Not
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Att utforma en dimensionsmodell är en av de vanligaste uppgifterna du kan göra med ett dataflöde. I den här artikeln beskrivs några av metodtipsen för att skapa en dimensionsmodell med hjälp av ett dataflöde.
Förbereda dataflöden
En av de viktigaste punkterna i alla dataintegreringssystem är att minska antalet läsningar från källdriftssystemet. I den traditionella dataintegreringsarkitekturen görs den här minskningen genom att skapa en ny databas som kallas mellanlagringsdatabas. Syftet med mellanlagringsdatabasen är att läsa in data as-is från datakällan till mellanlagringsdatabasen enligt ett regelbundet schema.
Resten av dataintegreringen använder sedan mellanlagringsdatabasen som källa för ytterligare transformering och konverterar den till den dimensionella modellstrukturen.
Vi rekommenderar att du följer samma metod med hjälp av dataflöden. Skapa en uppsättning dataflöden som ansvarar för att bara läsa in data as-is från källsystemet (och endast för de tabeller du behöver). Resultatet lagras sedan i dataflödets lagringsstruktur (antingen Azure Data Lake Storage eller Dataverse). Den här ändringen säkerställer att läsåtgärden från källsystemet är minimal.
Därefter kan du skapa andra dataflöden som hämtar sina data från mellanlagringsdataflöden. Fördelarna med den här metoden är:
