Erfarenhetsspecifik vägledning för haveriberedskap
Det här dokumentet innehåller erfarenhetsspecifik vägledning för att återställa dina Infrastrukturdata i händelse av en regional katastrof.
Exempelscenario
Ett antal vägledningsavsnitt i det här dokumentet använder följande exempelscenario för förklaringar och illustrationer. Gå tillbaka till det här scenariot efter behov.
Anta att du har en kapacitet C1 i region A som har en arbetsyta W1. Om du har aktiverat haveriberedskap för kapacitet C1 replikeras OneLake-data till en säkerhetskopia i region B. Om region A drabbas av störningar redundansväxlar infrastrukturtjänsten i C1 till region B.
Följande bild illustrerar det här scenariot. Rutan till vänster visar den störda regionen. Rutan i mitten representerar fortsatt tillgänglighet för data efter redundansväxling, och rutan till höger visar den fullständigt täckta situationen när kunden agerar för att återställa sina tjänster till full funktion.
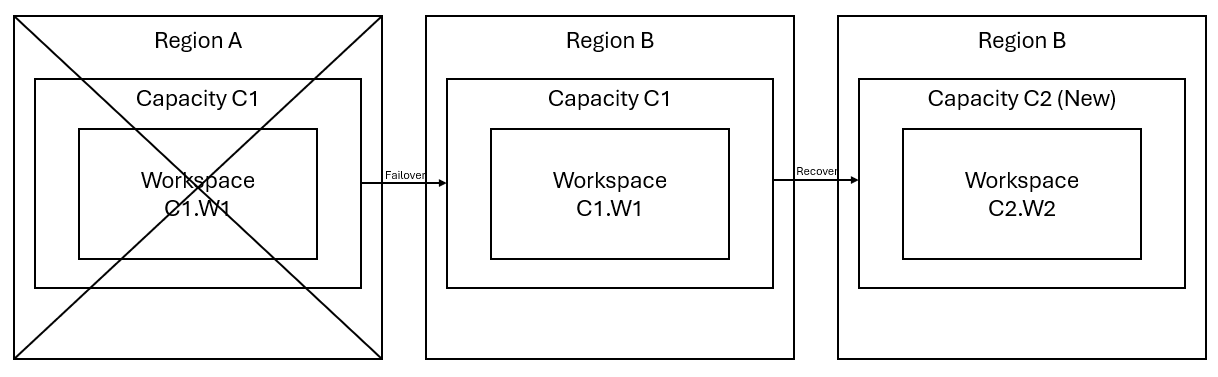
Här är den allmänna återställningsplanen:
Skapa en ny infrastrukturkapacitet C2 i en ny region.
Skapa en ny W2-arbetsyta i C2, inklusive motsvarande objekt med samma namn som i C1. W1.
Kopiera data från den störda C1. W1 till C2. W2.
Följ de dedikerade anvisningarna för varje komponent för att återställa objekt till deras fullständiga funktion.
Erfarenhetsspecifika återställningsplaner
Följande avsnitt innehåller stegvisa guider för varje Fabric-upplevelse för att hjälpa kunder genom återställningsprocessen.
Datateknik
Den här guiden vägleder dig genom återställningsprocedurerna för Dataingenjör miljön. Den omfattar lakehouses, notebook-filer och Spark-jobbdefinitioner.
Sjöhus
Lakehouses från den ursprungliga regionen är fortfarande otillgängliga för kunder. För att återställa ett sjöhus kan kunderna återskapa det i arbetsytan C2. W2. Vi rekommenderar två metoder för att återställa sjöhus:
Metod 1: Använda anpassat skript för att kopiera Lakehouse Delta-tabeller och -filer
Kunder kan återskapa lakehouses med hjälp av ett anpassat Scala-skript.
Skapa lakehouse (till exempel LH1) i den nyligen skapade arbetsytan C2. W2.
Skapa en ny notebook-fil i arbetsytan C2. W2.
Om du vill återställa tabellerna och filerna från det ursprungliga lakehouse-huset läser du data med OneLake-sökvägar som abfss (se Ansluta till Microsoft OneLake). Du kan använda kodexemplet nedan (se Introduktion till Microsoft Spark-verktyg) i notebook-filen för att hämta ABFS-sökvägarna för filer och tabeller från det ursprungliga lakehouse-huset. (Ersätt C1. W1 med det faktiska arbetsytans namn)
mssparkutils.fs.ls('abfs[s]://<C1.W1>@onelake.dfs.fabric.microsoft.com/<item>.<itemtype>/<Tables>/<fileName>')Använd följande kodexempel för att kopiera tabeller och filer till det nyligen skapade lakehouse.
För Delta-tabeller måste du kopiera tabell ett i taget för att återställa i det nya sjöhuset. När det gäller Lakehouse-filer kan du kopiera hela filstrukturen med alla underliggande mappar med en enda körning.
Kontakta supportteamet för tidsstämpeln för redundans som krävs i skriptet.
%%spark val source="abfs path to original Lakehouse file or table directory" val destination="abfs path to new Lakehouse file or table directory" val timestamp= //timestamp provided by Support mssparkutils.fs.cp(source, destination, true) val filesToDelete = mssparkutils.fs.ls(s"$source/_delta_log") .filter{sf => sf.isFile && sf.modifyTime > timestamp} for(fileToDelte <- filesToDelete) { val destFileToDelete = s"$destination/_delta_log/${fileToDelte.name}" println(s"Deleting file $destFileToDelete") mssparkutils.fs.rm(destFileToDelete, false) } mssparkutils.fs.write(s"$destination/_delta_log/_last_checkpoint", "", true)När du har kört skriptet visas tabellerna i det nya sjöhuset.
