanke på att minnesintern cache har en mindre kapacitet jämfört med SSD-cachen förblir data som tas bort från minnesintern cache kvar i SSD-cachen under en längre period. När efterföljande frågor begär dessa data hämtas de från SSD-cachen till minnesintern cache betydligt snabbare än om de hämtas från fjärrlagring, vilket i slutändan ger dig mer konsekventa frågeprestanda.
Cachehantering
Cachelagring förblir konsekvent aktiv och fungerar sömlöst i bakgrunden, vilket inte kräver några åtgärder från din sida. Det krävs inte att cachelagring inaktiveras, eftersom det oundvikligen skulle leda till en märkbar försämring av frågeprestanda.
Cachelagringsmekanismen samordnas och upprätthålls av själva Microsoft Fabric, och den ger inte användarna möjlighet att rensa cachen manuellt.
Fullständig transaktionskonsekvens i cacheminnet säkerställer att alla ändringar av data i lagringen, till exempel genom DML-åtgärder (Data Manipulation Language), efter att de ursprungligen har lästs in i minnesintern cache, resulterar i konsekventa data.
När cachen når sitt kapacitetströskelvärde och nya data läss för första gången tas objekt som har varit oanvända under den längsta varaktigheten bort från cacheminnet. Den här processen utförs för att skapa utrymme för tillströmningen av nya data och upprätthålla en optimal strategi för cacheanvändning.