- Minska antalet läsåtgärder från källsystemet och minska belastningen på källsystemet som ett resultat.
- Minska belastningen på datagatewayer om en lokal datakälla används.
- Att ha en mellanliggande kopia av data i avstämningssyfte, om källsystemdata ändras.
- Gör transformeringsdataflödena källoberoende.
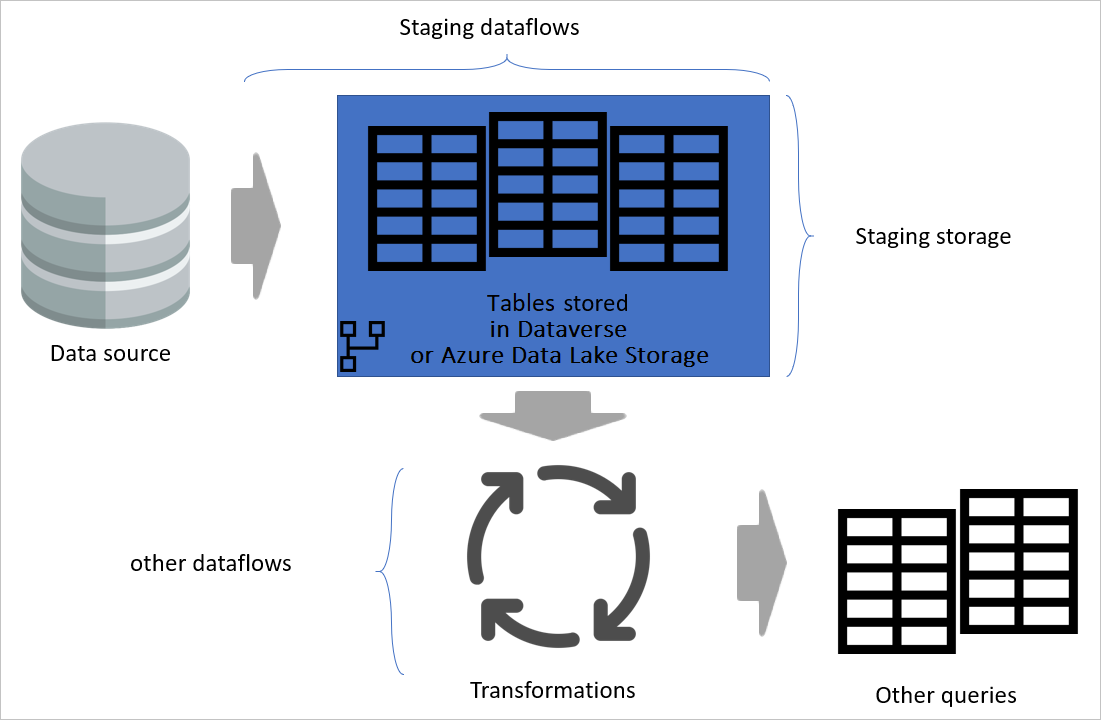
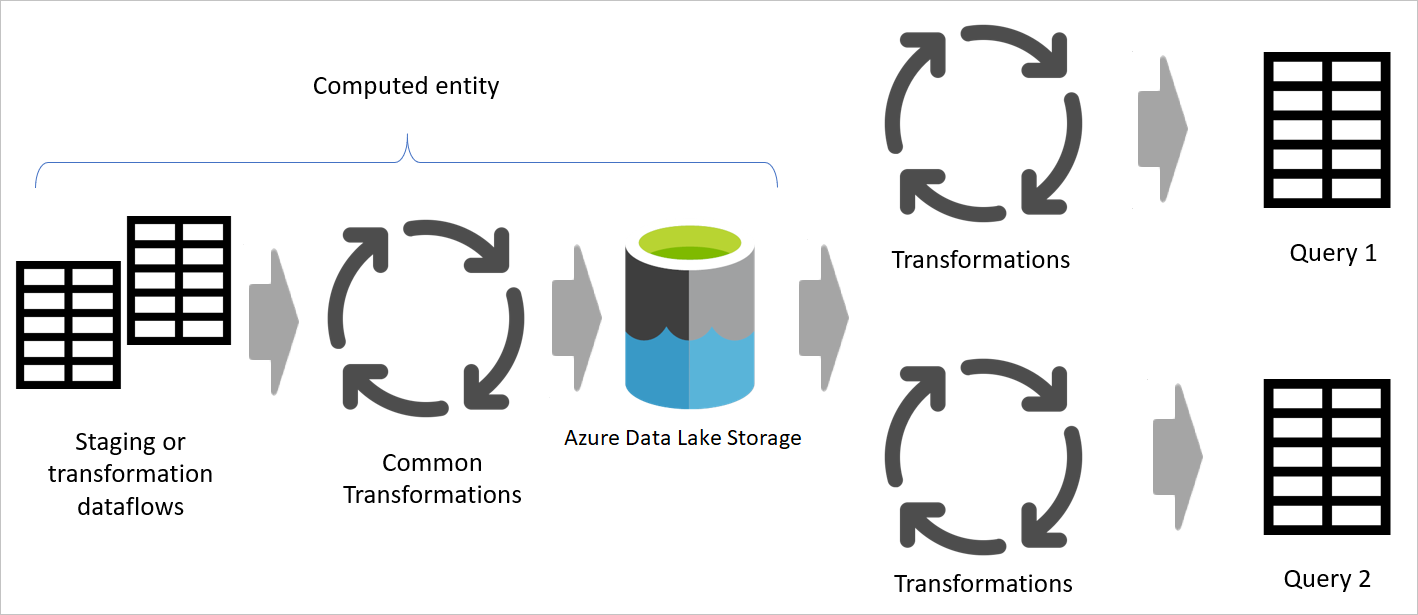
Diagram som betonar mellanlagring av dataflöden och mellanlagring. Diagrammet visar de data som hämtas från datakällan av staging-dataflödet och tabeller som lagras i antingen Dataverse eller Azure Data Lake Storage. Tabellerna visas sedan transformeras tillsammans med andra dataflöden, som sedan skickas ut som frågor.
Transformeringsdataflöden
När du separerar dina transformeringsdataflöden från mellanlagringsdataflödena är omvandlingen oberoende av källan. Den här separationen hjälper dig om du migrerar källsystemet till ett nytt system. Allt du behöver göra i så fall är att ändra mellanlagringsdataflödena. Transformeringsdataflödena fungerar troligen utan problem eftersom de endast kommer från mellanlagringsdataflödena.
Den här separationen hjälper också om källsystemanslutningen är långsam. Dataströmmen för transformation behöver inte vänta länge på att ta emot poster som kommer via en långsam anslutning från källsystemet. Staging-dataflödet har redan utfört den delen och data är redo för transformeringslagret.
