Överväganden för fältmappning för standarddataflöden
När du läser in data i Dataverse-tabeller mappar du källfrågans kolumner i dataflödets redigeringsupplevelse till dataverse-måltabellkolumnerna. Förutom att mappa data finns det andra överväganden och metodtips att ta hänsyn till. I den här artikeln går vi igenom de olika dataflödesinställningarna som styr beteendet för dataflödesuppdatering och därmed data i måltabellen.
Kontrollera om dataflöden skapar eller ökar poster för varje uppdatering
Varje gång du uppdaterar ett dataflöde hämtar det poster från källan och läser in dem i Dataverse. Om du kör dataflödet mer än en gång , beroende på hur du konfigurerar dataflödet, kan du:
- Skapa nya poster för varje dataflödesuppdatering, även om sådana poster redan finns i måltabellen.
- Skapa nya poster om de inte redan finns i tabellen eller uppdatera befintliga poster om de redan finns i tabellen. Det här beteendet kallas upsert.
Om du använder en nyckelkolumn visas dataflödet för att öka posterna till måltabellen, men om du inte väljer en nyckel visas dataflödet för att skapa nya poster i måltabellen.
En nyckelkolumn är en kolumn som är unik och deterministisk för en datarad i tabellen. I en ordertabell bör du till exempel inte ha två rader med samma order-ID om order-ID är en nyckelkolumn. Dessutom bör ett order-ID – låt oss säga en order med ID 345 – bara representera en rad i tabellen. Om du vill välja nyckelkolumnen för tabellen i Dataverse från dataflödet måste du ange nyckelfältet i karttabellupplevelsen.
Välja ett primärt namn och nyckelfält när du skapar en ny tabell
Följande bild visar hur du kan välja den nyckelkolumn som ska fyllas i från källan när du skapar en ny tabell i dataflödet.

Det primära namnfältet som du ser i fältmappningen är för ett etikettfält. Det här fältet behöver inte vara unikt. Fältet som används i tabellen för att kontrollera duplicering är det fält som du angav i fältet Alternativ nyckel .
Med en primärnyckel i tabellen ser du till att även om du har duplicerade data i fältet som mappas till primärnyckeln, läses inte de duplicerade posterna in i tabellen. Det här beteendet håller en hög kvalitet på data i tabellen. Data av hög kvalitet är avgörande för att skapa rapporteringslösningar baserade på tabellen.
Fältet primärt namn
Det primära namnfältet är ett visningsfält som används i Dataverse. Det här fältet används i standardvyer för att visa innehållet i tabellen i andra program. Det här fältet är inte det primära nyckelfältet och bör inte betraktas som det. Det här fältet kan ha duplicerade värden eftersom det är ett visningsfält. Det bästa sättet är dock att använda ett sammanfogat fält för att mappa till det primära namnfältet, så namnet är helt förklarande.
Det alternativa nyckelfältet är det som används som primärnyckel.
Välja ett nyckelfält vid inläsning till en befintlig tabell
När du mappar en dataflödesfråga till en befintlig Dataverse-tabell kan du välja om och vilken nyckel som ska användas när data läses in i måltabellen.
Följande bild visar hur du kan välja den nyckelkolumn som ska användas när du utökar poster till en befintlig Dataverse-tabell:

Ange en tabells unika ID-kolumn och använda den som ett nyckelfält för att utöka poster till befintliga Dataverse-tabeller
Alla Microsoft Dataverse-tabellrader har unika identifierare som definierats som GUID: er. Dessa GUID:er är den primära nyckeln för varje tabell. Som standard kan en tabells primärnyckel inte anges av dataflöden och genereras automatiskt av Dataverse när en post skapas. Det finns avancerade användningsfall där det är önskvärt att använda den primära nyckeln i en tabell, till exempel att integrera data med externa källor samtidigt som samma primära nyckelvärden bevaras i både den externa tabellen och Dataverse-tabellen.
Kommentar
- Den här funktionen är endast tillgänglig vid inläsning av data till befintliga tabeller.
- Det unika identifierarfältet accepterar endast en sträng som innehåller GUID-värden, andra datatyper eller värden gör att postskapandet misslyckas.
Om du vill dra nytta av en tabells unika identifierarfält väljer du Läs in till befintlig tabell på sidan Karttabeller när du skapar ett dataflöde. I exemplet som visas i den efterföljande bilden läser den in data i tabellen CustomerTransactions och använder kolumnen TransactionID från datakällan som unik identifierare för tabellen.
Observera att i listrutan Välj nyckel kan du välja den unika identifieraren , som alltid heter "tablename + id". Eftersom tabellnamnet är "CustomerTransactions" heter det unika identifierarfältet "CustomerTransactionId".

