Kubernetes-klustermönster med hög tillgänglighet
Den här artikeln beskriver hur du skapar och använder en Kubernetes-baserad infrastruktur med hög tillgänglighet med hjälp av Azure Kubernetes Service -motorn (AKS) på Azure Stack Hub. Det här scenariot är vanligt för organisationer med kritiska arbetsbelastningar i mycket begränsade och reglerade miljöer. Organisationer inom domäner som ekonomi, försvar och myndigheter.
Kontext och problem
Många organisationer utvecklar molnbaserade lösningar som utnyttjar avancerade tjänster och tekniker som Kubernetes. Även om Azure tillhandahåller datacenter i de flesta regioner i världen finns det ibland gränsanvändningsfall och scenarier där affärskritiska program måste köras på en specifik plats. Här är några saker att tänka på:
- Platskänslighet
- Svarstid mellan programmet och lokala system
- Bevarande av bandbredd
- Anslutning
- Regelmässiga eller lagstadgade krav
Azure löser de flesta av dessa problem i kombination med Azure Stack Hub. En bred uppsättning alternativ, beslut och överväganden för en lyckad implementering av Kubernetes som körs på Azure Stack Hub beskrivs nedan.
Lösning
Det här mönstret förutsätter att vi måste hantera en strikt uppsättning begränsningar. Programmet måste köras lokalt och alla personuppgifter får inte nå offentliga molntjänster. Övervakning och andra icke-PII-data kan skickas till Azure och bearbetas där. Externa tjänster som ett offentligt containerregister eller andra kan nås men kan filtreras via en brandvägg eller proxyserver.
Exempelprogrammet som visas här är utformat för att använda Kubernetes-interna lösningar när det är möjligt. Den här designen undviker leverantörslåsning i stället för att använda plattformsbaserade tjänster. Programmet använder till exempel en mongoDB-databasserverdel med egen värd i stället för en PaaS-tjänst eller extern databastjänst. Mer information finns i utbildningsvägen Introduktion till Kubernetes på Azure.

Föregående diagram illustrerar programarkitekturen för exempelprogrammet som körs på Kubernetes på Azure Stack Hub. Appen består av flera komponenter, bland annat:
- Ett AKS-motorbaserat Kubernetes-kluster på Azure Stack Hub.
- cert-manager, som tillhandahåller en uppsättning verktyg för certifikathantering i Kubernetes, som används för att automatiskt begära certifikat från Let's Encrypt.
- Ett Kubernetes-namnområde som innehåller programkomponenterna för klientdelen (ratings-web), API (ratings-api) och databas (ratings-mongodb).
- Den ingresskontrollant som dirigerar HTTP/HTTPS-trafik till slutpunkter i Kubernetes-klustret.
Exempelprogrammet används för att illustrera programarkitekturen. Alla komponenter är exempel. Arkitekturen innehåller bara en enda programdistribution. För att uppnå hög tillgänglighet (HA) kör vi distributionen minst två gånger på två olika Azure Stack Hub-instanser – de kan köras antingen på samma plats eller på två (eller flera) olika platser:
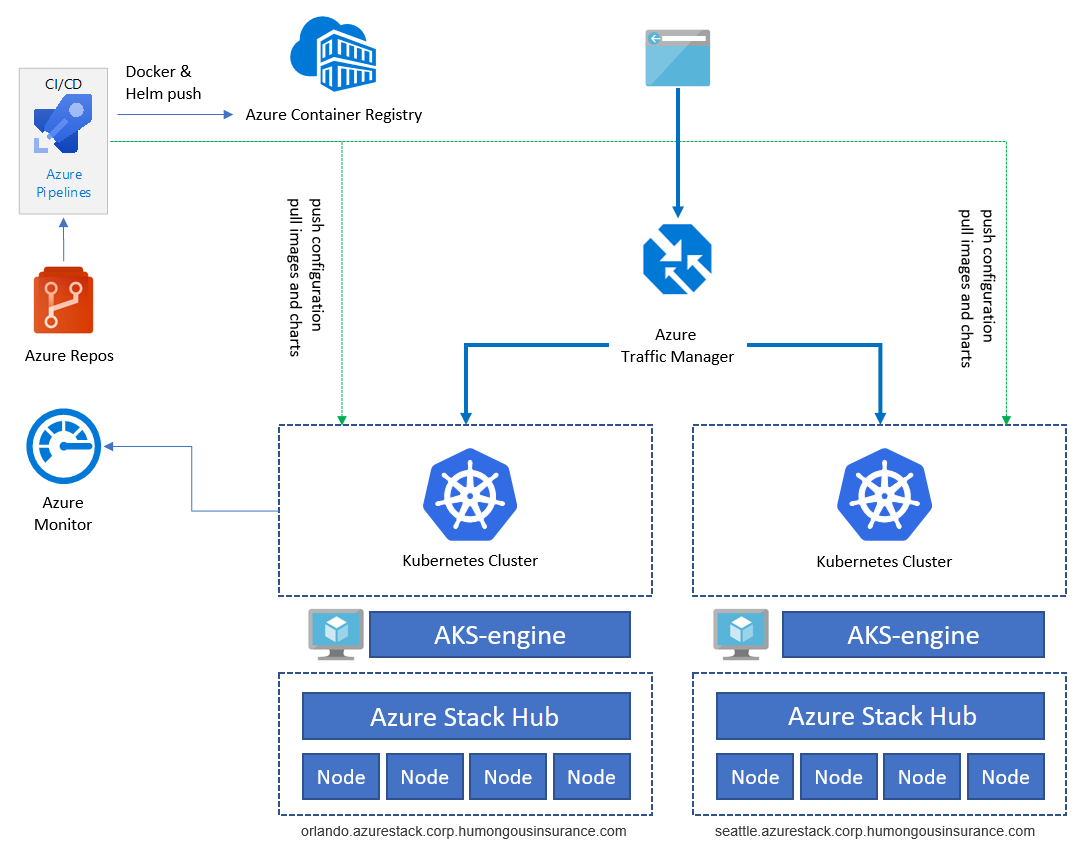
Tjänster som Azure Container Registry, Azure Monitor och andra finns utanför Azure Stack Hub i Azure eller lokalt. Den här hybriddesignen skyddar lösningen mot avbrott i en enda Azure Stack Hub-instans.