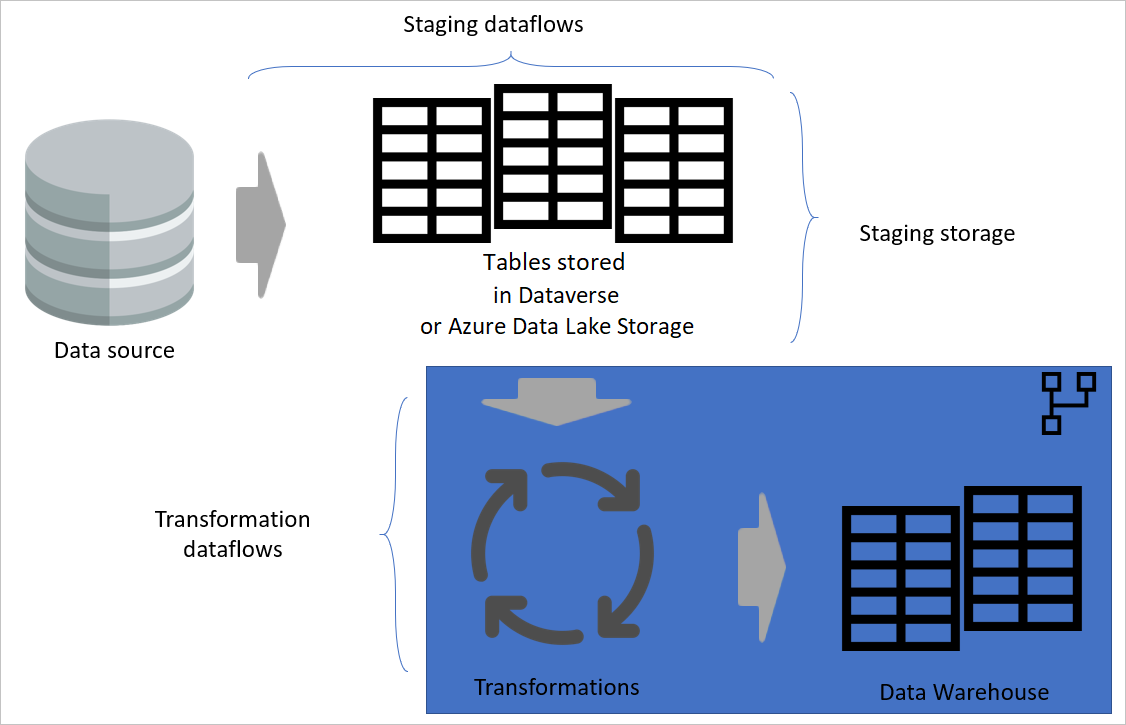
Lagerarkitektur
En arkitektur i flera lager är en arkitektur där du utför åtgärder i separata lager. Mellanlagrings- och transformeringsdataflöden kan vara två lager i en dataflödesarkitektur med flera lager. Att utföra åtgärder i lager säkerställer det minimala underhåll som behövs. När du vill ändra något behöver du bara ändra det i lagret där det finns. De andra lagren bör fortsätta att fungera bra.
Följande bild visar en arkitektur med flera lager för dataflöden där deras tabeller sedan används i Power BI-semantiska modeller.
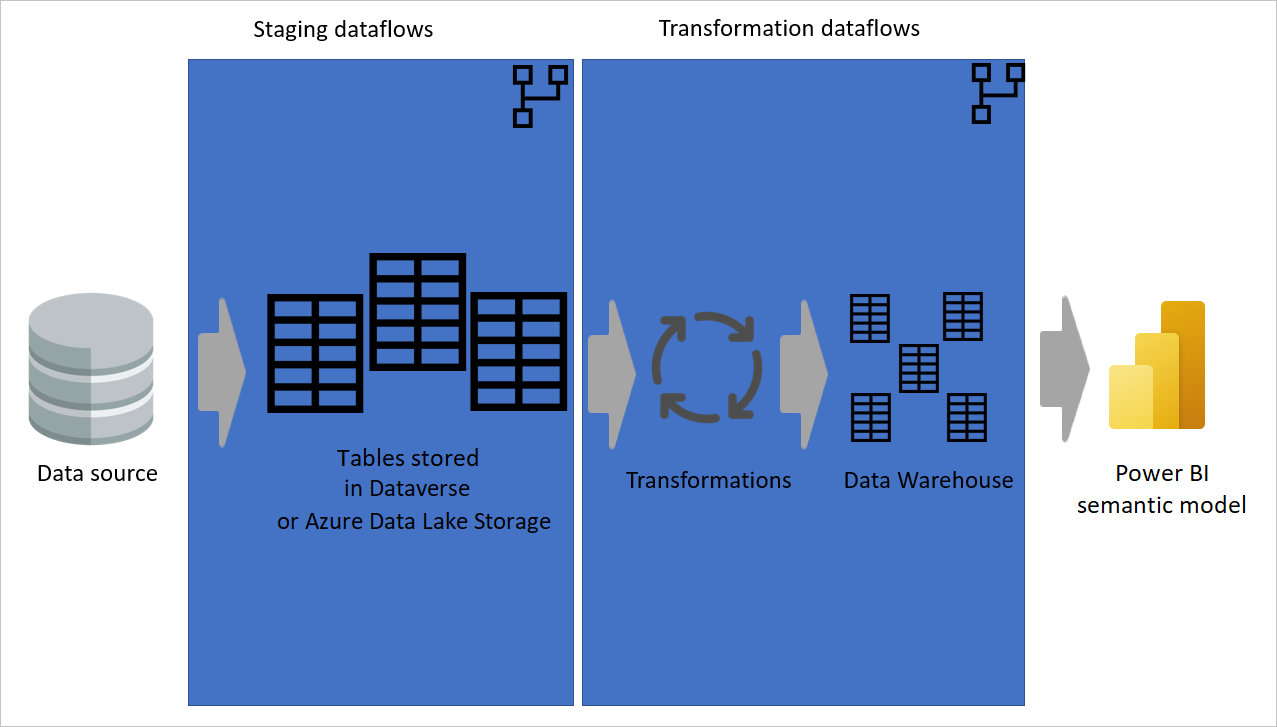
Använd en beräknad tabell så mycket som möjligt
