Anteckning
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Den här artikeln beskriver arkitekturen medallion lake och beskriver hur du kan implementera designmönstret i Microsoft Fabric. Den riktar sig till flera målgrupper:
- Datatekniker: Teknisk personal som utformar, skapar och underhåller infrastrukturer och system som gör det möjligt för organisationen att samla in, lagra, bearbeta och analysera stora mängder data.
- Center of Excellence-, IT- och BI-team: De team som ansvarar för att övervaka analyser i hela organisationen.
- Infrastrukturadministratörer: Administratörerna som ansvarar för att övervaka Infrastrukturresurser i organisationen.
Medallion Lakehouse-arkitekturen, som ofta kallas medallionarkitektur, är ett designmönster som används av organisationer för att logiskt organisera data i ett sjöhus. Det är den rekommenderade designmetoden för Fabric. Eftersom OneLake är datasjön för Fabric implementeras medaljongarkitekturen genom att skapa sjöhus i OneLake.
Medallion-arkitekturen består av tre distinkta skikt, även kallade zoner. De tre medaljongskikten är: brons (rådata), silver (verifierade data) och guld (berikade data). Varje lager anger kvaliteten på data som lagras i lakehouse, med högre nivåer som representerar högre kvalitet. Den här metoden med flera lager hjälper dig att skapa en enda sanningskälla för företagets dataprodukter.
Det är viktigt att medaljongarkitekturen garanterar atomicitet, konsistens, isolering och hållbarhet (ACID) när data fortskrider genom lagren. Dina data börjar i sin råa form och sedan förbereder en serie valideringar och transformeringar data för att optimera dem för effektiv analys samtidigt som de ursprungliga kopiorna bibehålls som sanningskälla.
För mer information, se Vad är medallion lakehouse-arkitekturen?.
Medallion-arkitektur i Infrastruktur
Målet med medaljongarkitekturen är att stegvis och progressivt förbättra strukturen och kvaliteten på data under varje fas.
Medallion-arkitekturen består av tre distinkta skikt (eller zoner).
- Brons: Det här första lagret kallas även för rådatazonen och lagrar källdata i sitt ursprungliga format, inklusive ostrukturerade, halvstrukturerade eller strukturerade datatyper. Data i det här lagret är vanligtvis endast tillägg och oföränderliga. Genom att bevara rådata i bronsskiktet behåller du en sanningskälla och aktiverar upparbetning och granskning i framtiden.
- Silver: Det här lagret kallas även för den berikade zonen och lagrar data från bronsskiktet. Data rensas och standardiseras och är nu strukturerade som tabeller (rader och kolumner). Det kan också vara integrerat med andra data för att ge en företagsvy över alla affärsentiteter, till exempel kunder, produkter med mera.
- Guld: Det här sista lagret kallas även för den kurerade zonen och lagrar data från silverskiktet. Data förfinas för att uppfylla specifika verksamhets- och analyskrav för nedströms. Tabeller överensstämmer vanligtvis med star-schemadesign, som stöder utveckling av datamodeller som är optimerade för prestanda och användbarhet.
Varje zon bör delas upp i sitt eget sjöhus eller informationslager i OneLake, med data som flyttas mellan zonerna när de transformeras och förfinas.
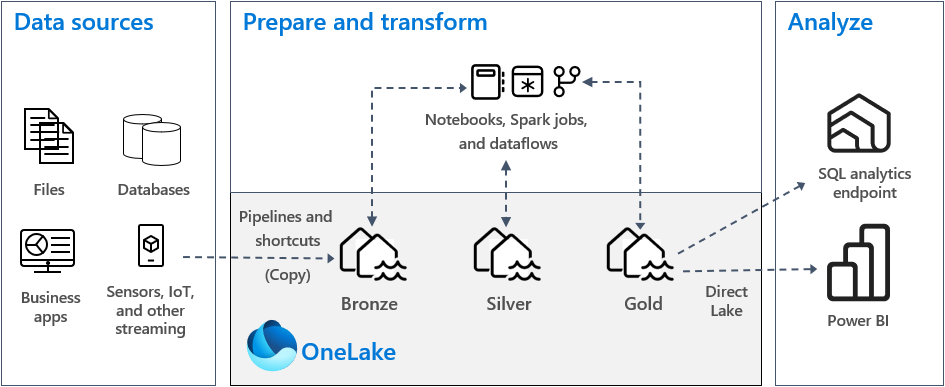
I en typisk implementering av medaljongarkitektur i Infrastruktur lagrar bronszonen data i samma format som datakällan. När datakällan är en relationsdatabas är Delta-tabeller ett bra val. Silver- och guldzonerna ska innehålla Delta-tabeller.