Komponenter
Den övergripande arkitekturen består av följande komponenter:
Azure Stack Hub är ett tillägg till Azure som kan köra arbetsbelastningar i en lokal miljö genom att tillhandahålla Azure-tjänster i ditt datacenter. Gå till Översikt över Azure Stack Hub om du vill veta mer.
Azure Kubernetes Service Engine (AKS Engine) är motorn bakom det hanterade Kubernetes-tjänsterbjudandet Azure Kubernetes Service (AKS) som är tillgängligt i Azure idag. För Azure Stack Hub gör AKS Engine att vi kan distribuera, skala och uppgradera fullständigt utvalda, självhanterade Kubernetes-kluster med hjälp av Azure Stack Hubs IaaS-funktioner. Gå till Översikt över AKS-motorn om du vill veta mer.
Gå till Kända problem och begränsningar om du vill veta mer om skillnaderna mellan AKS-motorn i Azure och AKS-motorn på Azure Stack Hub.
Azure Virtual Network (VNet) används för att tillhandahålla nätverksinfrastrukturen på varje Azure Stack Hub för Virtual Machines (VM) som är värd för Kubernetes-klusterinfrastrukturen.
Azure Load Balancer används för Kubernetes API-slutpunkten och Nginx-ingresskontrollanten. Lastbalanseraren dirigerar extern trafik (till exempel Internet) till noder och virtuella datorer som erbjuder en specifik tjänst.
Azure Container Registry (ACR) används för att lagra privata Docker-avbildningar och Helm-diagram som distribueras till klustret. AKS-motorn kan autentisera med containerregistret med hjälp av en Azure AD identitet. Kubernetes kräver inte ACR. Du kan använda andra containerregister, till exempel Docker Hub.
Azure Repos är en uppsättning versionskontrollverktyg som du kan använda för att hantera din kod. Du kan också använda GitHub eller andra Git-baserade lagringsplatser. Gå till Översikt över Azure-lagringsplatser om du vill veta mer.
Azure Pipelines är en del av Azure DevOps Services och kör automatiserade versioner, tester och distributioner. Du kan också använda CI/CD-lösningar från tredje part, till exempel Jenkins. Gå till Översikt över Azure Pipeline om du vill veta mer.
Azure Monitor samlar in och lagrar mått och loggar, inklusive plattformsmått för Azure-tjänsterna i lösningen och programtelemetri. Använd dessa data för att övervaka programmet, konfigurera aviseringar och instrumentpaneler och utföra rotorsaksanalys av fel. Azure Monitor integreras med Kubernetes för att samla in mått från kontrollanter, noder och containrar, samt containerloggar och huvudnodloggar. Gå till Översikt över Azure Monitor om du vill veta mer.
Azure Traffic Manager är en DNS-baserad lastbalanserare för trafik som gör att du kan distribuera trafik optimalt till tjänster i olika Azure-regioner eller Azure Stack Hub-distributioner. Traffic Manager ger också hög tillgänglighet och svarstider. Programslutpunkterna måste vara tillgängliga utifrån. Det finns även andra lokala lösningar.
Kubernetes Ingress Controller exponerar HTTP(S) vägar till tjänster i ett Kubernetes-kluster. Nginx eller någon lämplig ingångskontrollant kan användas för detta ändamål.
Helm är en pakethanterare för Kubernetes-distribution, vilket gör det möjligt att paketera olika Kubernetes-objekt som Distributioner, Tjänster, Hemligheter i ett enda "diagram". Du kan publicera, distribuera, kontrollera versionshantering och uppdatera ett diagramobjekt. Azure Container Registry kan användas som lagringsplats för att lagra paketerade Helm-diagram.
Designöverväganden
Det här mönstret följer några överväganden på hög nivå som beskrivs mer detaljerat i nästa avsnitt i den här artikeln:
- Programmet använder Kubernetes-interna lösningar för att undvika leverantörslåsning.
- Programmet använder en arkitektur för mikrotjänster.
- Azure Stack Hub behöver inte inkommande men tillåter utgående Internetanslutning.
Dessa rekommenderade metoder gäller även för verkliga arbetsbelastningar och scenarier.
Skalbarhetsöverväganden
Skalbarhet är viktigt för att ge användarna konsekvent, tillförlitlig och högpresterande åtkomst till programmet.
Exempelscenariot omfattar skalbarhet på flera lager i programstacken. Här är en översikt på hög nivå över de olika lagren:
| Arkitekturnivå | Påverkar | Hur gör jag? |
|---|---|---|
| Program | Program | Horisontell skalning baserat på antalet poddar/repliker/Container Instances* |
| Kluster | Kubernetes-kluster | Antal noder (mellan 1 och 50), VM-SKU-storlekar och nodpooler (AKS-motorn på Azure Stack Hub stöder för närvarande endast en enda nodpool); använda AKS-motorns skalningskommando (manuellt) |
| Infrastruktur | Azure Stack Hub | Antal noder, kapacitet och skalningsenheter i en Azure Stack Hub-distribution |
* Använda Kubernetes Horizontal Pod Autoscaler (HPA); automatiserad måttbaserad skalning eller vertikal skalning genom att ändra storlek på containerinstanserna (cpu/minne).
Azure Stack Hub (infrastrukturnivå)
Azure Stack Hub-infrastrukturen är grunden för den här implementeringen eftersom Azure Stack Hub körs på fysisk maskinvara i ett datacenter. När du väljer hubbmaskinvara måste du göra val för CPU, minnesdensitet, lagringskonfiguration och antal servrar. Om du vill veta mer om skalbarheten i Azure Stack Hub kan du ta en titt på följande resurser:
- Översikt över kapacitetsplanering för Azure Stack Hub
- Lägga till ytterligare skalningsenhetsnoder i Azure Stack Hub
Kubernetes-kluster (klusternivå)
Själva Kubernetes-klustret består av och bygger på Azure (Stack) IaaS-komponenter, inklusive beräknings-, lagrings- och nätverksresurser. Kubernetes-lösningar omfattar huvud- och arbetsnoder som distribueras som virtuella datorer i Azure (och Azure Stack Hub).
