Anteckning
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Följ anvisningarna i Skapa en modell i Syntex för att skapa en strukturerad eller frihandsfigur för dokumentbearbetning i ett innehållscenter. Eller följ anvisningarna i Skapa en modell på en lokal SharePoint-webbplats för att skapa modellen på en lokal webbplats. Använd sedan den här artikeln för att träna din modell.

Följ dessa steg om du vill träna en strukturerad eller frihandsmodell för dokumentbearbetning:
- Steg 1: Lägga till och analysera dokument
- Steg 2: Tagga fält och tabeller
- Steg 3: Träna och publicera din modell
- Steg 4: Använd din modell
Steg 1: Lägga till och analysera dokument
När du har skapat en strukturerad eller frihandsmodell för dokumentbearbetning öppnas sidan Välj information att extrahera . Här listar du all information som du vill att AI-modellen ska extrahera från dina dokument, till exempel Namn, Adress eller Belopp.
Obs!
När du letar efter exempelfiler att använda kan du läsa indatadokumentkrav och optimeringstips i dokumentbearbetningsmodellen.
Först definierar du de fält och tabeller som du vill lära modellen att extrahera på sidan Välj information för att extrahera. Detaljerade anvisningar finns i Definiera fält och tabeller för att extrahera.
Du kan skapa så många samlingar av dokumentlayouter som du vill att modellen ska bearbeta. Detaljerade anvisningar finns i Gruppera dokument efter samlingar.
När du har skapat dina samlingar och lagt till minst fem exempelfiler för var och en undersöker AI Builder på Syntex de uppladdade dokumenten för att identifiera fälten och tabellerna. Den här processen tar vanligtvis några sekunder. När analysen är klar kan du fortsätta med att tagga dokumenten.
Steg 2: Tagga fält och tabeller
Du måste tagga dokumenten för att lära modellen att förstå de fält och tabelldata som du vill extrahera. Detaljerade anvisningar finns i Tagga dokument.
Steg 3: Träna och publicera din modell
När du har skapat och tränat din modell är du redo att publicera den och använda den i SharePoint. Om du vill publicera modellen väljer du Publicera. Detaljerade anvisningar finns i Träna och publicera din modell för dokumentbearbetning.
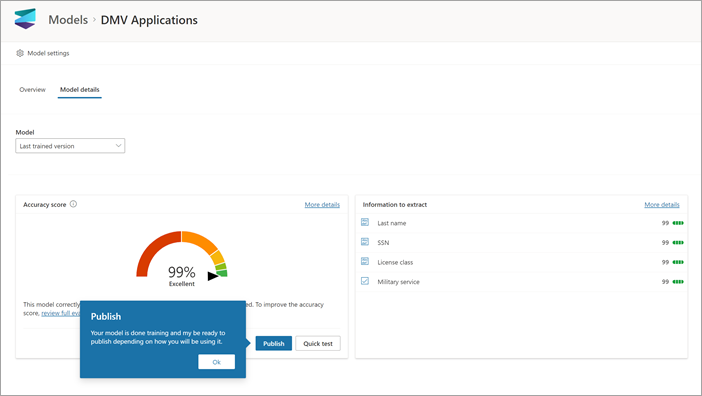
När modellen har publicerats går du till modellens startsida. Sedan har du möjlighet att tillämpa modellen på ett dokumentbibliotek.
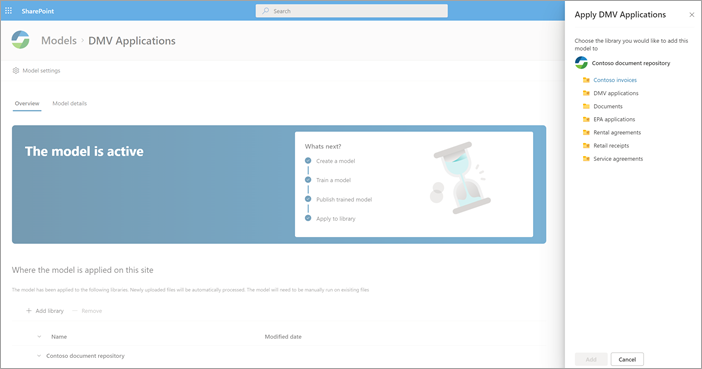
Steg 4: Använd din modell
I vyn för modellen för dokumentbibliotek kan du se att de fält som du valde nu visas som kolumner.
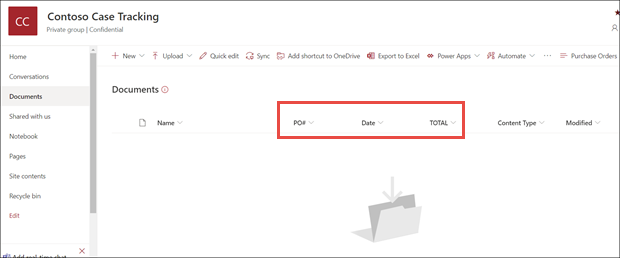
Notera att informationslänken bredvid Dokument påpekar att en modell för formulärbearbetning används i dokumentbiblioteket.