Dricks
För att lära dig hur du skapar en lakehouse, gå igenom handledningen för Lakehouse-scenariot från början till slut.
OneLake och lakehouse i Fabric
Grunden för ett modernt informationslager är en datasjö. Microsoft OneLake är en enda, enhetlig, logisk datasjö för hela organisationen. Den etableras automatiskt med varje Fabric-klientorganisation och är den enda platsen för alla dina analysdata.
Du kan använda OneLake för att:
- Ta bort silor och minska hanteringsarbetet. Alla organisationsdata lagras, hanteras och skyddas i en datasjöresurs.
- Minska dataförflyttning och duplicering. Målet med OneLake är att endast lagra en kopia av data. Färre kopior av data resulterar i färre dataförflyttningsprocesser, vilket leder till effektivitetsvinster och minskad komplexitet. Använd genvägar för att referera till data som lagras på andra platser i stället för att kopiera dem till OneLake.
- Använd med flera analysmotorer. Data i OneLake lagras i ett öppet format. På så sätt kan data efterfrågas av olika analysmotorer, inklusive Analysis Services (används av Power BI), T-SQL och Apache Spark. Andra icke-Fabric-program kan också använda API:er och SDK:er för att komma åt OneLake .
Om du vill lagra data i OneLake skapar du ett lakehouse i Fabric. En lakehouse är en plattform för dataarkitektur för lagring, hantering och analys av strukturerade och ostrukturerade data på en enda plats. Den kan skalas till stora datavolymer av alla filtyper och storlekar, och eftersom data lagras på en enda plats kan de delas och återanvändas i organisationen.
Varje lakehouse har en inbyggd SQL-analysslutpunkt som låser upp informationslagerfunktioner utan att behöva flytta data. Det innebär att du kan köra frågor mot dina data i lakehouse med hjälp av SQL-frågor och utan någon särskild konfiguration.
Mer information finns i Vad är ett sjöhus i Microsoft Fabric?.
Tabeller och filer
När du skapar ett sjöhus i OneLake etableras två fysiska lagringsplatser automatiskt:
- Tabeller är ett hanterat område för lagring av tabeller i alla format i Apache Spark (CSV, Parquet eller Delta). Alla tabeller, oavsett om de skapas automatiskt eller uttryckligen, identifieras som tabeller i lakehouse. Alla Delta-tabeller, som är Parquet-datafiler med en filbaserad transaktionslogg, identifieras också som tabeller.
- Filer är ett ohanterat område för lagring av data i valfritt filformat. Alla Delta-filer som lagras i det här området identifieras inte automatiskt som tabeller. Om du vill skapa en tabell över en Delta Lake-mapp i det ohanterade området skapar du en genväg eller en extern tabell med en plats som pekar på den ohanterade mappen som innehåller Delta Lake-filerna i Apache Spark.
Den största skillnaden mellan det hanterade området (tabeller) och det ohanterade området (filer) är den automatiska processen för identifiering och registrering av tabeller. Den här processen körs endast över alla mappar som skapats i det hanterade området, men inte i det ohanterade området.
I bronszonen lagrar du data i dess ursprungliga format, vilket kan vara tabeller eller filer. Om källdata kommer från OneLake, Azure Data Lake Store Gen2 (ADLS Gen2), Amazon S3 eller Google skapar du en genväg i bronszonen i stället för att kopiera data över.