- Kontrollplansnoder (master) tillhandahåller Kubernetes-kärntjänster och orkestrering av programarbetsbelastningar.
- Arbetsnoder (arbetare) kör dina programarbetsbelastningar.
När du väljer VM-storlekar för den första distributionen finns det flera saker att tänka på:
Kostnad – Tänk på den totala kostnaden per virtuell dator när du planerar dina arbetsnoder. Om dina programarbetsbelastningar till exempel kräver begränsade resurser bör du planera att distribuera virtuella datorer med mindre storlek. Azure Stack Hub, precis som Azure, faktureras normalt på förbrukningsbasis, så det är viktigt att storleksanpassa de virtuella datorerna för Kubernetes-roller på lämpligt sätt för att optimera förbrukningskostnaderna.
Skalbarhet – Skalbarhet för klustret uppnås genom att skala in och ut antalet huvud- och arbetsnoder, eller genom att lägga till ytterligare nodpooler (inte tillgängligt på Azure Stack Hub i dag). Skalning av klustret kan göras baserat på prestandadata som samlas in med Container Insights (Azure Monitor + Log Analytics).
Om programmet behöver fler (eller färre) resurser kan du skala ut (eller in) dina aktuella noder vågrätt (mellan 1 och 50 noder). Om du behöver fler än 50 noder kan du skapa ytterligare ett kluster i en separat prenumeration. Du kan inte skala upp de faktiska virtuella datorerna lodrätt till en annan VM-storlek utan att distribuera om klustret.
Skalningen görs manuellt med hjälp av den virtuella aks-motorns hjälpdator som användes för att distribuera Kubernetes-klustret från början. Mer information finns i Skala Kubernetes-kluster
Kvoter – Överväg de kvoter som du har konfigurerat när du planerar en AKS-distribution på din Azure Stack Hub. Kontrollera att varje prenumeration har rätt planer och kvoter konfigurerade. Prenumerationen måste hantera mängden beräkning, lagring och andra tjänster som behövs för dina kluster när de skalar ut.
Programarbetsbelastningar – Se begreppen kluster och arbetsbelastningar i Kubernetes-huvudbegreppen för Azure Kubernetes Service dokumentet. Den här artikeln hjälper dig att begränsa storleken på den virtuella datorn baserat på programmets beräknings- och minnesbehov.
Program (programnivå)
På programlagret använder vi Kubernetes Horizontal Pod Autoscaler (HPA). HPA kan öka eller minska antalet repliker (podd/Container Instances) i vår distribution baserat på olika mått (till exempel CPU-användning).
Ett annat alternativ är att skala containerinstanser lodrätt. Detta kan åstadkommas genom att ändra mängden processor och minne som begärs och är tillgängligt för en viss distribution. Mer information finns i Hantera resurser för containrar på kubernetes.io.
Nätverks- och anslutningsöverväganden
Nätverk och anslutning påverkar också de tre lager som nämnts tidigare för Kubernetes på Azure Stack Hub. I följande tabell visas lagren och vilka tjänster de innehåller:
| Skikt | Påverkar | Vad? |
|---|---|---|
| Program | Program | Hur är programmet tillgängligt? Kommer den att exponeras för Internet? |
| Kluster | Kubernetes-kluster | Kubernetes API, AKS Engine VM, Pulling container images (egress), Sending monitoring data and telemetry (egress) |
| Infrastruktur | Azure Stack Hub | Tillgänglighet för Azure Stack Hub-hanteringsslutpunkter som portalen och Azure Resource Manager slutpunkter. |
Program
För programlagret är det viktigaste att tänka på om programmet är exponerat och tillgängligt från Internet. Från ett Kubernetes-perspektiv innebär Internettillgänglighet att exponera en distribution eller podd med hjälp av en Kubernetes Service eller en ingresskontrollant.
Att exponera ett program med hjälp av en offentlig IP-adress via en Load Balancer eller en ingresskontrollant innebär inte att programmet nu är tillgängligt via Internet. Det är möjligt för Azure Stack Hub att ha en offentlig IP-adress som bara visas på det lokala intranätet – alla offentliga IP-adresser är inte riktigt Internetuppkopplade.
