Beräkningstabellscenarier och användningsfall
Det finns fördelar med att använda beräknade tabeller i ett dataflöde. Den här artikeln beskriver användningsfall för beräknade tabeller och beskriver hur de fungerar i bakgrunden.
Vad är en beräknad tabell?
En tabell representerar datautdata för en fråga som skapats i ett dataflöde efter att dataflödet har uppdaterats. Den representerar data från en källa och, om du vill, de transformeringar som tillämpades på den. Ibland kanske du vill skapa nya tabeller som är en funktion i en tidigare inmatad tabell.
Även om det är möjligt att upprepa de frågor som skapade en tabell och tillämpa nya transformeringar på dem, har den här metoden nackdelar: data matas in två gånger och belastningen på datakällan fördubblas.
Beräknade tabeller löser båda problemen. Beräknade tabeller liknar andra tabeller eftersom de hämtar data från en källa och du kan använda ytterligare transformeringar för att skapa dem. Men deras data kommer från det lagringsdataflöde som används och inte från den ursprungliga datakällan. De skapades tidigare av ett dataflöde och återanvänddes sedan.
Beräknade tabeller kan skapas genom att referera till en tabell i samma dataflöde eller genom att referera till en tabell som skapats i ett annat dataflöde.

Varför ska jag använda en beräknad tabell?
Det kan ta lång tid att utföra alla omvandlingssteg i en tabell. Det kan finnas många orsaker till den här avmattningen – datakällan kan vara långsam, eller så kan omvandlingarna som du gör behöva replikeras i två eller flera frågor. Det kan vara fördelaktigt att först mata in data från källan och sedan återanvända dem i en eller flera tabeller. I sådana fall kan du välja att skapa två tabeller: en som hämtar data från datakällan och en annan – en beräknad tabell – som tillämpar fler transformeringar på data som redan skrivits till datasjön som används av ett dataflöde. Den här ändringen kan öka prestanda och återanvändning av data, vilket sparar tid och resurser.
Om två tabeller till exempel delar ens en del av sin transformeringslogik, utan en beräknad tabell, måste omvandlingen göras två gånger.
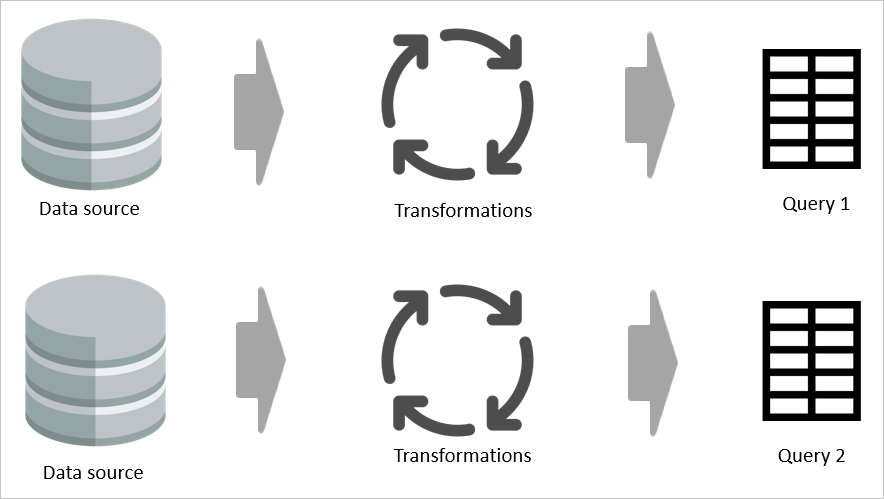
Men om en beräknad tabell används bearbetas den gemensamma (delade) delen av omvandlingen en gång och lagras i Azure Data Lake Storage. De återstående transformeringarna bearbetas sedan från utdata från den gemensamma omvandlingen. På det hela taget går bearbetningen mycket snabbare.
