Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Sammansättningar i Power BI kan förbättra frågeprestanda jämfört med stora DirectQuery-semantiska modeller. Genom att använda aggregeringar cachelagras data på den aggregerade nivån i minnet. Du kan konfigurera aggregeringar i Power BI manuellt i datamodellen enligt beskrivningen i den här artikeln. För Premium-prenumerationer kan du aktivera funktionen Automatiska sammansättningar i modellinställningar för att skapa dem automatiskt.
Skapa sammansättningstabeller
Beroende på datakällans typ kan du skapa en sammansättningstabell i datakällan som en tabell eller vy, intern fråga. För bästa prestanda skapar du en sammansättningstabell som en importtabell som skapats i Power Query. Använd dialogrutan Hantera sammansättningar i Power BI Desktop för att definiera sammansättningar för sammansättningskolumner med sammanfattnings-, detaljtabell- och informationskolumnegenskaper.
Dimensionsdatakällor, till exempel informationslager och data marts, kan använda relationsbaserade aggregeringar. Hadoop-baserade stora datakällor baserar ofta aggregeringar på GroupBy-kolumner. I den här artikeln beskrivs vanliga skillnader i Power BI-datamodellering för varje typ av datakälla.
Hantera sammansättningar
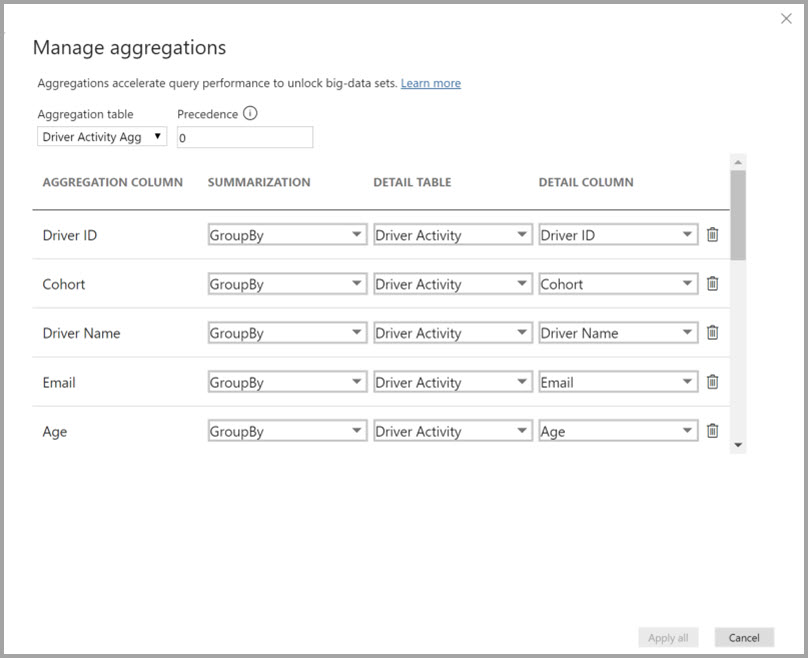
I fönstret Data i en Power BI Desktop-vy högerklickar du på tabellen sammansättningar och väljer sedan Hantera aggregeringar.
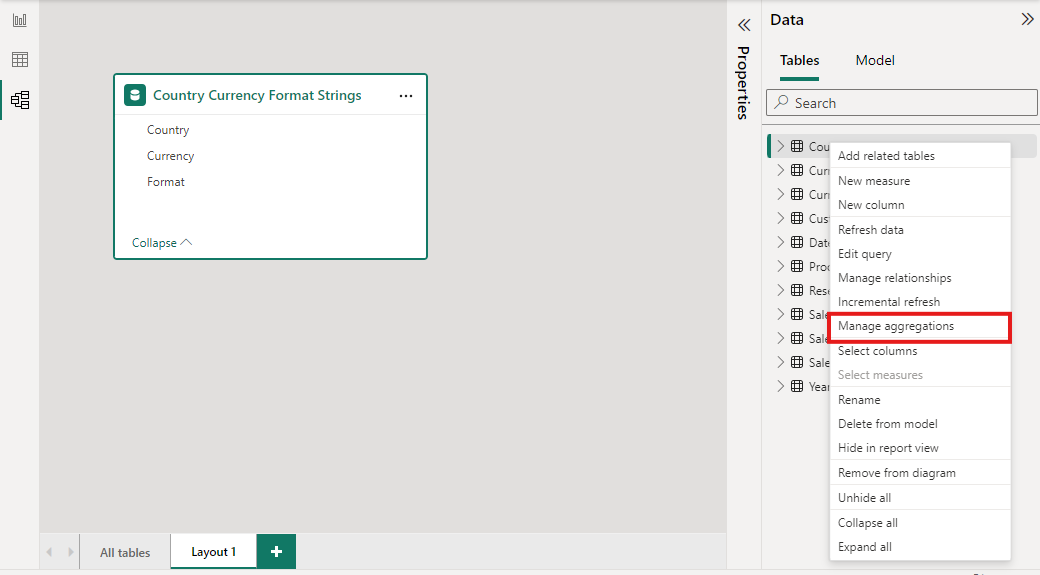
Dialogrutan Hantera sammansättningar visar en rad för varje kolumn i tabellen, där du kan ange aggregeringsbeteendet. I följande exempel omdirigeras frågor till tabellen Försäljningsinformation internt till sammansättningstabellen Sales Agg .