Föregående block tar hänsyn till inkommande trafik till programmet. Ett annat ämne som måste övervägas för en lyckad Kubernetes-distribution är utgående/utgående trafik. Här följer några användningsfall som kräver utgående trafik:
- Hämta containeravbildningar som lagras på DockerHub eller Azure Container Registry
- Hämtar Helm-diagram
- Generera Application Insights-data (eller andra övervakningsdata)
Vissa företagsmiljöer kan kräva användning av transparenta eller icke-transparenta proxyservrar. Dessa servrar kräver specifik konfiguration på olika komponenter i klustret. Dokumentationen om AKS-motorn innehåller olika detaljer om hur du hanterar nätverksproxyservrar. Mer information finns i AKS-motorn och proxyservrar
Slutligen måste trafik mellan kluster flöda mellan Azure Stack Hub-instanser. Exempeldistributionen består av enskilda Kubernetes-kluster som körs på enskilda Azure Stack Hub-instanser. Trafik mellan dem, till exempel replikeringstrafiken mellan två databaser, är "extern trafik". Extern trafik måste dirigeras via antingen en plats-till-plats-VPN eller offentliga IP-adresser för Azure Stack Hub för att ansluta Kubernetes på två Azure Stack Hub-instanser:
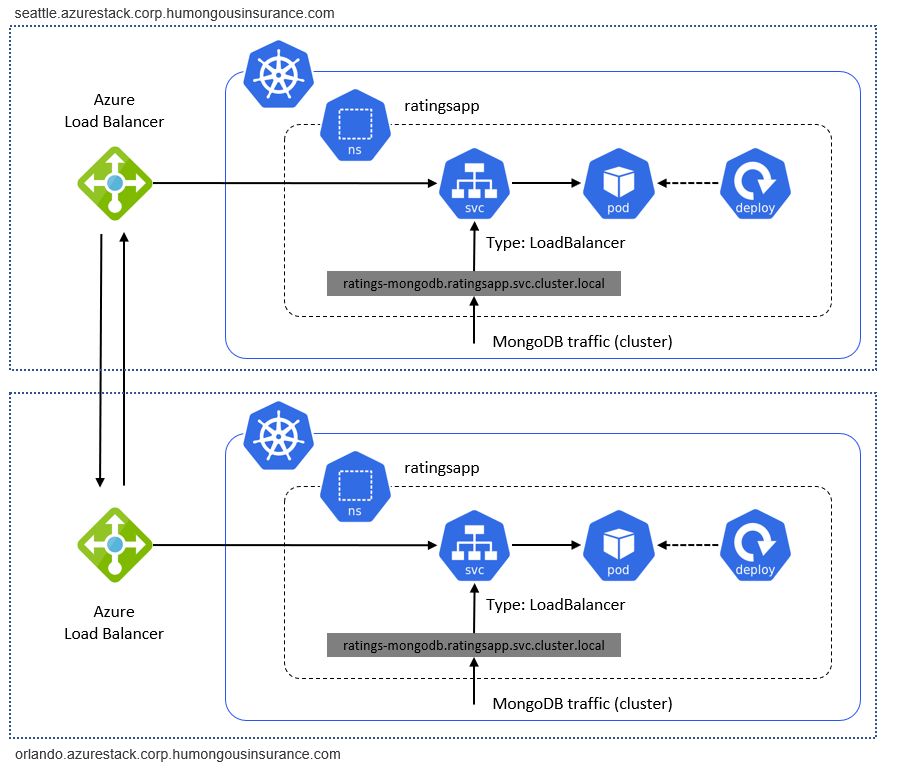
Kluster
Kubernetes-klustret behöver inte nödvändigtvis vara tillgängligt via Internet. Den relevanta delen är kubernetes-API:et som används för att driva ett kluster, till exempel med hjälp av kubectl. Kubernetes API-slutpunkten måste vara tillgänglig för alla som driver klustret eller distribuerar program och tjänster ovanpå det. Det här avsnittet beskrivs mer detaljerat ur ett DevOps-perspektiv i avsnittet Om distribution (CI/CD) nedan.
På klusternivå finns det också några överväganden kring utgående trafik:
- Noduppdateringar (för Ubuntu)
- Övervakningsdata (skickas till Azure LogAnalytics)
- Andra agenter som kräver utgående trafik (specifika för varje distribuerarmiljö)
Innan du distribuerar Kubernetes-klustret med hjälp av AKS Engine ska du planera för den slutliga nätverksdesignen. I stället för att skapa en dedikerad Virtual Network kan det vara mer effektivt att distribuera ett kluster till ett befintligt nätverk. Du kan till exempel använda en befintlig VPN-anslutning från plats till plats som redan har konfigurerats i din Azure Stack Hub-miljö.
Infrastruktur
Infrastruktur syftar på åtkomst till Azure Stack Hub-hanteringsslutpunkterna. Slutpunkterna omfattar klient- och administratörsportalerna samt Azure Resource Manager-administratörs- och klientslutpunkter. Dessa slutpunkter krävs för att köra Azure Stack Hub och dess kärntjänster.
Överväganden för data och lagring
Två instanser av vårt program kommer att distribueras på två enskilda Kubernetes-kluster över två Azure Stack Hub-instanser. Den här designen kräver att vi överväger hur data ska replikeras och synkroniseras mellan dem.
Med Azure har vi den inbyggda funktionen för att replikera lagring över flera regioner och zoner i molnet. Med Azure Stack Hub finns det för närvarande inga inbyggda sätt att replikera lagring över två olika Azure Stack Hub-instanser – de bildar två oberoende moln utan övergripande sätt att hantera dem som en uppsättning. Att planera för återhämtning av program som körs i Azure Stack Hub tvingar dig att överväga detta oberoende i din programdesign och distributioner.
I de flesta fall är lagringsreplikering inte nödvändigt för ett motståndskraftigt program med hög tillgänglighet som distribueras i AKS. Men du bör överväga oberoende lagring per Azure Stack Hub-instans i din programdesign. Om den här designen är ett problem eller en vägspärr för att distribuera lösningen på Azure Stack Hub finns det möjliga lösningar från Microsoft Partner som tillhandahåller bifogade filer för lagring. Med bifogade lagringsbilagor får du en lagringsreplikeringslösning i flera Azure Stack Hubs och Azure. Mer information finns i Partnerlösningar.
I vår arkitektur beaktades dessa lager:
Konfiguration
Konfigurationen omfattar konfigurationen av Azure Stack Hub, AKS Engine och själva Kubernetes-klustret. Konfigurationen bör automatiseras så mycket som möjligt och lagras som Infrastruktur som kod i ett Git-baserat versionskontrollsystem som Azure DevOps eller GitHub. De här inställningarna kan inte enkelt synkroniseras över flera distributioner. Därför rekommenderar vi att du lagrar och tillämpar konfigurationen utifrån och använder DevOps-pipelinen.
Program
Programmet ska lagras på en Git-baserad lagringsplats. När det finns en ny distribution, ändringar i programmet eller haveriberedskap kan den enkelt distribueras med hjälp av Azure Pipelines.
Data
Data är det viktigaste övervägandet i de flesta programutformningar. Programdata måste vara synkroniserade mellan de olika instanserna av programmet. Data behöver också en strategi för säkerhetskopiering och haveriberedskap om det uppstår ett avbrott.
Att uppnå den här designen beror mycket på teknikval. Här följer några lösningsexempel för att implementera en databas på ett sätt med hög tillgänglighet på Azure Stack Hub:
- Distribuera en SQL Server 2016-tillgänglighetsgrupp till Azure och Azure Stack Hub
- Distribuera en MongoDB-lösning med hög tillgänglighet till Azure och Azure Stack Hub
Att tänka på när du arbetar med data på flera platser är ett ännu mer komplext övervägande för en lösning med hög tillgänglighet och återhämtning. Tänk på att:
- Svarstid och nätverksanslutning mellan Azure Stack Hubs.