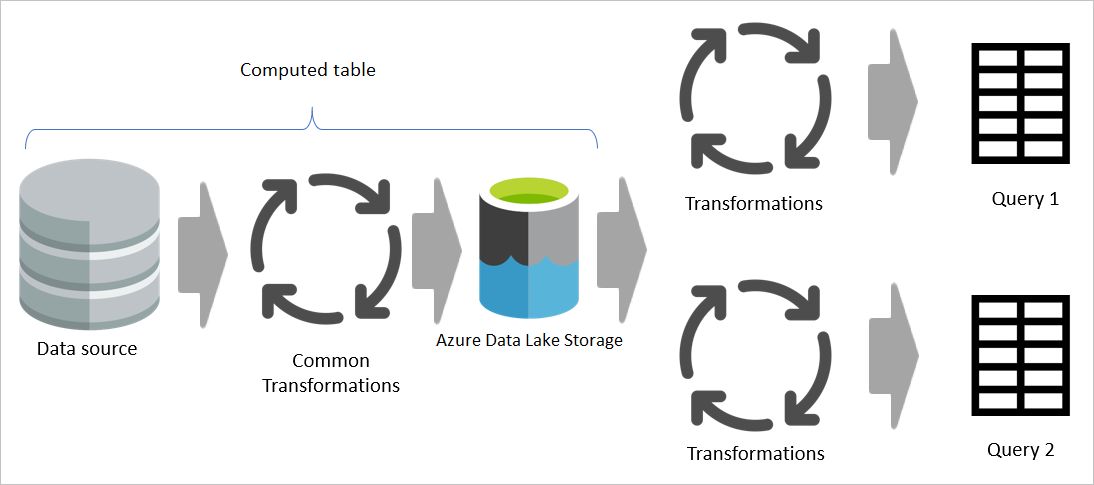
En beräknad tabell ger en plats som källkod för omvandlingen och påskyndar omvandlingen eftersom den bara behöver göras en gång i stället för flera gånger. Belastningen på datakällan minskar också.
Exempelscenario för att använda en beräknad tabell
Om du skapar en aggregerad tabell i Power BI för att påskynda datamodellen kan du skapa den aggregerade tabellen genom att referera till den ursprungliga tabellen och tillämpa fler transformeringar på den. Med den här metoden behöver du inte replikera omvandlingen från källan (den del som kommer från den ursprungliga tabellen).
Följande bild visar till exempel tabellen Beställningar.

Med hjälp av en referens från den här tabellen kan du skapa en beräknad tabell.
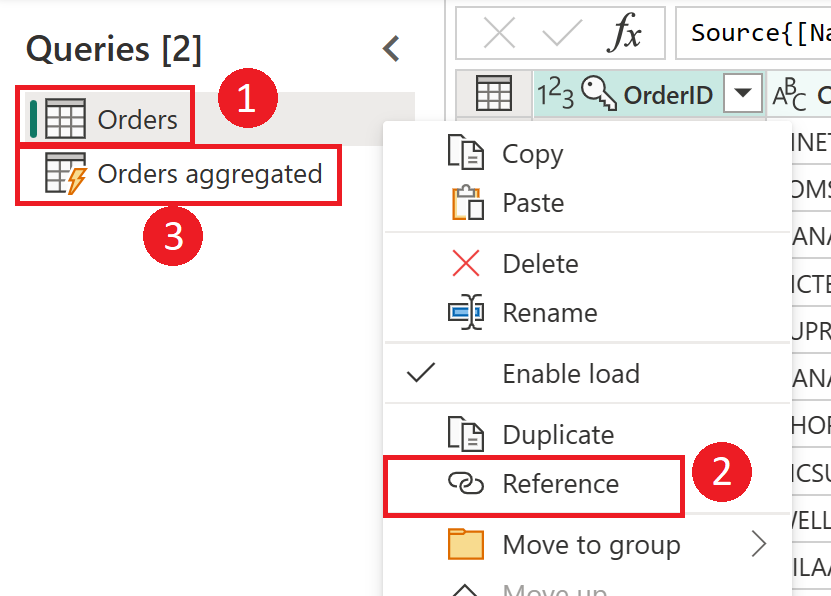
Skärmbild som visar hur du skapar en beräknad tabell från tabellen Beställningar. Högerklicka först på tabellen Beställningar i fönstret Frågor och välj alternativet Referens på den nedrullningsbara menyn. Den här åtgärden skapar den beräknade tabellen, som här har bytt namn till aggregerade beställningar.
Den beräknade tabellen kan ha ytterligare transformeringar. Du kan till exempel använda Gruppera efter för att aggregera data på kundnivå.