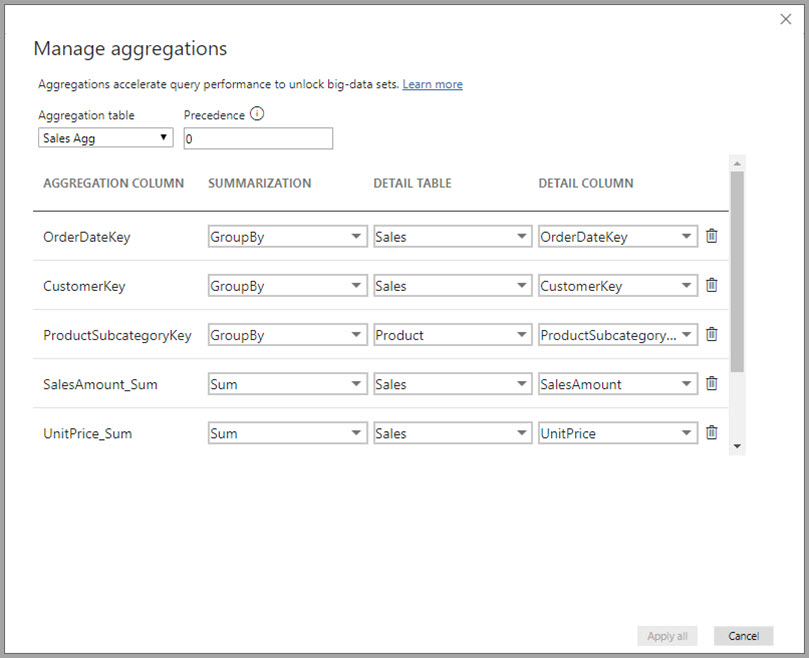
I det här relationsbaserade aggregeringsexemplet är GroupBy-posterna valfria. Förutom DISTINCTCOUNT påverkar de inte aggregeringsbeteendet och är främst för läsbarhet. Utan GroupBy-poster påverkas aggregeringarna fortfarande, baserat på relationerna. Det här beteendet skiljer sig från stordataexemplet senare i den här artikeln, där GroupBy-posterna krävs.
Valideringar
Dialogrutan Hantera aggregeringar framtvingar valideringar:
- Informationskolumnen måste ha samma datatyp som sammansättningskolumnen, förutom sammanfattningsfunktionerna Antal och Antal tabellrader. Tabellrader för antal och antal är endast tillgängliga för heltalssammansättningskolumner och kräver ingen matchande datatyp.
- Länkade aggregeringar som täcker tre eller flera tabeller tillåts inte. Sammansättningar i tabell A kan till exempel inte referera till en tabell B som har sammansättningar som refererar till en tabell C.
- Duplicerade sammansättningar, där två poster använder samma sammanfattningsfunktion och refererar till samma detaljtabell och detaljkolumn, tillåts inte.
- Informationstabellen måste använda DirectQuery-lagringsläge, inte Import.
- Gruppering efter en främmande nyckelkolumn som används av en inaktiv relation och som förlitar sig på funktionen USERELATIONSHIP för aggregeringsberäkningar stöds inte. Alternativt kan du använda funktionen TREATAS i stället för USERELATIONSHIP. När du använder TREATAS kontrollerar du att det inte finns några aktiva relationer mellan tabellerna. Aggregeringar kan fortfarande träffas när du använder TREATAS med den här konfigurationen.
- Sammansättningar baserade på GroupBy-kolumner kan använda relationer mellan sammansättningstabeller, men redigering av relationer mellan aggregeringstabeller stöds inte i Power BI Desktop. Om det behövs kan du skapa relationer mellan sammansättningstabeller med hjälp av ett verktyg från tredje part eller en skriptlösning via XMLA-slutpunkter (XMLA).
De flesta valideringar tillämpas genom att inaktivera listrutevärden och visa förklarande text i verktygstipset.
Sammansättningstabeller är dolda
Användare med skrivskyddad åtkomst till modellen kan inte ställa frågor till aggregeringstabeller. Skrivskyddad åtkomst undviker säkerhetsproblem när den används med säkerhet på radnivå (RLS). Konsumenter och frågor refererar till detaljtabellen, inte sammansättningstabellen, och behöver inte känna till sammansättningstabellen.
Därför döljs sammansättningstabeller från rapportvyn . Om tabellen inte redan är dold, anger dialogrutan Hantera sammansättningar att den är dold när du väljer Tillämpa alla.
Lagringslägen
Aggregeringsfunktionen fungerar med lagringslägen på tabellnivå. Power BI-tabeller kan använda DirectQuery-, Import- eller Dual Storage-lägen. DirectQuery skickar frågor direkt till serverdelen, medan Import cachelagrar data i minnet och skickar frågor till cachelagrade data. Alla Power BI-import- och icke-flerdimensionella DirectQuery-datakällor fungerar med aggregeringar.
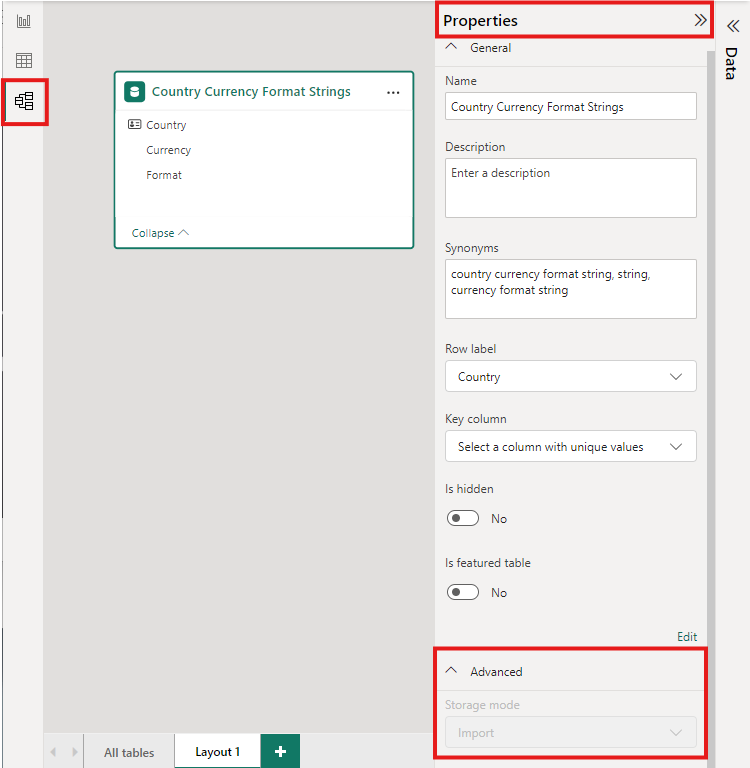
Om du vill ange lagringsläget för en aggregerad tabell till Importera för att påskynda frågor väljer du den aggregerade tabellen i Power BI Desktop-modellvyn . I fönstret Egenskaper expanderar du Avancerat, listrutan under Lagringsläge och väljer Importera. När du har angett lagringsläget till Importera kan du inte ändra det igen.
