Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Du kan använda Python, ett programmeringsspråk som ofta används av statistiker, dataforskare och dataanalytiker, i Power BI Desktop Power Query-redigeraren. Med den här integreringen av Python i Power Query-redigeraren kan du utföra datarensning med Python och utföra avancerad dataformning och analys i datauppsättningar, inklusive slutförande av saknade data, förutsägelser och klustring, bara för att nämna några få. Python är ett kraftfullt språk och kan användas i Power Query-redigeraren för att förbereda datamodellen och skapa rapporter.
Förutsättningar
Du måste installera Python och Pandas innan du börjar.
Installera Python – Om du vill använda Python i Power BI Desktops Power Query-redigerare måste du installera Python på den lokala datorn. Du kan ladda ned och installera Python kostnadsfritt från många platser, inklusive den officiella Python-nedladdningssidan och Anaconda.
Installera Pandas – Om du vill använda Python med Power Query-redigeraren måste du också installera Pandas. Pandas används för att flytta data mellan Power BI och Python-miljön.
Använda Python med Power Query-redigeraren
Om du vill visa hur du använder Python i Power Query-redigeraren kan du ta det här exemplet från en börsdatauppsättning baserat på en CSV-fil som du kan ladda ned härifrån och följa med. Stegen för det här exemplet är följande procedur:
Läs först in dina data i Power BI Desktop. I det här exemplet läser du in filen EuStockMarkets_NA.csv och väljer Hämta data>Text/CSV från fliken Start i Power BI Desktop.
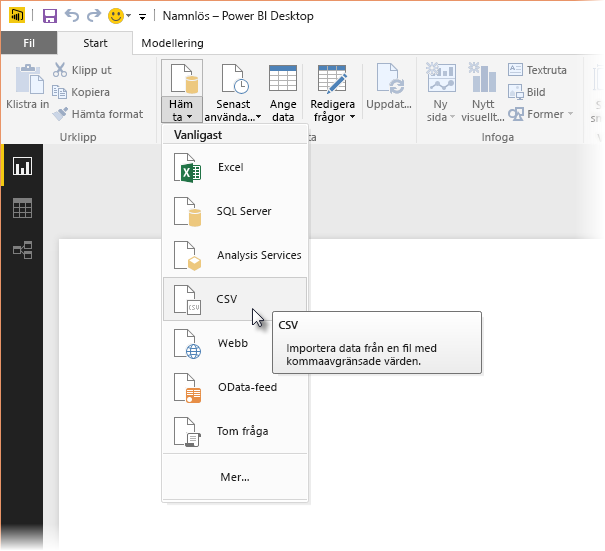
Välj filen och välj Öppna, så visas CSV i dialogrutan CSV-fil .
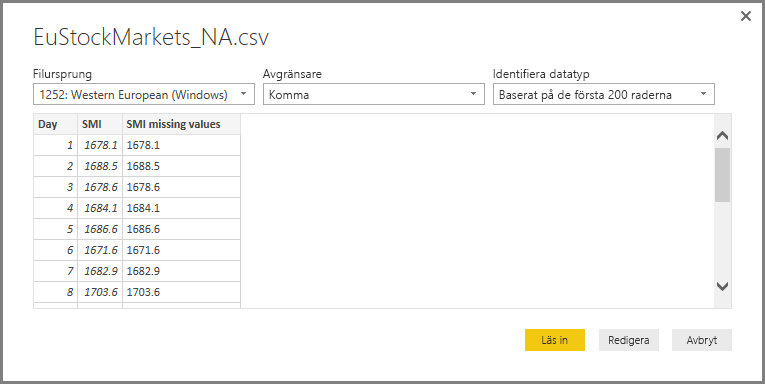
När data har lästs in visas de i fönstret Fält i Power BI Desktop.
Öppna Power Query-redigeraren genom att välja Transformera data från fliken Start i Power BI Desktop.
