Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Spegling i Fabric är ett enkelt sätt att undvika komplexa ETL-processer (extrahera, transformera, läsa in) och sömlöst integrera dina befintliga Google BigQuery-informationslagerdata med resten av dina data i Fabric. Du kan kontinuerligt replikera dina Google BigQuery-data direkt till Fabrics OneLake. Väl i Fabric kan du dra nytta av kraftfulla funktioner för business intelligence, AI, datateknik, datavetenskap och datadelning.
För en handledning om hur du konfigurerar Google BigQuery-databasen för spegling i Fabric, se Tutorial: Konfigurera Microsoft Fabric speglade databaser från Google BigQuery.
Viktigt!
Spegling för Google BigQuery är nu i förhandsversion. Produktionsarbetsbelastningar stöds inte under förhandsversionen.
Varför använda spegling i Fabric?
Spegling i Microsoft Fabric tar bort komplexiteten i att sammanfoga verktyg från olika leverantörer. Du behöver inte migrera dina data. Anslut till dina Google BigQuery-data i princip i realtid för att använda Fabrics uppsättning analysverktyg. Fabric fungerar också sömlöst med Microsoft-produkter, Google BigQuery och ett brett utbud av tekniker som stöder Delta Lake-tabellformatet med öppen källkod.
Vilka analysupplevelser är inbyggda?
Spegling skapar två objekt i din arbetsyta för Fabric.
- Det speglade databasobjektet. Spegling hanterar replikering av data till OneLake och konvertering till Parquet i ett analysklart format. Spegling möjliggör nedströmsscenarier som datateknik, datavetenskap med mera. Speglade databaser skiljer sig från lager- och SQL-analysslutpunktsobjekt.
- En SQL-analysslutpunkt
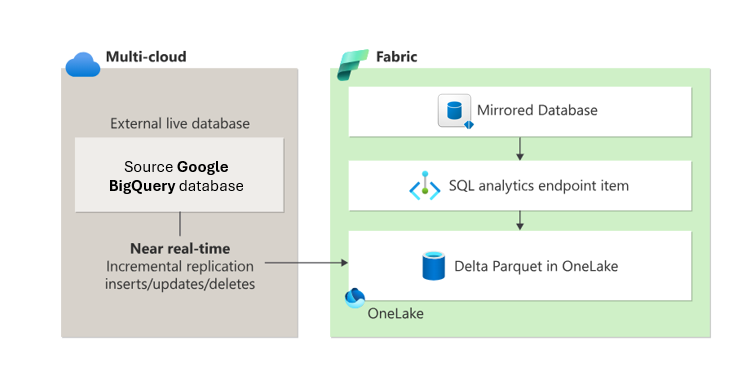
Från varje speglad databas ger en SQL-analysslutpunkt en skrivskyddad analysupplevelse ovanpå deltatabellerna som skapas under speglingen. Den här slutpunkten stöder T-SQL-syntax för att definiera och köra frågor mot dataobjekt, men den tillåter inte direkta dataändringar eftersom data är skrivskyddade.
Med SQL Analytics-slutpunkten kan du:
- Bläddra bland tabeller som refererar till dina Delta Lake-data som speglas från BigQuery.
- Skapa frågor och vyer utan kod och utforska data visuellt – ingen SQL krävs.
- Skapa SQL-vyer, infogade tabellvärdesfunktioner (TVF:er) och lagrade procedurer för att lägga till affärslogiklager med T-SQL.
- Ange och hantera behörigheter för objekt.
- Fråga efter data i andra lager och lakehouses på samma arbetsyta.
Förutom frågeredigeraren SQL, Det finns ett brett ekosystem med verktyg som kan köra frågor mot SQL-analysslutpunkten, inklusive SQL Server Management Studio (SSMS), MSSQL-tillägget för Visual Studio Code och till och med GitHub Copilot.
Säkerhetsfrågor
Det finns specifika användarbehörighetskrav för att aktivera Fabric Mirroring.
Fabric tillhandahåller även dataskyddsfunktioner för att hantera åtkomst inom Microsoft Fabric. Mer information finns i dokumentationen om dataskyddsfunktioner.
Överväganden för speglade BigQuery-kostnader
Fabric-beräkningen som används för att replikera dina data till Fabric OneLake är kostnadsfri. Kostnaden för speglingslagring är kostnadsfri upp till en gräns baserat på kapacitet. Beräkningen för att köra frågor mot data med SQL, Power BI eller Spark debiteras med jämna mellanrum.
Fabric debiterar inte för nätverksdataavgifter vid inkommande trafik till OneLake för mirroring.
Det finns kostnader för Google BigQuery-beräkning och molnfrågekostnader när data speglas: BigQuery Change Data Capture (CDC) använder BigQuery-beräkning för radändringar, Storage Write API för datainmatning, och BigQuery-lagring för datalagring, vilket alla medför kostnader.
Mer information om kostnader för spegling av Google BigQuery finns i prissättningen som förklaras.