Mer information om lagringslägen för tabeller finns i Hantera lagringsläge i Power BI Desktop.
RLS för sammansättningar
För att fungera korrekt för sammansättningar bör RLS-uttryck filtrera både sammansättningstabellen och detaljtabellen.
I följande exempel fungerar RLS-uttrycket i tabellen Geografi för sammansättningar, eftersom Geografi finns på filtreringssidan av relationer till tabellen Sales och tabellen Sales Agg . Frågor som använder aggregeringstabellen och frågor som inte gör det, har båda RLS framgångsrikt tillämpat.
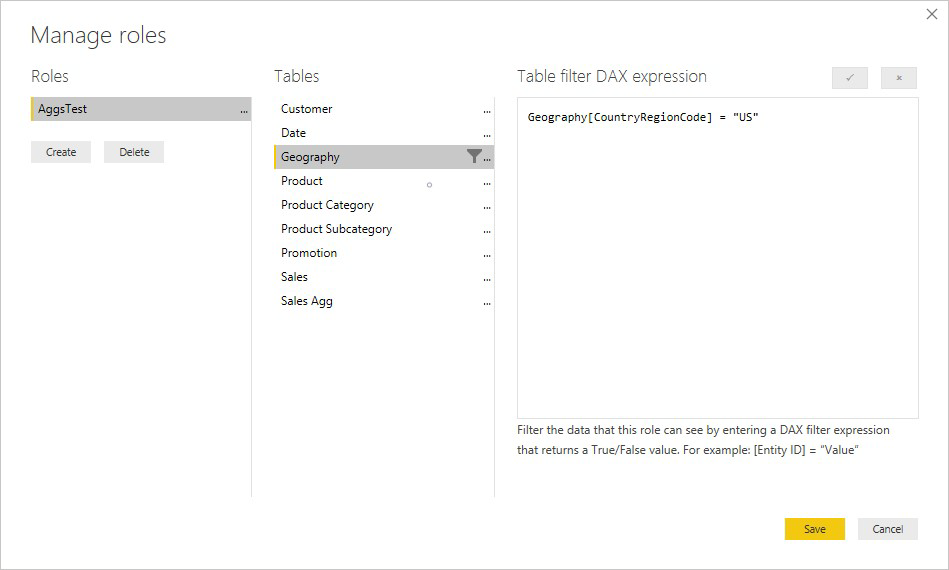
Ett RLS-uttryck i tabellen Produkt filtrerar endast tabellen Sales i detalj, inte den aggregerade Sales Agg-tabellen . Eftersom sammansättningstabellen är en annan representation av data i detaljtabellen är det osäkert att besvara frågor från sammansättningstabellen om RLS-filtret inte kan tillämpas. Det rekommenderas inte att endast filtrera informationstabellen eftersom användarfrågor från den här rollen inte drar nytta av aggregeringsträffar.
Ett RLS-uttryck som endast filtrerar sammansättningstabellen Sales Agg och inte tabellen Sales detail ( Försäljningsinformation ) tillåts inte.
För aggregeringar baserade på GroupBy-kolumner kan ett RLS-uttryck som tillämpas på detaljtabellen filtrera sammansättningstabellen, eftersom alla GroupBy-kolumner i sammansättningstabellen omfattas av detaljtabellen. Å andra sidan kan ett RLS-filter i sammansättningstabellen inte filtrera detaljtabellen, så det är inte tillåtet.
Sammansättning baserat på relationer
Dimensionsmodeller använder vanligtvis aggregeringar baserat på relationer. Power BI-modeller från informationslager och datalager liknar stjärn- och snöflingescheman, med relationer mellan dimensionstabeller och faktatabeller.
I följande exempel hämtar modellen data från en enda datakälla. Tabeller använder DirectQuery-lagringsläge. Tabellen Sales fact innehåller miljarder rader. Om du ställer in lagringsläget för Försäljning till Import för cachning skulle det förbruka mycket minne och resurser.