Metod 2: Använd Azure Storage Explorer för att kopiera filer och tabeller
Om du bara vill återställa specifika Lakehouse-filer eller tabeller från det ursprungliga lakehouse-huset använder du Azure Storage Explorer. Mer information finns i Integrera OneLake med Azure Storage Explorer. För stora datastorlekar använder du Metod 1.
Kommentar
De två metoderna som beskrivs ovan återställer både metadata och data för Delta-formaterade tabeller, eftersom metadata är samlokalisering och lagras med data i OneLake. För icke-Delta-formaterade tabeller (e.g. CSV, Parquet osv.) som skapas med hjälp av DDL-skript/-kommandon (Spark Data Definition Language) ansvarar användaren för att underhålla och köra Spark DDL-skript/-kommandon igen för att återställa dem.
Notebook-fil
Notebook-filer från den primära regionen är fortfarande inte tillgängliga för kunder och koden i notebook-filer replikeras inte till den sekundära regionen. För att återställa notebook-kod i den nya regionen finns det två metoder för att återställa notebook-kodinnehåll.
Metod 1: Användarhanterad redundans med Git-integrering (i offentlig förhandsversion)
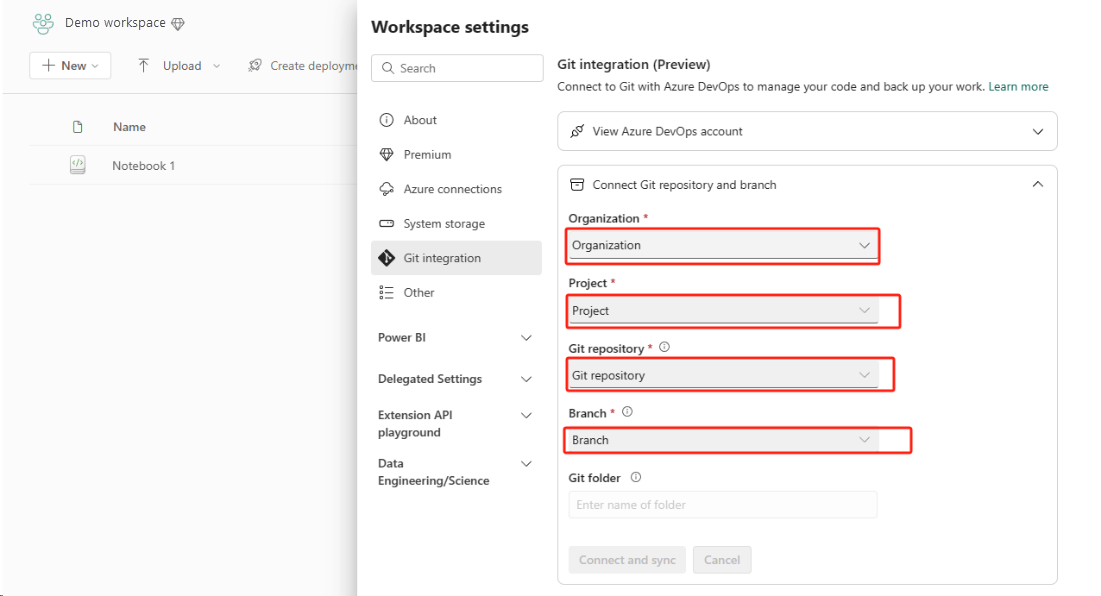
Det bästa sättet att göra detta enkelt och snabbt är att använda Fabric Git-integrering och sedan synkronisera notebook-filen med din ADO-lagringsplats. När tjänsten redundansväxlar till en annan region kan du använda lagringsplatsen för att återskapa anteckningsboken på den nya arbetsytan som du skapade.
Konfigurera Git-integrering för din arbetsyta och välj Anslut och synkronisera med ADO-lagringsplats.