I silver- och guldzonerna lagrar du vanligtvis data i Delta-tabeller. Men du kan också lagra data i Parquet- eller CSV-filer. Om du gör det måste du uttryckligen skapa en genväg eller en extern tabell med en plats som pekar på den ohanterade mapp som innehåller Delta Lake-filerna i Apache Spark.
I Microsoft Fabric ger Lakehouse Explorer en enhetlig grafisk representation av hela Lakehouse så att användarna kan navigera, komma åt och uppdatera sina data.
Mer information om automatisk tabellidentifiering finns i Automatisk tabellidentifiering och registrering.
Delta Lake-lagring
Delta Lake är ett optimerat lagringslager som utgör grunden för lagring av data och tabeller. Det stöder ACID-transaktioner för stordataarbetsbelastningar, och därför är det standardlagringsformatet i en Infrastruktursjöhus.
Delta Lake ger tillförlitlighet, säkerhet och prestanda i lakehouse för både strömning och batchdrift. Internt lagrar den data i Parquet-filformat, men den har även transaktionsloggar och statistik som ger funktioner och prestandaförbättringar jämfört med standardformatet Parquet.
Delta Lake-format ger följande fördelar jämfört med generiska filformat:
- Stöd för ACID-egenskaper, särskilt hållbarhet för att förhindra skadade data.
- Snabbare läsfrågor.
- Ökad data freshness.
- Stöd för både batch- och strömningsarbetsbelastningar.
- Stöd för återställning av data genom Delta Lake-tidsresor.
- Förbättrad regelefterlevnad och granskning med hjälp av Delta Lake-tabellhistorik.
Fabric standardiserar lagringsfilformatet med Delta Lake. Som standard skapar varje arbetsbelastningsmotor i Fabric Delta-tabeller när du skriver data till en ny tabell. Mer information finns i Tabellerna Lakehouse och Delta Lake.
Distributionsmodell
Om du vill implementera medaljongarkitektur i Infrastruktur kan du antingen använda lakehouses (ett för varje zon), ett informationslager eller en kombination av båda. Ditt beslut bör baseras på dina önskemål och expertkunskaper i ditt team. Med Fabric kan du använda olika analysmotorer som fungerar på en kopia av dina data i OneLake.
Här är två mönster att tänka på:
- Mönster 1: Skapa varje zon som ett sjöhus. I det här fallet får företagsanvändare åtkomst till data med hjälp av SQL-analysslutpunkten.
- Mönster 2: Skapa brons- och silverzonerna som sjöhus och guldzonen som ett informationslager. I det här fallet får företagsanvändare åtkomst till data med hjälp av datalagerslutpunkten.
Även om du kan skapa alla sjöhus på en enda infrastrukturarbetsyta rekommenderar vi att du skapar varje sjöhus på en egen, separat arbetsyta. Den här metoden ger dig mer kontroll och bättre styrning på zonnivå.
För bronszonen rekommenderar vi att du lagrar data i dess ursprungliga format eller använder Parquet eller Delta Lake. När det är möjligt behåller du data i sitt ursprungliga format. Om källdata kommer från OneLake, Azure Data Lake Store Gen2 (ADLS Gen2), Amazon S3 eller Google skapar du en genväg i bronszonen i stället för att kopiera data över.
För silver- och guldzonerna rekommenderar vi att du använder Delta-tabeller på grund av de extra funktioner och prestandaförbättringar som de ger. Infrastrukturresurserna standardiseras i Delta Lake-format och som standard skriver varje motor i Fabric data i det här formatet. Dessutom använder dessa motorer optimering av V-Order-skrivtid till Parquet-filformatet. Den optimeringen möjliggör snabba läsningar av Fabric-beräkningsmotorer, till exempel Power BI, SQL, Apache Spark och andra. Mer information finns i Delta Lake-tabelloptimering och V-order.
Slutligen står många organisationer idag inför en massiv ökning av datavolymer, tillsammans med ett ökande behov av att organisera och hantera dessa data på ett logiskt sätt samtidigt som mer målinriktad och effektiv användning och styrning underlättas. Det kan leda till att du upprättar och hanterar en decentraliserad eller federerad dataorganisation med styrning. För att uppfylla det här målet bör du överväga att implementera en datanätsarkitektur. Data mesh är ett arkitekturmönster som fokuserar på att skapa datadomäner som erbjuder data som en produkt.
Du kan skapa en datanätsarkitektur för din dataegendom i Fabric genom att skapa datadomäner. Du kan skapa domäner som mappar till dina affärsdomäner, till exempel marknadsföring, försäljning, inventering, personal och andra. Du kan sedan implementera medallion-arkitektur genom att konfigurera datazoner inom var och en av dina domäner. Mer information om domäner finns i Domäner.
Förstå Datalagring i Delta-tabeller
Det här avsnittet beskriver andra riktlinjer som rör implementering av en medallion lakehouse-arkitektur i Fabric.
Filstorlek
I allmänhet presterar en stordataplattform bättre när den har några stora filer snarare än många små filer. Prestandaförsämring inträffar när beräkningsmotorn har många metadata och filåtgärder att hantera. För bättre frågeprestanda rekommenderar vi att du siktar på datafiler som är ungefär 1 GB stora.
Delta Lake har en funktion som kallas förutsägelseoptimering. Förutsägande optimering automatiserar underhållsåtgärder för Delta-tabeller. När den här funktionen är aktiverad identifierar Delta Lake tabeller som skulle dra nytta av underhållsåtgärder och optimerar sedan deras lagring. Även om den här funktionen bör utgöra en del av din driftskvalitet och ditt arbete med att förbereda data, kan Fabric även optimera datafiler under dataskrivning. Mer information finns i Förutsägande optimering för Delta Lake.
Historisk kvarhållning
Som standard upprätthåller Delta Lake en historik över alla ändringar som gjorts, så storleken på historiska metadata växer med tiden. Baserat på dina affärskrav behåller du endast historiska data under en viss tidsperiod för att minska dina lagringskostnader. Överväg att behålla historiska data endast under den senaste månaden eller någon annan lämplig tidsperiod.
Du kan ta bort äldre historiska data från en Delta-tabell med hjälp av kommandot VACUUM. Som standard kan du dock inte ta bort historiska data under de senaste sju dagarna. Denna begränsning upprätthåller datakonsekvensen. Konfigurera standardantalet dagar med tabellegenskapen delta.deletedFileRetentionDuration = "interval <interval>". Den egenskapen avgör hur lång tid en fil måste tas bort innan den kan betraktas som en kandidat för en vakuumåtgärd.
Tabellpartitioner
När du lagrar data i varje zon rekommenderar vi att du använder en partitionerad mappstruktur i tillämpliga fall. Den här tekniken förbättrar datahanterbarheten och frågeprestanda. I allmänhet resulterar partitionerade data i en mappstruktur i snabbare sökning efter specifika dataposter på grund av partitionsrensning/eliminering.
Vanligtvis lägger du till data i måltabellen när nya data tas emot. I vissa fall kan du dock sammanfoga data eftersom du behöver uppdatera befintliga data samtidigt. I så fall kan du utföra en upsert-åtgärd med hjälp av KOMMANDOT MERGE. När måltabellen är partitionerad måste du använda ett partitionsfilter för att påskynda åtgärden. På så sätt kan motorn eliminera partitioner som inte kräver uppdatering.
Dataåtkomst
Du bör planera och kontrollera vem som behöver åtkomst till specifika data i lakehouse. Du bör också förstå de olika transaktionsmönster som de kommer att använda vid åtkomst till dessa data. Du kan sedan definiera rätt tabellpartitioneringsschema och datasamordning med Delta Lake Z-orderindex.
Relaterat innehåll
Mer information om hur du implementerar en Infrastruktursjöhus finns i följande resurser.