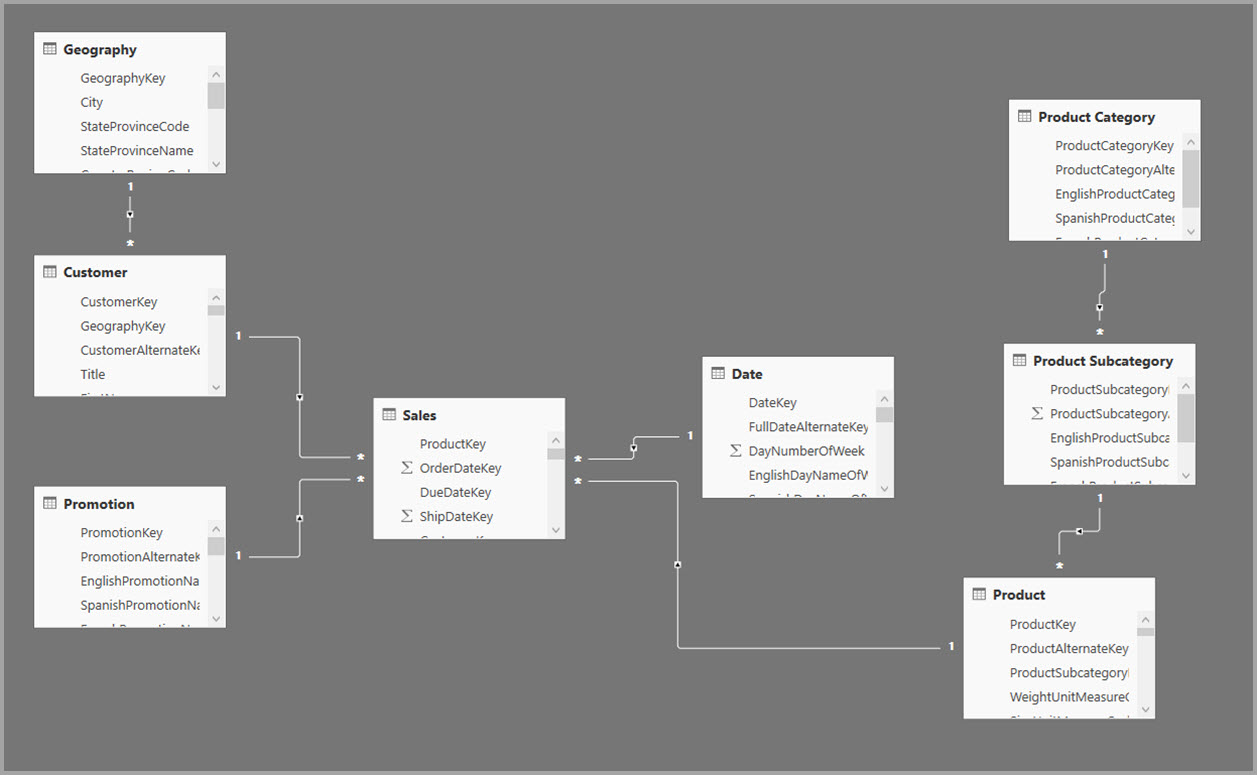
Skapa i stället aggregeringstabellen Sales Agg . I tabellen Sales Agg är antalet rader lika med summan av SalesAmount grupperat efter CustomerKey, DateKey och ProductSubcategoryKey. Tabellen Sales Agg har högre kornighet än Försäljning, så i stället för miljarder kan den innehålla miljontals rader, vilket är enklare att hantera.
Om följande dimensionstabeller används oftast för frågor med högt affärsvärde kan de filtrera Sales Agg med hjälp av en-till-många- eller många-till-en-relationer .
- Geografi
- Kund
- Datum
- Produktunderkategori
- Produktkategori
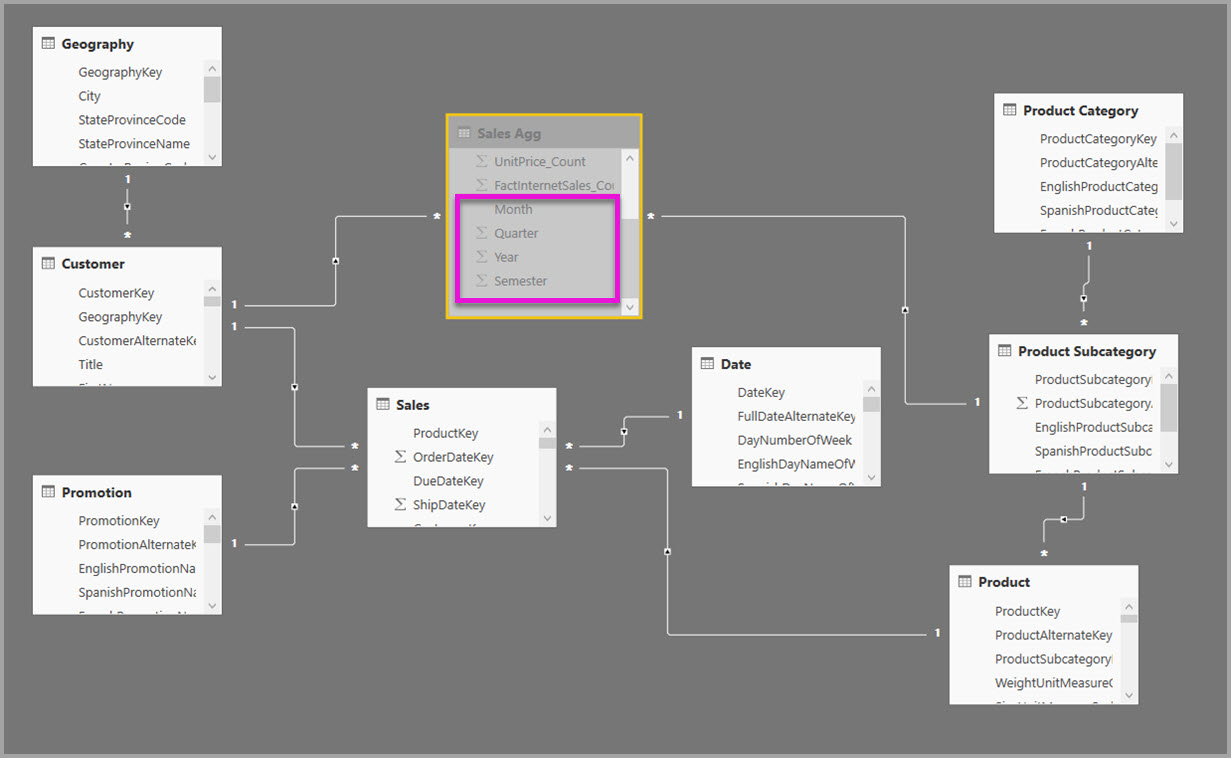
Följande bild visar den här modellen.