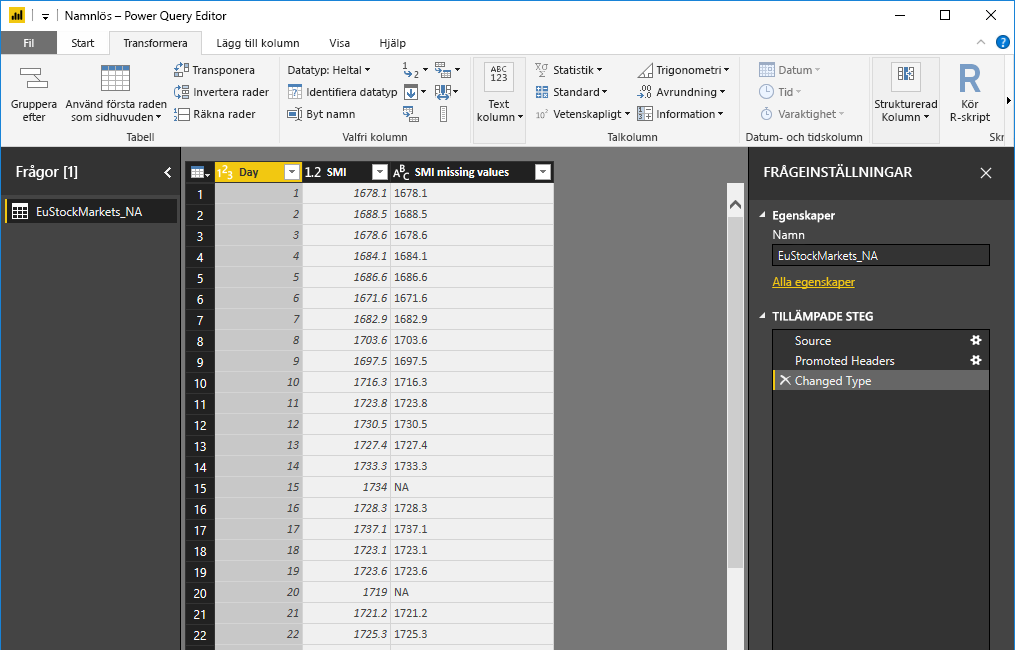
På fliken Transformera väljer du Kör Python-skript och Kör Python-skriptredigeraren visas som i nästa steg. Raderna 15 och 20 lider av saknade data, liksom andra rader som du inte kan se i följande bild. Följande steg visar hur Python slutför dessa rader åt dig.
I det här exemplet anger du följande skriptkod:
import pandas as pd completedData = dataset.fillna(method='backfill', inplace=False) dataset["completedValues"] = completedData["SMI missing values"]Anmärkning
Du måste ha pandas-biblioteket installerat i Python-miljön för att den tidigare skriptkoden ska fungera korrekt. Installera Pandas genom att köra följande kommando i Python-installationen:
pip install pandasNär koden placeras i dialogrutan Kör Python-skript ser den ut som i följande exempel:
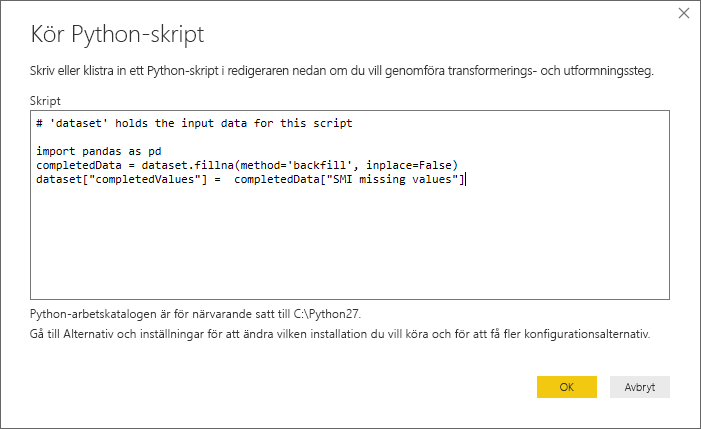
När du har valt OK visar Power Query-redigeraren en varning om datasekretess.