- Tillgänglighet för identiteter för tjänster och behörigheter. Varje Azure Stack Hub-instans integreras med en extern katalog. Under distributionen väljer du att använda antingen Azure Active Directory (Azure AD) eller Active Directory Federation Services (AD FS) (ADFS). Därför finns det potential att använda en enda identitet som kan interagera med flera oberoende Azure Stack Hub-instanser.
Affärskontinuitet och haveriberedskap
Affärskontinuitet och haveriberedskap (BCDR) är ett viktigt ämne i både Azure Stack Hub och Azure. Den största skillnaden är att i Azure Stack Hub måste operatören hantera hela BCDR-processen. I Azure hanteras delar av BCDR automatiskt av Microsoft.
BCDR påverkar samma områden som nämns i föregående avsnitt Data- och lagringsöverväganden:
- Infrastruktur/konfiguration
- Programtillgänglighet
- Programdata
Som vi nämnde i föregående avsnitt ansvarar dessa områden för Azure Stack Hub-operatören och kan variera mellan olika organisationer. Planera BCDR enligt dina tillgängliga verktyg och processer.
Infrastruktur och konfiguration
Det här avsnittet beskriver den fysiska och logiska infrastrukturen och konfigurationen av Azure Stack Hub. Den omfattar åtgärder i administratörs- och klientutrymmena.
Azure Stack Hub-operatören (eller administratören) ansvarar för underhållet av Azure Stack Hub-instanserna. Inkludera komponenter som nätverk, lagring, identitet och andra ämnen som ligger utanför omfånget för den här artikeln. Mer information om Azure Stack Hub-åtgärder finns i följande resurser:
- Återställa data i Azure Stack Hub med infrastruktursäkerhetskopieringstjänsten
- Aktivera säkerhetskopiering för Azure Stack Hub från administratörsportalen
- Återställa från oåterkallelig dataförlust
- Metodtips för Infrastructure Backup-tjänsten
Azure Stack Hub är den plattform och infrastrukturresurs där Kubernetes-program ska distribueras. Programägaren för Kubernetes-programmet är en användare av Azure Stack Hub, med åtkomst beviljad för att distribuera den programinfrastruktur som behövs för lösningen. Programinfrastruktur innebär i det här fallet Kubernetes-klustret, som distribueras med AKS-motorn och de omgivande tjänsterna. Dessa komponenter distribueras till Azure Stack Hub, som begränsas av ett Azure Stack Hub-erbjudande. Kontrollera att erbjudandet som accepteras av Kubernetes-programmets ägare har tillräcklig kapacitet (uttryckt i Azure Stack Hub-kvoter) för att distribuera hela lösningen. Som vi rekommenderade i föregående avsnitt bör programdistributionen automatiseras med hjälp av pipelines för infrastruktur som kod och distribution som Azure DevOps Azure Pipelines.
Mer information om erbjudanden och kvoter för Azure Stack Hub finns i Översikt över tjänster, planer, erbjudanden och prenumerationer i Azure Stack Hub
Det är viktigt att spara och lagra AKS Engine-konfigurationen på ett säkert sätt, inklusive dess utdata. Dessa filer innehåller konfidentiell information som används för att komma åt Kubernetes-klustret, så de måste skyddas från att exponeras för icke-administratörer.
Programtillgänglighet
Programmet bör inte förlita sig på säkerhetskopior av en distribuerad instans. Som standard distribuerar du om programmet helt efter infrastruktur som kod-mönster. Du kan till exempel distribuera om med Azure DevOps Azure Pipelines. BCDR-proceduren bör omfatta omdistribution av programmet till samma eller ett annat Kubernetes-kluster.
Programdata
Programdata är den viktiga delen för att minimera dataförlusten. I föregående avsnitt beskrevs tekniker för att replikera och synkronisera data mellan två (eller flera) instanser av programmet. Beroende på vilken databasinfrastruktur (MySQL, MongoDB, MSSQL eller andra) som används för att lagra data finns det olika tekniker för databastillgänglighet och säkerhetskopiering att välja mellan.
De rekommenderade sätten att uppnå integritet är att använda antingen:
- En intern säkerhetskopieringslösning för den specifika databasen.
- En säkerhetskopieringslösning som officiellt stöder säkerhetskopiering och återställning av den databastyp som används av ditt program.
Viktigt
Lagra inte dina säkerhetskopierade data på samma Azure Stack Hub-instans där dina programdata finns. Ett fullständigt avbrott i Azure Stack Hub-instansen skulle också äventyra dina säkerhetskopior.
Överväganden för tillgänglighet
Kubernetes på Azure Stack Hub som distribueras via AKS Engine är inte en hanterad tjänst. Det är en automatiserad distribution och konfiguration av ett Kubernetes-kluster med hjälp av Azure Infrastructure-as-a-Service (IaaS). Därför ger den samma tillgänglighet som den underliggande infrastrukturen.
Azure Stack Hub-infrastrukturen är redan motståndskraftig mot fel och tillhandahåller funktioner som tillgänglighetsuppsättningar för att distribuera komponenter över flera fel- och uppdateringsdomäner. Men den underliggande tekniken (redundansklustring) orsakar fortfarande viss stilleståndstid för virtuella datorer på en påverkad fysisk server, om det uppstår ett maskinvarufel.
Det är en bra idé att distribuera kubernetes-produktionsklustret samt arbetsbelastningen till två (eller flera) kluster. Dessa kluster ska finnas på olika platser eller datacenter och använda tekniker som Azure Traffic Manager för att dirigera användare baserat på klustrets svarstid eller baserat på geografi.