När du använder resultatet av ett dataflöde i ett annat dataflöde använder du begreppet beräknad tabell, vilket innebär att du hämtar data från en "redan bearbetad och lagrad" tabell. Samma sak kan hända i ett dataflöde. När du refererar till en tabell från en annan tabell kan du använda den beräknade tabellen. Den här metoden är användbar när du har en uppsättning transformeringar som måste göras i flera tabeller, som kallas vanliga transformeringar.
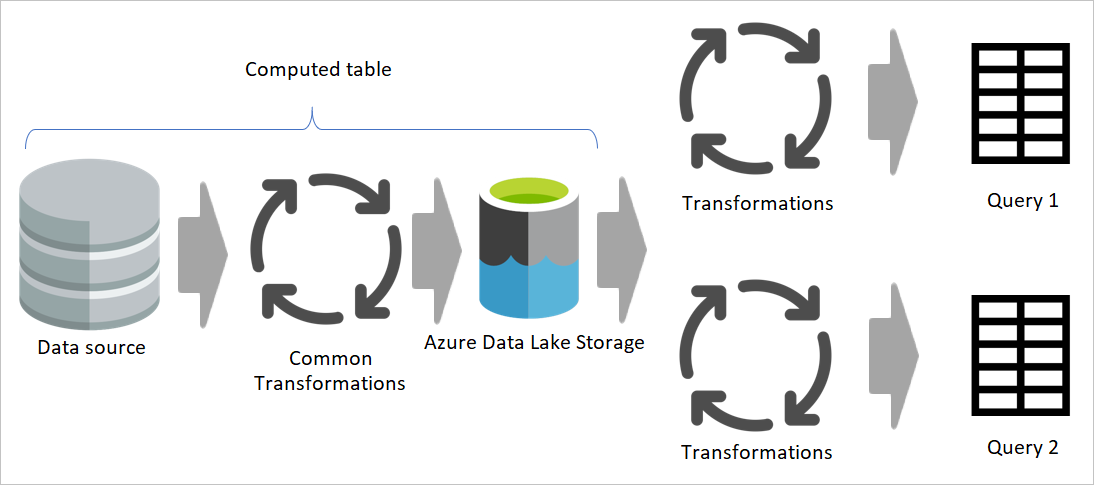
I föregående bild hämtar den beräknade tabellen data direkt från källan. I arkitekturen för mellanlagrings- och transformeringsdataflöden är det dock troligt att de beräknade tabellerna kommer från mellanlagringsdataflödena.