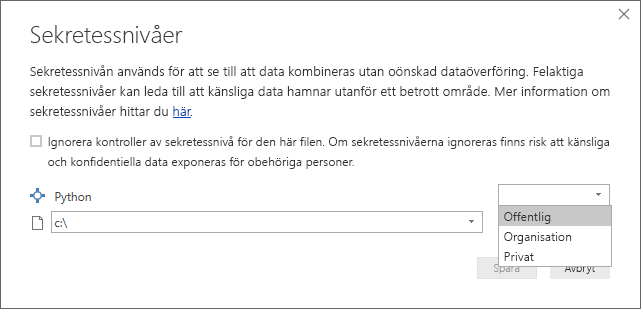
För att Python-skripten ska fungera korrekt i Power BI-tjänsten måste alla datakällor vara offentliga. Mer information om sekretessinställningar och deras konsekvenser finns i Sekretessnivåer.
Lägg märke till en ny kolumn i fönstret Fält med namnet completedValues. Observera att det finns några dataelement som saknas, till exempel på rad 15 och 18. Ta en titt på hur Python hanterar det i nästa avsnitt.
Med bara tre rader Python-skript fyllde Power Query-redigeraren i de saknade värdena med en förutsägelsemodell.
Skapa visuella objekt från Python-skriptdata
Nu kan vi skapa ett visuellt objekt för att se hur Python-skriptkoden med hjälp av Pandas-biblioteket har slutfört de saknade värdena, enligt följande bild:
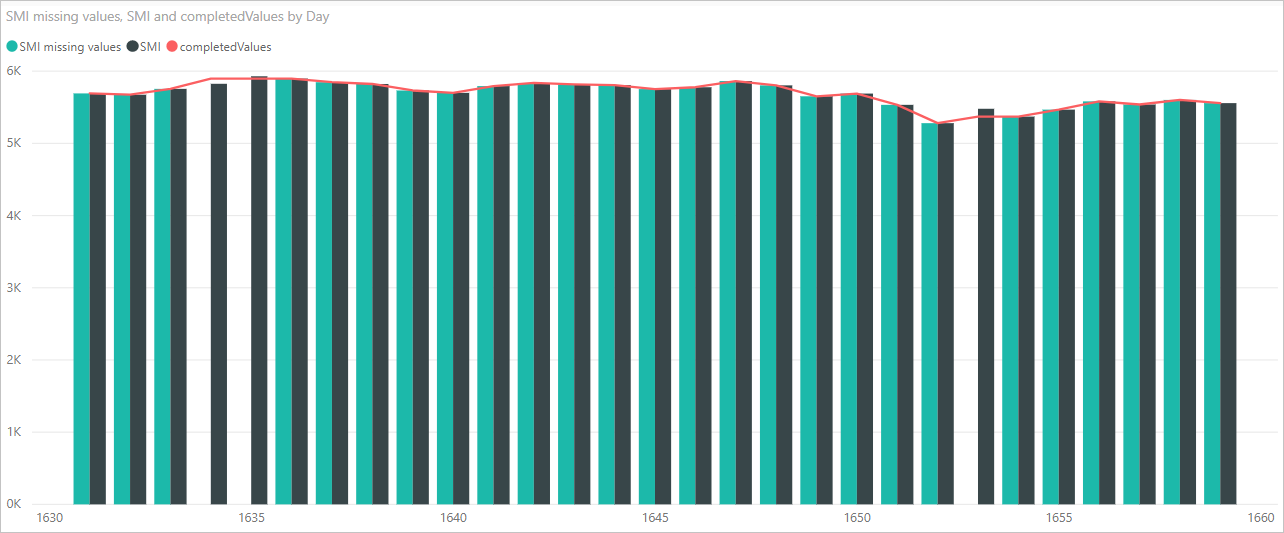
När det visuella objektet är klart och andra visuella objekt som du kanske vill skapa med Power BI Desktop kan du spara Power BI Desktop-filen . Power BI Desktop-filer sparas med filnamnstillägget .pbix . Använd sedan datamodellen, inklusive Python-skripten som ingår i den, i Power BI-tjänsten.