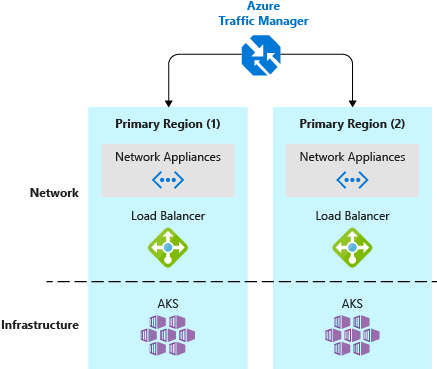
Kunder som har ett enda Kubernetes-kluster ansluter vanligtvis till tjänstens IP-adress eller DNS-namn för ett visst program. I en distribution med flera kluster bör kunderna ansluta till ett Traffic Manager DNS-namn som pekar på tjänsterna/ingressen för varje Kubernetes-kluster.
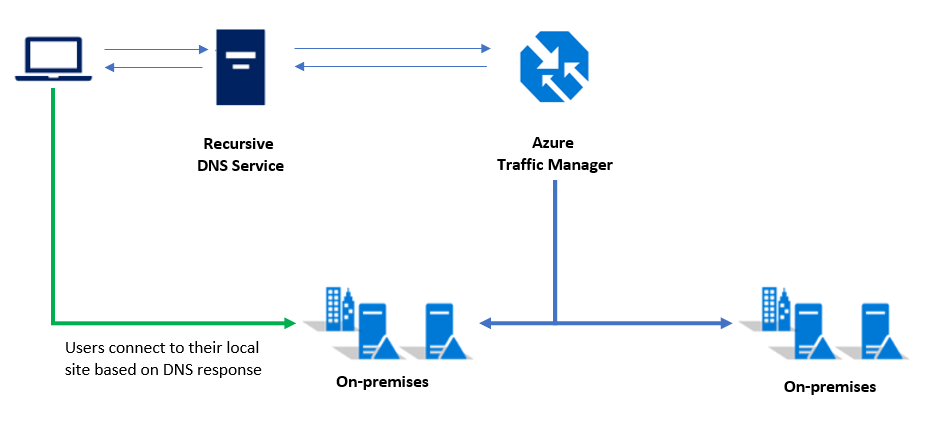
Anteckning
Det här mönstret är också bästa praxis för (hanterade) AKS-kluster i Azure.
Själva Kubernetes-klustret, som distribueras via AKS-motorn, bör bestå av minst tre huvudnoder och två arbetsnoder.
Identitets- och säkerhetsöverväganden
Identitet och säkerhet är viktiga ämnen. Särskilt när lösningen omfattar oberoende Azure Stack Hub-instanser. Både Kubernetes och Azure (inklusive Azure Stack Hub) har olika mekanismer för rollbaserad åtkomstkontroll (RBAC):
- Azure RBAC styr åtkomsten till resurser i Azure (och Azure Stack Hub), inklusive möjligheten att skapa nya Azure-resurser. Behörigheter kan tilldelas till användare, grupper eller tjänstens huvudnamn. (Ett huvudnamn för tjänsten är en säkerhetsidentitet som används av program.)
- Kubernetes RBAC styr behörigheter till Kubernetes-API:et. Att till exempel skapa poddar och lista poddar är åtgärder som kan auktoriseras (eller nekas) till en användare via RBAC. Om du vill tilldela Kubernetes-behörigheter till användare skapar du roller och rollbindningar.
Azure Stack Hub-identitet och RBAC
Azure Stack Hub innehåller två alternativ för identitetsprovider. Vilken leverantör du använder beror på miljön och om den körs i en ansluten eller frånkopplad miljö:
- Azure AD – kan bara användas i en ansluten miljö.
- ADFS till en traditionell Active Directory-skog – kan användas i både en ansluten eller frånkopplad miljö.
Identitetsprovidern hanterar användare och grupper, inklusive autentisering och auktorisering för åtkomst till resurser. Åtkomst kan beviljas till Azure Stack Hub-resurser som prenumerationer, resursgrupper och enskilda resurser som virtuella datorer eller lastbalanserare. Om du vill ha en konsekvent åtkomstmodell bör du överväga att använda samma grupper (antingen direkt eller kapslade) för alla Azure Stack Hubs. Här är ett konfigurationsexempel:
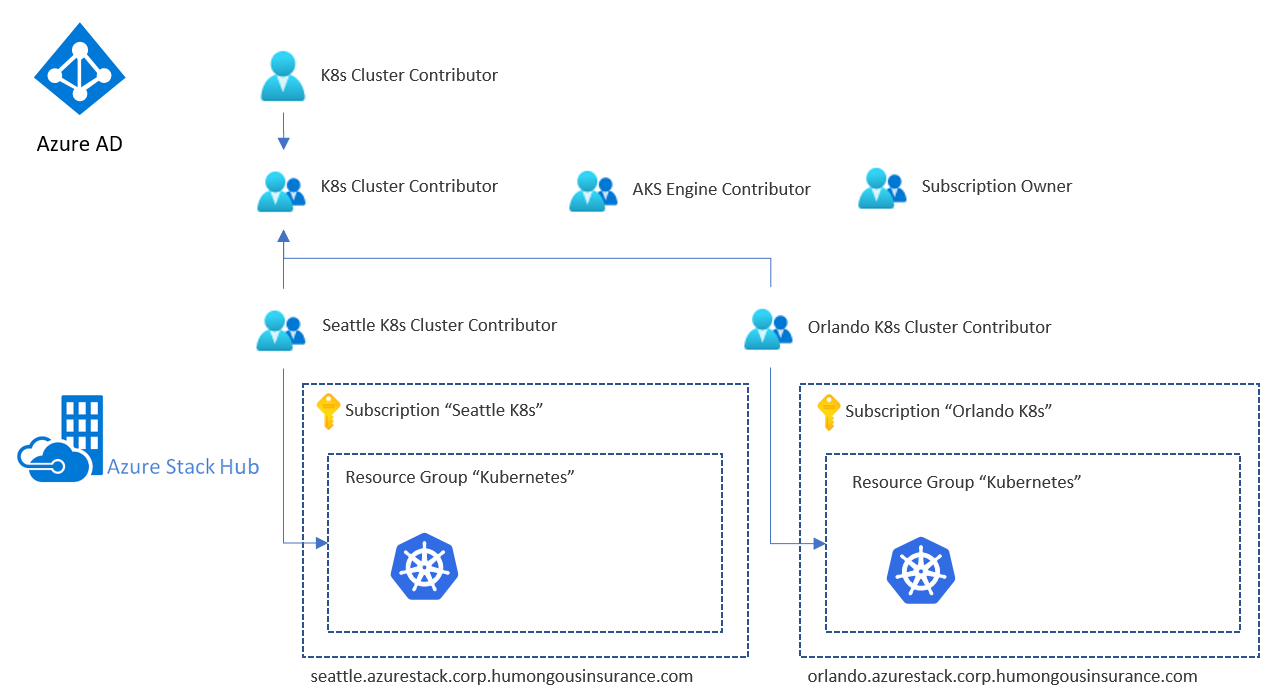
Exemplet innehåller en dedikerad grupp (med AAD eller ADFS) för ett specifikt syfte. Om du till exempel vill ge deltagarbehörigheter för resursgruppen som innehåller vår Kubernetes-klusterinfrastruktur på en specifik Azure Stack Hub-instans (här "Seattle K8s Cluster Contributor"). Dessa grupper kapslas sedan in i en övergripande grupp som innehåller "undergrupperna" för varje Azure Stack Hub.