Skapa ett stjärnschema
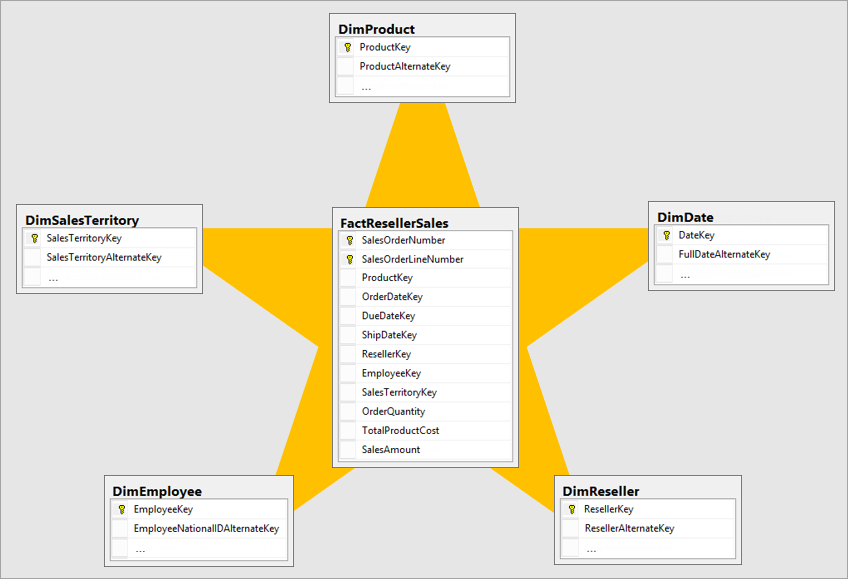
Den bästa dimensionella modellen är en stjärnschemamodell som har dimensioner och faktatabeller utformade på ett sätt som minimerar tiden för att fråga efter data från modellen. En star-schemamodell gör det också enkelt att förstå för datavisualiseraren.
Det är inte idealiskt att föra in data i samma layout som det operativa systemet i ett BI-system. Datatabellerna ska byggas om. Vissa av tabellerna bör ha formen av en dimensionstabell, som behåller den beskrivande informationen. Vissa av tabellerna bör ha formen av en faktatabell för att behålla aggregeringsbara data. Den bästa layouten för faktatabeller och dimensionstabeller att bilda är ett stjärnschema. För mer information, gå till Förstå stjärnschema och vikten för Power BI.
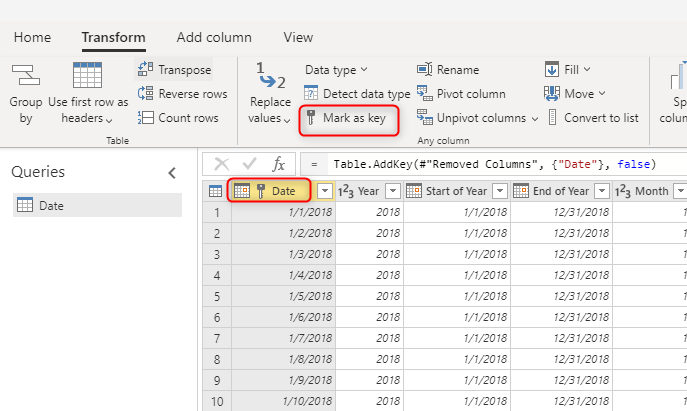
Använda ett unikt nyckelvärde för dimensioner
När du skapar dimensionstabeller kontrollerar du att du har en nyckel för var och en. Den här nyckeln säkerställer att det inte finns några många-till-många-relationer (eller med andra ord "svaga") relationer mellan dimensioner. Du kan skapa nyckeln genom att använda en transformering för att se till att en kolumn eller en kombination av kolumner returnerar unika rader i dimensionen. Sedan kan den kombinationen av kolumner markeras som en nyckel i tabellen i dataflödet.
Gör en inkrementell uppdatering för stora faktatabeller
Faktatabeller är alltid de största tabellerna i den dimensionella modellen. Vi rekommenderar att du minskar antalet rader som överförs för dessa tabeller. Om du har en mycket stor faktatabell kontrollerar du att du använder inkrementell uppdatering för tabellen. En inkrementell uppdatering kan göras i Power BI-semantikmodellen och även dataflödestabellerna.
Du kan använda inkrementell uppdatering för att endast uppdatera en del av data, den del som ändrades. Det finns flera alternativ för att välja vilken del av data som ska uppdateras och vilken del som ska sparas. Mer information finns i Använda inkrementell uppdatering med Power BI-dataflöden.

Referera till skapandet av dimensions- och faktatabeller
I källsystemet har du ofta en tabell som du använder för att generera både fakta- och dimensionstabeller i informationslagret. Dessa tabeller är bra kandidater för beräknade tabeller och även mellanliggande dataflöden. Den gemensamma delen av processen– till exempel datarensning och borttagning av extra rader och kolumner – kan göras en gång. Genom att använda en referens från utdata från dessa åtgärder kan du skapa dimensions- och faktatabellerna. Den här metoden använder den beräknade tabellen för de vanliga omvandlingarna.