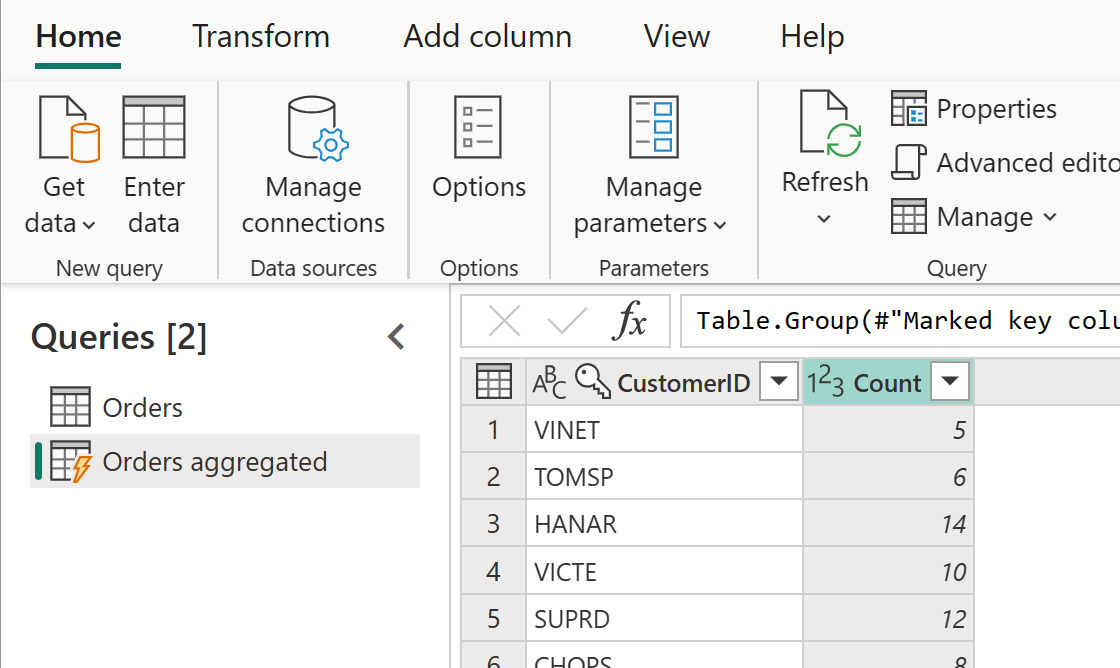
Det innebär att tabellen Orders Aggregated hämtar data från tabellen Beställningar och inte från datakällan igen. Eftersom vissa av de omvandlingar som behöver göras redan har gjorts i tabellen Beställningar är prestandan bättre och datatransformeringen går snabbare.
Beräknad tabell i andra dataflöden
Du kan också skapa en beräknad tabell i andra dataflöden. Det kan skapas genom att hämta data från ett dataflöde med Microsoft Power Platform-dataflödesanslutningen.
Bilden framhäver anslutningsappen för Power Platform-dataflöden från fönstret Välj datakälla i Power Query. Dessutom ingår en beskrivning som anger att en dataflödestabell kan byggas ovanpå data från en annan dataflödestabell, som redan finns kvar i lagringen.
Konceptet med den beräknade tabellen är att ha en tabell kvar i lagringen och andra tabeller som hämtas från den, så att du kan minska lästiden från datakällan och dela några av de vanliga omvandlingarna. Den här minskningen kan uppnås genom att hämta data från andra dataflöden via dataflödesanslutningsappen eller referera till en annan fråga i samma dataflöde.
Beräknad tabell: Med transformeringar eller utan?
Nu när du vet att beräknade tabeller är bra för att förbättra datatransformeringens prestanda är en bra fråga att ställa om transformeringar alltid ska skjutas upp till den beräknade tabellen eller om de ska tillämpas på källtabellen. Ska data alltid matas in i en tabell och sedan transformeras i en beräknad tabell? Vilka är för- och nackdelarna?
Läsa in data utan transformering för Text-/CSV-filer
När en datakälla inte har stöd för frågedelegering (till exempel text-/CSV-filer) är det liten fördel med att tillämpa transformeringar när data hämtas från källan, särskilt om datavolymerna är stora. Källtabellen bör bara läsa in data från text-/CSV-filen utan att tillämpa några transformeringar. Sedan kan beräknade tabeller hämta data från källtabellen och utföra omvandlingen ovanpå inmatade data.
Du kan fråga dig vad är värdet för att skapa en källtabell som bara matar in data? En sådan tabell kan fortfarande vara användbar, för om data från källan används i mer än en tabell minskar belastningen på datakällan. Dessutom kan data nu återanvändas av andra personer och dataflöden. Beräknade tabeller är särskilt användbara i scenarier där datavolymen är stor, eller när en datakälla nås via en lokal datagateway, eftersom de minskar trafiken från gatewayen och belastningen på datakällorna bakom dem.
Utföra några av de vanliga omvandlingarna för en SQL-tabell
Om datakällan stöder frågedelegering är det bra att utföra några av transformeringarna i källtabellen eftersom frågan viks till datakällan och endast transformerade data hämtas från den. De här ändringarna förbättrar den övergripande prestandan. Den uppsättning transformeringar som är vanliga i nedströmsberäknade tabeller bör tillämpas i källtabellen, så att de kan vikas till källan. Andra transformeringar som endast gäller för underordnade tabeller bör göras i beräknade tabeller.
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för