Vår exempelanvändare har nu behörigheten "Deltagare" för båda resursgrupperna som innehåller hela uppsättningen Kubernetes-infrastrukturresurser. Användaren kommer att ha åtkomst till resurser på båda Azure Stack Hub-instanserna, eftersom instanserna delar samma identitetsprovider.
Viktigt
Dessa behörigheter påverkar endast Azure Stack Hub och vissa av de resurser som distribueras ovanpå den. En användare som har den här åtkomstnivån kan göra mycket skada, men inte komma åt de virtuella Kubernetes IaaS-datorerna eller Kubernetes-API:et utan ytterligare åtkomst till Kubernetes-distributionen.
Kubernetes-identitet och RBAC
Ett Kubernetes-kluster använder som standard inte samma identitetsprovider som den underläggande Azure Stack Hub. De virtuella datorer som är värdar för Kubernetes-klustret, huvudnoderna och arbetsnoderna använder den SSH-nyckel som anges under distributionen av klustret. Den här SSH-nyckeln krävs för att ansluta till dessa noder med hjälp av SSH.
Kubernetes-API:et (till exempel med hjälp kubectlav ) skyddas också av tjänstkonton, inklusive ett standardkonto för "klusteradministratörstjänst". Autentiseringsuppgifterna för det här tjänstkontot lagras ursprungligen .kube/config i filen på dina Kubernetes-huvudnoder.
Hantering av hemligheter och programautentiseringsuppgifter
Det finns flera alternativ för att lagra hemligheter som anslutningssträngar eller databasautentiseringsuppgifter, bland annat:
- Azure Key Vault
- Kubernetes-hemligheter
- Tredjepartslösningar som HashiCorp Vault (körs på Kubernetes)
Lagra inte hemligheter eller autentiseringsuppgifter i klartext i dina konfigurationsfiler, programkod eller i skript. Och lagra dem inte i ett versionskontrollsystem. I stället bör distributionsautomationen hämta hemligheterna efter behov.
Korrigera och uppdatera
PNU-processen (Patch and Update) i Azure Kubernetes Service automatiseras delvis. Kubernetes-versionsuppgraderingar utlöses manuellt, medan säkerhetsuppdateringar tillämpas automatiskt. Dessa uppdateringar kan omfatta os-säkerhetskorrigeringar eller kerneluppdateringar. AKS startar inte automatiskt om dessa Linux-noder för att slutföra uppdateringsprocessen.
PNU-processen för ett Kubernetes-kluster som distribueras med aks-motorn på Azure Stack Hub är ohanterad och är klusteroperatorns ansvar.
AKS Engine hjälper till med de två viktigaste uppgifterna:
- Uppgradera till en nyare Kubernetes- och basversion av OS-avbildning
- Uppgradera endast basoperativsystemavbildningen
Nyare os-basavbildningar innehåller de senaste säkerhetskorrigeringarna och kerneluppdateringarna för operativsystemet.
Mekanismen för obevakad uppgradering installerar automatiskt säkerhetsuppdateringar som släpps innan en ny version av basoperativsystemavbildningen är tillgänglig på Azure Stack Hub Marketplace. Obevakad uppgradering är aktiverat som standard och installerar säkerhetsuppdateringar automatiskt, men startar inte om Kubernetes-klusternoderna. Omstart av noderna kan automatiseras med hjälp av KUbernetes REboot Daemon (kured)) med öppen källkod. Kured söker efter Linux-noder som kräver en omstart och hanterar sedan automatiskt omplaneringen av poddar som körs och omstartsprocessen för noder.
Överväganden för distribution (CI/CD)
Azure och Azure Stack Hub exponerar samma REST-API:er för Azure Resource Manager. Dessa API:er hanteras på samma sätt som andra Azure-moln (Azure, Azure China 21Vianet Azure Government). Det kan finnas skillnader i API-versioner mellan moln, och Azure Stack Hub tillhandahåller endast en delmängd av tjänsterna. URI:n för hanteringsslutpunkten är också olika för varje moln och för varje instans av Azure Stack Hub.
Förutom de subtila skillnader som nämns ger Azure Resource Manager REST-API:er ett konsekvent sätt att interagera med både Azure och Azure Stack Hub. Samma uppsättning verktyg kan användas här som med andra Azure-moln. Du kan använda Azure DevOps, verktyg som Jenkins eller PowerShell för att distribuera och dirigera tjänster till Azure Stack Hub.
Överväganden
En av de största skillnaderna när det gäller Azure Stack Hub-distributioner är frågan om internettillgänglighet. Internettillgänglighet avgör om du vill välja en Microsoft värdbaserad eller en lokal byggagent för dina CI/CD-jobb.
En lokalt installerad agent kan köras ovanpå Azure Stack Hub (som en virtuell IaaS-dator) eller i ett nätverksundernät som har åtkomst till Azure Stack Hub. Gå till Azure Pipelines-agenter om du vill veta mer om skillnaderna.