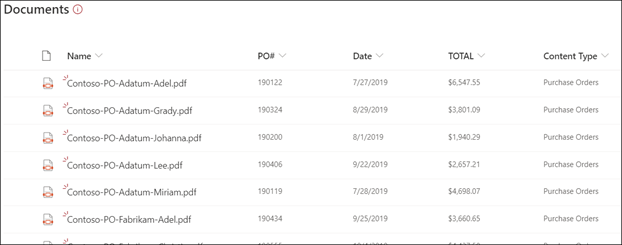
Ladda upp filer till ditt dokumentbibliotek. Alla filer som modellen identifierar som dess innehållstyp listar filerna i din vy och visar den extraherade data i kolumnerna.
Obs!
Om en strukturerad eller frihandsmodell för dokumentbearbetning och en ostrukturerad modell för dokumentbearbetning tillämpas på samma bibliotek klassificeras filen med hjälp av den ostrukturerade dokumentbearbetningsmodellen och eventuella tränade extraktorer för den modellen. Om det finns tomma kolumner som matchar modellen för dokumentbearbetning fylls kolumnerna i med de extraherade värdena.
Ange ett sidintervall för bearbetning
För den här modellen kan du ange att bearbeta ett intervall med sidor för en fil i stället för hela filen. Du gör detta under Modellinställningar i inställningen Sidintervall . Som standard är inställningen Sidintervall tom. Om inget sidintervall anges bearbetas hela dokumentet. Mer information finns i Ange ett sidintervall för att extrahera information från specifika sidor.
Fältet Klassificeringsdatum
När en anpassad modell tillämpas på ett dokumentbibliotek inkluderas fältet Klassificeringsdatum i biblioteksschemat. Som standard är det här fältet tomt. Men när dokument bearbetas och klassificeras av en modell uppdateras det här fältet med en datum/tid-stämpel för slutförande.
När en modell stämplas med klassificeringsdatumet kan du använda Skicka ett e-postmeddelande när Syntex har bearbetat ett filflöde för att meddela användarna att en ny fil har bearbetats och klassificerats av en modell i SharePoint-dokumentbiblioteket.
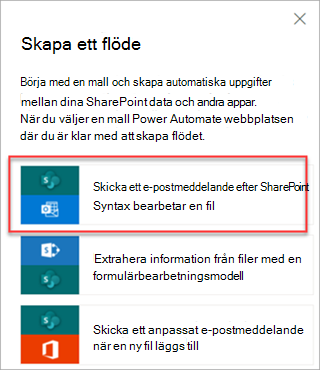
Så här kör du flödet:
Välj en fil och välj sedan Integrera>Power Automate>Skapa ett flöde.
På panelen Skapa ett flöde väljer du Skicka ett e-postmeddelande när Syntex har bearbetat en fil.
Använda flöden för att extrahera information
Viktigt
Informationen i det här avsnittet gäller inte för den senaste versionen av Syntex. Den lämnas endast som referens för de formulärbearbetningsmodeller som skapades i tidigare versioner. I den senaste versionen behöver du inte längre konfigurera flödena för att bearbeta befintliga filer.
Två flöden är tillgängliga för att bearbeta en vald fil eller batch med filer i ett bibliotek där en strukturerad eller frihandsmodell för dokumentbearbetning har tillämpats.
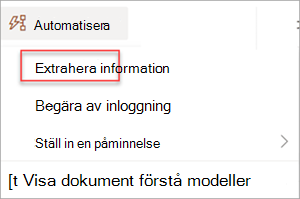
Extrahera information från en bild eller PDF-fil med en dokumentbearbetningsmodell – Använd för att extrahera text från en vald bild eller PDF-fil genom att köra en modell för dokumentbearbetning. Stöder en enskild markerad fil i taget och stöder endast PDF-filer och bildfiler (.png, .jpg och .jpeg). Om du vill köra flödet väljer du en fil och sedan Automatisera>extraheringsinformation.
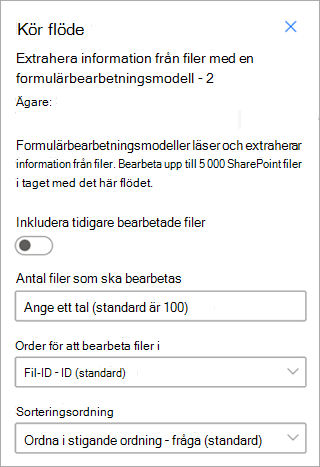
Extrahera information från filer med en modell för dokumentbearbetning – Använd med modeller för dokumentbearbetning för att läsa och extrahera information från en batch med filer. Bearbetar upp till 5 000 SharePoint-filer åt gången. När du kör det här flödet finns det vissa parametrar som du kan ange. Du kan:
- Välj om du vill inkludera tidigare bearbetade filer (standardinställningen är inte att inkludera tidigare bearbetade filer).
- Välj antalet filer som ska bearbetas (standardvärdet är 100 filer).
- Ange i vilken ordning filerna ska bearbetas (alternativen är efter fil-ID, filnamn, skapad tid eller senast ändrad tid).
- Ange hur du vill att ordningen ska sorteras (stigande eller fallande ordning).
Obs!
Extrahera information från en bild- eller PDF-fil med ett dokumentbearbetningsmodellflöde är automatiskt tillgängligt för ett bibliotek med en associerad dokumentbearbetningsmodell. Flödet Extrahera information från filer med en modell för dokumentbearbetning är en mall som måste läggas till i biblioteket om det behövs.