Anmärkning
Vill du se en slutförd .pbix-fil med de här stegen slutförda? Du har tur. Du kan ladda ned den färdiga Power BI Desktop-filen som används i de här exemplen här.
När du har laddat upp .pbix-filen till Power BI-tjänsten krävs ytterligare ett par steg för att göra det möjligt för data att uppdateras i tjänsten och för att göra det möjligt att uppdatera visuella objekt i tjänsten. Data behöver åtkomst till Python för att visuella objekt ska kunna uppdateras. De andra stegen är följande steg:
- Aktivera schemalagd uppdatering för datauppsättningen. Information om hur du aktiverar schemalagd uppdatering för arbetsboken som innehåller din datauppsättning med Python-skript finns i Konfigurera schemalagd uppdatering, som även innehåller information om personlig gateway.
- Installera den personliga gatewayen. Du behöver en personlig gateway installerad på datorn där filen finns och där Python är installerat. Power BI-tjänsten måste komma åt arbetsboken och återge uppdaterade grafik. Mer information finns i installera och konfigurera personlig gateway.
Överväganden och begränsningar
Det finns vissa begränsningar för frågor som innehåller Python-skript som skapats i Power Query-redigeraren:
Alla Inställningar för Python-datakällor måste vara offentliga och alla andra steg i en fråga som skapats i Power Query-redigeraren måste också vara offentliga. Om du vill komma åt datakällans inställningar väljer du > i Power BI Desktop.
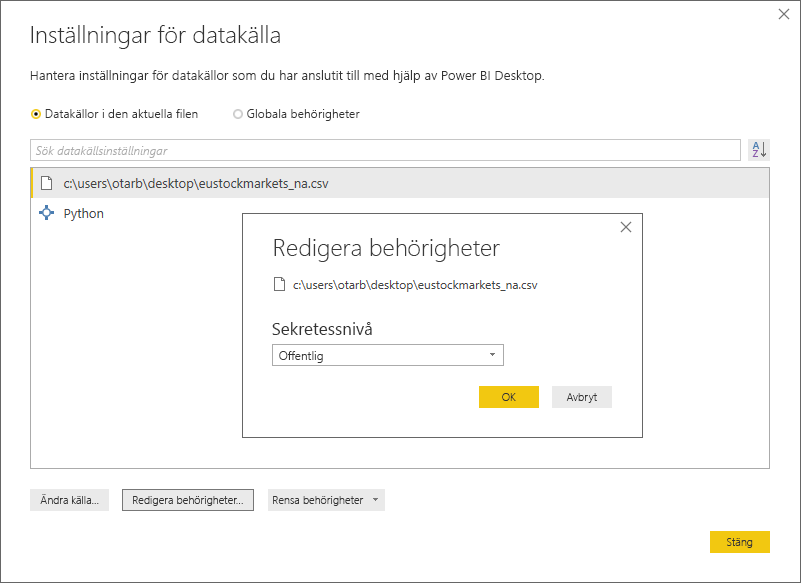
I dialogrutan Inställningar för datakälla väljer du datakällorna och sedan Redigera behörigheter... och ser till att sekretessnivån är inställd på Offentlig.
Om du vill aktivera schemalagd uppdatering av dina visuella Python-objekt eller datauppsättningar måste du aktivera Schemalagd uppdatering och ha en personlig gateway installerad på datorn som innehåller arbetsboken och Python-installationen. Mer information om båda finns i föregående avsnitt i den här artikeln, som innehåller länkar för mer information om var och en.
Kapslade tabeller, som är tabell med tabeller, stöds för närvarande inte.
Det finns alla möjliga saker du kan göra med Python och anpassade frågor, så utforska och forma dina data precis som du vill att de ska visas.