Följande bild hjälper dig att avgöra om du behöver en lokalt installerad eller en Microsoft värdbaserad byggagent:
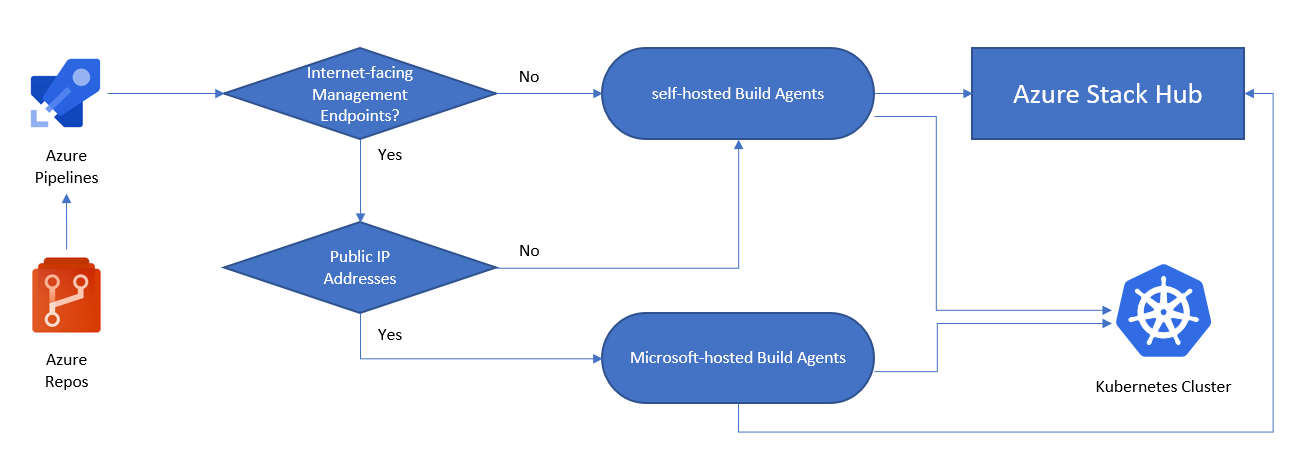
- Är Azure Stack Hub-hanteringsslutpunkterna tillgängliga via Internet?
- Ja: Vi kan använda Azure Pipelines med Microsoft värdbaserade agenter för att ansluta till Azure Stack Hub.
- Nej: Vi behöver lokalt installerade agenter som kan ansluta till Azure Stack Hubs hanteringsslutpunkter.
- Är vårt Kubernetes-kluster tillgängligt via Internet?
- Ja: Vi kan använda Azure Pipelines med Microsoft värdbaserade agenter för att interagera direkt med Kubernetes API-slutpunkt.
- Nej: Vi behöver lokalt installerade agenter som kan ansluta till Kubernetes-klustrets API-slutpunkt.
I scenarier där Azure Stack Hub-hanteringsslutpunkterna och Kubernetes-API:et är tillgängliga via Internet kan distributionen använda en Microsoft värdbaserad agent. Den här distributionen resulterar i en programarkitektur på följande sätt:

Om Azure Resource Manager-slutpunkter, Kubernetes API eller båda inte är direkt tillgängliga via Internet kan vi använda en lokal byggagent för att köra pipelinestegen. Den här designen behöver mindre anslutning och kan endast distribueras med lokal nätverksanslutning till Azure Resource Manager-slutpunkter och Kubernetes-API:et:

Anteckning
Hur är det med frånkopplade scenarier? I scenarier där antingen Azure Stack Hub eller Kubernetes eller båda inte har internetuppkopplade hanteringsslutpunkter är det fortfarande möjligt att använda Azure DevOps för dina distributioner. Du kan antingen använda en lokalt installerad agentpool (som är en DevOps-agent som körs lokalt eller på själva Azure Stack Hub) eller en helt lokal Azure DevOps Server lokalt. Den lokalt installerade agenten behöver bara utgående HTTPS-internetanslutning (TCP/443).
Mönstret kan använda ett Kubernetes-kluster (distribuerat och samordnat med AKS-motorn) på varje Azure Stack Hub-instans. Den innehåller ett program som består av en klientdel, en medelnivå, serverdelstjänster (till exempel MongoDB) och en nginx-baserad ingresskontrollant. I stället för att använda en databas som finns i K8-klustret kan du använda "externa datalager". Databasalternativen omfattar MySQL, SQL Server eller någon typ av databas som finns utanför Azure Stack Hub eller i IaaS. Konfigurationer som detta finns inte i omfånget här.
Partnerlösningar
Det finns Microsoft partnerlösningar som kan utöka funktionerna i Azure Stack Hub. Dessa lösningar har visat sig vara användbara vid distributioner av program som körs i Kubernetes-kluster.
Lagrings- och datalösningar
Som beskrivs i Överväganden för data och lagring har Azure Stack Hub för närvarande ingen intern lösning för att replikera lagring över flera instanser. Till skillnad från Azure finns inte möjligheten att replikera lagring över flera regioner. I Azure Stack Hub är varje instans ett eget distinkt moln. Lösningar är dock tillgängliga från Microsoft Partner som aktiverar lagringsreplikering i Azure Stack Hubs och Azure.
SKALBARHET
Scality levererar lagring i webbskala som har drivit digitala företag sedan 2009. Scality RING, vår programvarudefinierade lagring, förvandlar x86-standardservrar till en obegränsad lagringspool för alla typer av data – fil och objekt – i petabyteskala.
CLOUDIAN
Cloudian förenklar företagslagring med obegränsad skalbar lagring som konsoliderar massiva datamängder till en enda, lätthanterad miljö.
Nästa steg
Mer information om begrepp som introduceras i den här artikeln:
- Skalning mellan moln och geo-distribuerade appmönster i Azure Stack Hub.
- Arkitektur för mikrotjänster på Azure Kubernetes Service (AKS).
När du är redo att testa lösningsexemplet fortsätter du med distributionsguiden för Kubernetes-kluster med hög tillgänglighet. Distributionsguiden innehåller stegvisa instruktioner för att distribuera och testa dess komponenter.