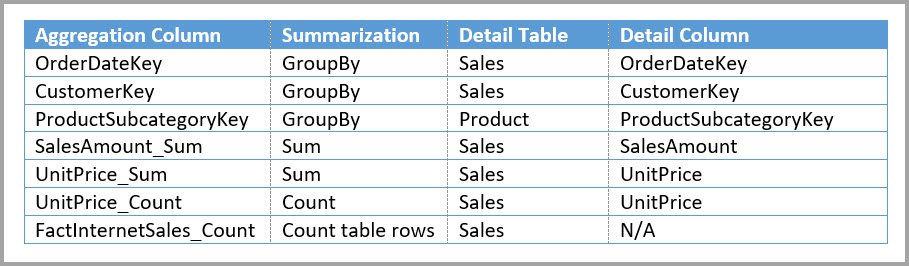
I följande tabell visas aggregeringarna för tabellen Sales Agg .
Anmärkning
Tabellen Sales Agg, precis som vilken tabell som helst, har flexibiliteten att läsas in på olika sätt. Du kan utföra aggregeringen i källdatabasen med hjälp av ETL- eller ELT-processer eller med hjälp av M-uttrycket för tabellen. Den aggregerade tabellen kan använda importlagringsläge, med eller utan inkrementell uppdatering för semantiska modeller. Eller så kan den använda DirectQuery och optimeras för snabba frågor med hjälp av columnstore-index. Den här flexibiliteten möjliggör balanserade arkitekturer som kan sprida frågebelastning för att undvika flaskhalsar.
Om du ändrar lagringsläget för den aggregerade tabellen Sales Agg till Import öppnas en dialogruta där det står att de relaterade dimensionstabellerna kan ställas in på lagringsläge Dubbla.
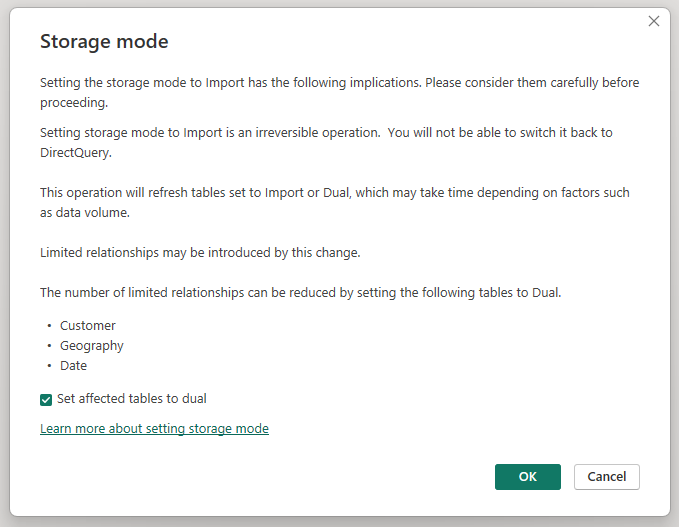
Om du ställer in de relaterade dimensionstabellerna på Dubbla kan de fungera som antingen Import eller DirectQuery, beroende på underfrågan. I exemplet:
- Frågor som aggregerar mått från tabellen Sales Agg i importläge och grupperar efter attribut från de relaterade dubbla tabellerna returnerar resultat från minnesintern cache.
- Frågor som aggregerar mått från tabellen DirectQuery Sales och grupperar efter attribut från de relaterade dubbla tabellerna returnerar resultat i DirectQuery-läge. Frågelogik, inklusive GroupBy-åtgärden, skickas till källdatabasen.
Mer information om läget Dubbla lagringsläge finns i Hantera lagringsläge i Power BI Desktop.
Regelbundna kontra begränsade relationer
Aggregatträffar baserade på relationer kräver normala relationer.
Vanliga relationer omfattar följande kombinationer av lagringsläge, där båda tabellerna kommer från en enda källa:
| Tabell på många sidor | Tabell på 1-sidan |
|---|---|
| Dubbel | Dubbel |
| Importera | Importera eller dubbla |
| DirectQuery | DirectQuery eller Dubbel |
Det enda fallet där en relation mellan källor är vanlig är om båda tabellerna är inställda på Import. Många-till-många-relationer är alltid begränsade.
För sammansättningsträffar mellan källor som inte är beroende av relationer, se Sammansättningar baserade på GroupBy-kolumner.
Exempel på relationsbaserad sammansättningsfråga
I följande fråga används aggregeringen eftersom kolumnerna i tabellen Date har den kornighet som kan använda aggregeringen. Kolumnen SalesAmount använder sumaggregering .

Följande fråga använder inte aggregeringen. Trots att frågan begär summan av SalesAmount, utför den en GroupBy-åtgärd på en kolumn i tabellen Produkt, som inte har en granularitet som kan använda aggregeringen. Om du ser relationerna i modellen kan en produktunderkategori ha flera produktrader . Frågan kan inte avgöra vilken produkt som ska aggregeras till. I det här fallet återgår frågan till DirectQuery och skickar en SQL-fråga till datakällan.

Aggregationer är inte bara för enkla beräkningar som utför en direkt summa. Komplexa beräkningar kan också vara till nytta. Konceptuellt delas en komplex beräkning upp i underfrågor för varje SUM, MIN, MAX och COUNT. Varje underfråga utvärderas för att avgöra om den kan använda aggregeringen. Den här logiken gäller inte i alla fall på grund av frågeplansoptimering, men i allmänhet bör den gälla. I följande exempel används aggregeringen:

Funktionen COUNTROWS kan dra nytta av aggregeringar. Följande fråga använder aggregeringen eftersom det finns en sammansättning av antal tabellrader som definierats för tabellen Försäljning .

Funktionen AVERAGE kan dra nytta av aggregeringar. Följande fråga använder aggregeringen eftersom AVERAGE internt viks till en SUMMA dividerat med ett ANTAL. Eftersom kolumnen UnitPrice har aggregeringar definierade för både SUM och COUNT används aggregeringen.