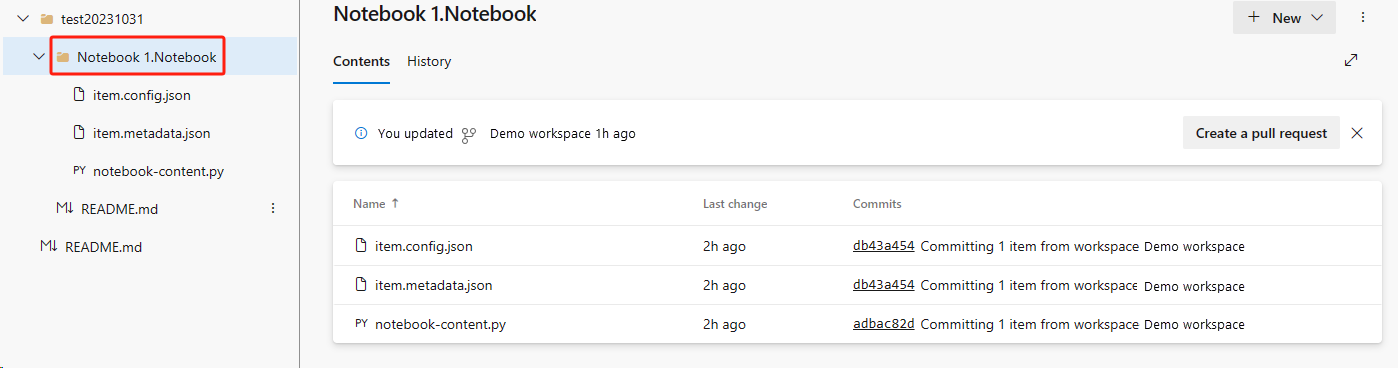
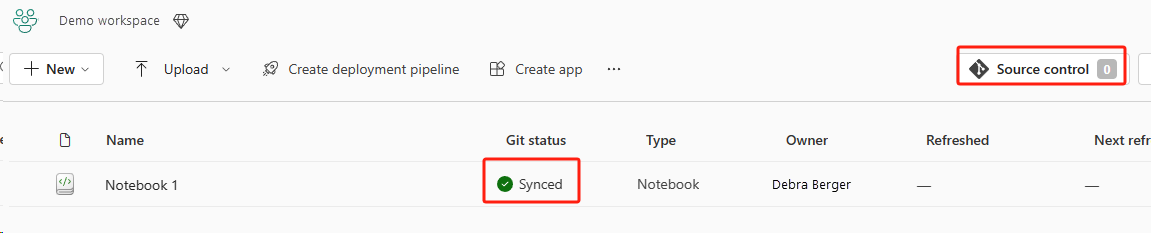
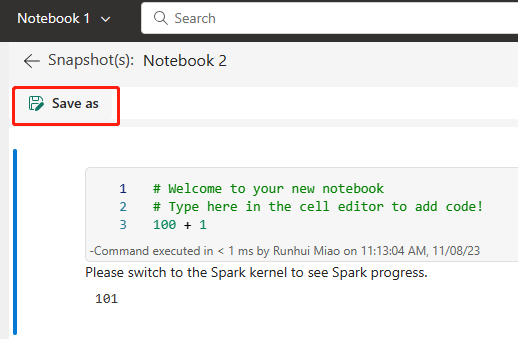
Följande bild visar den synkroniserade notebook-filen.
Återställa notebook-filen från ADO-lagringsplatsen.
I den nyligen skapade arbetsytan ansluter du till din Azure ADO-lagringsplats igen.
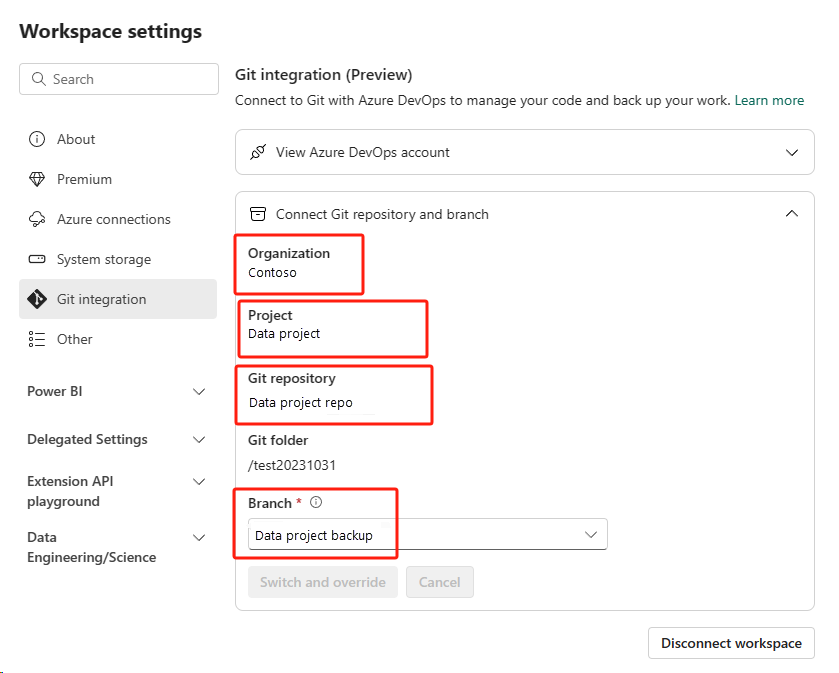
Välj knappen Källkontroll. Välj sedan relevant gren av lagringsplatsen. Välj sedan Uppdatera alla. Den ursprungliga anteckningsboken visas.
