Anteckning
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Det här scenariot visar hur du ansluter till OneLake via Azure Databricks. När du har slutfört den här självstudien kan du läsa och skriva till en Microsoft Fabric lakehouse från din Azure Databricks-arbetsyta.
Förutsättningar
Innan du ansluter måste du ha:
- En infrastrukturarbetsyta och ett sjöhus.
- En Premium Azure Databricks-arbetsyta. Endast Premium Azure Databricks-arbetsytor stöder genomströmning av Microsoft Entra-autentiseringsuppgifter, vilket du behöver för det här scenariot.
Konfigurera databricks-arbetsytan
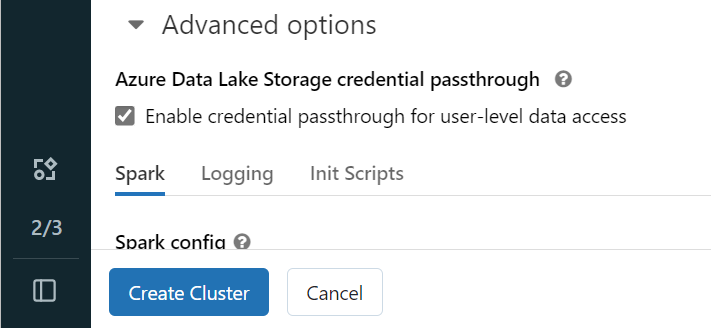
Öppna din Azure Databricks-arbetsyta och välj Skapa>kluster.
Om du vill autentisera till OneLake med din Microsoft Entra-identitet måste du aktivera autentiseringsgenomströmning för Azure Data Lake Storage (ADLS) i klustret i Avancerade alternativ.
Kommentar
Du kan också ansluta Databricks till OneLake med hjälp av tjänstens huvudnamn. Mer information om hur du autentiserar Azure Databricks med ett huvudnamn för tjänsten finns i Hantera tjänstens huvudnamn.
Skapa klustret med önskade parametrar. Mer information om hur du skapar ett Databricks-kluster finns i Konfigurera kluster – Azure Databricks.
Öppna en notebook-fil och anslut den till det nyligen skapade klustret.
Skapa anteckningsboken
Gå till fabric lakehouse och kopiera sökvägen Azure Blob Filesystem (ABFS) till ditt lakehouse. Du hittar den i fönstret Egenskaper .
Kommentar
Azure Databricks stöder endast ABFS-drivrutinen (Azure Blob Filesystem) när du läser och skriver till ADLS Gen2 och OneLake:
abfss://myWorkspace@onelake.dfs.fabric.microsoft.com/.Spara sökvägen till ditt lakehouse i din Databricks-anteckningsbok. I det här lakehouse-huset skriver du dina bearbetade data senare:
oneLakePath = 'abfss://myWorkspace@onelake.dfs.fabric.microsoft.com/myLakehouse.lakehouse/Files/'Läs in data från en offentlig Databricks-datauppsättning till en dataram. Du kan också läsa en fil någon annanstans i Infrastrukturresurser eller välja en fil från ett annat ADLS Gen2-konto som du redan äger.
yellowTaxiDF = spark.read.format("csv").option("header", "true").option("inferSchema", "true").load("/databricks-datasets/nyctaxi/tripdata/yellow/yellow_tripdata_2019-12.csv.gz")Filtrera, transformera eller förbereda dina data. I det här scenariot kan du trimma datamängden för snabbare inläsning, ansluta till andra datauppsättningar eller filtrera ned till specifika resultat.
filteredTaxiDF = yellowTaxiDF.where(yellowTaxiDF.fare_amount<4).where(yellowTaxiDF.passenger_count==4) display(filteredTaxiDF)Skriv din filtrerade dataram till fabric lakehouse med hjälp av din OneLake-sökväg.
filteredTaxiDF.write.format("csv").option("header", "true").mode("overwrite").csv(oneLakePath)Testa att dina data har skrivits genom att läsa den nyligen inlästa filen.
lakehouseRead = spark.read.format('csv').option("header", "true").load(oneLakePath) display(lakehouseRead.limit(10))
Grattis! Nu kan du läsa och skriva data i Fabric med hjälp av Azure Databricks.