I vissa fall kan funktionen DISTINCTCOUNT dra nytta av aggregeringar. Följande fråga använder aggregeringen eftersom det finns en GroupBy-post för CustomerKey, som upprätthåller customerkey-distinktiteten i sammansättningstabellen. Den här tekniken kan fortfarande nå prestandatröskelvärdet där mer än 2 till 5 miljoner distinkta värden kan påverka frågeprestanda. Det kan dock vara användbart i scenarier där det finns miljarder rader i detaljtabellen, men 2 till 5 miljoner distinkta värden i kolumnen. I det här fallet kan DISTINCTCOUNT utföra uppgiften snabbare än att skanna tabellen med miljarder rader, även om den cachats i minnet.

Data Analysis Expressions (DAX) tidsintelligensfunktioner är medvetna om aggregering. Följande fråga använder aggregering eftersom funktionen DATESYTD genererar en tabell med CalendarDay-värden, och aggregeringstabellen har en detaljeringsgrad som täcks av grupperingskolumnerna i Date-tabellen. Det här är ett exempel på ett tabellvärdefilter till funktionen CALCULATE, som kan fungera med aggregeringar.

Sammansättning baserat på GroupBy-kolumner
Hadoop-baserade stordatamodeller har andra egenskaper än dimensionsmodeller. För att undvika kopplingar mellan stora tabeller använder stordatamodeller ofta inte relationer, utan avnormaliserar dimensionsattribut till faktatabeller. Du kan låsa upp sådana stordatamodeller för interaktiv analys med hjälp av aggregeringar baserade på GroupBy-kolumner.
Följande tabell innehåller den numeriska kolumnen Förflyttning som ska aggregeras. Alla andra kolumner är attribut som ska grupperas efter. Tabellen innehåller IoT-data och ett stort antal rader. Lagringsläget är DirectQuery. Frågor om datakällan som aggregeras över hela modellen är långsamma på grund av den stora volymen.
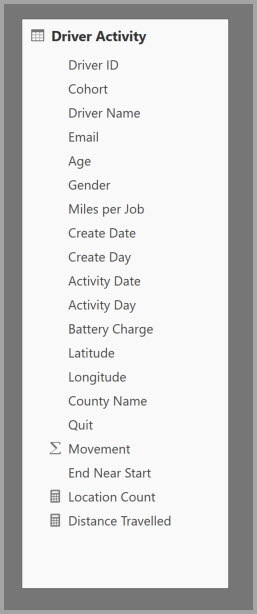
Om du vill aktivera interaktiv analys av den här modellen lägger du till en aggregeringstabell som grupperas efter de flesta attributen, men exkluderar attribut med hög kardinalitet som longitud och latitud. Den här metoden minskar dramatiskt antalet rader och är tillräckligt liten för att bekvämt passa in i en minnesintern cache.
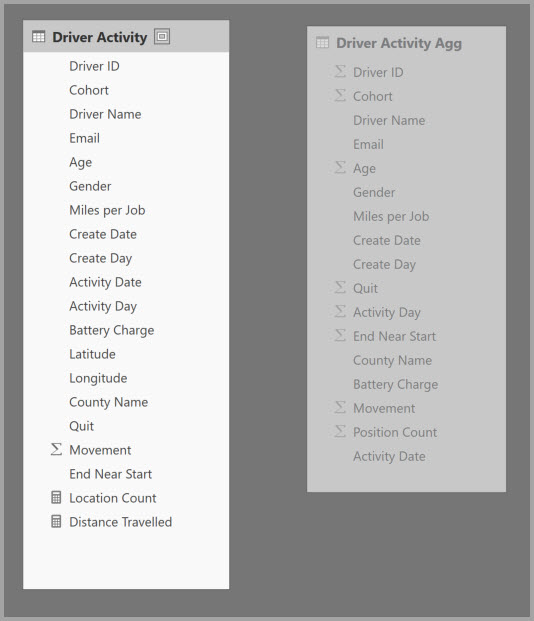
Definiera aggregeringsmappningarna för tabellen Driver Activity Agg i dialogrutan Hantera sammansättningar .
I sammansättningar baserade på GroupBy-kolumner är GroupBy-posterna inte valfria. Utan dem drabbas inte aggregeringarna. Det här beteendet skiljer sig från att använda aggregeringar baserat på relationer, där GroupBy-posterna är valfria.
I följande tabell visas aggregeringarna för tabellen Driver Activity Agg .
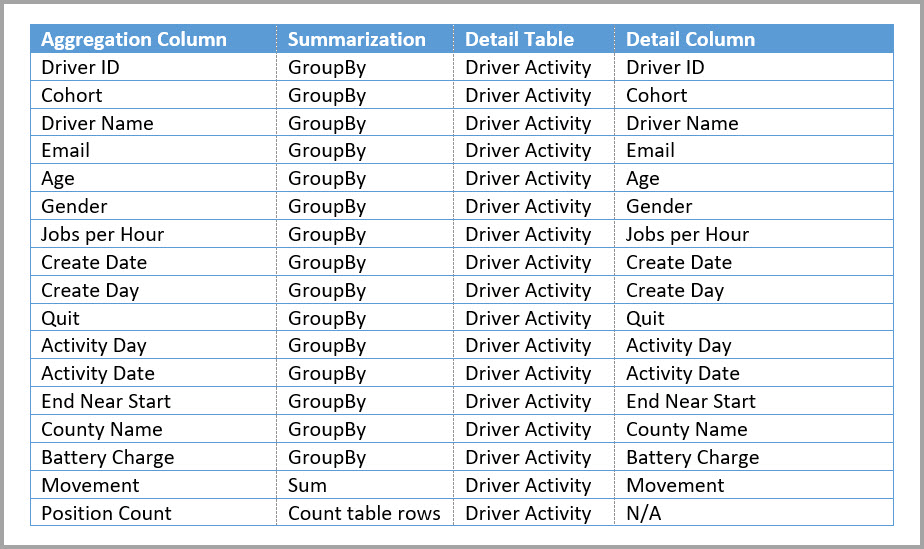
Ange lagringsläget för den aggregerade tabellen Driver Activity Agg till Import.