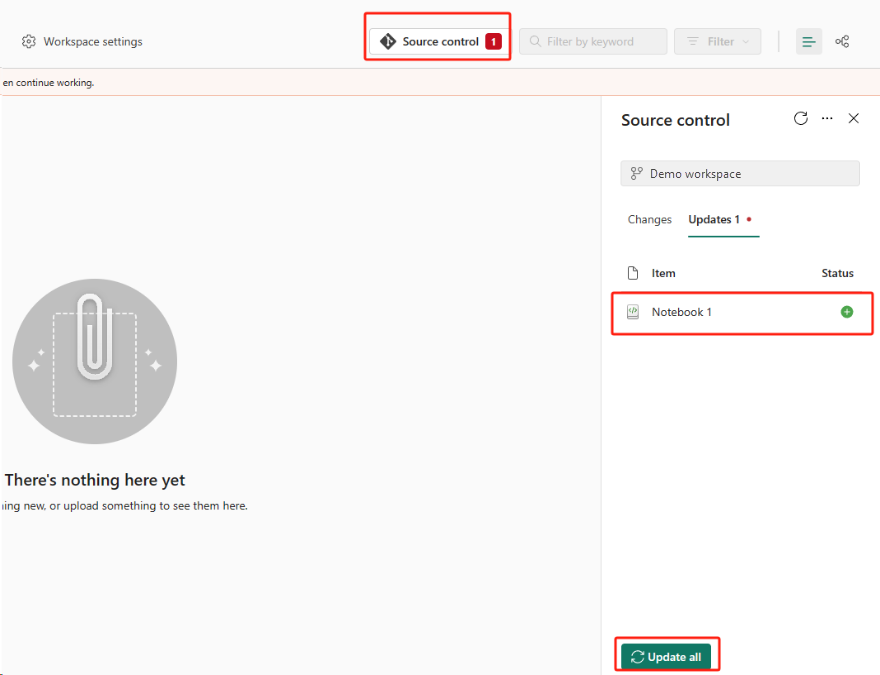
Om den ursprungliga notebook-filen har ett standard lakehouse kan användarna referera till Lakehouse-avsnittet för att återställa lakehouse och sedan ansluta det nyligen återställda lakehouse till den nyligen återställda notebook-filen.
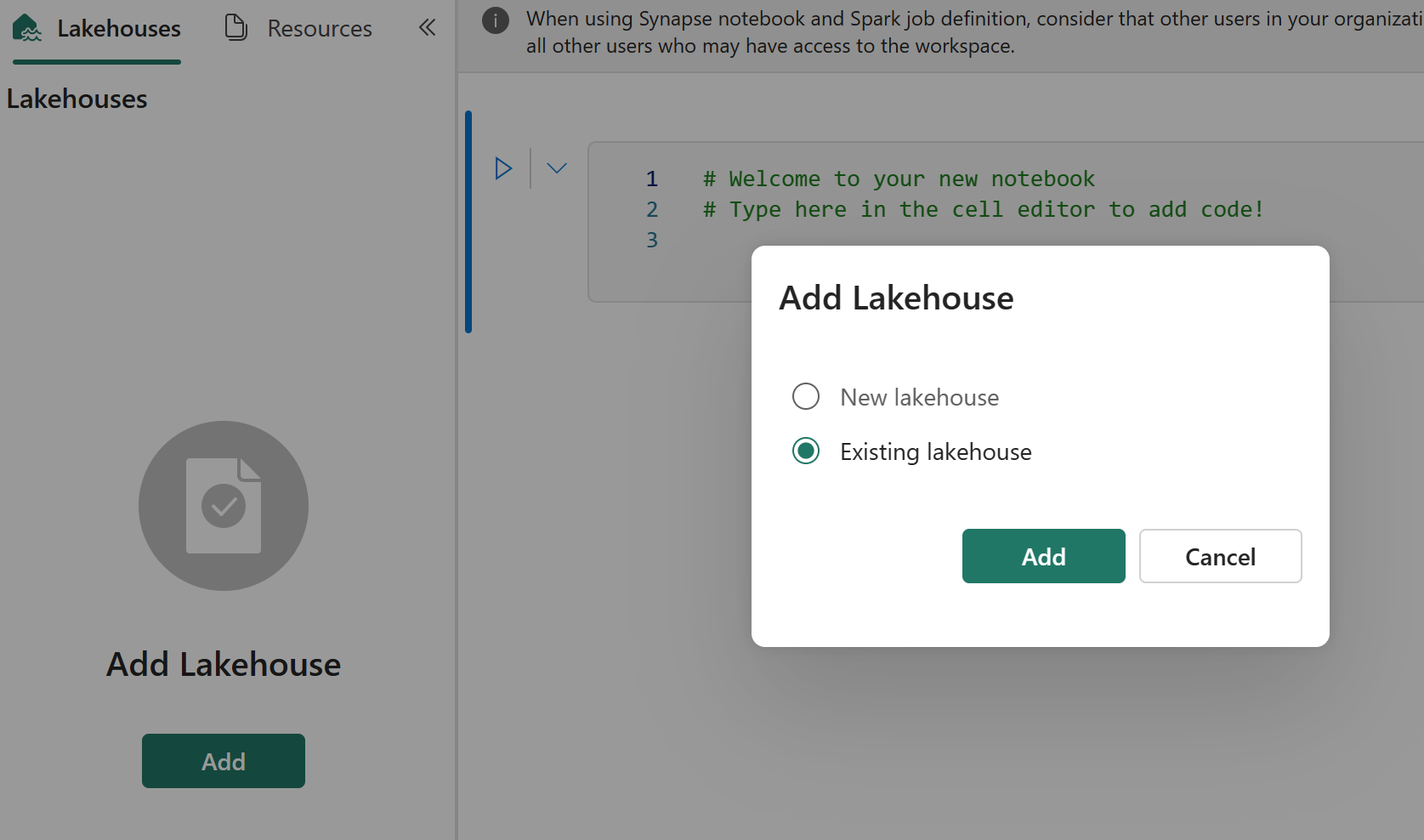
Git-integreringen stöder inte synkronisering av filer, mappar eller notebook-ögonblicksbilder i notebook-resursutforskaren.