När du har valt det uppdateras avsnittet kolumnmappning så att det innehåller den unika identifieraren som en målkolumn. Du kan sedan mappa källkolumnen som representerar den unika identifieraren för varje post.

Vad är bra kandidater för nyckelfältet
Nyckelfältet är ett unikt värde som representerar en unik rad i tabellen. Det är viktigt att ha det här fältet eftersom det hjälper dig att undvika dubbletter av poster i tabellen. Det här fältet kan komma från tre källor:
Primärnyckeln i källsystemet (till exempel OrderID i föregående exempel). sammanfogat fält som skapats via Power Query-transformeringar i dataflödet.

En kombination av fält som ska väljas i alternativet Alternativ nyckel . En kombination av fält som används som ett nyckelfält kallas även för en sammansatt nyckel.
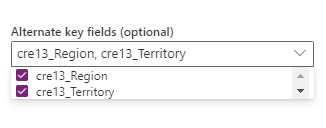
Ta bort rader som inte längre finns
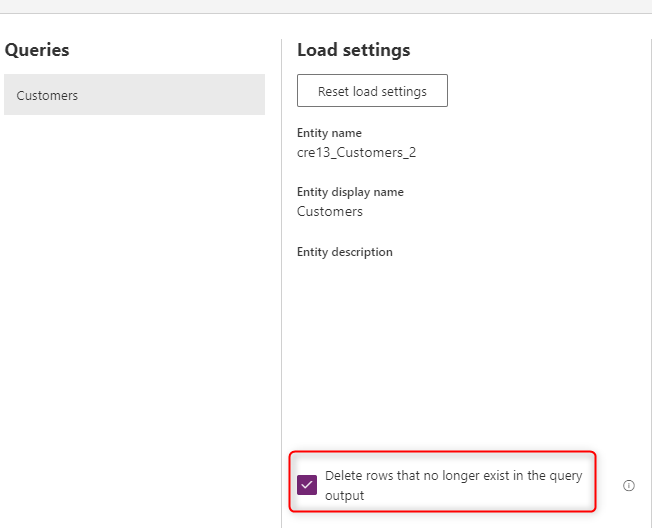
Om du vill att data i tabellen alltid ska synkroniseras med data från källsystemet väljer du alternativet Ta bort rader som inte längre finns i frågeutdata. Det här alternativet gör dock dataflödet långsammare eftersom det finns ett behov av en radjämförelse baserat på primärnyckeln (alternativ nyckel i fältmappningen av dataflödet) för att den här åtgärden ska kunna utföras.
Alternativet innebär att om det finns en datarad i tabellen som inte finns i nästa dataflödesuppdaterings frågeutdata tas raden bort från tabellen.
Kommentar
Standard V2-dataflöden förlitar sig på fälten createdon och modifiedon för att ta bort rader som inte finns i dataflödenas utdata från måltabellen. Om dessa kolumner inte finns i måltabellen tas inte poster bort.
Kända begränsningar
- Mappning till polymorfa uppslagsfält stöds för närvarande inte.
- Mappning till ett uppslagsfält på flera nivåer, ett uppslag som pekar på en annan tabells uppslagsfält, stöds för närvarande inte.
- Mappning till fälten Status och Statusorsak stöds för närvarande inte.
- Det går inte att mappa data till text med flera rader som innehåller radbrytningstecken och radbrytningarna tas bort. I stället kan du använda radbrytningstaggen
<br>för att läsa in och bevara text med flera rader. - Mappning till valfält som konfigurerats med alternativet för flera val aktiverat stöds endast under vissa förhållanden. Dataflödet läser bara in data till valfält med alternativet för flera val aktiverat, och en kommaavgränsad lista med värden (heltal) för etiketterna används. Om etiketterna till exempel är "Choice1, Choice2, Choice3" med motsvarande heltalsvärden "1, 2, 3" ska kolumnvärdena vara "1,3" för att välja de första och sista valen.
- Standard V2-dataflöden förlitar sig på fälten
createdonochmodifiedonför att ta bort rader som inte finns i dataflödenas utdata från måltabellen. Om dessa kolumner inte finns i måltabellen tas inte poster bort. - Mappning till fält vars egenskap IsValidForCreate är inställd på
falsestöds inte (till exempel fältet Konto i entiteten Kontakt).