Exempel på GroupBy-sammansättningsfråga
Följande fråga använder aggregeringen eftersom kolumnen Aktivitetsdatum omfattas av sammansättningstabellen. Funktionen COUNTROWS använder aggregering av räknade tabellrader.

Särskilt för modeller som innehåller filterattribut i faktatabeller är det en bra idé att använda sammansättningar av antal tabellrader . Power BI kan skicka frågor till modellen med COUNTROWS i fall där det inte uttryckligen begärs av användaren. Filterdialogrutan visar till exempel antalet rader för varje värde.
Kombinerade aggregeringstekniker
Du kan kombinera teknikerna för relationerna och GroupBy-kolumnerna för aggregeringar. Sammansättningar baserade på relationer kan kräva att de avnormaliserade dimensionstabellerna delas upp i flera tabeller. Om det här kravet är kostsamt eller opraktiskt för vissa dimensionstabeller kan du replikera nödvändiga attribut i sammansättningstabellen för dessa dimensioner och använda relationer för andra.
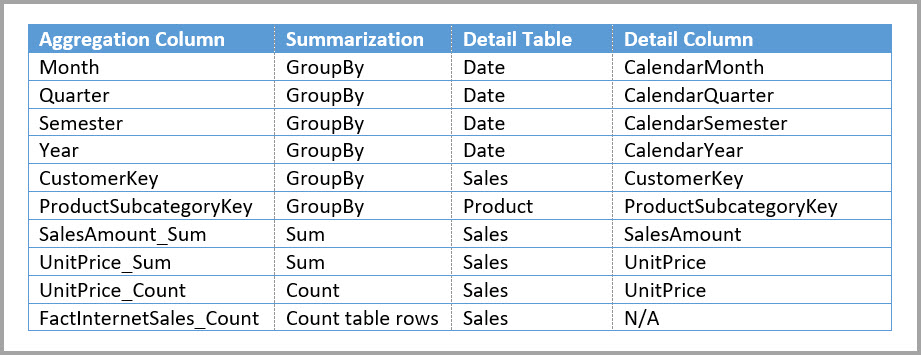
Följande modell replikerar till exempel Månad, Kvartal, Termin och År i tabellen Sales Agg . Det finns ingen relation mellan Sales Agg och tabellen Date, men det finns relationer till kund- och produktunderkategori. Lagringsläget för Sales Agg är Import.
I följande tabell visas de poster som angetts i dialogrutan Hantera aggregeringar för tabellen Sales Agg. GroupBy-posterna där Datum är detaljtabellen är obligatoriska för att använda sammansättningar för frågor som grupperas efter datumattributen . Precis som i föregående exempel påverkar GroupBy-posterna för CustomerKey och ProductSubcategoryKey inte aggregeringsanvändningen, förutom DISTINCTCOUNT, på grund av förekomsten av relationer.
Exempel på kombinerad sammansättningsfråga
Följande fråga använder aggregeringen eftersom sammansättningstabellen omfattar CalendarMonth och du kan komma åt CategoryName via en-till-många-relationer. Frågan använder SUM-aggregeringen för SalesAmount.

Följande fråga använder inte aggregeringen eftersom sammansättningstabellen inte täcker CalendarDay.

Följande tidsinformationsfråga använder inte aggregeringen eftersom funktionen DATESYTD genererar en tabell med CalendarDay-värden och sammansättningstabellen inte täcker CalendarDay.

Sammansättningsprioritet
Med sammansättningspriorens kan en enskild underfråga överväga flera sammansättningstabeller.
Följande exempel är en sammansatt modell som innehåller flera källor:
- Tabellen Driver Activity DirectQuery innehåller över en biljon rader med IoT-data som kommer från ett system med stora data. Det hanterar drillthrough-förfrågningar för att kunna granska enskilda IoT-avläsningar i kontrollerade filterkontexter.
- Tabellen Driver Activity Agg är en mellanliggande sammansättningstabell i DirectQuery-läge. Den innehåller över en miljard rader i Azure Synapse Analytics (tidigare SQL Data Warehouse) och optimeras vid källan med hjälp av kolumnlagringsindex.
- Tabellen Import av drivrutinsaktivitet Agg2 har hög detaljeringsgrad eftersom group-by-attributen är få och har låg kardinalitet. Antalet rader kan vara så lågt som tusentals, så att det enkelt kan passa in i en minnesintern cache. De här attributen används av en högpresterande instrumentpanel, så frågor som refererar till dem bör vara så snabba som möjligt.
Anmärkning
DirectQuery-sammansättningstabeller som använder en annan datakälla än detaljtabellen stöds endast om sammansättningstabellen kommer från en SQL Server-, Azure SQL- eller Azure Synapse Analytics-källa (tidigare SQL Data Warehouse).
Den här modellens minnesfotavtryck är relativt litet, men det låser upp en enorm modell. Den representerar en balanserad arkitektur eftersom den sprider frågebelastningen mellan komponenterna i arkitekturen och använder dem baserat på deras styrkor.