Om den ursprungliga notebook-filen har filer i notebook-resursutforskaren:
Se till att spara filer eller mappar på en lokal disk eller på någon annan plats.
Ladda upp filen igen från din lokala disk eller molnenheter till den återställda notebook-filen.
Om den ursprungliga notebook-filen har en ögonblicksbild av notebook-filen sparar du även ögonblicksbilden av notebook-filen till ditt eget versionskontrollsystem eller din lokala disk.
Mer information om Git-integrering finns i Introduktion till Git-integrering.
Metod 2: Manuell metod för att säkerhetskopiera kodinnehåll
Om du inte använder Git-integreringsmetoden kan du spara den senaste versionen av din kod, filer i resursutforskaren och ögonblicksbilden av notebook-filer i ett versionskontrollsystem som Git och manuellt återställa notebook-innehållet efter ett haveri:
Använd funktionen "Importera anteckningsbok" för att importera den notebook-kod som du vill återställa.
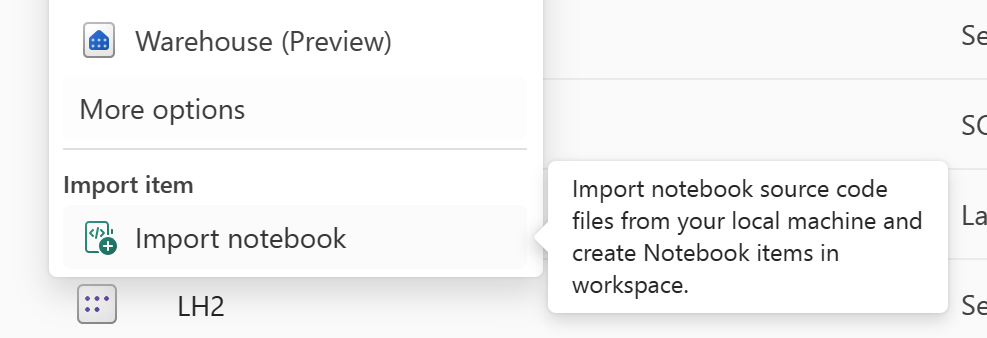
Efter importen går du till önskad arbetsyta (till exempel "C2. W2") för att komma åt den.
Om den ursprungliga notebook-filen har ett standard lakehouse läser du avsnittet Lakehouse. Anslut sedan det nyligen återställda lakehouse (som har samma innehåll som det ursprungliga standard lakehouse) till den nyligen återställda notebook-filen.
Om den ursprungliga notebook-filen har filer eller mappar i resursutforskaren laddar du upp filerna eller mapparna som sparats i användarens versionskontrollsystem igen.
Definition av Spark-jobb
Spark-jobbdefinitioner (SJD) från den primära regionen är fortfarande inte tillgängliga för kunder, och huvuddefinitionsfilen och referensfilen i notebook-filen replikeras till den sekundära regionen via OneLake. Om du vill återställa SJD i den nya regionen kan du följa de manuella stegen nedan för att återställa SJD. Observera att historiska körningar av SJD inte återställs.
Du kan återställa SJD-objekten genom att kopiera koden från den ursprungliga regionen med hjälp av Azure Storage Explorer och manuellt återansluta Lakehouse-referenser efter katastrofen.
Skapa ett nytt SJD-objekt (till exempel SJD1) i den nya arbetsytan C2. W2, med samma inställningar och konfigurationer som det ursprungliga SJD-objektet (till exempel språk, miljö osv.).
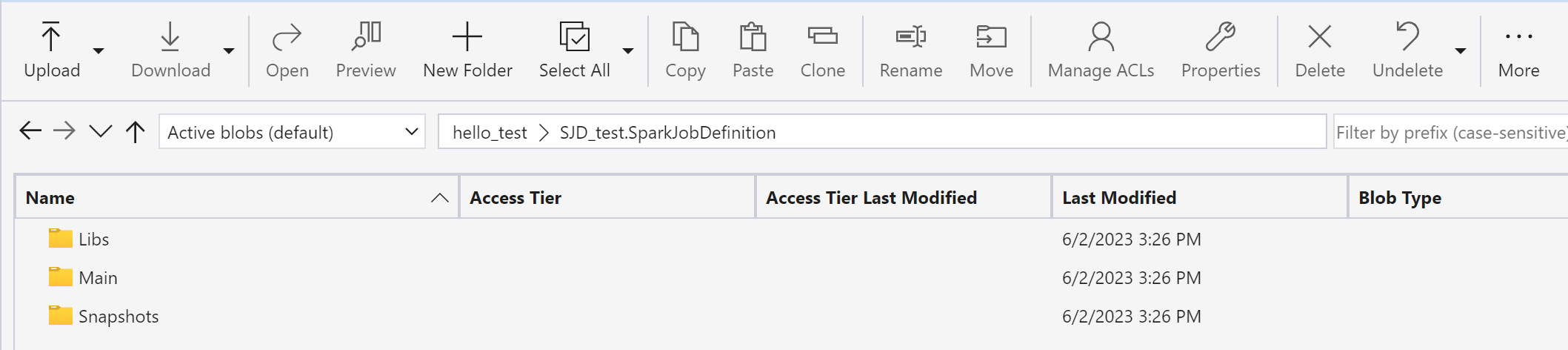
Använd Azure Storage Explorer för att kopiera Libs, Mains och Snapshots från det ursprungliga SJD-objektet till det nya SJD-objektet.
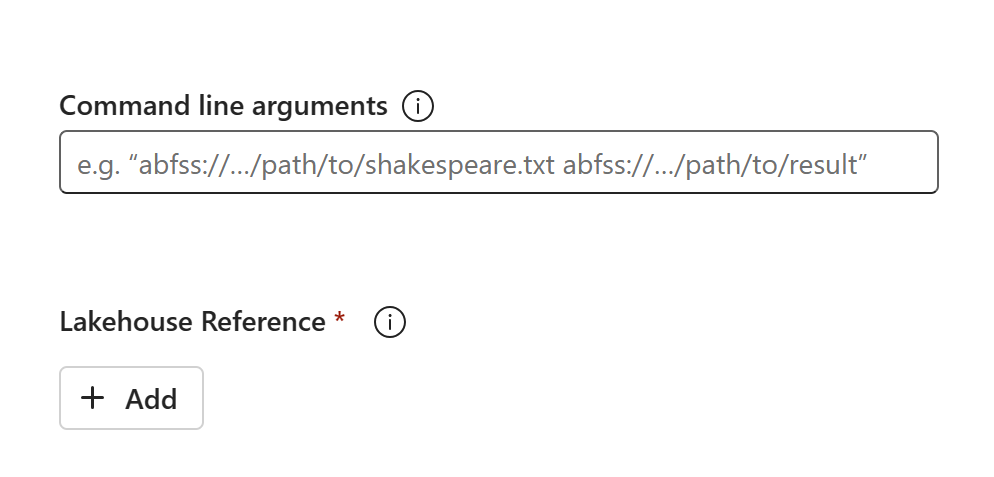
Kodinnehållet visas i den nyligen skapade SJD:en. Du måste lägga till den nyligen återställda Lakehouse-referensen manuellt till jobbet (se Återställningsstegen för Lakehouse). Användarna måste ange de ursprungliga kommandoradsargumenten manuellt.
Nu kan du köra eller schemalägga din nyligen återställda SJD.
Mer information om Azure Storage Explorer finns i Integrera OneLake med Azure Storage Explorer.
Datavetenskap
Den här guiden vägleder dig genom återställningsprocedurerna för Datavetenskap upplevelse. Den omfattar ML-modeller och experiment.
ML-modell och experiment
Datavetenskap objekt från den primära regionen är fortfarande inte tillgängliga för kunder, och innehållet och metadata i ML-modeller och experiment replikeras inte till den sekundära regionen. Om du vill återställa dem helt i den nya regionen sparar du kodinnehållet i ett versionskontrollsystem (till exempel Git) och kör kodinnehållet igen manuellt efter katastrofen.
Återställ anteckningsboken. Se återställningsstegen för notebook-filer.
Konfiguration, historiskt kör mått och metadata replikeras inte till den kopplade regionen. Du måste köra om varje version av din datavetenskapskod för att helt återställa ML-modeller och experiment efter katastrofen.
Informationslager
Den här guiden vägleder dig genom återställningsprocedurerna för informationslagerupplevelsen. Den täcker lager.
Distributionslager
Lager från den ursprungliga regionen är fortfarande otillgängliga för kunder. Använd följande två steg för att återställa lager.
Skapa ett nytt interim lakehouse i arbetsytan C2. W2 för de data som du kopierar över från det ursprungliga lagret.
Fyll i informationslagrets Delta-tabeller genom att använda lagerutforskaren och T-SQL-funktionerna (se Tabeller i datalager i Microsoft Fabric).
Kommentar
Vi rekommenderar att du behåller din lagerkod (schema, tabell, vy, lagrad procedur, funktionsdefinitioner och säkerhetskoder) version och sparad på en säker plats (till exempel Git) enligt dina utvecklingsmetoder.
Datainmatning via Lakehouse- och T-SQL-kod
I nyskapade arbetsytan C2. W2:
Skapa ett interim lakehouse "LH2" i C2. W2.
Återställ Delta-tabellerna i interim lakehouse från det ursprungliga lagret genom att följa Återställningsstegen för Lakehouse.
Skapa ett nytt lager "WH2" i C2. W2.
Anslut interim lakehouse i din lagerutforskare.
Beroende på hur du ska distribuera tabelldefinitioner före dataimporten kan den faktiska T-SQL som används för import variera. Du kan använda metoden INSERT INTO, SELECT INTO eller CREATE TABLE AS SELECT för att återställa Lagertabeller från lakehouses. Vidare i exemplet skulle vi använda INSERT INTO-smak. (Om du använder koden nedan ersätter du exempel med faktiska tabell- och kolumnnamn)
USE WH1 INSERT INTO [dbo].[aggregate_sale_by_date_city]([Date],[City],[StateProvince],[SalesTerritory],[SumOfTotalExcludingTax],[SumOfTaxAmount],[SumOfTotalIncludingTax], [SumOfProfit]) SELECT [Date],[City],[StateProvince],[SalesTerritory],[SumOfTotalExcludingTax],[SumOfTaxAmount],[SumOfTotalIncludingTax], [SumOfProfit] FROM [LH11].[dbo].[aggregate_sale_by_date_city] GOSlutligen ändrar du anslutningssträng i program med hjälp av ditt Infrastrukturlager.
Kommentar
För kunder som behöver regional haveriberedskap och helt automatiserad affärskontinuitet rekommenderar vi att du behåller två infrastrukturlagerinställningar i separata infrastrukturresurser och underhåller kod- och dataparitet genom att utföra regelbundna distributioner och datainmatning till båda platserna.
Speglad databas
Speglade databaser från den primära regionen är fortfarande inte tillgängliga för kunder och inställningarna replikeras inte till den sekundära regionen. Om du vill återställa den i händelse av ett regionalt fel måste du återskapa den speglade databasen på en annan arbetsyta från en annan region.
Data Factory
Data Factory-objekt från den primära regionen är fortfarande inte tillgängliga för kunder och inställningarna och konfigurationen i datapipelines eller dataflödesgen2-objekt replikeras inte till den sekundära regionen. Om du vill återställa dessa objekt i händelse av ett regionalt fel måste du återskapa dina Dataintegration objekt på en annan arbetsyta från en annan region. I följande avsnitt beskrivs informationen.
Dataflöden Gen2
Om du vill återställa ett Dataflow Gen2-objekt i den nya regionen måste du exportera en PQT-fil till ett versionskontrollsystem som Git och sedan återställa Dataflow Gen2-innehållet manuellt efter katastrofen.
I dataflödets Gen2-objekt går du till fliken Start i Power Query-redigeraren och väljer Exportera mall.
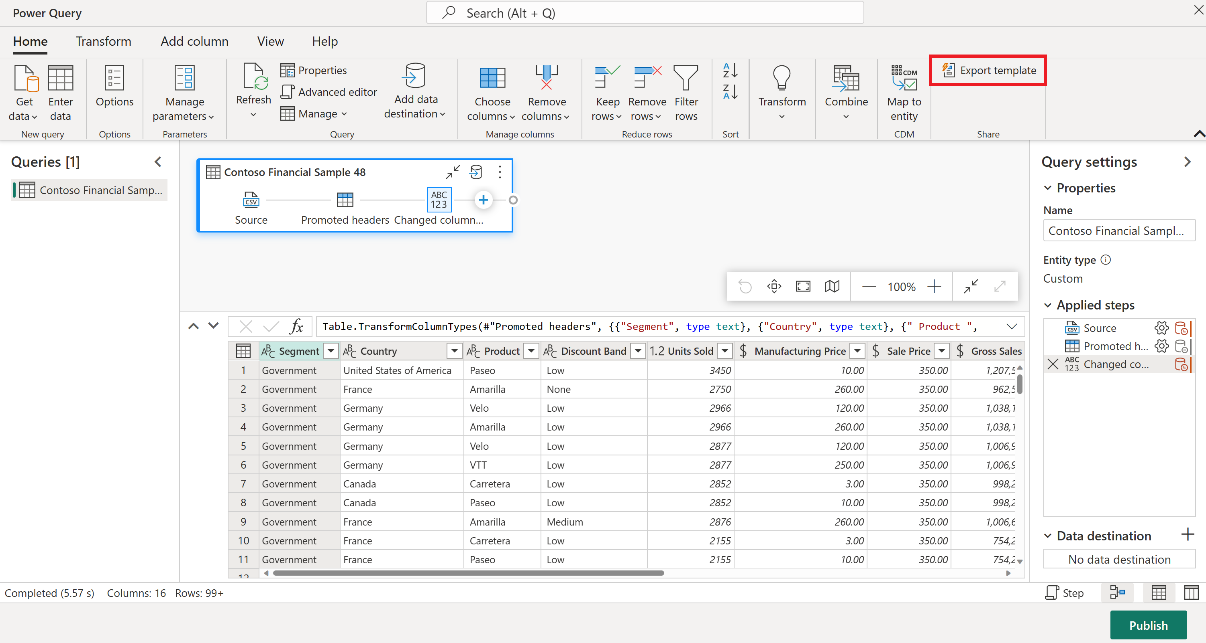
I dialogrutan Exportera mall anger du ett namn (obligatoriskt) och en beskrivning (valfritt) för den här mallen. När du är klar klickar du på OK.
Efter katastrofen skapar du ett nytt Dataflow Gen2-objekt i den nya arbetsytan "C2. W2".
I den aktuella vyrutan i Power Query-redigeraren väljer du Importera från en Power Query-mall.
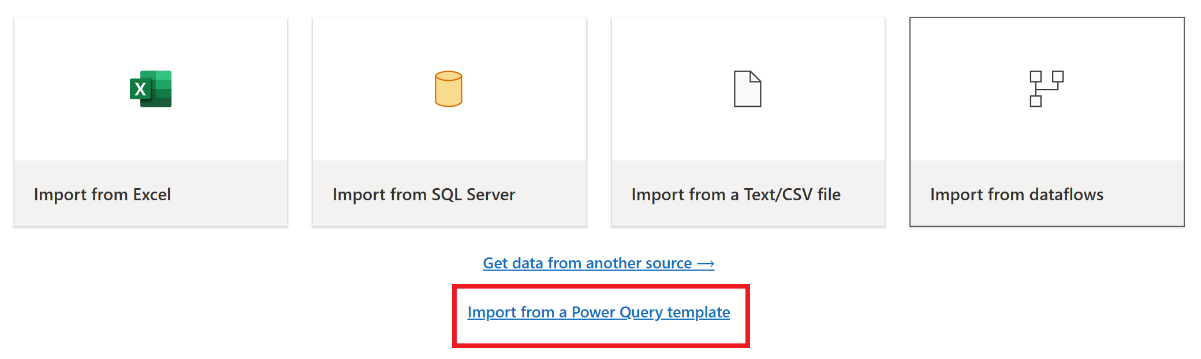
I dialogrutan Öppna bläddrar du till din standardmapp för nedladdningar och väljer den .pqt-fil som du sparade i föregående steg. Välj sedan Öppna.
Mallen importeras sedan till ditt nya Dataflow Gen2-objekt.
Datapipelines
Kunder kan inte komma åt datapipelines i händelse av regional katastrof och konfigurationerna replikeras inte till den kopplade regionen. Vi rekommenderar att du skapar kritiska datapipelines på flera arbetsytor i olika regioner.
Kopiera jobb
CopyJob-användare måste vidta proaktiva åtgärder för att skydda mot en regional katastrof. Följande metod säkerställer att en användares CopyJobs förblir tillgängliga efter en regional katastrof.
Användarhanterad redundans med Git-integrering (i offentlig förhandsversion)
Det bästa sättet att göra den här processen enkel och snabb är att använda Fabric Git-integrering och sedan synkronisera ditt CopyJob med din ADO-lagringsplats. När tjänsten växlar över till en annan region kan du använda förvaret för att återskapa CopyJob i den nya arbetsytan du skapade.
Konfigurera git-integreringen för arbetsytan och välj ansluta och synkronisera med ADO-lagringsplatsen.

Följande bild visar det synkroniserade CopyJob.

Återställ CopyJob från ADO-lagringsplatsen.
På den nyligen skapade arbetsytan ansluter du och synkroniserar till din Azure ADO-lagringsplats igen. Alla Fabric-objekt i detta lagringsarkiv laddas ned automatiskt till din nya arbetsyta.
Om det ursprungliga CopyJob använder ett Lakehouse kan användarna referera till avsnittet Lakehouse för att återställa Lakehouse och sedan ansluta det nyligen återställda CopyJob till det nyligen återställda Lakehouse.
Mer information om Git-integrering finns i Introduktion till Git-integrering.
Realtidsinformation
Den här guiden vägleder dig genom återställningsprocedurerna för realtidsinformationsupplevelsen. Den omfattar KQL-databaser/frågeuppsättningar och eventstreams.
KQL-databas/frågeuppsättning
KQL-databas-/frågeuppsättningsanvändare måste vidta proaktiva åtgärder för att skydda mot en regional katastrof. Följande metod säkerställer att data i KQL-databasernas frågeuppsättningar förblir säkra och tillgängliga i händelse av en regional katastrof.
Använd följande steg för att garantera en effektiv haveriberedskapslösning för KQL-databaser och frågeuppsättningar.
Upprätta oberoende KQL-databaser: Konfigurera två eller flera oberoende KQL-databaser/frågeuppsättningar på dedikerade Infrastrukturresurser-kapaciteter. Dessa bör konfigureras i två olika Azure-regioner (helst Azure-kopplade regioner) för att maximera motståndskraften.
Replikera hanteringsaktiviteter: Alla hanteringsåtgärder som vidtas i en KQL-databas bör speglas i den andra. Detta säkerställer att båda databaserna förblir synkroniserade. Viktiga aktiviteter som ska replikeras är:
Tabeller: Kontrollera att tabellstrukturerna och schemadefinitionerna är konsekventa mellan databaserna.
Mappning: Duplicera alla nödvändiga mappningar. Kontrollera att datakällor och mål är korrekt anpassade.
Principer: Kontrollera att båda databaserna har liknande datakvarhållning, åtkomst och andra relevanta principer.
Hantera autentisering och auktorisering: Konfigurera nödvändiga behörigheter för varje replik. Se till att rätt auktoriseringsnivåer har fastställts, vilket ger åtkomst till den personal som krävs samtidigt som säkerhetsstandarderna upprätthålls.
Parallell datainmatning: Om du vill hålla data konsekventa och redo i flera regioner läser du in samma datauppsättning i varje KQL-databas samtidigt som du matar in den.
Händelseström
En händelseström är en central plats i Infrastrukturplattformen för att samla in, transformera och dirigera realtidshändelser till olika destinationer (till exempel lakehouses, KQL-databaser/frågeuppsättningar) utan kod. Så länge målen stöds av haveriberedskap förlorar inte eventstreams data. Därför bör kunderna använda haveriberedskapsfunktionerna i dessa målsystem för att garantera datatillgänglighet.
Kunder kan också uppnå geo-redundans genom att distribuera identiska Eventstream-arbetsbelastningar i flera Azure-regioner som en del av en aktiv/aktiv strategi för flera platser. Med en aktiv/aktiv metod för flera platser kan kunderna komma åt sin arbetsbelastning i någon av de distribuerade regionerna. Den här metoden är den mest komplexa och kostsamma metoden för haveriberedskap, men det kan minska återställningstiden till nära noll i de flesta situationer. För att vara helt geo-redundanta kan kunderna
Skapa repliker av deras datakällor i olika regioner.
Skapa Eventstream-objekt i motsvarande regioner.
Anslut dessa nya objekt till identiska datakällor.
Lägg till identiska mål för varje händelseström i olika regioner.