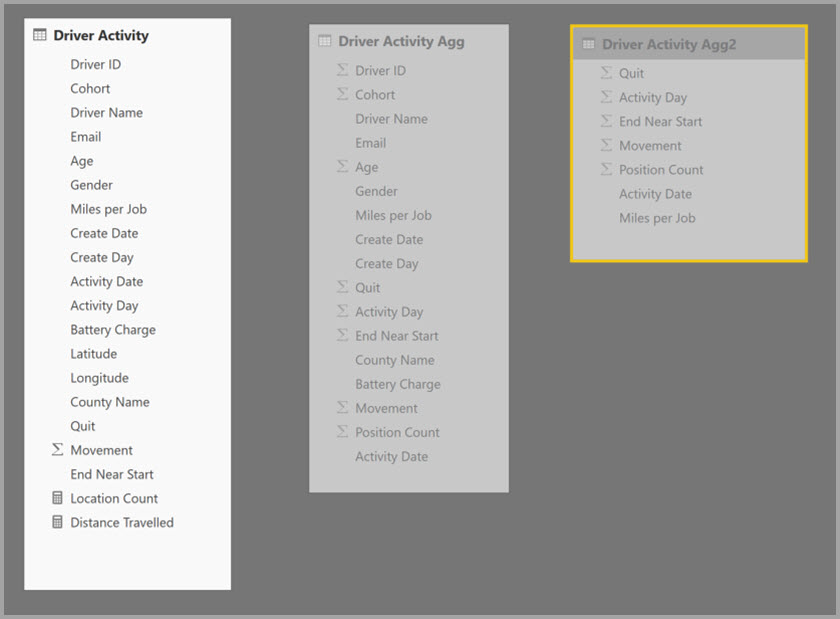
Dialogrutan Hanterade sammansättningar för Driver Activity Agg2 anger fältet Prioritet till 10, vilket är högre än för Driver Activity Agg. Den högre prioritetsinställningen innebär att frågor som använder sammansättningar överväger Driver Activity Agg2 först. Underfrågor som inte har den kornighet som Driver Activity Agg2 kan hantera bör överväga Driver Activity Agg i stället. Detaljerade frågor som inte kan besvaras av någon av sammansättningstabellerna kan dirigeras till Drivrutinsaktivitet.
Tabellen som anges i kolumnen Detaljtabell är Drivrutinsaktivitet, inte Drivrutinsaktivitets-Agg, eftersom länkade aggregeringar inte tillåts.
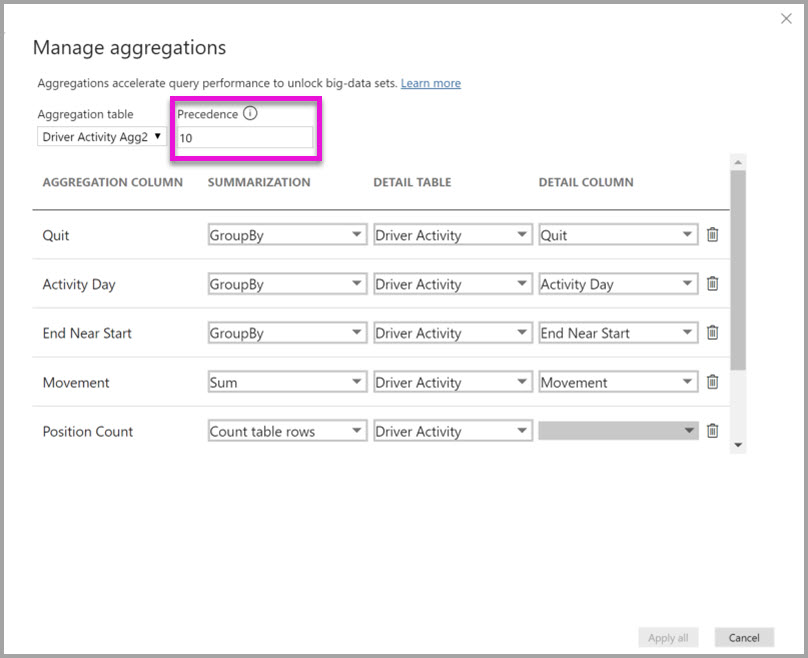
I följande tabell visas aggregeringarna för tabellen Driver Activity Agg2 .
Identifiera om frågor träffar eller missar aggregeringar
SQL Profiler kan identifiera om frågor kommer från minnesintern cachelagringsmotor, eller om DirectQuery skickar dem till datakällan. Du kan använda samma process för att identifiera om aggregeringar används. Mer information finns i Frågor som träffar eller missar cacheminnet.
SQL Profiler tillhandahåller även den Query Processing\Aggregate Table Rewrite Query utökade händelsen.
Följande JSON-kodfragment visar ett exempel på utdata från händelsen när en aggregering används.
- matchingResult visar att underfrågan använder en aggregering.
- dataRequest visar GroupBy-kolumnerna och aggregerade kolumner som underfrågan använder.
- mappning visar kolumnerna i sammansättningstabellen som är mappade till.

Håll cacheminnen synkroniserade
Sammansättningar som kombinerar DirectQuery-, Import- och Dual Storage-lägen kan returnera olika data om inte minnesintern cachen förblir synkroniserad med källdata. Exekvering av frågor försöker till exempel inte maskera dataproblem genom att filtrera DirectQuery-resultat för att matcha cachelagrade värden. Du kan behöva hantera dessa problem vid källan. Prestandaoptimeringar bör aldrig äventyra din förmåga att uppfylla affärskraven. Du måste förstå dina dataflöden och utforma dem i enlighet med detta.
Överväganden och begränsningar
Sammansättningar stöder inte dynamiska M-frågeparametrar.
Från och med augusti 2022 ignorerar Power BI aggregeringstabeller i importläge med enkel inloggning (SSO) aktiverade datakällor på grund av möjliga säkerhetsrisker. För att säkerställa optimal frågeprestanda vid användning av aggregeringar bör du inaktivera enkel inloggning för dessa datakällor.
Gemenskap
Power BI har en livlig community där MVP:er, BI-proffs och kollegor delar expertis i diskussionsgrupper, videor, bloggar med mera. När du lär dig mer om aggregeringar bör du kolla in följande resurser: